大模型(LLM)推理加速之KV Cache技术
前言
在学习Key-Value Cache(kv cache),读者需要熟悉Transformer架构,最好能够懂得分析transformer模型的参数量、计算量、中间激活、KV cache。本文不会再对Transformer架构做赘述。
KV cache原理
在如GPT等大模型的推理当中,一次推理只生成一个token,输出的token会与输入tokens拼接在一起,作为下一次推理的输入,每个token都需要依赖之前生成的token,这个重要的特性就是自回归性(autoregressive)。
然而随着推理的进行,输入的tokens会越变越长,导致推理FLOPs(计算量,如果读过前言中的那篇文章,可以知道推理的
F
L
O
P
s
=
2
?
模型参数量
?
t
o
k
e
n
数)
FLOPs = 2 * 模型参数量 * token数)
FLOPs=2?模型参数量?token数)随之增大。这会严重影响推理的速度。
由于在推理过程中,第
i
i
i次注意力的计算都会重复计算前
i
?
1
i-1
i?1个token的
K
K
K和
V
V
V值,故KV Cache的出发点就在这里,缓存当前轮可重复利用的
K
K
K和
V
V
V值,下一轮计算时直接读取缓存结果。
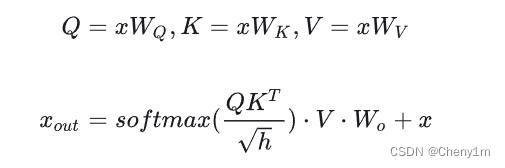
具体细节
- 原来的推理过程:假设输入是 [ b , s , h ] [b,s,h] [b,s,h](batchsize,seqencelen,hidden), K , Q , V K,Q,V K,Q,V矩阵是 [ h , h ] [h,h] [h,h],那么每次的计算结果就 [ b , s , h ] [b,s,h] [b,s,h]
- 使用KV cache: 每次输出不再 C o n c a t Concat Concat给之前的输出(因为每次计算依据缓存过之前token的 K , V K,V K,V值),所以输入是 [ b , 1 , h ] [b,1,h] [b,1,h],那么每次计算结果就是 [ b , 1 , h ] [b,1,h] [b,1,h],在此刻再与之前已经计算过的shape为 [ b , s ? 1 , h ] [b,s-1,h] [b,s?1,h]的 K , V K,V K,V值分别进行 C o n c a t Concat Concat即可得到与原来推理过程相同的结果。但是每次没有重复计算前 i ? 1 i-1 i?1个token的 K K K和 V V V值,减少了推理计算量,提升了推理速度。
更多
如果还有细节理解不到位的地方可以参考大模型推理性能优化之KV Cache解读
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JS数组API: push、pop 、unshift 、splice、filter、reduce、concat、 forEach...
- 鸿蒙开发-UI-布局-弹性布局
- Python基础(二十二、自定义模块和包)
- Camunda Asynchronous continuations
- 第四章练习题补充
- 超实用!微信备份聊天记录和批量导出好友
- 圣诞节快乐
- <蓝桥杯软件赛>零基础备赛20周--第13周--DFS剪枝
- 【IDEA】Idea pull 项目报错,提示 has no tracked branch
- 力扣labuladong一刷day50天单调栈