ES 之索引和文档
本文主要介绍ES中的数据组成结构单元。
一、文档(Document)
1、概念
-
ES的数据存储单元是面向文档的,文档是所有数据存储,搜索的最小单元。
你可以把ES中的文档对应成mysql中的一条条数据记录。到时候你存进ES的数据就是一个个文档。 -
文档存入ES是序列化成为JSON格式的。
众所周知,json对象是由字段组成的。
每个字段都有对应的字段类型,包括字符串,数字,布尔,日期,二进制,范围类型。 -
每个文档都有一个Unique ID,也就是唯一标识,可以对应Mysql表中的主键。
ES中这个ID可以自己指定,也可以由ES自动生成。我们上一篇导入logstash配置的时候那个id就是指定的唯一标识键。
2、数据结构
一个JSON文档包含了一系列的字段,类似数据库中表的各个字段属性列。
JSON文档的格式灵活,不需要你强制的预先定义格式。
其中字段的类型可以人为指定,或者是通过ES自动推算。
支持数组格式,支持数据的嵌套。
3、文档的元数据
随便去Kibana中查一个数据如下:
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "5233",
"_score" : 1.0,
"_source" : {
"@version" : "1",
"title" : "Road to Utopia",
"id" : "5233",
"year" : 1946,
"genre" : [
"Comedy"
]
}
}
我们看到有这么几个东西组成:这几个组成就是文档的一个元数据。
- _index:表示这个文档数据属于哪个索引,文档存储的地方
- _type:表示文档所属的类型,类型7.0基本没意义了,都是_doc.文档代表的对象的类
- _id:表示这个文档的唯一标识,也就是上面说的类似主键。文档的唯一标识.id仅仅是一个字符串,它与_index和_type组合时,就可以在Elasticsearch中唯一标识一个文档。当创建一个文档,你可以自定义_id,也可以让Elasticsearch帮你自动生成
- _score:表示这个文档在本次检索中的相关性打分,这个在全文检索中有重要作用。
- _source:这里面放的就是你文档的真实内容。就是那个json文档,文档中有一个@version是文档的版本,这个版本每次修改都会递增,利用这个可以做乐观锁,CAS在并发修改的时候控制线程安全。
而且也看到文档json中有字符串,有时间,还有个数组。各种类型都有,json数据格式的灵活性得以展示。
二、索引(index)
1、概念介绍
索引是ElasticSearch存放数据的地方,可以理解为关系型数据库中的一个数据库。事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。然而,这只是一些内部细节——我们的程序完全不用关心分片。对于我们的程序而言,文档存储在索引(index)中。剩下的细节由Elasticsearch关心既可。(索引的名字必须是全部小写,不能以下划线开头,不能包含逗号)
先使用语句查看一下索引的结构。
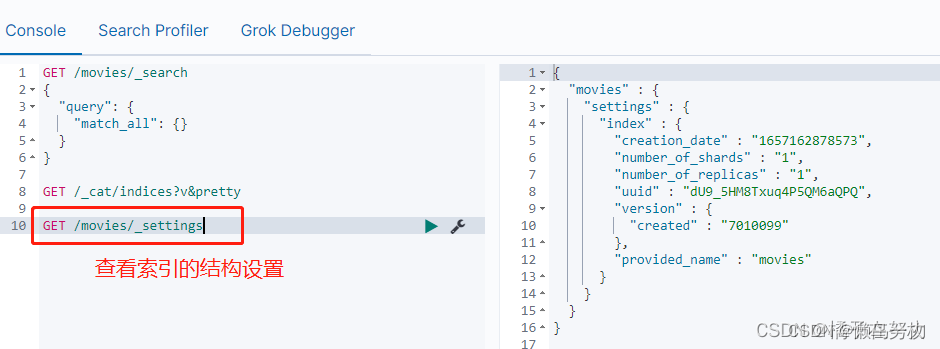
我们看到这个索引的一个结构组成。
-
index也就是索引是文档的容器,是一类文档的集合。你可以理解为Mysql中的表这个概念。
- 每个索引都有自己的一个mapping定义,用于定义包含文档的字段名和字段类型,你可以对应理解为mysql中的表结构定义。定义好文档字段的类型,名称。
- shard体现的存储的维度,索引中的数据会分散在shard分片上。
-
索引的Mapping和Settings
- Mapping定义的是文档字段的类型,就像Mysql的字段类型。表结构。
- Setting定义不同的数据分布,比如在那个分片,去哪个节点这种。后续看。
2. 语境理解
索引在不同的语境中是不同的意思。
在ES中当你说你索引一个文档,就是把这个文档插入ES。
当你说一个索引,那就是名词,就是一个索引结构。
在MYSQL中可能是B+树索引。ES中还有倒排索引。
3. 索引创建原则
类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。如果你把比如product,sales,human resource(employee),全都放在一个大的index里面,比如说company index,不合适的。
index中包含了很多类似的document:类似是什么意思,其实指的就是说,这些document的fields很大一部分是相同的,你说你放了3个document,每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。
索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
三、Type(类型)
ES在7.0之前是有type这个概念的,一个Index可以设置多个types,那时候Index类似数据库,typel类似表,这个组成。
6.0开始的时候type就被逐步废弃。7.0开始,一个索引只有一个Type就是_doc,也就是一个库一个表,这时候库就是表了,这时候我们就说一个Index类似一个表。
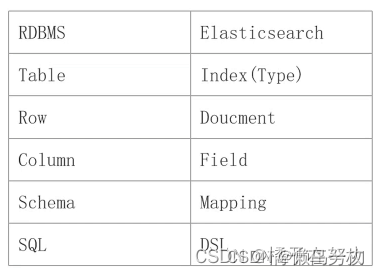
此时es的结构和mysql的结构就可以用下面这个表格做对应理解,其实不是那么契合的。就是帮助理解而已。
四、索引 Rest Api
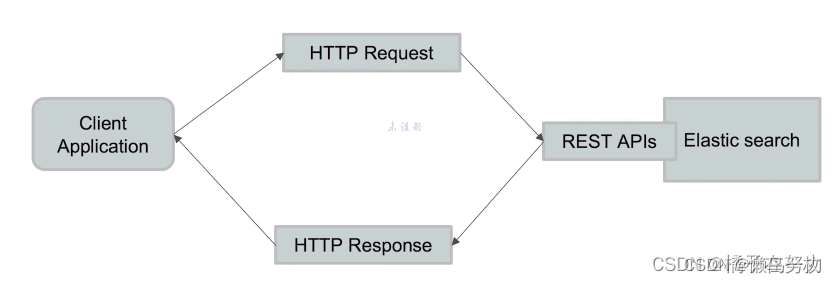
ES的检索提供了完整的rest的api调用来实现。
1. 查看索引的设置
GET /movies/_settings
在这个管理里面可以看到当前ES的所有的索引可以查看索引的详细信息。
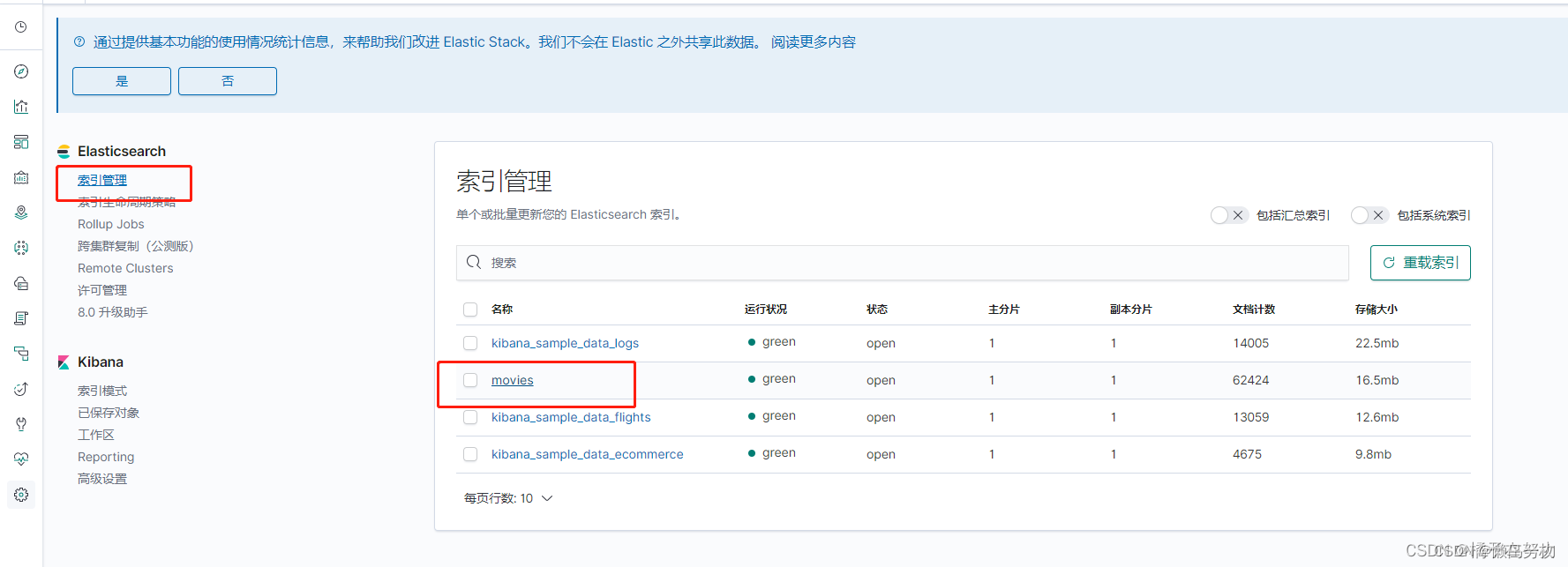
点击索引进去看到详细信息。
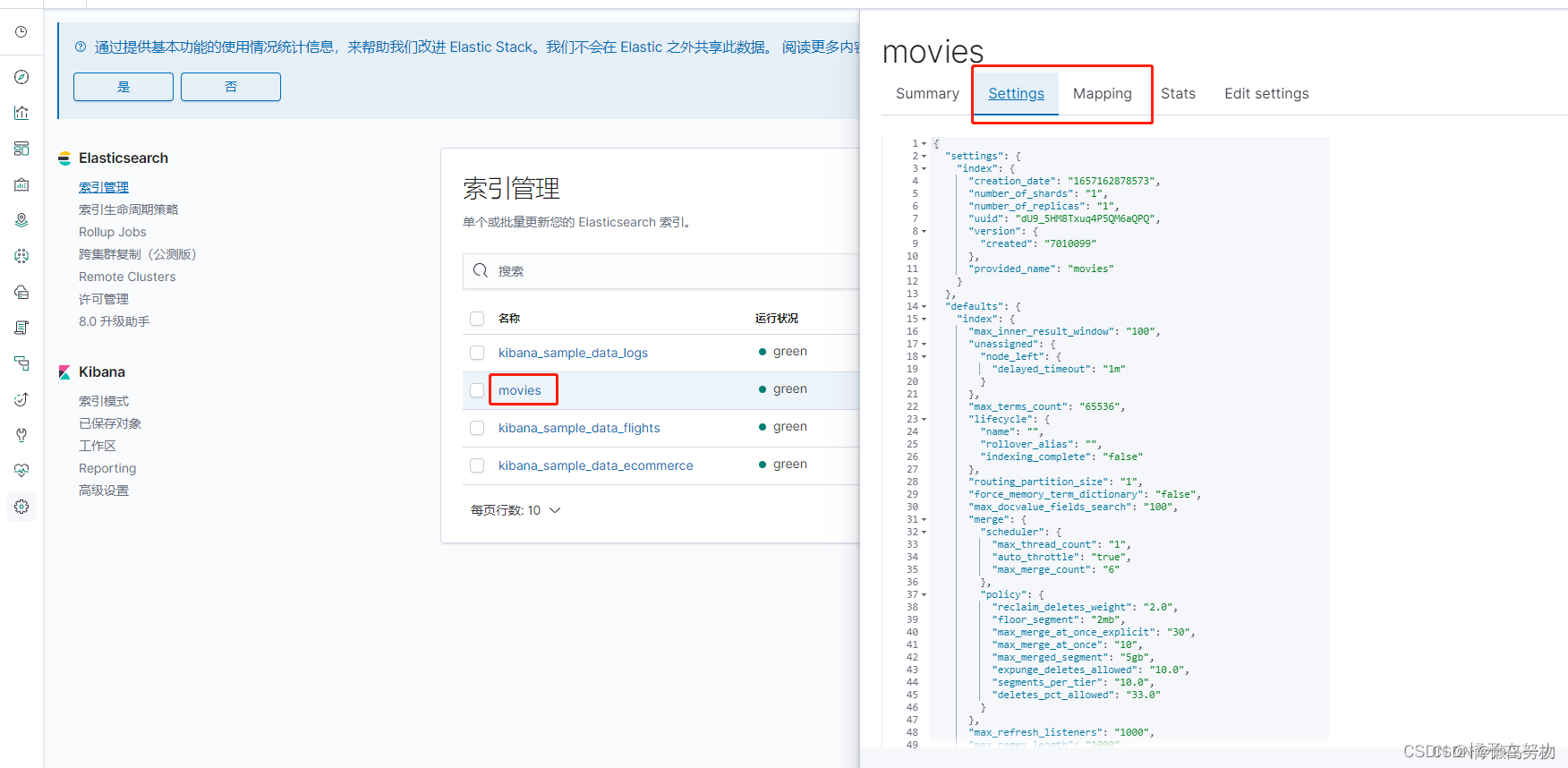
2、索引操作 rest api
# 查询ES索引下的数据量
GET _cat/indices/movies?v
# 查询ES索引下的mapping关系
GET /movies/_mapping
# 查询ES当前环境下索引对应的数据量
GET _cat/indices?v
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!