如何批量提取pdf文件名到excel?
如何批量提取pdf文件名到excel?在大家整理PDF文档的时候会不会遇到下面这些问题,首先PDF过多,每个PDF文件都有自己的名字,我们想要分类排放的话非常麻烦,不仅耗费时间而且带来的收益非常低,然后即使我们整理好了PDF文档,后续想要寻找这些PDF文档的话也是非常麻烦的,因为没有快速搜索的操作,即使将PDF进行分类了寻找也非常的难受,最后整理PDF文档的时候可能会出错,因为消耗了大量的精力和集中力,如果我们一次操作太长的时间很有可能导致整理后的文档有问题,后续要维护会变的更加麻烦。
综上所述,如果我们在整理PDF文档的时候遇到了上面这些问题应该怎么办呢?小编这里推荐的是批量提取PDF文件名到excel里面,这样能够带来超多的好处,首先能够快速的为我们整理和分类PDF文件,无需我们自己创建文件夹并一个个添加进去了,然后excel文档是支持查询操作的,如果我们想要找什么PDF文件直接搜索就可以找到,不用我们再自己手动翻找PDF文件,最后excel文档能够帮助我们完成分析和报告,如果领导有这方面的需求,excel文档也能够帮助我们快速完成分析的操作,那么应该如何批量提取PDF文件到excel里面呢?快来跟随小编看看下面这些方法吧!

方法一:使用“优速文件名提取器”批量提取PDF文件名到excel
步骤1:首先请您将“优速文件名提取器”下载并安装到电脑上,安装完成后打开软件,在软件左侧可以看到【文件名】选项,点击它。
步骤2:之后需要先将PDF导入到软件中,只要点击【添加文件】按钮就可以选择pdf文件并导入到软件里面。
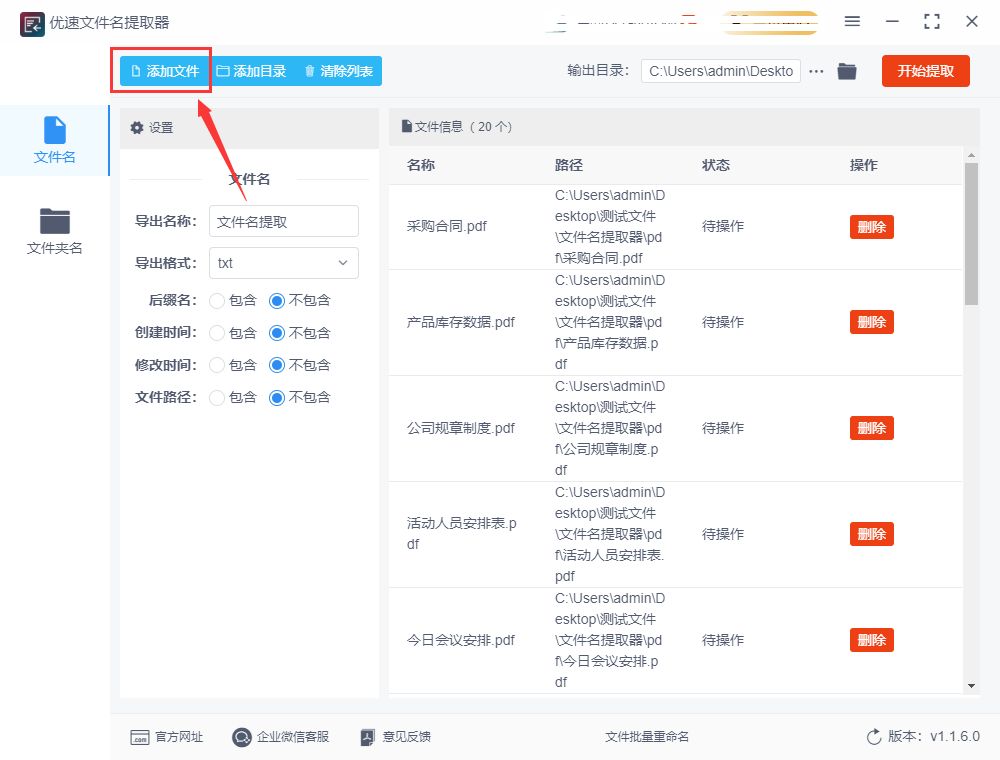
步骤3:文件导入成功后左侧就会显示出很多设置,在这里我们可以设置名称、后缀等内容,但最重要的就是【导出格式】一定要设置为xlsx格式,也就是excel的格式,其余设置都可以按照自己的想法调节。

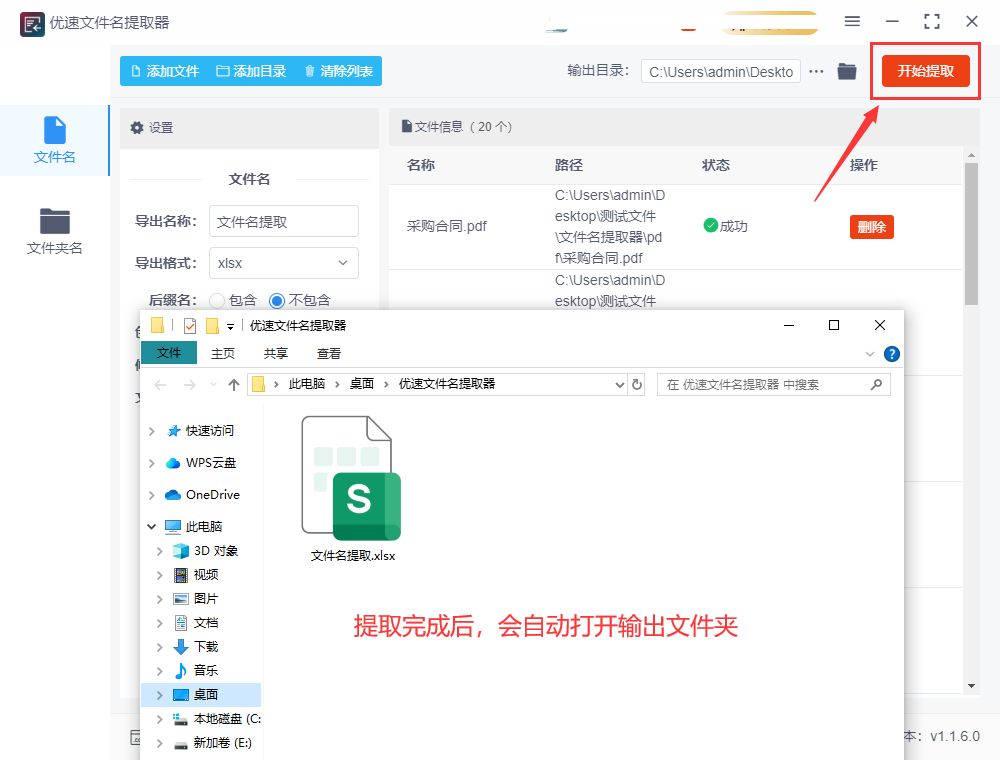
步骤4:调节完全部设置后点击右上角的【开始提取】按钮,启动软件的提取操作。等待一会提取完成会自动打开输出文件夹,文件名提取后的excel导出文件就保存在这里。
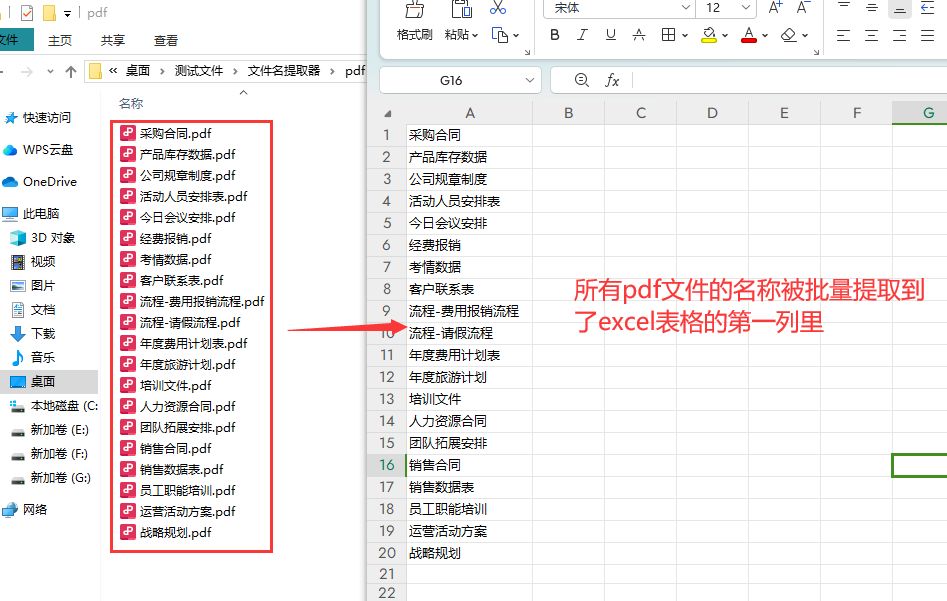
步骤5:双击将excel文件打开就可以看到所有PDF文件名都被成功提取到excel表格的第一列里。
方法二:使用Python 脚本来进行提取
要批量提取 PDF 文件的名称到 Excel 表格中,你可以使用一些自动化的工具或脚本来实现这个目的。以下是一种常见的方法:
使用 Python 脚本:
你可以使用 Python 编写一个脚本来批量提取 PDF 文件名称,并将其保存到 Excel 表格中。首先,你需要安装 pandas 和 PyPDF2 这两个 Python 库,它们分别用于处理 Excel 表格和 PDF 文件。
下面是一个简单的示例代码,演示了如何批量提取指定文件夹中的 PDF 文件名称,并将其保存到 Excel 表格中:
import os
import pandas as pd
from PyPDF2 import PdfReader
# 指定 PDF 文件所在的文件夹路径
pdf_folder = '/path/to/your/pdf/folder'
# 遍历文件夹,提取 PDF 文件名
pdf_files = [f for f in os.listdir(pdf_folder) if f.endswith('.pdf')]
# 创建一个空的 DataFrame 用于存储 PDF 文件名
pdf_df = pd.DataFrame(columns=['File Name'])
# 将 PDF 文件名添加到 DataFrame 中
for pdf_file in pdf_files:
pdf_df = pdf_df.append({'File Name': pdf_file}, ignore_index=True)
# 保存 DataFrame 到 Excel 表格中
output_excel = '/path/to/your/output/excel/file.xlsx'
pdf_df.to_excel(output_excel, index=False)
在这个示例代码中,你需要将 /path/to/your/pdf/folder 替换为存储 PDF 文件的文件夹路径,将 /path/to/your/output/excel/file.xlsx 替换为你想要保存的 Excel 文件路径。
运行这个 Python 脚本后,它将遍历指定文件夹中的所有 PDF 文件,提取它们的文件名,并将文件名保存到指定的 Excel 表格中。
通过这种方式,你可以方便地批量提取 PDF 文件的名称到 Excel 表格中。如果你对 Python 不太熟悉,你也可以寻求其他自动化工具或脚本来完成类似的任务。

将PDF提取到excel里面是会带来很多的好处,但要知道这样操作也不是十全十美的,首先机械操作也会消耗很多的时间,特别是PDF文件比较多的时候,我们可能需要挂机一会才可以完成提取操作,然后机器控制的灵活性是没有手动那么好的,比如我们要控制文件的版本,想要修改后的名字,这种时候我们只能通过手动修改去完成了,机器无法帮我们确认要哪种,所以两种都会直接添加上去,最后将PDF文件名提取到excel的时候一定要注意数据的保护,不要随意分享给别人,否则可能会造成数据泄露等严重后果,那么到这里小编这篇“如何批量提取pdf文件名到excel?”就结束了,相信看完这篇文章的你,肯定获得了很多的知识!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!