缓存数据库一致性问题
发布时间:2024年01月05日
为什么使用缓存?
- 业务处于起步阶段,流量非常小,那无论是读请求还是写请求,直接操作数据库
- 随着业务指数级增长,请求量剧增,直接访问数据库,导致性能急剧下降,需要引入缓存提高读性能。
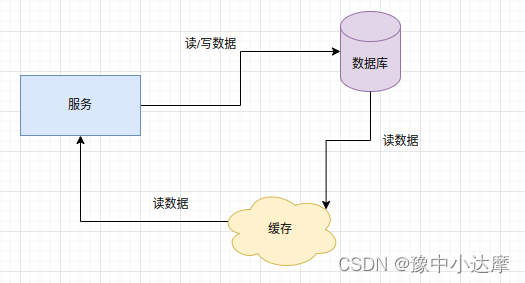
引入缓存导致的一些问题?
1、如何将数据库的数据加载到缓存中?
- 系统启动或者业务执行前,统一将数据刷入缓存
- 写操作时变更数据库,不操作缓存
- 启动定时任务,定时将数据库数据更新到缓存中

- 优点
- 所有的缓存都可以直接命中,不需要查数据库,性能特别高
- 缺点:
- 缓存利用率低:写多读少的场景特别明显,不经常访问数据也在缓存中
- 数据不一致:定时刷新缓存,数据不一致的程度完全取决于定时任务的执行频率
- 适用场景
- 业务体量小,数据库一致性要求不高的业务场景。
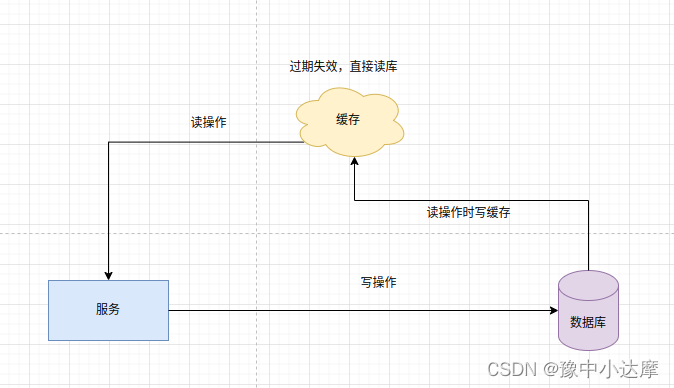
读操作时写缓存
- 写操作时,写数据库
- 读操作时,先读缓存,缓存不存在时读库写缓存(缓存只保留访问的热数据)
- 写入缓存的同时写入失效时间
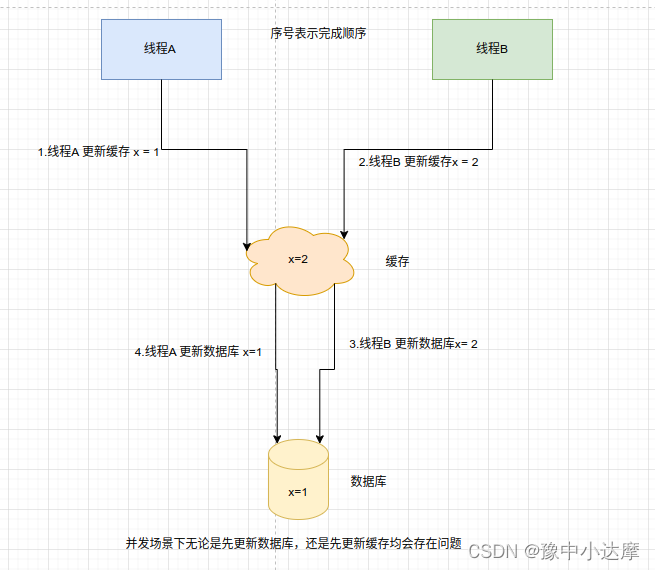
- 先更新缓存,再更新数据库
- 两个步骤不同步导致的问题

- 并发问题
- 两个步骤不同步导致的问题
- 先更新数据库,再更新缓存
- 两个步骤不一致导致的问题
- 并发问题
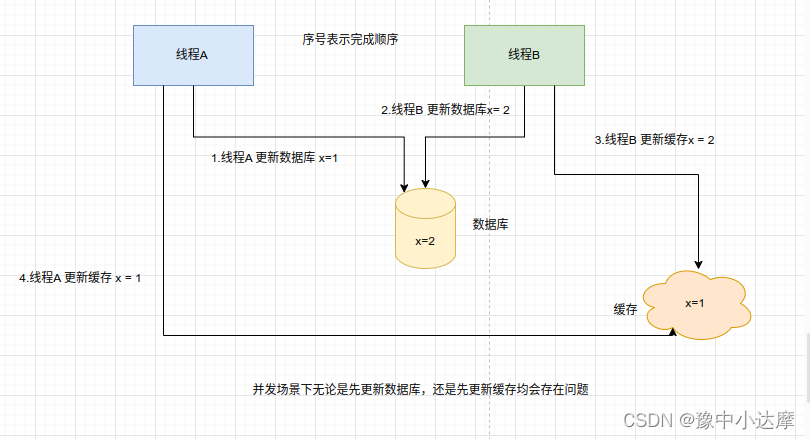
- 两个步骤不一致导致的问题
无论先更新缓存,还是先更新数据库,这种更新操作都会存在数据不一致和并发问题,不仅缓存利用率不高,还会造成机器性能的浪费,所以,可以采用删除缓存的策略
- 先删除缓存,再更新数据库
- 删除更新步骤不一致的问题

- 删除更新步骤不一致的问题
虽然不存在缓存不一致的情况,但是有缓存击穿的风险,可以加锁将读取数据库,写缓存的两个逻辑合并为原子操作。
- 并发问题
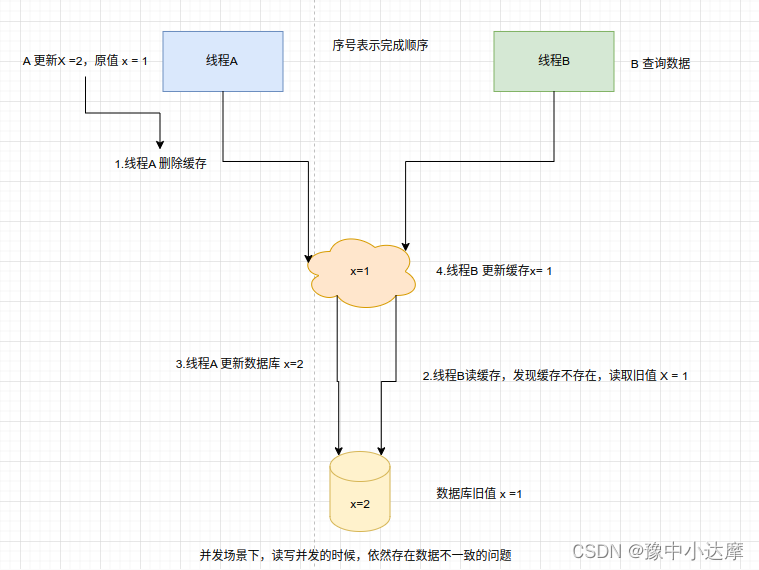
先删除缓存再更新数据库,读写并发时,存在数据库缓存不一致的问题。
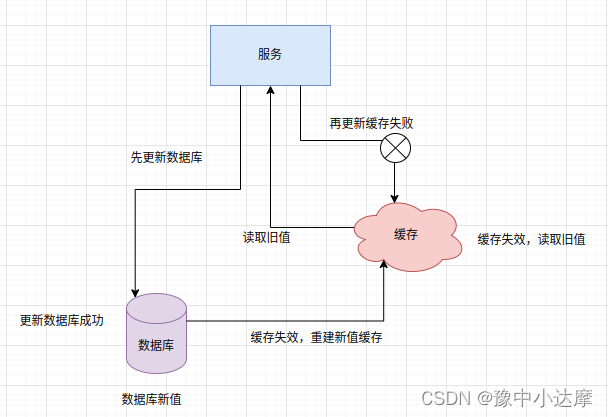
- 先更新数据库,再删除缓存
- 删除更新步骤不一致的问题

- 删除更新步骤不一致的问题
更新完数据库,删除缓存失败之后,导致数据缓存不一致问题
- 并发问题
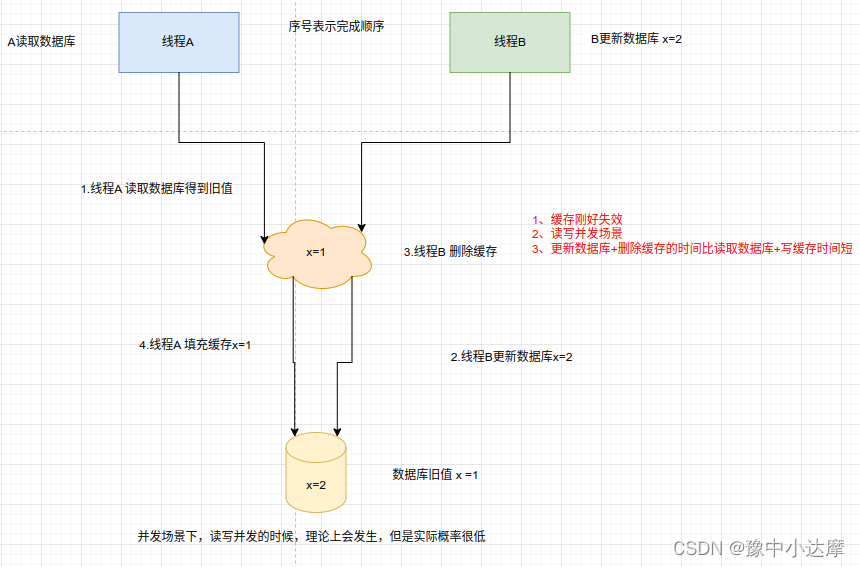
看似理论上会发生的事情,其实概率极低,先更新数据库后删除缓存的方案是可以保证数据一致性的。
如何解决操作缓存,操作数据库两步不一致问题?
- 两步操作,不管哪个先哪个后,后面的失败了都会存在问题
-
常用解决方案就是,重试补偿。
-
重试的缺点
- 依然有失败的几率
- 重试次数过多,占用线程资源,无法服务其他客户端请求。
-
可以使用异步重试
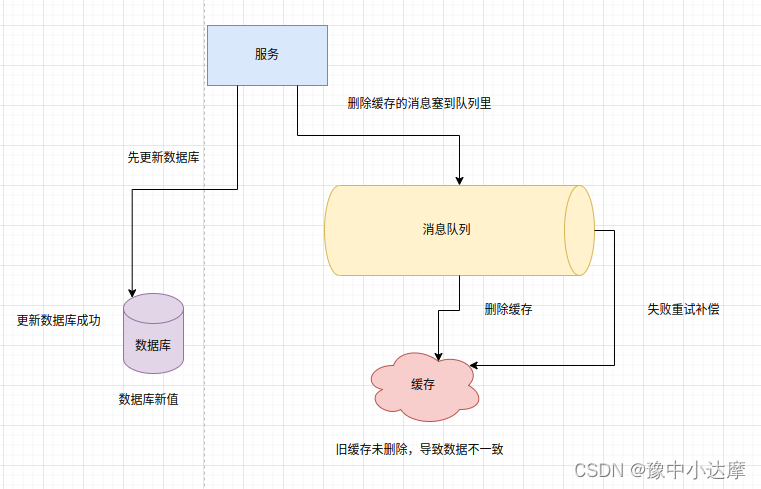
- 使用消息队列异步重试删除缓存
- 消息队列保证可靠性投递
- 消息队列保证消息成功投递
- 项目中一般经常使用消息队列,维护成本没有增加
- 写缓存和写消息队列失败的概率也很小
- 引入消息队列解决两步不同步的问题,比较合适
- 使用消息队列异步重试删除缓存
-
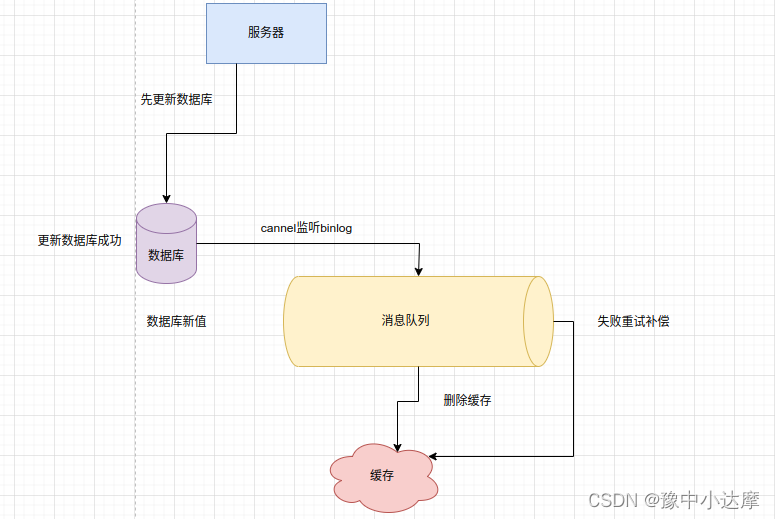
- 订阅数据库binlog操作缓存
- 业务代码中不用操作缓存
- 数据库变更的时候,产生一条binlog,订阅这条binlog去删除对应的缓存
- 不用考虑消息队列写失败的问题(变更成功,一定有binlog)
- 自动投递下有的队列(canel)
- 推荐方案:先更新数据库 再删除缓存,然后使用消息队列或者canel订阅binlog,塞到下游队列的方案。
缓存双删策略
- 先删除缓存,再更新数据库(存在缓存回填旧值)

- 主从架构
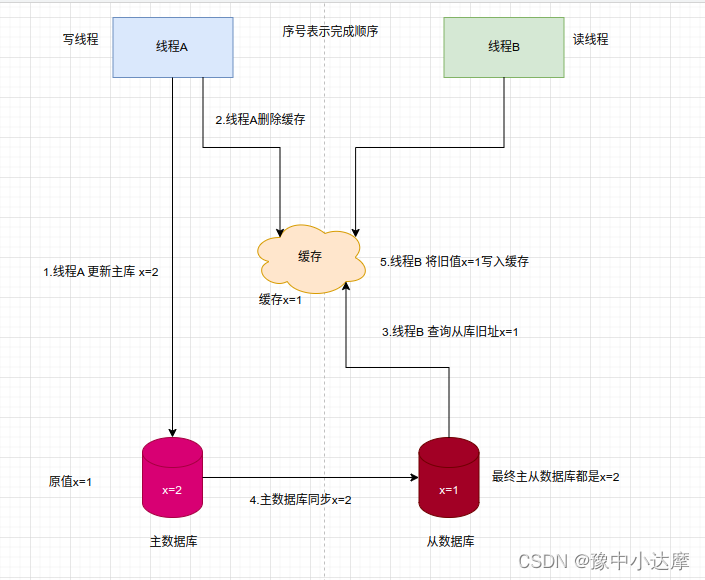
- 以上两种情况都导致读线程,回填了旧值到缓存中,到缓存失效,或者删除之前,读线程读的都是旧的脏数据。
- 解决方案
- 写线程A 休眠或者生成一个延时消息,再删除一次缓存。
- 复杂的生产场景延时时间不太好确定
- 一般针对主从的问题,就是延时时间大于主从复制(或者读线程,读数据库+写入缓存的时间)的时间多个几百毫秒.
- 只能尽可能降低不一致的概率。
- 实际场景中推荐先更新数据库,再删除缓存方案,然后尽量保证主从复制的时间不要太延迟,降低问题的概率
- 写线程A 休眠或者生成一个延时消息,再删除一次缓存。
数据强一致性
- 根据 CAP 和BASE理论,很难做到强一致性,想做到强一致性,可以使用2pc,3pc,paxos等一致性协议。也可以使用分布式锁来实现,但是会付出一定的代价,性能比较差点,违背了增加缓存提高响应的初衷。所以 一旦使用缓存就要做好容忍短期的一致性。
文章来源:https://blog.csdn.net/donkey_xiao/article/details/135405863
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LINUX网络第四章:SSH远程管理
- 一文弄懂kubernetes之Service
- 数据结构之dict类
- 关于在Pycharm解释器中运行代码发现安在Linux终端中安装的包找不到的解决方案
- 程序员跳槽,HR 就喜欢听这样的离职原因。让老实人别再吃亏!
- openGauss学习笔记-179 openGauss 数据库运维-逻辑复制-发布订阅
- 高通8255芯片烧写方法
- 火鸡目标检测数据集VOC格式120张
- Visual Studio 下载安装教程,附安装包和工具,Visual Studio 2022,Visual Studio所有版本都有
- FL Studio水果软件21.2.0中文破解包下载