python爬虫基础
发布时间:2024年01月23日
python爬虫基础
前言
Python爬虫是一种通过编程自动化地获取互联网上的信息的技术。其原理可以分为以下几个步骤:
- 发送HTTP请求: 爬虫首先会通过HTTP或HTTPS协议向目标网站发送请求。这个请求包含了爬虫想要获取的信息,可以是网页的HTML内容、图片、视频等。
- 接收响应: 目标网站接收到请求后,会返回一个HTTP响应。这个响应包含了请求的数据,状态码、头部信息等。爬虫需要解析这个响应来获取所需的信息。
- 解析HTML: 如果爬虫的目标是获取网页上的数据,它需要解析HTML文档。HTML是一种标记语言,包含了网页的结构和内容。爬虫可以使用解析库(如BeautifulSoup、lxml)来从HTML中提取所需的数据。
- 提取数据: 爬虫通过解析HTML文档,可以从中提取出所需的数据,例如链接、文本、图片地址等。提取数据的方式通常是使用选择器(Selector),它是一种用于定位HTML元素的表达式。
- 存储数据: 爬虫获取到的数据可以被存储到本地文件或数据库中,以备后续使用。常见的数据存储格式包括文本文件、JSON、CSV等。
- 处理动态页面: 一些网站使用JavaScript来动态加载内容,这就需要爬虫能够执行JavaScript代码,或者使用带有JavaScript渲染功能的工具(如Selenium、Puppeteer)来获取完整的页面内容。
1、python相关库(BeautifulSoup)
今天主要介绍一下BeautifulSoup模块
BeautifulSoup是一个用于从HTML或XML文档中提取数据的Python库。它的主要作用是解析复杂的HTML或XML文档,并提供了一种简单的方式来浏览文档树、搜索特定的标签、提取数据等。BeautifulSoup的设计目标是让数据提取变得容易、直观,并且具有Pythonic的风格。
2、BeautifulSoup模块的安装
安装命令
pip install bs4
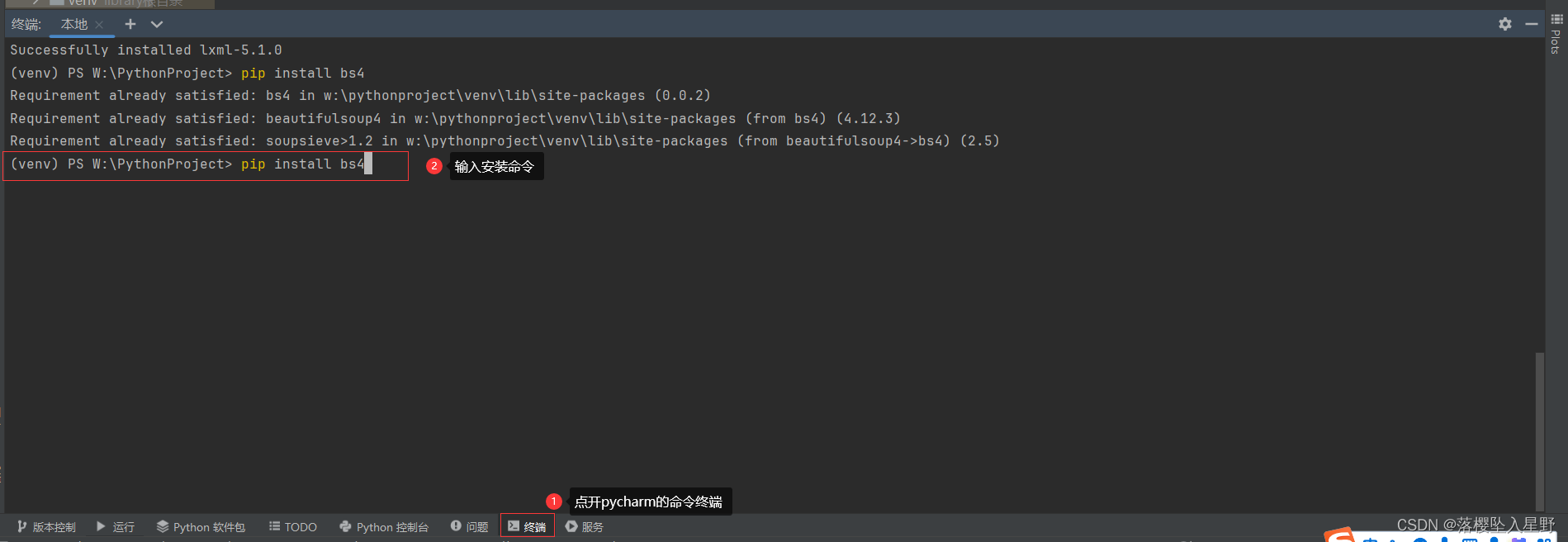
我这里是安装过了,第一次安装会出现suessful

3、BeautifulSoup的使用
3.1 简单的使用(以百度为例)
# coding=utf-8
import requests # 导入请求模块
from bs4 import BeautifulSoup #
# from bs4 import BeautifulSoup 这样导入的目的是从 bs4(Beautiful Soup 4)库中引入 BeautifulSoup 类。这样导入的好处是在代码中使用 BeautifulSoup 类时不需要每次都写出完整的模块路径,简化了代码,提高了可读性。
# 设置要爬取的网站
url = "https://www.baidu.com/"
heder = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 爬取内容
res = requests.get(url, headers=heder) # 这里是去请求网页的内容
# 获取内容
content = res.text # 这里是让爬取的内容以文本的形式打开,同时保存到变量
# 初始化Beatifulsoup
soup = BeautifulSoup(content, 'html.parser')
# 获取标题标签
print(soup.title)
# 如果想要直接获取标题的内容
# print(soup.title.string)
注意:因为百度需要添加请求头才能获取返回的内容,故此处定义了一个heder
请求头可以按以下方式获取
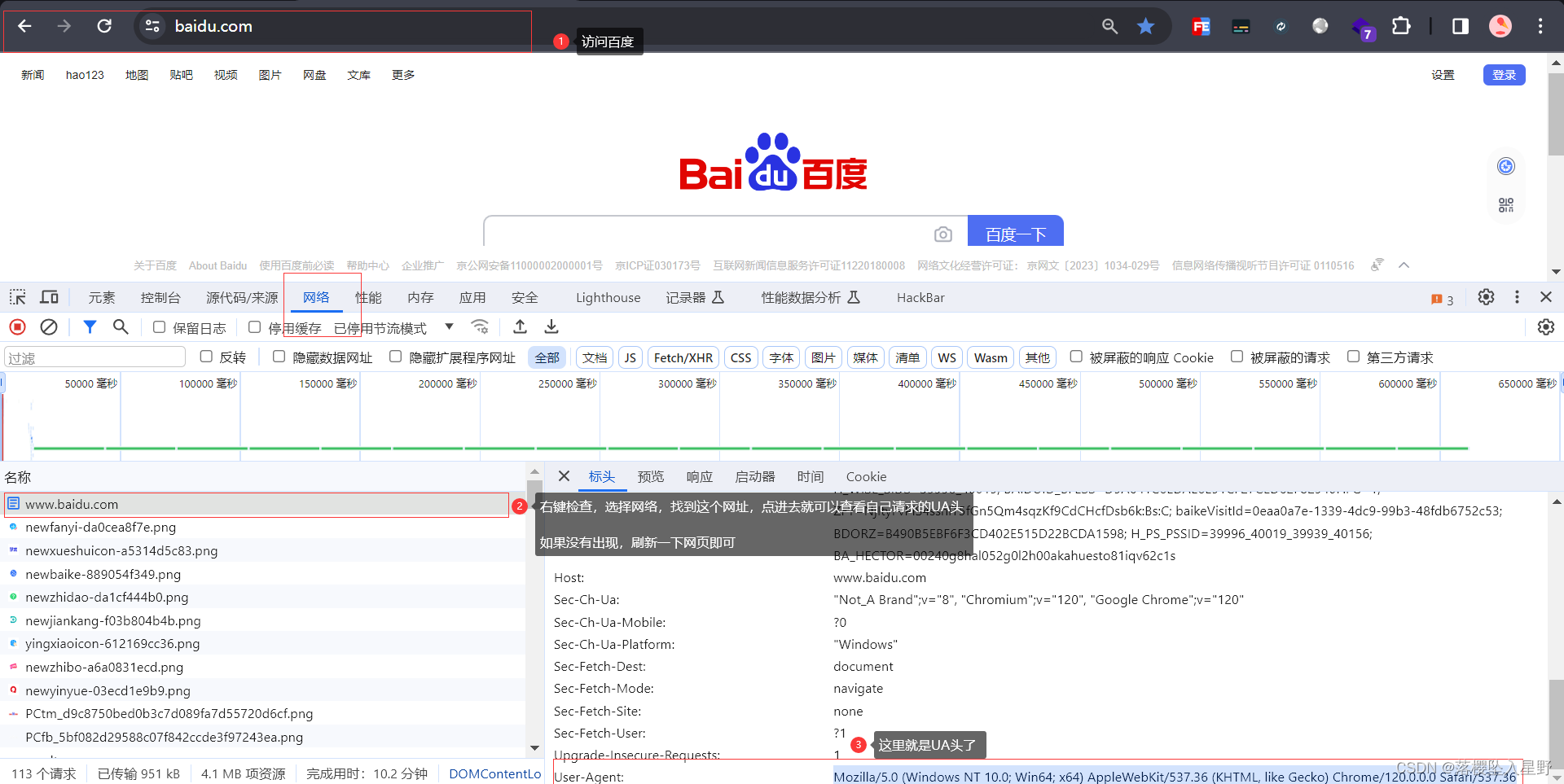
运行结果

3.2 soup.tagName的使用
在BeautifulSoup中,soup.tagName 的语法用于访问解析后的HTML文档中特定HTML标签的第一个出现实例。在这里,soup 是BeautifulSoup对象的引用,而tagName是你想要访问的HTML标签的名称。
它会返回第一个你指定的html标签的内容
这里可以看到百度的第一个a标签是百度首页的
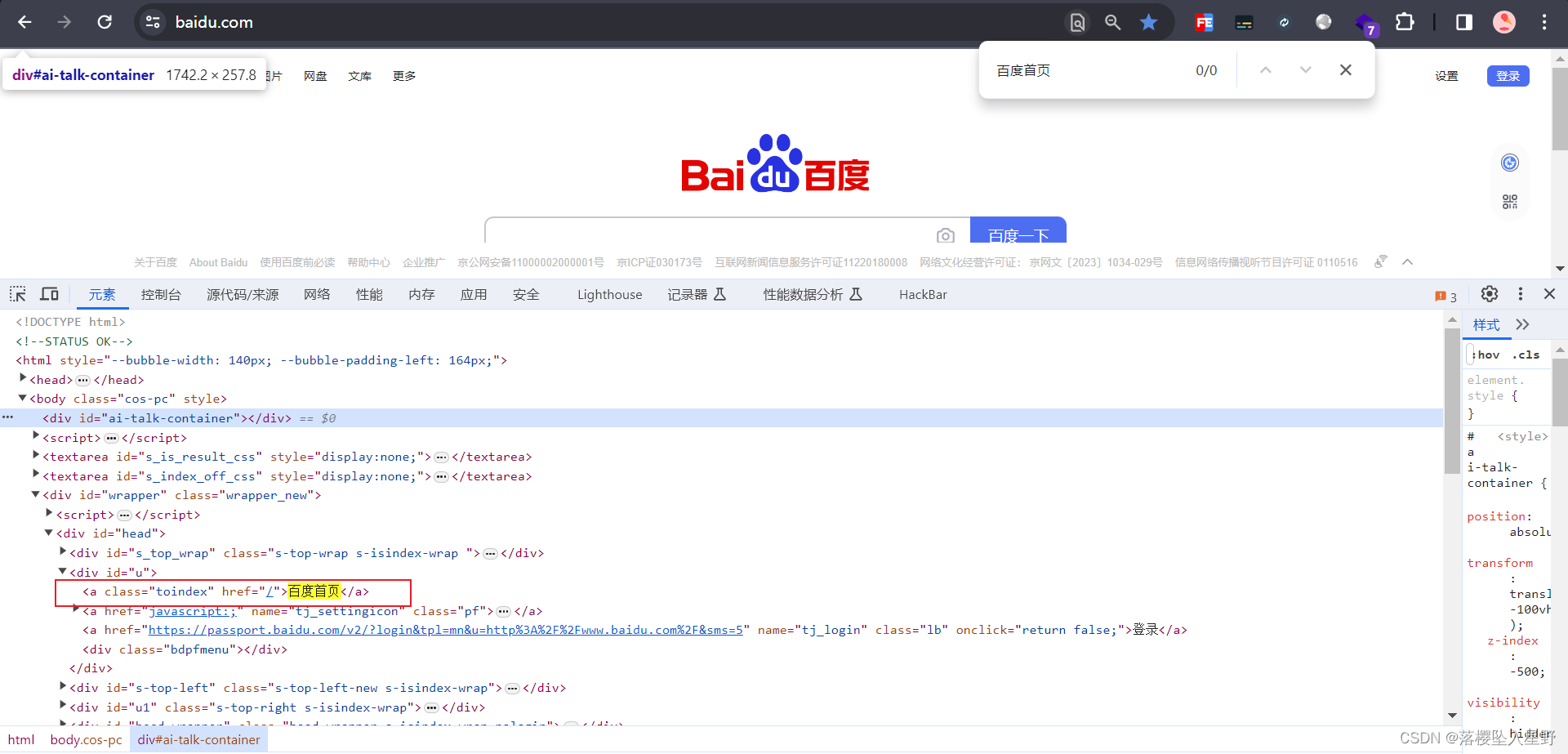
使用soup.tagName
# coding=utf-8
import requests
from bs4 import BeautifulSoup
# 设置要爬取的网站
url = "https://www.baidu.com/"
heder = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 爬取内容
res = requests.get(url, headers=heder)
# 获取内容
content = res.text # 这里是让爬取的内容以文本的形式打开,同时保存到变量
# 初始化Beatifulsoup
soup = BeautifulSoup(content, 'html.parser')
# 获取<a></a>标签第一次出现的地方
# print(soup.tagName)
print(soup.a)
运行结果

3.3 soup.find
soup.find() 是 BeautifulSoup 中用于查找单个标签的方法。它用于按照指定的条件查找文档中的第一个匹配的标签,并返回这个标签的 BeautifulSoup 对象。
查找标签的功能与soup.tagName是一样的,不同的是soup.find拥有丰富的参数,所以可以通过标签的class属性,或者是id属性来查找特定的标签
相关参数
name: 要查找的标签名称,可以是字符串、正则表达式、函数等。attrs: 标签的属性,可以用字典形式表示。recursive: 是否递归查找,默认为 True。string: 标签中的文本内容。kwargs: 其他特定标签属性的关键字参数。
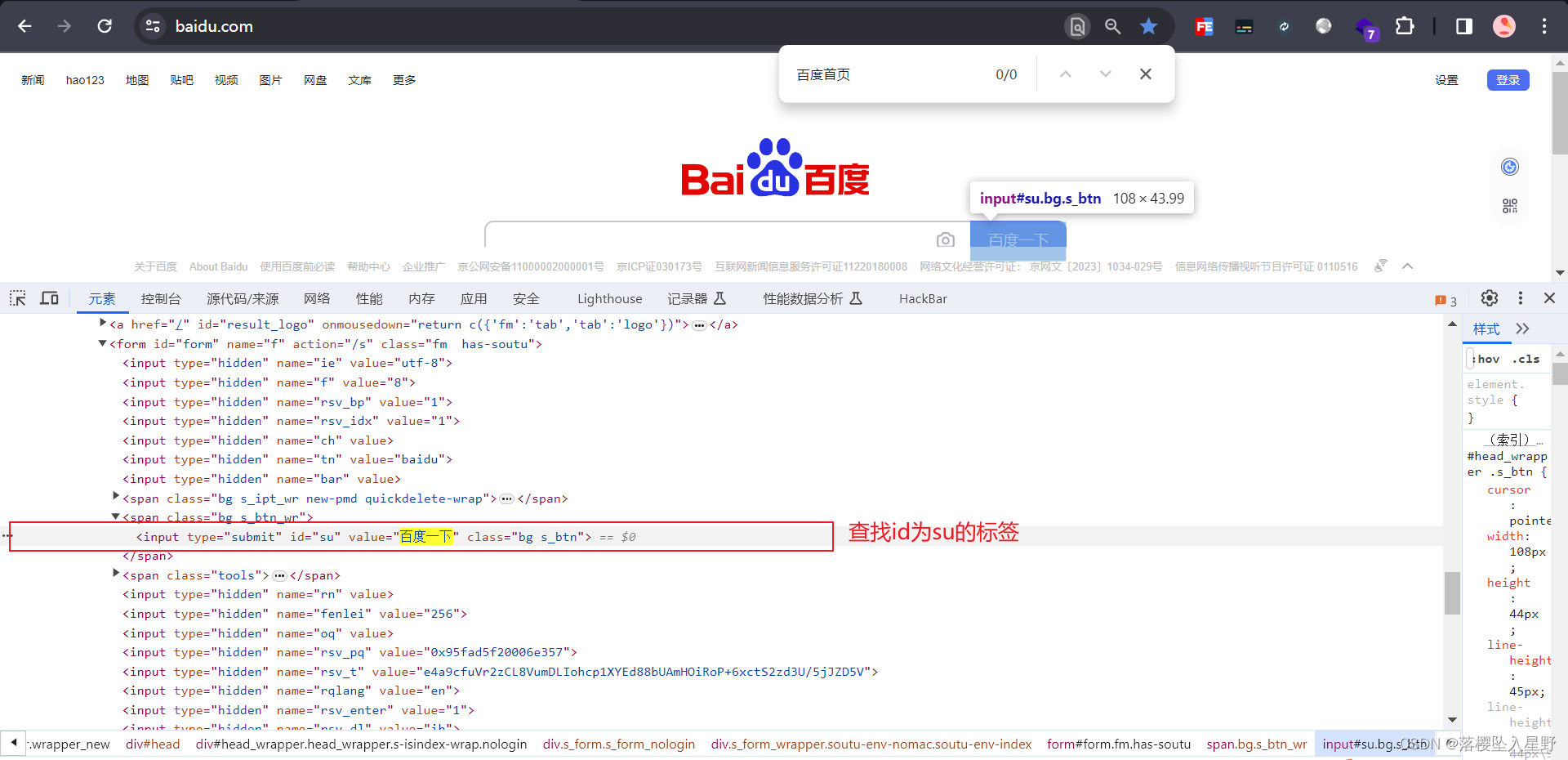
下面演示通过attrs查找
# coding=utf-8
import requests
from bs4 import BeautifulSoup
# 设置要爬取的网站
url = "https://www.baidu.com/"
heder = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 爬取内容
res = requests.get(url, headers=heder)
# 获取内容
content = res.text # 这里是让爬取的内容以文本的形式打开,同时保存到变量
# 初始化Beatifulsoup
soup = BeautifulSoup(content, 'html.parser')
# 获取<a></a>标签第一次出现的地方
print(soup.find('input', attrs={'id': 'su'}))
运行结果

3.4 soup.find_all
该方法返回的是指定标签下面的所有内容,而且是列表的形式;传入的方式是多种多样的。
(1)传入单个标签
# coding=utf-8
import requests
from bs4 import BeautifulSoup
# 设置要爬取的网站
url = "https://www.baidu.com/"
heder = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 爬取内容
res = requests.get(url, headers=heder)
# 获取内容
content = res.text # 这里是让爬取的内容以文本的形式打开,同时保存到变量
# 初始化Beatifulsoup
soup = BeautifulSoup(content, 'html.parser')
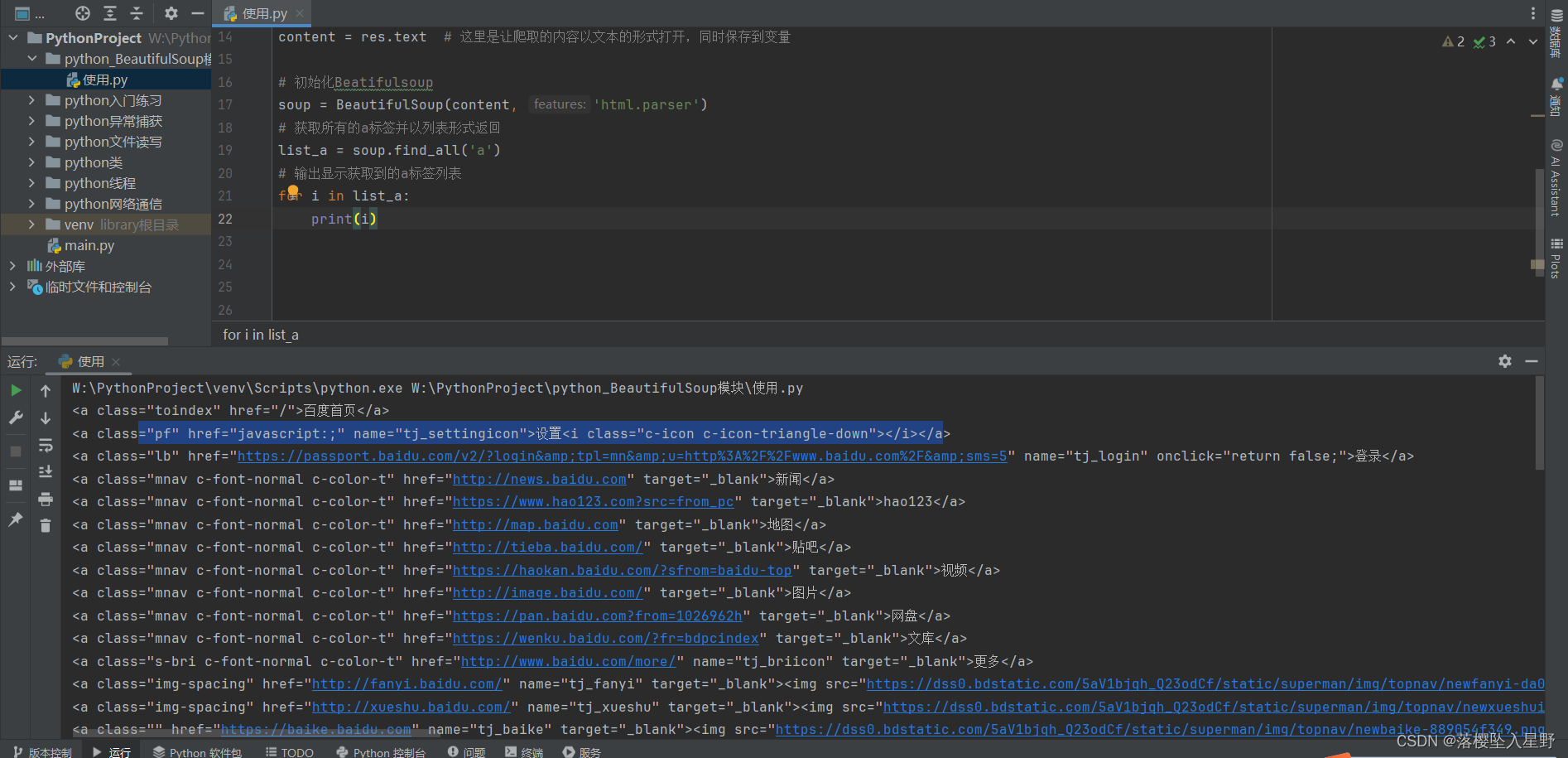
# 获取所有的a标签并以列表形式返回
list_a = soup.find_all('a')
# 输出显示获取到的a标签列表
for i in list_a:
print(i)
运行结果
(2)传入多个标签
# coding=utf-8
import requests
from bs4 import BeautifulSoup
# 设置要爬取的网站
url = "https://www.baidu.com/"
heder = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 爬取内容
res = requests.get(url, headers=heder)
# 获取内容
content = res.text # 这里是让爬取的内容以文本的形式打开,同时保存到变量
# 初始化Beatifulsoup
soup = BeautifulSoup(content, 'html.parser')
# 获取所有的a标签和input标签并以列表形式返回
list_a = soup.find_all('a', 'input')
# 输出显示获取到的a标签列表
for i in list_a:
print(i)
(3)传入正则表达式
万金油表达式
# 找所有的xxx标签: 属性xxx满足对应正则表达式
soup.find_all(name='xxx',attrs={'xxx':re.compile('正则表达式')}
文章来源:https://blog.csdn.net/weixin_59047731/article/details/135786031
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 联盟 | Shoplazza X HelpLook,AI技术助推商业效能增长
- AI数字员工的出现:不是取代,而是让技术更好地服务于人类_光点科技
- 基于SSM的驾校预约管理系统
- Java 第12章 异常 本章作业
- 发明专利、实用新型、外观设计!简阳市专利申请需要准备哪些资料?
- App应用如何在应用市场获得更多下载量?
- 盘点好用内容合规监测工具
- fmincon函数求解非线性超越方程的学习记录
- 霞多丽葡萄酒有什么惊喜之初?
- 谷达冠楠:抖店创业初期需要注意哪些