Video-GroundingDino论文解读
文章目录
前言
之前我在博客介绍了一篇grounding DINO文章,该篇文章只是用于图像定位检测的open-vocabulary内容。最近,偶然看到一篇video grounding DINO文章,该篇文章解决视频相关定位,视频Grounding旨在定位视频中与输入文本查询相对应的时空部分。本文通过引入开放词汇时空视频Grounding任务,解决了当前视频Grounding方法中的一个关键限制。直白说,作者使用时空方式实现视频open-vocablary任务。我将在本博客分享我的见解,若有错误之处,欢迎指正。
一、摘要
视频Grounding旨在定位视频中与输入文本查询相对应的时空部分。本文通过引入开放词汇时空视频Grounding任务,解决了当前视频Grounding方法中的一个关键限制。 与由于训练数据和预定义词汇有限而难以应对开放词汇场景的流行封闭集方法不同,我们的模型利用基础空间基础模型的预训练表示。 这使其能够有效地弥合自然语言和多样化视觉内容之间的语义差距,在封闭式和开放式词汇环境中实现强劲的性能。 我们的贡献包括一种新颖的时空视频基础模型,在多个数据集的封闭集评估中超越了最先进的结果,并在开放词汇场景中展示了卓越的性能。 值得注意的是,所提出的模型在 VidSTG(陈述式和疑问式)和 HC-STVG(V1 和 V2)数据集的封闭集设置中优于最先进的方法。 此外,在 HC-STVG V1 和 YouCook-Interactions 的开放词汇评估中,我们的模型超越了最近表现最好的模型 4.26 m_vIoU 和 1.83% 的准确率,证明了其在处理不同语言和视觉概念以提高视频理解方面的功效。

二、引言
时空视频定位是链接视觉内容和语言描述的中枢,这促使视觉数据的语义理解。先前在视觉定位的方法如TubeDETR/STCAT和STVGFormer主要聚焦在closed-set数据,模型在这些带有预定义类别和详细注释的数据集中训练。尽管这些模型在VidSTG和HC-STVG closed-set数据集表现state-of-the-art,但模型在训练集之外泛化表现面临挑战。现有视频数据集规模小与受限多样性样本阻碍模型适应看不见unseen的场景。
现有监督方法又受有限vocabulary(类别)的闭集限制。作者也调研了open-vocabulary的时空视频定位方法。与传统惯例不一样,时空视频定位任务意解决多样性语言与视觉概念的视频定位是一个挑战。主要目的是在一系列有类别标注的数据与使用open-vocabulary方法生成unseen目标训练模型。为此,本文探讨了开放词汇视频基础所固有的挑战和机遇,为更强大和通用的视频理解奠定了基础。
作者又说,训练一个有效的open-vocabulary的视频定位需要大量带有丰富自然语言表达和对应时空定位数据集,这样数据能是模型学习通用视觉和文本特征去处理样本外的分布预测(zero-shot),可更好泛化。我们们受到基准方法启发,特别是空间定位方法。我们目的是结合预训练表征去增强视频定位。我们方法需是时空视频定位模型能像DETR架构一样通过空间回归模块增强。
三、贡献
1、我们评估时空定位模型,在HC-STVG V1与YouCook-interactions的zero-shot。我们模型超过最先进的TubeDETR与STCAT分别4.26的m_vIoU和1.83% accuracy。
2、结合空间定位优势与video-specific adapter互补,我们方法表现优异在四个closed-set数据集中。i.e.,VidSTG (Declarative) [32], VidSTG (Interrogative) [32],HC-STVG V1 [24] and HC-STVG V2 [24]
注:我觉得比较重要,也是贡献1说的时空定位模型结构,该篇文章也是提出编解码模块,处理时空融合。
四、模型结构
1、模型定义与问题
数据少问题
文章也说了对于数据少的问题,受空间定位方法启发,我们用空间grounding方法从有限的训练样本中生成表征去增强视频grounding的弱表征。原文如下说明:
To solve this problem, our approach takes inspirationfrom recent
spatial grounding methods [4, 8, 12, 14, 29],which have strong open-vocabulary performance
thanks to the large image-text corpus they are trained on. We can utilize the generalized representations of these models to enrich the weaker representation of video-grounding
approaches obtained from the limited number of training samples.
Our approach aims to leverage the strong pretrained representations of
spatial grounding methods to achieve strong closed-set supervised
and open-vocabulary video grounding performance
个人觉得作者并没有说清楚,数据少问题的处理
模型解决问题
spatio-temporal video grounding任务通过在视频序列中整合时间与空间信息涉及定位、识别目标和行为。与空间定位对应,它只聚焦一帧的定位、识别、行为,少了时间维度。这意味需要随时间移动理解每一帧目标位置或行为。
模型模块
作者提出类似DETR设计的时空视频定位模型,我们时空视频定位方法是基于DETR的DINO检测器,也借助了GLIP与Grounding DINO的图像文本校准概念,如下论文描述。
Our proposed spatio-temporal video grounding method uses DETR-like [1] design, with
temporal aggregation and adaptation modules for learning video-specific representations.
nce. Our spatio-temporal video grounding approach is based on the state-of-the-art DETRbased [1]
object detection framework DINO [31] and also borrows concepts of image-text alignment and grounding
from Grounded Language-Image Pre-training (GLIP) [10] and Grounding DINO [12].
2、模型结构
模型结构图
作者论文描述,文本与图像编码分别使用bert与swin-transformer,随后使用交叉多模态注意力机制编码,在解码时使用文本指导query,并也使用交叉多模态注意力机制解码。
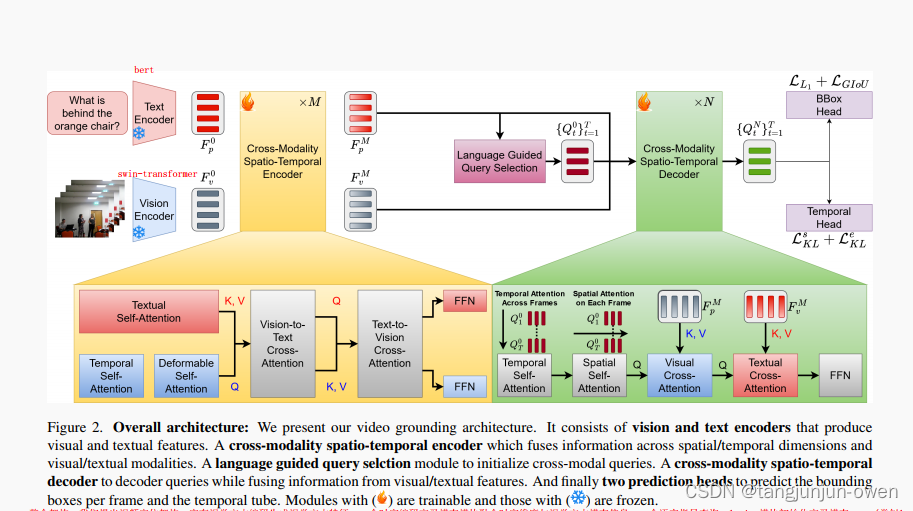
整个架构:我们提出视频定位架构。它有视觉文本编码生成视觉文本特征。一个时空编码交叉模态模块融合时空维度与视觉文本模态信息。一个语言指导查询selction模块初始化交叉模态query(类似learn query)。一个时空解码交叉模态模块当融合信息来自视觉文本特征时解码queries。最终2个预测头预测每一帧的box和时间tube。火符号是学习模块、冰符号是冻结模块。
Cross-Modality Spatio-Temporal Encoder
作者解释获得视频特征与文本特征之间在不同帧间既没有多模态交互信息也没有时间依赖信息。因此,作者在不同时间帧中使用交叉多模态时空信息编码去学习交叉模态特征。对于视频特征,作者使用多头self-attention在时间维度编码,随后使用Deformable Attention在空间维度编码;对于文本特征,也采用同视频特征一样的方法。然后融合这2个特征类似GLIP方法。

Language-Guided Query Selection
该模块旨在选择与输入文本更相关的特征作为解码器query,以实现有效的语言视觉融合。使用正余弦位置编码,类似DETR可学习query方式。

Cross-Modality Spatio-Temporal Decoder
非常感觉类似DETR方法,使用query解码获得bounding box和开始或结束帧,然后做了一系列transformer等方式变化到可被head接收解码格式。

Prediction Heads
最终输出使用多层MLP方式实现。

总结
本篇文章是如何使用类似Groundin DINO进一步实现视频的时空定位,多了时间维度。作者提出,如何空间融合与时间融合的模块。但文章并没详细描述时间融合细节与处理视频数据少的问题。整体来说,本篇文章就是多了时间维度的open-vocabulary方法,是可值得借鉴的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 算法-滑动窗口
- 用通俗易懂的方式讲解大模型:ChatGLM3-6B 功能原理解析
- JavaScript中audio停止播放事件
- 从起高楼到楼塌了的中台战略 —— 业务中台、数据中台、技术中台
- 硬件基础:组合逻辑电路
- 案例125:基于微信小程序的个人健康数据管理系统的设计与实现
- 企业微信机器人发送文本、图片、文件、markdown、图文信息
- SpringBoot-开启Admin监控服务
- Pearson correlation coefficient (Pearson’s r) 皮尔森相关系数
- 实习课知识整理3:首页商品列表的展示