基于深度学习算法的垃圾分类图像识别研究
收藏和点赞,您的关注是我创作的动力
概要
??在科技发达、智能时代中,深度学习、机器学习以及人工智能成为了高频词。它们看似深不可测,但是又离不开我们的生活。深度学习和机器学习是一种技术、而人工智能一种是一种体现。使用深度学习和机器技术,使机器拥有人的某种大脑结构从而来实现人的某种行为,它不仅解决了很多即无聊又繁琐的工作,从而解放了很多工人每天反复并且厌倦的动作节,节省了大量的时间;而且它在每件工作当中,能够做到比人更加精确,并且不会像人类一样受感情甚至环境的影响导致工作的效率以及成品的达标率降低。正因为人工智能给人们带来了出乎意料的惊喜以及数不胜数的方便,并且人工智能能够满足人类的懒惰性,所以人类对深度学习、机器学习以及人工智能的需求也越来越多。在这种人工智能急剧膨胀的形势下,深度学习与机器学习成了垃圾分类的主要推力。众所周知,垃圾是人类既厌恶又无法摆脱的物体,而垃圾则是铺天盖地层出叠见地出现在我们地视野中,解决垃圾问题给全球带了巨大的挑战。想要有效处理垃圾,垃圾分类是必然的结果,然而垃圾分类过程又是一件既繁琐又耗时的事,而且使用人工进行垃圾分类它不仅需要耗费大量的人工而且它还会大大降低准确率。这时人工智能、深度学习就起了重要的作用。
本文正是研究深度学习算法的垃圾分类图像识别。论述多种深度学习算法及网络结构的图像识别处理原理,分析深度学习在图像识别中的突出优势,并且提出垃圾分类在现实社会中面临的问题与挑战。在综合了解研究后,深入探讨使用深度学习算法的卷积神经网络,在大量的有效图像数据集的训练过程中是如何增加一种全新的隐藏层,并且使用这种增加卷积层的方法来得出更高层次的特征提取从而让机器自动提取特征来实现图像的识别。
关键词: 深度学习 图像识别 垃圾分类 机器学习 人工智能
一、研究背景与意义
1.1.1研究背景
??在人类还没有意识到垃圾对我们的生活饮食、身体健康,社会环境等会造成极大影响的时候,人们把对自己没有使用价值的外包装、砖瓦陶瓷、剩菜剩饭、荧光灯管等垃圾都随意丢弃,甚至在各街道上的垃圾也是随眼可见。随着人们这种肆无忌惮随意扔垃圾的行为,大自然至今给我们带来惨痛的教训。根据数据显示,在一个人口密集的中国每年生产的垃圾总数量高达10亿吨,成为了一个垃圾成产的超级大国。然而在人类没有正确对待垃圾处理的问题中,导致了堆积成山的垃圾形成有剧毒的腐烂物,和有害的脏水渗透到地下造成严重的水资源污染,这些有害的腐蚀物品和水不仅侵蚀人类的身体,甚至某些地区因为这些有害垃圾导致很多村民得了癌症,形成了癌症村。
垃圾对人类造成如此大的危害,所以如何处理垃圾问题成了国家与人民刻不容缓的重要任务,也是我们义不容辞的责任。在数量如此庞大的垃圾里,实行垃圾分类是最有效的方法,只有让更多的垃圾有效的循环使用,变成有价值的垃圾,从而才能达到减少垃圾降低危害的目的。但垃圾分类是一项大工程,如果垃圾分类只有环保工人在实行,那只有微乎其微的作用,所以垃圾分类,人人有责。本课题就是为了让大家能够快速并准确的对垃圾进行分类做出的一个垃圾分类图像识别。设计采取六种不同的垃圾类型图片,通过使用深度学习算法的最火热的AlexNet卷积神经网络结构,该结构由5层卷积层和3层全连接层组成。其中卷积层用于提取图像特征,全连接层用于逻辑处理。通过网络训练从而使得机器得到一个能够自动识别垃圾的设计。本研究不仅能够提高垃圾分类的准确率与效率,并且可让人们能够简单方便地学习垃圾对应属于的类型。
1.1.2研究目的
??实行垃圾分类是生态文明,保护环境的重要环节。简单粗暴的垃圾焚烧、垃圾填埋、垃圾堆放等等都不仅会导致严重的环境污染还会占用土地资源,甚至严重的影响人的身体健康,然而实行垃圾分类,它可以弃废为宝:把纸箱,塑料,金属,布料等可回收垃圾进行分拣、加工、打包等步骤就成为了新的衣服,窗帘,塑料箱等新的商品进行销售;把剩菜剩饭、腐烂水果等厨余垃圾经过预处理分成油脂、污水和残渣等,其中油脂运到油脂加工厂进一步加工,油脂加工生成的生物柴油可用来使用在汽车上做燃料。污水排到污水处理站经过处理后再排放,降低水资源的污染。而残渣可以进行发酵产出沼气可用来发电,发酵后的残渣还可以作为有机营养肥料,助于植物的生长;最终有害的电池、灯泡、水银、化妆品等有害垃圾,还会进一步分为有无作用垃圾,有用的垃圾要进行深度的加工,无用的垃圾才被拉到一个专门设置过的填埋场进行填埋。这一系列都是垃圾分类的重要处理过程,显而易见,垃圾分类的实施不仅达到资源的循环利用,还可以减轻资源紧缺的重要问题,进行垃圾分类还可以提高人类的的素质素养,以及价值观念,让社会上都养成勤俭节约的作风,学会节约资源,利用资源。
??然而要全面推广垃圾分类,人类必须要了解垃圾所对应的类型。本课题的垃圾分类图像识别就是解决人类对垃圾分类的疑惑。人们可以通过垃圾图片及摄影可得出垃圾类型,从而学习分类垃圾以及对垃圾的正确投放。因此,此课题的设计研究对国家社会以及社会环境有着非常积极的作用。
1.1.3研究意义
??通过这次课题的设计与研究,深深的认识到垃圾对我们人类带来的巨大的影响,为自己以前做过乱扔垃圾的行为感到十分的惭愧。在研究过程中,不断地改变了自己对垃圾的价值观,提高了自己的探究能力以及专业能力。本设计对垃圾图像或者用摄像头对垃圾进行识别,有助于使用者能够通过最简便的方法来得知垃圾的类型并且提高投放垃圾的准确率,可降低环卫工人的工作量,加快社会环境的环保。此研究还可对社会提供借鉴价值,推广实施垃圾分类,营造美好环保家园。由此可见,本次研究的深度学习算法垃圾分类图像识别不能进对个人,社会,国家都有着非常大的意义,是一个值得探究的课题。
二、项目技术理论
2.1开发工具
?? Microsoft VS Code,通常被简称为VS Code或VSC。它是一个非常强大的工具并且可跨三大平台运行,Window、Linux和Mac。VS Code可以满足用户根据各自喜好编辑出心目中最完美的专属编译器。不仅JavaScript,TypeScript,Node.js都是VS Code所支持的,而且在各大语言里提供富裕的运行时与扩展库,如Python,C++,C#,PHP等语言。对于一个程序员来说,VS Code能达到他们心目中的免费,高效,开源,轻便,这是完全取胜于atom,webstorm和MyEclipse等开发工具。在2019年Jupyter增加在VS Code的功能里,再也不需要用插件而且可以直接运行调试,比PyCharm更简便,更轻捷,所以对于Python学者来说VS Code又比PyCharm更胜一筹。
2.2深度学习
??众所周知,深度学习是人工智能的一门热技术,它来源于机器学习,是机器学习的新创作,新发展。深度学习参照人的大脑神经元结构,将数据的输入模仿成大脑神经元的树突接收外界信息,数据的加权求和过程仿照神经元的细胞核将收到的信息进行加工,深度学习的激活函数仿照神经元的轴突运输信息,再通过突触输出感知信息。数据从输入到输出相当于一个完整的神经元从感知信息到头脑获取信息。在深度学习中经常把多个单一的神经元组合在一起,上一个神经元的输出作为下一个神经元的输入,如此类推,最终达到只剩一头一尾的输入和输出点,这样构成的结构就成为神经网络结构,其中输入点和输出点中间层都叫做隐含层。与机器学习相比深度学习不同的特征是无监督学习,它不需要人给予学习的特征,只要有一批数据,深度学习能够自己根据数据通过多层神经网络结构反复处理找出最具有代表性的特征,继而来对新数据做出判断给出正确结果。在神经元的基础上增加深度,根据现状的大数据与云计算研究出来的一系列算法在现实生活的应用起到非常大的作用,如现今的自然语言处理,语音识别和图像处理等这些最为广泛的应用都离不开我们深度学习的神经网络。
2.3人工智能
??人工智能可在中间分为两个词语,“人工”和“智能”,可译为人工制造,人工生产和知识,意识,能力。所以人工智能即是人工制造出有智慧有能力并且可以仿照人的思维过程的机器来解决现今较为复杂的事情。要实现高级人工智能,我们需要用海量优质并有效的数据,在优秀的算法中让机器自行反复强化印象就能让机器更有效率产出满意的结果,所以数据,算法和云计算环境是人工智能中心索要。但想要让机器构造出一定的人脑思维,那涉及的学课不单单是计算机,心理、推力等学课也是较为重要的一部分。在大数据急速发展的时代,智能机器替代人类完成复杂的任务,而且比人类更为准确,更为快速,这就是为什么人工智能在当代为何如此火爆的原因,这也是人工智能的研究价值所在。
2.4图像识别
??图像识别通过大数据技术对图像预处理、特征提取,然后训练得出模型就可以对目标进行识别。在人类中的图像识别中,人们根据图像反应到我们感官的信息,然后大脑自动进行处理,帅选,认识,储存对图像进行认知和再认的过程就为人类的图像识别。在人工智能的图像识别中,它与人类的图像识别相似,参照人的大脑结果,用深度学习算法对新输入的数据进行特征处理,训练构成一个模板,当再有数据输入时候,数据图像与已存在的模板相符,那么机器就能把图像识别,这就称为机器的图像识别。
三、深度学习算法模型
??深度学习算法结合数据的多个输入输出构成的隐藏层就是深度学习算法的模型。要想得到一个最有效的算法模型,海量的数据训练和多层的神经网络是数据特征提取的重要关键,只有拥有庞大完美的数据集再结合一个优秀的算法就可以得到一个准确率高、识别速度快的模型。深度学习仿照人脑通过多个神经元以层级的方式传递提取特征,所以深度学习算法也是通过多层的神经网络来学习传递并得出最有效的特征。本章节就是研究分析多种深度学习算法的网络结构的构建与图像识别的关联知识。
3.1自动编码神经网络
3.1.1自动编码器
??自动编码器是无监督的神经网络模型。既然有无监督学习存在,那相对应的有监督学习同理也存在。所谓有监督学习,其实就是数据包括了数据特征与数据标签。一般而言,有监督学习就是给定机器数据以及数据标签,让机器自动把数据的特征与相对应的数据标签联合起来,最终达到机器能够从一个无标签的数据中反馈出一个正确的标签结果。而相对应的无监督学习数据是没有给定标签的,需要机器根据数据的内在特征把数据规划分类,找出规律。其无监督学习一般用在聚类、密度估计与异常检测应用中。实际构成自动编码器主要有两部分。第一部分根据无监督学习来训练网络去除噪声从而使得数据得以降维,此过程也叫做编码过程;第二部分将编码得出的数据重新构造成原始状态的数据,此过程叫做解码过程。如下图3.1所示:
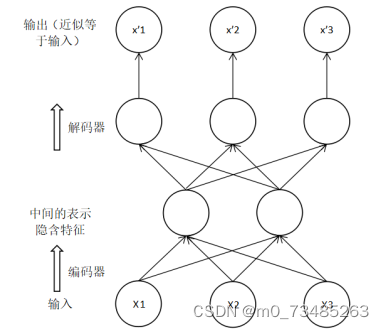
图3.1 自动编码器过程图
??由上图的编码过程可知,若当把x1,x2,x3三个数据作为自动编码的输入数据,则三个数据经过编码器就可以得出一个整体数据的隐含特征,隐含特征指的是在原始数据中挑出最具有代表性的特征,其隐含特征的数据也称为压缩数据。然后压缩数据通过解码器就得到和原始数据相似并且与原始数据维度相同的重构数据x1’,x2’,x3’。
??如今把原来数据经过编码解码得出的重构数据在自动编码器中较为少用。目前较为有用的是数据经过编码器得出的压缩数据。压缩数据主要用途在两个方面,一个用途是用自动编码器的方法把数据经过编码器得出的压缩数据,此数据的维度是比原来数据要低,起到去除噪声的作用。去除噪声的数据主要包含数据中最主要的特征。所以编码器可以用在有监督学习的应用中,因为在目前有监督学习需要的是带有标签的数据,而此类数据的数据量较为少数。自动编码器可以提取大量没标签数据的特征,然后将此数据与特征送到有监督学习中使用,这是体现自动编码器的特征提取的功能。另外,编码器还便于可视化的处理,类似于PCA和主成分分析法将数据降维得到压缩的数据图像。
3.1.2变分自动编码器
??如何重构原始输入的数据是变分自动编码器研究所在。我们从3.1.1节得知在自动编码器中间层的隐含特征数据可以重构原始数据,在此我们定义隐含特征数据为Z,因此我们可以在隐含特征Z中加入满足某种分布的随机因素就可以重构出想要的数据,如下图3.2变分自动编码器模型所示,这种模型简称VAE。
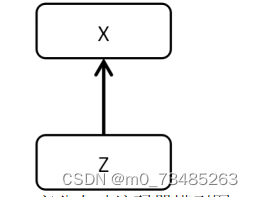
图3.2 变分自动编码器模型图
??这种模型一般作用于数据的自动生成。在自动编码器模型的训练结束后,我们可分别在经验分布和解码器中可得出潜在变量与新的样本数据。变分自动编码器的X由潜在并不可观测的隐含变量Z生成,若生成的数据X是图像,那么Z则是用于生成X图像的潜在属性。所以数据生成过程由Z的构成和Z变换成X的过程两大步骤组成。将给定的数据X传给编码器网络,就可以得到给定X情况下Z的分布,然后根据Z的分布进行采样得出演变量样本Z,然后将Z传递给解码器网络,通过解码器网络可以获得在给定Z的条件下X分布的两个参数,这样我们就可以从中采样得出最终的数据X。训练完毕变分自动编码器后我们只需要解码器进行生成数据。在生成数据中先对Z在标准正态分布进行采样来生成新的数据。这种变分自动编码器一般用于图像生成,可以使用训练数据通过变分自动编码器得出新的的数据而且比训练数据效果更为好看的图片。
3.1.3生成对抗网络
??生成对抗网络现今一般用在辨别图像真假的应用中,它就像一个鉴定师鉴定图画的真迹与假迹。在这种对抗的形势下,仿制师和鉴定师的技术也就不断地相互促进,不断提高技术水平。那么仿制师和鉴定师是如何相辅相成的呢?
??仿制师在生成对抗网络中对应的是生成器。显然,生成器的作用是创建伪造图像,其目标是让判别器无法鉴定真假。其生成器的模型一般是从均匀分布和高斯分布的随机噪声中生成图像。
??鉴定师在生成对抗网络中对应的是判别器。显然,判别器的作用是确定给定的图像是否为真实,判别器用来辨别图片是生成于生成器还是从数据集中选取的真实图片。
??一开始生成器模型与判别器模型都没有经过训练,然后两个模型在训练中竞争为了脱颖而出。生成模型将产出图像,其图片越为接近真实图片证明训练得越好,以成功欺骗判别模型为目标,而判别模型就对生成模型生成的图片进行判断是否为真。在这种对抗的环境下训练,两者模型水平达到越来越高,最终趋于一个稳定。这种就是生成图片的对抗网络过程,同时这种对抗网络也可以用在生成文本的应用中。在生成对抗网络的网络模型没有规定的限制,可以用多层感知机、卷积神经网络、自动编码器等网络结构。
3.2受限波尔兹曼机
??受限波尔兹曼机简称RMB,在名字上来看波尔兹曼机就是一个马尔科夫随机场,也就是一个带条件的无向图模型。简单理解就是把隐藏状态的模型与马尔科夫随机场结合起来。如图3.3所示,把一个无向图形分为两类节点,阴影部分为可观测变量,另外一类叫隐藏变量,这样的结构模型就是受限波尔兹曼机模型。
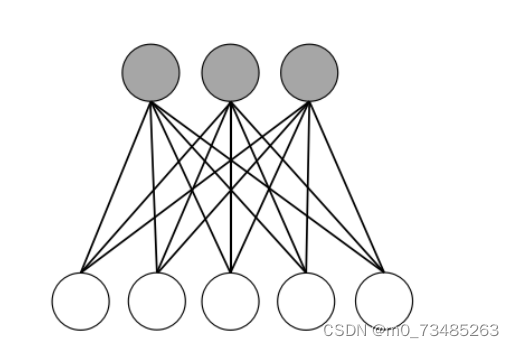
图3.3 受限波尔兹曼机模型
??与波尔兹曼机和受限波尔兹曼机不同的地方在于后者在同层之间是没有任何连接的,只有在显层和隐层之间关系才是全连接的关系,因为在RMB中去除同层之间的连接可以简便训练过程,这样更方便于实际应用模型训练。在受限波尔兹曼机的训练过程里,通常使用的是对比散度的方法。例如当我们假设显层与隐层的神经元个数分别为d和q,v是显层的状态向量,h是隐层的状态向量。那么在所有的隐层状态向量下求显层状态向量的概率,我们可以使用显层在隐层条件下的每一位概率连乘得出显层状态的概率;同样对于在所有的显层状态向量下求隐层状态向量的概率可以使用隐层在显层条件下的每一位概率连乘就可得出隐层状态的概率。
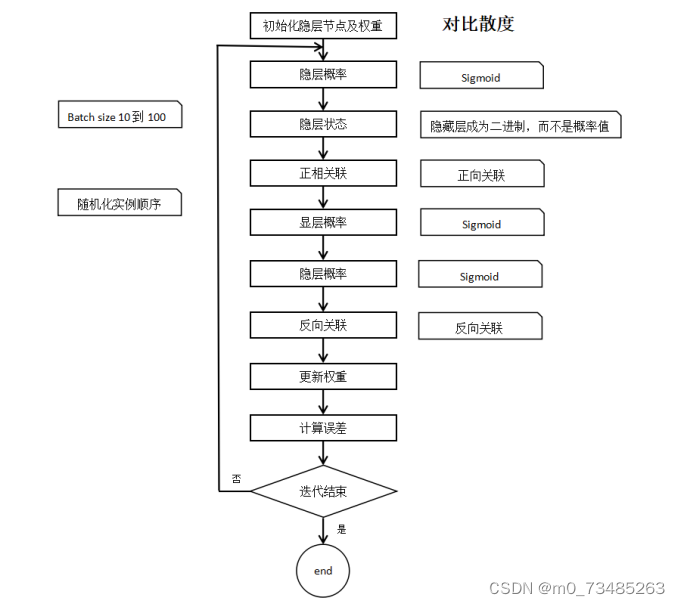
图3.4 对比散度训练过程图
??如上图3.4所示,在使用对比散度训练过程里,我们通常使用批量处理的方法,选取10到100之间的数作为实践经验。在训练前先把数据进行随机打乱处理,先初始化权重和显隐层的节点数,通过显层的输入乘上对应的权重得出激活值就可以调用sigmoid函数来算出隐层的概率,用隐层概率与一组0到1之间的随机值进行比较,如果隐层概率比随机值大则隐层状态就为1,反之则为0。然后在正向关联里使用显层输入的数据和隐层算出来的概率进行转置运算。与得出隐层概率同样的方法得到显层概率后再使用显层概率作为输入来计算隐层的概率。再用显隐层概率进行转置得出反向关联,正反关联之差乘以学习率再除以批量的大小来更新权重。在整个过程里我们可以设定一个变量来记录误差。最后检验训练是否结束,若没有结束则重复一遍整个训练过程。上述就是受限波尔兹曼机对比散度的训练过程,这种受限波尔兹曼机通常使用在深信度网络里,通过搭建多层的受限波尔曼机进行训练。
3.3卷积神经网络
??在图像识别领域里特征学习是必不可少的技术操作;在神经网络领域里特征学习是永恒的主题。提取特征可以使用有监督学习、无监督学习、自动编码器等等方法,但在神经网络里,卷积是目前最热门,相对又简便的一门特征提取技术。人工智能飞速发展使得卷积神经网络技术越来越先进。例如现今超级火热的抖音尬舞机、美图秀秀等这些都是用计算机视觉卷积神经网络技术实现的。
卷积神经网络最广泛应用于图像识别,它就相当于一个被遮盖住的箱子,接收二维像素阵列作为图像数据,经过卷积神经网络箱子的处理,输出得到的是图像是什么的信息。所以最重要的是要清楚卷积神经网络的处理过程,了解它是如何从图片上得知它的信息的。
3.3.1卷积神经网络结构概述
??全连接神经网络拥有多层结果虽然提高了学习能力,但是它的复杂程度与参数的个数也同时增加会导致梯度爆炸的现象。整个模型的复杂度变大就会极容易出现过拟合问题。所以全连接神经网络就不适合构建多层的网络结构,而卷积神经网络就是全连接神经网络的创新,它在建立多层网络结构的时候可以有效地避免梯度下降的问题出现,降低了全连接神经网络的复杂程度。
卷积神经网络可以构建多层次的网络结构,最常见的网络结构有LeNet5,它一般可以搭建5到7层的网络结构;AlexNet可搭建10层左右的网络结构;而ResNet是网络结构层次之最,可搭建的网络结构高达100多层。这些所有的网络结构都是由卷积神经网络结构变化而来的,他们的目的都是为了能够增加搭建网络结构的层数,这样可以使得网络结构模型的学习能力大大的提升,所以卷积神经网络是提高模型的学习能力同时要避免网络的过拟合现象的一种优化技术。
卷积神经网络应用在图像识别里,它保持了全连接的层级结构,数据传入在卷积神经网络里同样是需要一层一层的进行处理,但是在每一层的运算处理形式却有所不同,它可以根据自己所需的情况来制定每一层的功能实现。它的主要层次由数据输入层、卷积计算层、ReLU激励层、池化层、全连接层和输出层构成。如下图3.5所示:
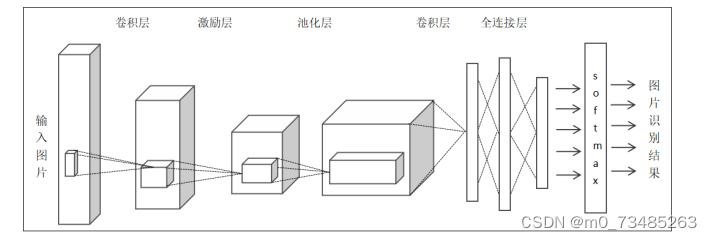
图3.5 卷积神经网络架构图
??图片数据输入层(Input Layer):顾名思义就是样本数据的输入,在此前我们需要对原始数据进行降维,归一化等处理后才把数据传入输入层中。因为经过预处理后的数据可以加快训练时间更利于神经网络的收敛。在图3.5图片输入在一个三维矩阵里面,其中它的长宽深代表着输入图像的长、宽和色彩通道RGB。
??卷积计算层(CONV Layer):卷积计算层在名字上看就知道识卷积神经网络最重要的一部分。它通过卷积核在样本数据进行每一小块每一小块的扫描计算,同时卷积层将神经网络中分成的所有小块进行加深处理,提取更为具体的特征,所以其深度也会同时增加。
激励层(ReLU Incentive Layer):这里的激励层使用的是ReLU激活函数。其根据卷积运算层的输出结果进行非线性映射操作。
??池化层(Pooling Layer):池化层对数据进行压缩,降低模型的复杂度的。
全连接层(FC Layer):传统的和卷积的神经网络都有全连接层,在卷积神经网络的全连接层反映在不同层级之间的所有神经元相互连接。
3.3.2卷积神经网络之AlexNet
??AlexNet技术远远超出CNN;它采用双通道双GPU的结构使得训练的速度大大得以提升了;以小换大,以多换少的方式,用多层小卷积堆加一起,用来替换一个大卷积层,使其深度甚比LeNet的要深,而且AlexNet打破了LeNet5黑白图片识别,以识别三个通道的彩色图片为主,准确率足足提升了10个百分比。在卷积神经网络里,最让人头痛的训练速度也是让AlexNet的GPU双通道训练得以解决的,使用一块GPU进行网络训练,可提升20倍以上的速度;将sigmoid函数换成ReLU激活函数,不仅简便了求导过程,而且在多层神经网络训练时避免了梯度消失的问题出现;Dropout结构的操作使用在最后的全连接层中,减少过度拟合现象。有了AlexNet模型的训练与速度问题就迎刃而解,从而成为业界最为火爆的结构之一。
当输入到AlexNet网络结构中的数据尺寸大小是256×256×3的彩色图片,要经过图像的随机剪切处理后使得图像的尺寸大小为224×224×3,然后图片再经过的旋转、位置的变换,把尺寸扩大为227×227×3。在AlexNet中输入的图像尺寸大小为227×227×3可以使得在后面的计算就不需要添加填充值,这有利于计算简便。
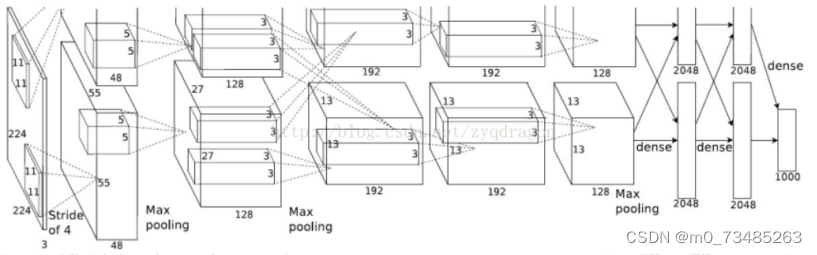
图3.6 AlexNet训练模型结构图
??如上图3.5AlexNet的训练模型结构图所示,图片经过预处理后进入第一层,也称卷积池化层,以彩色图像为卷积层的输入数据,数据大小是预处理后的图像大小W×W:227×227,这时我们需要设定一个过滤器F×F:11×11,过滤器可以卷积运算进入卷积层中的图像,每一次卷积后都会得出一个新像素图像,卷积计算完成一次就会按照设定的步长S:4的频率从上到下,从左到右的移动。此外卷积还需要的值有填充值设为P:0,在AlexNet中采用双GPU训练,所以一共有96个核,但双通道结构,因此其深度依据卷积核的数量为为48×2。而卷积完成后形成图像的像素矩阵大小的可根据公式:N=(W-F+2P)/S+1来计算,因此图像经过第一层的卷积激励层后的尺寸大小为(227-11)/4+1=55,所以过滤器的神经元的个数为55×55×48×2。而参数个数相当于线性函数的w与b的参数,其个数计算为(11×11×3+1)×48×2=34944个参数。第一个卷积结束后进出第一个池化层,它的输入数据是卷积后输出的数据,其尺寸大小为55×55×48×2。池化核的尺寸大小为F×F:3×3、填充值为P:0、步长为S:2。同第一层卷积层计算公式一样可得出在此层的最大池化层的数据输出尺寸大小为27×27×48×2。在最大池化里参数个数为0。
??第二层卷积池化层,以第一层输出27×27×48×2大小的数据传进第二层的卷积层中,使用F×F:5×5的过滤器。为了卷积核在数据图像是扫描运算时候能够相对应,所以增加填充值P:2。每次卷积核在数据图像从上到下,从左到右扫描的移动步长为S:1,深度为128×2。得出输出数据的尺寸大小为(27-5+2×2)/1+1=27,即27×27×128×2。第二层的最大池化所输入的数据尺寸大小是第二层卷积层的输出数据的尺寸大小,即27×27×128×2,其池化核的尺寸大小为F×F:3×3、填充值为P:0、步长为S:2,得出输出数据的尺寸大小为(27-3)/2+1=13,即13×13×128×2。
??第三层只有卷积层,同上一层以第二层池化层所输出的13×13×128×2大小的数据传进第三层卷积层中,使用F×F:3×3的过滤器,过滤器根据步长为S:1的速度在输入的图像中从上到下,从左往右扫描。同样为了卷积核在数据图像是扫描运算时候能够相对应,所以增加填充值为P:1。深度为192×2,得出输出数据的尺寸大小为(13-3+2×1)/1+1=13,即13×13×192×2。
??第四层还是只有卷积层,以第三层卷积层输出的13×13×192×2大小的数据传进第四层的卷积层中,使用F×F:3×3的过滤器,过滤器根据步长为S:1的速度在输入的图像中从上到下,从左往右扫描。同样为了卷积核在数据图像是扫描运算时候能够相对应,所以增加填充值为P:1。深度为192×2,得出输出数据的尺寸大小为(13-3+2×1)/1+1=13,即13×13×192×2。
??第五层又一个卷积池化层,以第四层卷积层输出13×13×192×2大小的数据传进第五层的卷积层,使用F×F:3×3的过滤器,过滤器根据步长为S:1的速度在输入的图像中从上到下,从左往右扫描。同样为了卷积核在数据图像是扫描运算时候能够相对应,所以增加填充值为P:1。深度为128×2,得出输出数据的尺寸大小为(13-3+2×1)/1+1=13,即13×13×128×2。第五层的最大池化所输入的数据尺寸大小是第五层卷积层的输出数据13×13×128×2,其池化核的尺寸大小为F×F:3×3、填充值为P:0、步长为S:2,得出输出数据的尺寸大小为(13-3)/1+1=6,即6×6×128×2。
??第六层开始就是三个全连接层,由第五层池化层的输出计算可得6×6×128×2=9216,所以第一个全连接层的输入的神经元个数为9216。神经元进入第一个全连接层被滤波器卷积运算,再通过ReLU激活函数的映射以及Dropout结构的运算,得到2048×2=4096个神经元输出值;同样这4096个神经元作为第二个全连接的输入神经元数据,输入层和自身层全连接后再通过ReLU激活函数的映射以及Dropout结构的运算4096个输出数据;接着用次4096个输出数据与第三层的1000个神经元进行全连接,经过训练得出最终的训练结果值。
??由图3.6和上述描述总结得出下表3-1AlexNet卷积神经网络结构表:
??表3-1 AlexNet卷积神经网络结构表:
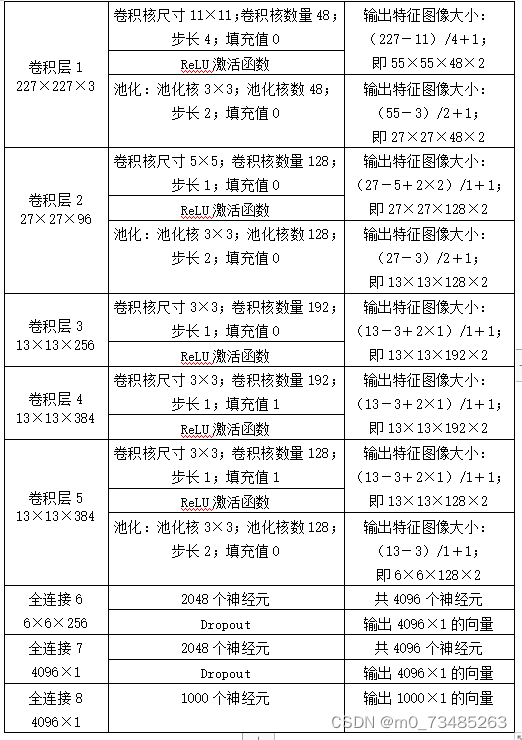
??通过上述总结出在AlexNet神经网络结构的训练过程里,ReLU激活函数解决了原始神经网络使用Sigmoid函数梯度下降的问题;在最后的全连接层里使用Dropout结构有效的忽略一些无关紧要的神经元,使得神经网络不会出现过拟合的现象;在AlexNet中训练过程中创新使用了最大池化,有效的避免像普通的卷积神经网络里使用的平均池化带来的模糊化麻烦,缩小池化核输出值重叠并且可以覆盖,让提取的特征更具有丰富性;在具有大量数据与参数的模型训练中,使用强大的GPU实行并行训练,降低了计算机很多性能的损耗。
四、系统设计与分析
4.1垃圾分类图像识别系统构成及原理
4.1.1图像处理基础知识
??使机器能够模仿人的大脑对外界图像进行识别分类,图像学习的好坏直接影响机器识别的准确率结果。通过图像进行学习,我们需要大量的图像数据,不管我们的数据图像来自网上下载、网上爬取还是自行拍照,其图像的格式、尺寸大小、光暗程度都是参差不齐,各有不同。如果把形态各异的图片传给机器会增加机器学习得复杂性,导致最终机器训练出来得模型可靠性降低,甚至难以达到目标需求。那么图像预处理有多种方法:直方图均衡、中间滤波、归一化和图像增强等等技术。
??直方图均衡技术主要使用直方图对比方法更改图片的灰度值,在图像中逐个点进行更改灰度值,使得所有像素点得灰度级别在同一层级上。这种通过直方图均衡技术后可以得出一个比较平缓得直方图,这多数用于医护人员X射线的操作,让黑暗无法识别的区域使用灰度图展现在适合眼睛亮度的地方。
??中间滤波主要技术是去除噪音,中间滤波把图像周围灰度值反差较大的像素点用周围相似的像素点替代,这样可以去除另类孤立的噪声点。中间滤波处理图像更加清晰而且在处理彩色图像中不会破环彩色像素。
??归一化对图像预处理中有几何归一化和灰度归一化两种普遍技术,其最终结果是让环境不相同的的图片尽可能地使其具有一致性,让图片有某些固定的不变特性。
图像增强技术不考虑降质缺陷,展现图像最具有代表性,也就是最感兴趣的特征区域,遮掩无关紧要的特征区域。
??总的来说,图像处理的目的都是尽可能地除去让机器无法识别的干扰。简化图像数据,使图像地主要特征更为突出,更便于学习训练。
4.1.2垃圾分类图像识别系统构成
??本设计的垃圾分类图像识别搭建在TensorFlow的环境下实现的。整个项目大体分为图像的收集、图像的处理、卷积神经网络的搭建、模型训练、模型测试、最后用一个GUI界面对项目进行封装。设计完成了一个可识别垃圾图像类别以及可调用摄像头识别垃圾物体的系统。如下图4.1垃圾分类图像识别的系统构成步骤所示:
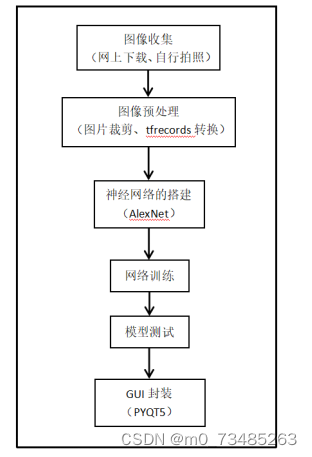
图4.1 垃圾分类图像识别的系统构成步骤
4.1.3图像识别系统功能分类模块设计
??分类是图像识别系统的中心环节,系统的最终目标是根据已训练好的模型反馈对应图像的分类类型,然后以一个直观的的图标展现给用户。系统从分类模块中可分为有六个分类模块,分别为Cardboard、Glass、Metal、Paper、Plastic和Trash,而从功能模块中可划分为两大模块,图像识别功能模块与摄像头识别功能模块。其中六大类分类模块是根据机器传入的图片进入功能模块调用训练模型才可得出结果,所以六类分类模块也可看作是功能模块的子模块。如下图4.2系统的模块示意图所示:
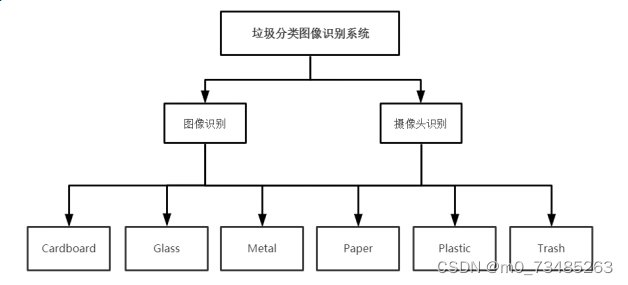
图4.2 垃圾图像识别功能分类模块图
??由上图在项目系统中从功能模块中可分为两模块,图像识别模块与摄像头识别模块。从分类模块中可分为cardboard、glass、metal、paper、plastic、trash六种类型。
图像识别:在项目系统中用户可以使用手机拍照的垃圾图片或网上下载的垃圾图片,但凡是.jpeg、.jpg、.png格式的图片都可以传如系统对该图片进行预测得到垃圾的分类结果。
摄像头识别:若用户觉得拍照再传进系统比较麻烦,那么还可以采用直接摄像头的方法。用户可以打开摄像头,把要分类的垃圾放进摄像头拍摄区域,同样也可以得出垃圾的分类结果。注意使用摄像头进行分类预测时,最好不要让多种垃圾同时出现在摄像头中,因为系统目前还只可以在同一时间只识别一种垃圾。
??Cardboard:主要以相对比较厚硬的纸皮箱为主的类型垃圾,系统根据传入的图片或影像识别Cardboard类型垃圾,此类型垃圾可进行回收,处理后可再次使用。
Glass:主要是玻璃类型的垃圾,系统根据传入的图片或影像识别Glass类型垃圾,此类型垃圾特点反光、坚硬、并以透明为主。玻璃类型的垃圾经过加工厂加工处理,还可以循环利用。
Metal:主要是金属垃圾类型,系统根据传入的图片或影像识别Metal类型垃圾,此类型垃圾可进行回收,加工处理后可再次使用。
??Paper:主要以比较薄的纸张类型垃圾,系统根据传入的图片或影像识别Paper类型垃圾,此类型垃圾可进行回收,处理后可作为原材料作用于很多地方。
Plastic:主要塑料类型垃圾,系统根据传入的图片或影像识别Plastic类型垃圾,此类型垃圾绝不可以燃烧或者随便扔,因为燃烧会放出大量的有害物质危害人类健康。若随便乱扔塑料垃圾是无法分解,对环境会有很大的危害,此类垃圾也可以拿去收费站,专业人员会根据具体情况进行加工处理循环利用。
??Trash:是不可回收垃圾,系统根据传入的图片或影像识别Trash类型垃圾,此类型垃圾投入不可回收垃圾桶里,专业人员会根据具体的垃圾又分为是否可用垃圾,有用垃圾进行加工处理再次使用,无用垃圾最后才放到经过处理的填埋场进行填埋。
4.2垃圾分类图像识别系统设计
4.2.1垃圾图像数据来源
??本设计的主题是基于深度学习算法的垃圾分类图像识别,所以需要准备的原始数据是各个类型的垃圾图片,根据网上随机下载的垃圾图片,还有小部分垃圾图片数据是收集于自行拍照。把所有收集的数据集合在一起进行分类,主要分为六大类型,其中包括有:cardboard、glass、metal、paper、plastic、trash,并且在本地建立以这六种类型为名的文件夹,如下图4.3垃圾图片数据文件夹分类类型所示。把所有的图片数据上标签,然后归类存放到对应类型的文件夹里,如图4.4cardboard类型的数据图片,图4.5glass类型的数据图片,图4.6metal类型的数据图片,图4.7paper类型的数据图片,图4.8plastic类型的数据图片,图4.9trash类型的数据图片,如下所示:
图4.3 垃圾图片数据文件夹分类类型

图4.4 cardboard类型的图片数据

图4.5 glass类型的图片数据
图4.6 metal类型的图片数据

图4.7 paper类型的图片数据

图4.8 plastic类型的图片数据
图4.9 trash类型的图片数据
4.2.2图像预处理
??在模型训练之前我们需要对数据进行裁剪,使得数据输入到神经网络的时候所有图像的尺寸大小都是一致的。本设计使用了Python语言和TensorFlow的环境,我们可以把数据图像转化为一种二进制的tfrecords文件。这种文件正是使用tensorflow来运行,python来制作代码的。而且tfrecords在tensorflow中,无论是在拷贝、转移、读取还是存储都是有着非常大的优势。
??TFRecords文件训练对计算机资源的需求大大的减少了,训练时只需要将已保存好的TFRecords文件的特定格式简单的取出训练即可;如果图像预处理单单使用tensorflow来操作,那么当遇到图像预处理操作复杂时则对训练模型会带来干扰,但是TFRecords他可以不被限制于tensorflow,灵活处理图片数据,逻辑复杂的数据处理也能够完胜;TFRecords在训练占用内存少,训练结束却要比原始数据大,这也就是TFRecords可以快速训练大量数据的原因。
??在本项目图片数据预处理,首先使用tf.python_io.TFRecordWriter创建一个TFRecords文件夹,遍历自己已经分类好并且已经打上标签的图片,把所有图片的大小使用resize裁剪图片使得图片尺寸大小为227×227,使得尺寸匹配上后面在卷积神经网络输入数据的尺寸。然后把图片类型转为原生的Bytes,进入真正的将图片转化为二进制,使用tf.train.Example和tf.python_io.TFRecordWriter分别对图片格式进行输入和写入,当所有的数据已经输入转化后,然后example对图像和对应的标签进行封装,把序列化为字符串那么图片转为二进制的TFRecords文件就完美结束了。把图片制定为二进制文件,当我们需要读取的时候我们可以使用队列的方法或者直接使用循环然后用ParseFromString进行解析就可。下图4.10是图片预处理与转为TFRecords文件的核心代码:
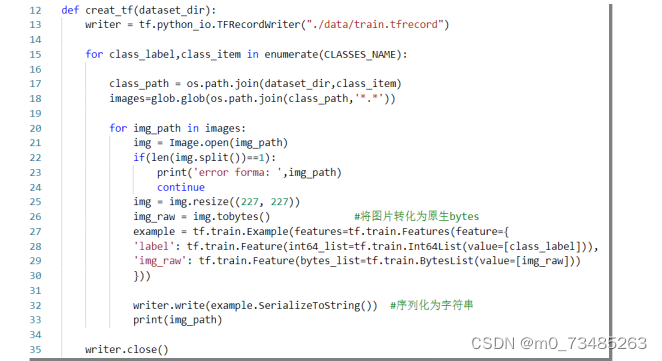
图4.10 垃圾图片数据转为TFRecords核心代码图
4.2.3AlexNet卷积神经网络搭建
??得到数据后就到了本设计最为重要的步骤,搭建卷积神经网络了。实验中我选用了AlexNet作为这次的神经网络结构,因为AlexNet在图像识别的领域里有着很大的优势,并且实现起来相对比较简便。在整个AlexNet的神经网络结构里,它可以搭建多层的结构并且参数个数庞大却不会出现过拟合情况而且可以通过GPU双通道的方法来降低机器训练的性能损耗,大大的减少了训练时间的耗费。如下表4-1是本次实验搭建的网络模型结构:
表4-1 AlexNet卷积神经网络结构搭建表
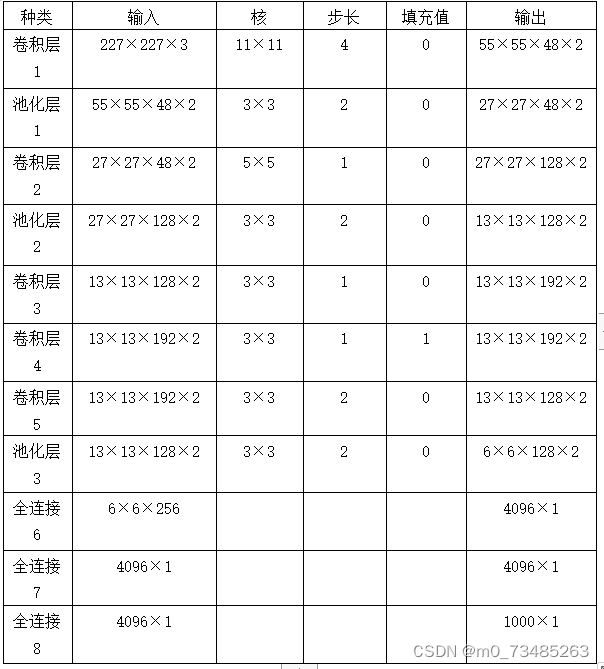
??如上表AlexNet卷积神经网络结构搭建表看出本次模型的AlexNet共搭建了八层,其中前两层和第五层由卷积层和池化层组合构成,并且还执行数据标准化处理。而第三和四层只有一个卷积层。在第六层往后是三个全连接层,在第一个全连接层中的输入数据是取最后一层的卷积层的输出结果,在第六层的全连接层中经过平滑处理随机删除得到4096个神经元输出结果。全连接层嵌入dropout函数,防止数据过拟合。而处在第八层后面的softmax函数,用来输出最终的分类标签。如下图4.11AlexNet的主要代码所示:

图4.11 AlexNet卷积搭建主要代码
??由上图代码可见类和函数的不同分类问题可使用self.NUM_CLASSES在最后全连接层里解决。其实在搭建卷积层前我们许需要定义一些辅助函数,辅助函数可以用于在搭建卷积时创建网络层。还有全连接函数中我们可以使用Tensorboard来监督整个网络结构的激活值、Dropout层以及最大池化层,用tf.summary()来进行添加并且在tensorboard中显示。在Tensorboard中我们可以查看训练过程的细微变化情况,此网页可记录训练过程的准确率、损失值等数据情况。
??搭建完卷积网络,还要写一个函数用来加载准备训练的数据。本设计在网上下载bvlc_alexnet.npy文件,调用此文件能够省去自己训练参数的时间,同时电脑硬件标准需求也降低了。该文件主要是别人已经训练好的imageNet参数数据,我们只要根据自己所需调用接口即可,而且使用此文件的参数往往比你自己训练的参数要准确的多。其bvlc_alexnet.npy下载地址和加载预训练参数的函数主要代码如下图4.12所示:
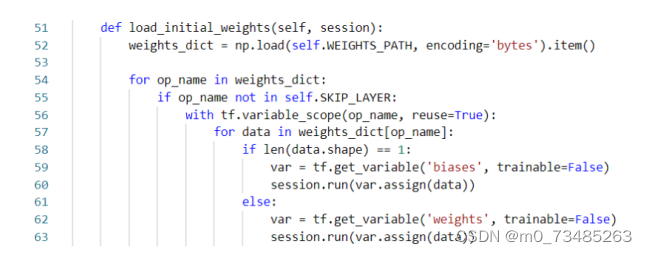
图4.12 bvlc_alexnet.npy下载连接与加载预训练参数主要代码
4.2.4模型训练
??万事俱备,接下来我们就开始训练模型了。首先我们需要读取已准备好的tfrecords文件,因为tfrecords是二进制文件,所以里面的数据我们需要使用队列的方式进行读取。而tf.train.string_input_producer生成的解析队列数据我们可以使用tf.parse_single_example解析器进行读取,读取出来的数据返回的是一个文件和文件名称,然后把返回的值存放在对象serialized_example中。最后还需要进行协议缓冲,使用tf.parse_single_example把Example解析为张量的形式就可以真正的用于训练操作了。如下4.13是使tfrecords文件解析成队列形式的主要代码图:

图4.13 tfrecords文件解析成队列的主要代码
??数据准备好后就要把图片和标签传进已搭建的AlexNet卷积网络中,然后我们还需定义一些dropout和全连接层的变量列表,然后就可以执行整个AlexNet卷积网络结构图了。在卷积神经网络训练过程里,我们还需要设定损失值和优化器,同事使用tensorboard把模型显示出来,这样训练的损失值的收敛情况和与准确率就一目了然。下图4.14数据训练的主要代码:
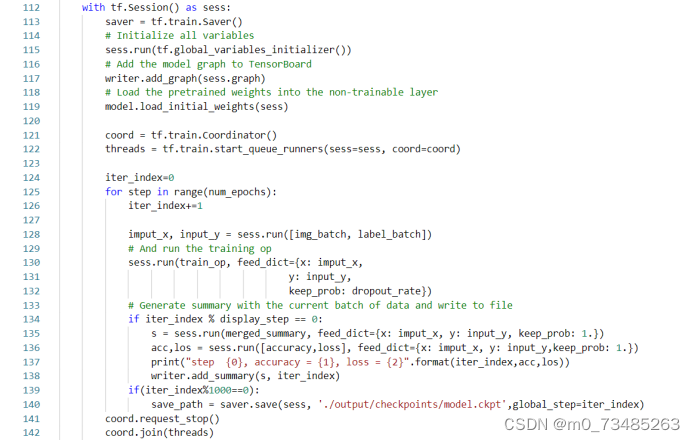
图4.14 数据训练的主要代码图
??网络训练的损失函数与准确率的变化情况我们可以在训练结束后tensorboard网页中查看到,如图4.15所示。图4.16是训练后所保存模型。
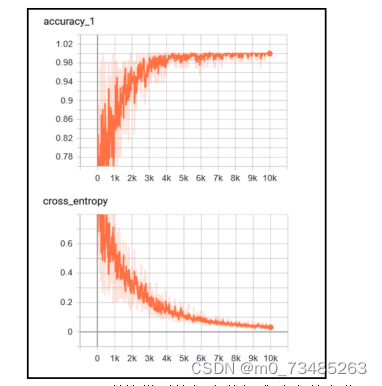
图4.15 AlexNet训练模型的损失值与准确率的变化图

图4.16 训练模型
??由上图可得在10000次的迭代训练中,准确率在训练次数达到四千五后开始趋于平稳,达到98%以上。损失函数在训练次数达到七千五后开始趋向平缓,损失值降低到0.05以下。
4.2.4模型测试
??训练结束得到高准确的模型我们就可以开始进行模型测试了,模型测试主要代码把抽样测试的图片传进训练好的模型看测试结果是否正确即可,如下图4.17模型测试的主要代码:
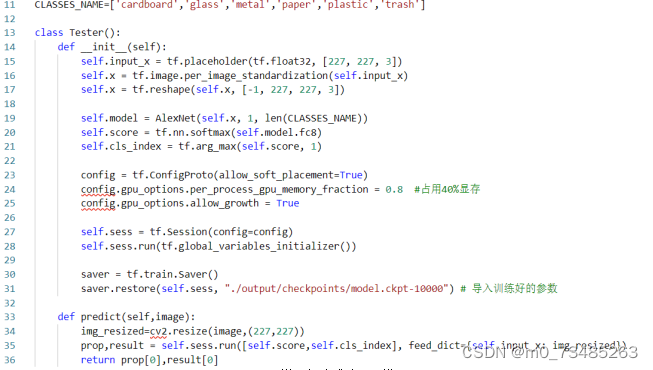
图4.17 模型测试主要代码
??在先前的模型训练我们使用了saver.save()的方法来保存训练的模型,模型在训练时候已经存放好参数,我们可以使用tf.train.Saver()来载入模型进行模型测试,就不需要每测试一遍又要进行训练,从而达到了节省时间的效果。
4.3GUI界面设计
??项目完成了垃圾图像数据集的准备、图像数据预处理、AlexNet卷积神经网络的搭建、模型训练与模型测试。然后就可以使用PYQT5对整个项目进行封装,设计可视化界面。
4.3.1PYQT5简介
??PYQT5是使用Python模块拼接来实现各种功能,这时一款非常强大的GUI支持库里面有六百多个类,方法与函数,它支持python2.x和python3.x两个版本。Pyqt5不仅可以使用在Window系统中,Mac与Unix等主流的操作系统也可以运行。
4.3.2PYQT5界面设计
??本设计使用PYQT5对基于深度学习算法的垃圾分类图像识别项目进行界面化设计,其界面设计主要包含有主界面、三个按钮以及六个分类图标与准确率柱状图。主界面用来展示打开的图片与摄像头的摄入;按钮分别为Open Image用来打开本地图片、Open Camera用来打开摄像头、Recognize对打开的图片或摄像头前的物品进行识别;主界面下方是六种垃圾类型的图片,用来反馈识别结果;在图标的右方是识别物体在各种类型的准确率柱状图的展示。其界面展示图如下图4.18所示:
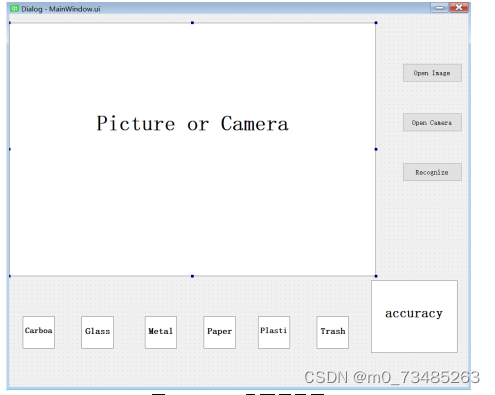
图4.18 GUI界面展示图
??pyqt5-tools中包含有工具QtDesigner、pyuic和pyrcc等。在界面实现首先我们可以使用QtDesigner工具根据自己的需求以拖动的形式画出一个大概的界面,如上图4.18GUI界面展示图,使用pyuic命令把界面.ui文件转换为python文件,此时文件拥有界面设计的主要代码框架,我们在其可以根据自己的需求进行优化改进。
??使用pyuic的命令把.ui文件转换为python文件中主要有Ui_MainWindow类和retranslateUI(self,MainWindow)函数,其中Ui_MainWindow它继承空类object,相当于一个空容器,要来装MainWindow的对象,还有一个子对象centralwidget,主要用在后面在主窗口中运行;而各个控件的属性就要使用retranslateUI(self,MainWindow)函数来设置。然后使用button.clicked.connect(clicked_function)来设置触发按钮Open Image和Open Camera和label.setPixmap用来显示分类的图标。
五、 目录
第一章 绪论 1
1.1研究背景、目的及意义 1
1.1.1研究背景 1
1.1.2研究目的 1
1.1.3研究意义 2
1.2研究现状 3
1.2.1国外研究现状 3
1.2.2国内研究现状 4
第二章 开发工具与关键技术的介绍 5
2.1开发工具 5
2.2深度学习 5
2.3人工智能 6
2.4图像识别 6
第三章 深度学习算法模型 7
3.1自动编码神经网络 7
3.1.1自动编码器 7
3.1.2变分自动编码器 8
3.1.3生成对抗网络 9
3.2受限波尔兹曼机 9
3.3卷积神经网络 11
3.3.1卷积神经网络结构概述 11
3.3.2卷积神经网络之AlexNet 12
第四章 系统设计与分析 17
4.1垃圾分类图像识别系统构成及原理 17
4.1.1图像处理基础知识 17
4.1.2垃圾分类图像识别系统构成 17
4.1.3图像识别系统功能分类模块设计 18
4.2垃圾分类图像识别系统设计 19
4.2.1垃圾图像数据来源 19
4.2.2图像预处理 22
4.2.3AlexNet卷积神经网络搭建 23
4.2.4模型训练 25
4.2.4模型测试 27
4.3GUI界面设计 28
4.3.1PYQT5简介 28
4.3.2PYQT5界面设计 28
4.4项目结果研究与分析 29
第五章 项目结论与展望 34
5.1项目结论 34
5.2未来展望 35
参考文献 36
致谢 37
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- pat大炮打蚊子
- 【笔记】认识凸优化
- 国标28181平台只能连接视频监控吗?
- 力扣.34以及二分法两种方法的区别
- 代码随想录算法训练营第45天|● 139.单词拆分 ● 关于多重背包,你该了解这些! ● 背包问题总结篇!
- 中国学者张跃泷获乌克兰国家工程院外籍院士荣誉
- Javaweb小案例-基于SpringBoot+Vue实现的Timo商城
- Spring Boot 构建工具插件
- Restrict Content Pro WordPress – 限制会员内容 付费内容网站(包含所有扩展)
- Python中闭包Closure的5个层次