多场景建模:阿里多场景多任务元学习方法M2M
multi-scenario multi-task meta learning approach (M2M)
背景
广告领域大部分是针对用户建模的,像点击率预估,很少有针对广告主需求建模(广告消耗预估、活跃率/流失率预估、广告曝光量预估),广告的类型较多(搜索广告、展示广告、实时流广告),广告主在不同场景类型上面的行为也不同,这篇文章就是针对广告主建模的。
针对广告主建模的难点:
- 很难建模数据量较小或者新的场景,数据样本太少,无法学习充分
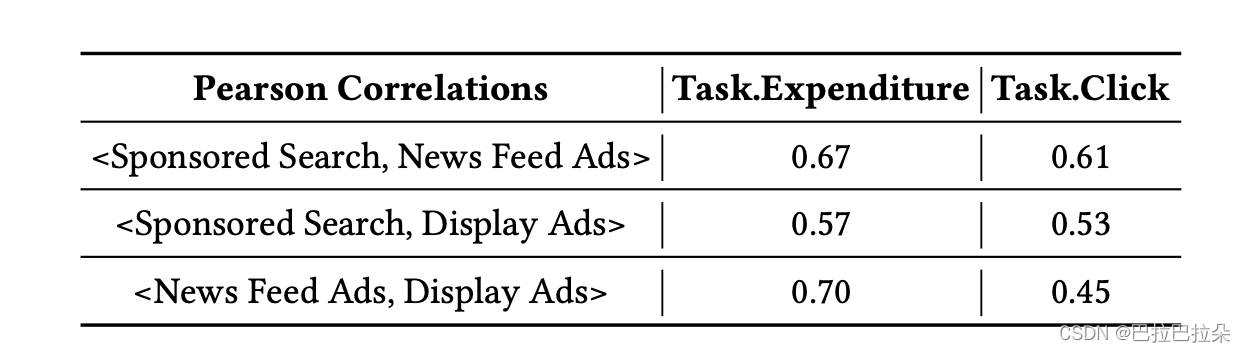
- 场景之间的相互关系比较复杂,较难建模,即便是相同任务,在不同场景也表现不同,如下图,不同任务在不同场景对的皮尔逊相关性。
解决方案:
引入了meta unit,融合丰富的场景知识来学习显示的场景之间的相关性,这样可以很方便的扩展到新场景。
提出了meta attention,捕获不同任务在不同场景之间的相关性
提出了meta tower,用于增强捕获特定场景特征表示的能力
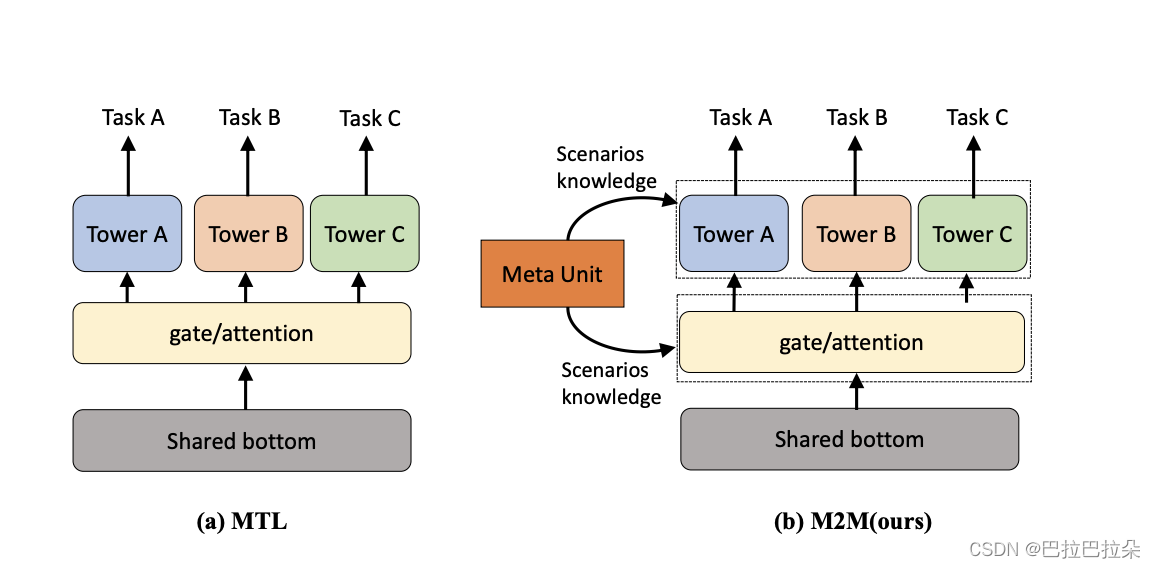
点评:核心是通过场景表示学到的信息作为专家网络及任务学习的动态权重,在任务学习过程中加入场景的个性化。
方法详情
M2M包括3个主要的阶段
第一阶段
Backbone Network,主干网络获得特征、任务、场景的embedding表示,这部分和没有创新,一般做法。
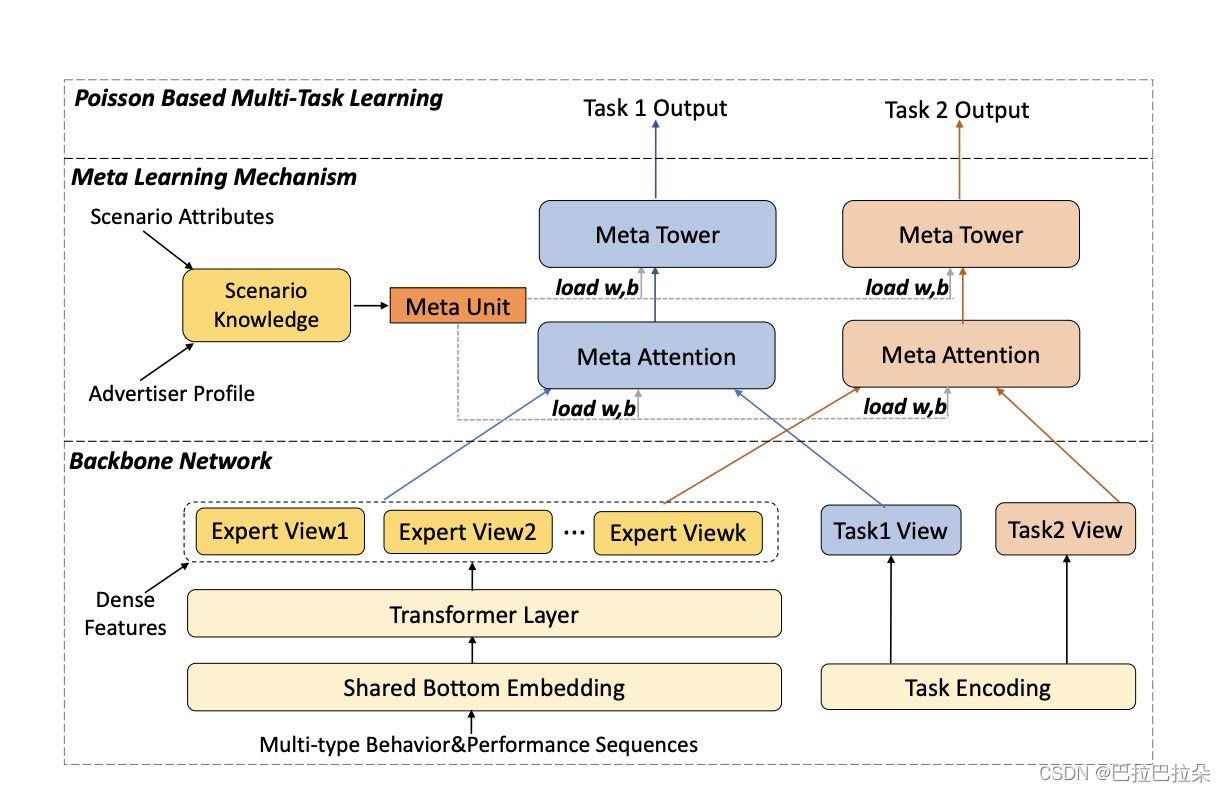
step1:Shared Bottom Embedding
对广告主行为序列、表现序列离线化,用embedding层做成序列embedding,然后加上位置embedding,拼接起来。
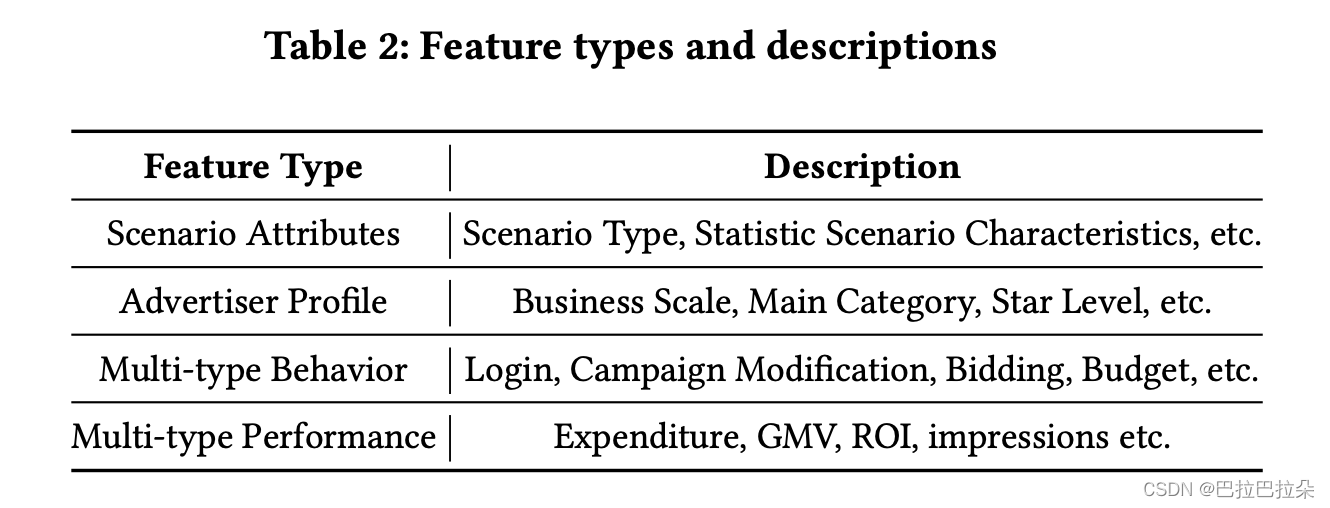
特征属性特征:
S
=
{
s
1
,
s
2
,
.
.
,
s
l
}
S=\{s_1,s_2,..,s_l\}
S={s1?,s2?,..,sl?}
广告主画像特征:
A
=
{
a
1
,
a
2
,
.
.
.
,
a
m
}
A=\{a_1,a_2,...,a_m\}
A={a1?,a2?,...,am?}
行为序列特征:
X
b
=
{
X
b
t
}
t
=
1
T
X_b = \{X_b^t\}_{t=1}^T
Xb?={Xbt?}t=1T?
指标特征:
X
p
=
{
X
p
T
}
t
=
1
T
X_p=\{X_p^T\}_{t=1}^T
Xp?={XpT?}t=1T?
step2: Transformer Layer 学习序列更深层次的表达
M
H
(
X
)
=
c
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
.
.
.
,
h
e
a
d
h
)
W
H
MH(X)=concat(head_1,head_2,...,head_h)W^H
MH(X)=concat(head1?,head2?,...,headh?)WH
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
X
W
i
Q
,
X
W
i
K
,
X
W
i
V
)
head_i=Attention(XW_i^Q,XW_i^K,XW_i^V)
headi?=Attention(XWiQ?,XWiK?,XWiV?)
将转换后的行为序列Embedding和指标序列Embedding
F
=
c
o
n
c
a
t
(
M
H
(
X
b
)
,
M
H
(
X
p
)
)
F=concat(MH(X_b), MH(X_p))
F=concat(MH(Xb?),MH(Xp?))
step3: Expert View Representation
经过transform编码后的embedding和其他dense特征拼接在一起,套用MMoE的结构,用
k
k
k个专家进行学习
E
i
=
f
M
L
P
(
F
)
????
i
∈
1
,
2
,
.
.
.
,
k
E_i = f_{MLP}(F) \ \ \ \ i \in 1,2,...,k
Ei?=fMLP?(F)????i∈1,2,...,k
step4:Task View Representation
受MRAN启发,除了特征embedding,在相同空间对所有task进行embedding,得到
m
m
m个任务的表示
T
t
=
f
M
L
P
(
E
m
b
e
d
d
i
n
g
)
???
t
∈
1
,
2
,
.
.
.
,
m
T_t=f_{MLP}(Embedding) \ \ \ t \in 1,2,...,m
Tt?=fMLP?(Embedding)???t∈1,2,...,m
step5: Scenario Knowledge Representation.
将场景属性及广告主画像合并起来,经过一个简单的mlp网络学习得到场景Embedding表示
S
~
=
f
M
L
P
(
S
,
A
)
\tilde S = f_{MLP}(S,A)
S~=fMLP?(S,A)
第二阶段
Meta Learning Mechanism, 元注意力(meta attention)组件和元塔(meta tower)组件,捕获不同场景之间的相关性以及增强特定场景特征表达能力
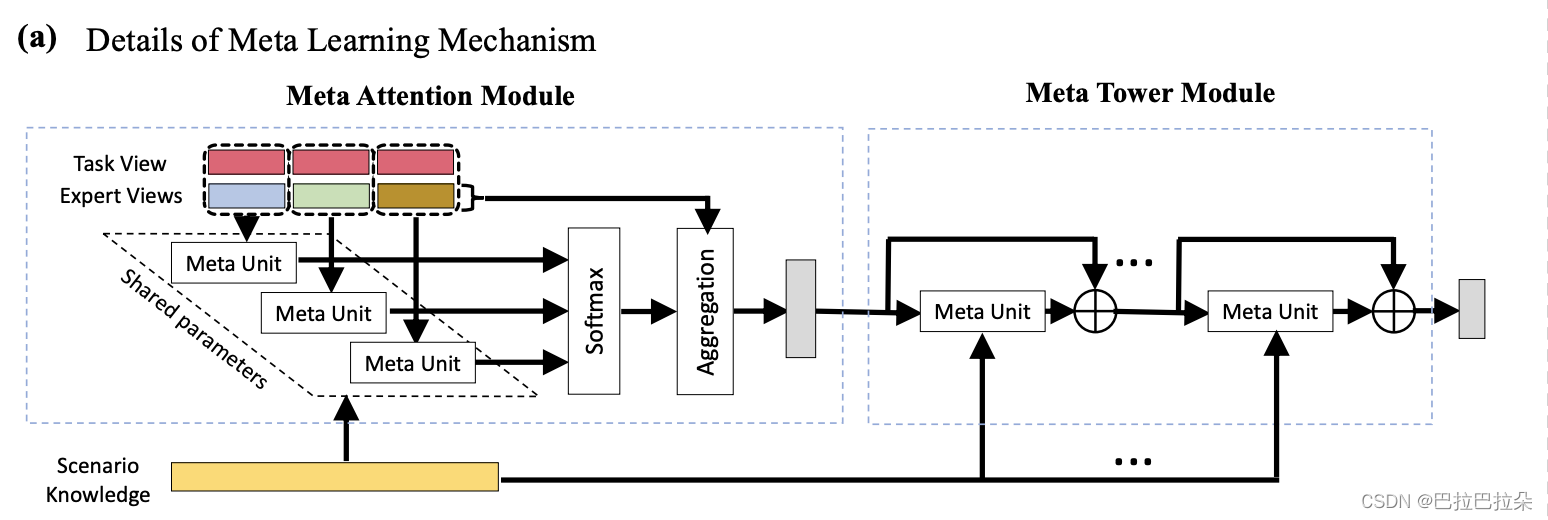
meta attention 和 meta tower的基础都是meta unit,这里详细阐述meta unit,结构如下:
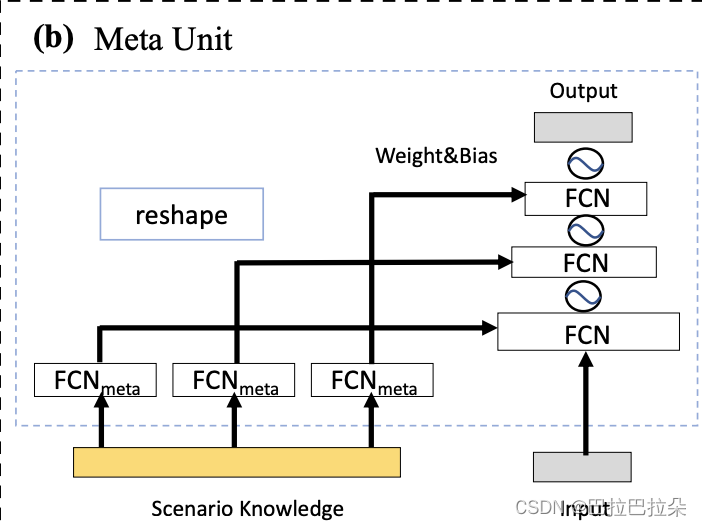
右侧input为输入,在meta attention里面input是concat(expert_out_embedding,task_embedding),
即专家网络的输出embedding和task的embedding拼接起来。在meta tower里面input就是前面attention后的结果。
input经过的几层FCN的权重是动态产生的,由场景embedding经过一个简单的FCN后得到的embedding,
经过reshape后得到,这样不同场景meta unit里面的主网络FCN权重是不一样的,通过这样的动态权重做到场景的个性化。
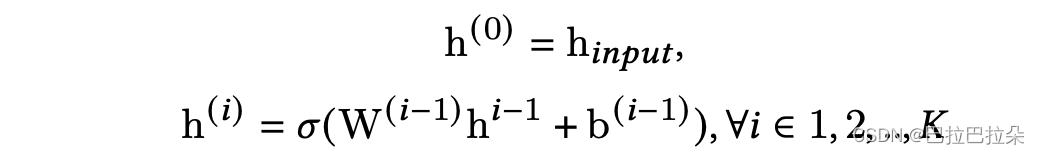
注意这里的
W
(
i
?
1
)
W^{(i-1)}
W(i?1)和
b
(
i
?
1
)
b^{(i-1)}
b(i?1)是通过场景Embedding经过mlp网络输出的向量再进行reshape得到,这里权重和偏置是根据场景动态产生的。比如说场景Embedding经过mlp得到一个256维的向量,这就可以reshape成128->64->64这样的简单3层mlp。
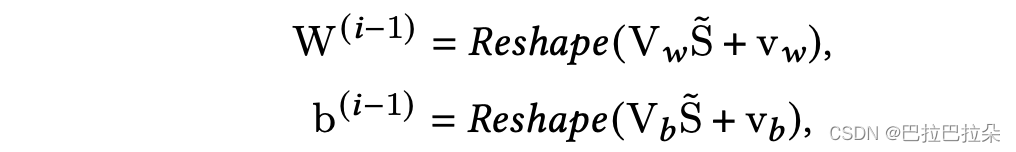
输入
h
i
n
p
u
t
h_input
hi?nput经过几层动态权重的FCN得到输出
h
o
u
t
p
o
u
t
h_outpout
ho?utpout,meta unit这个过程定义为
M
e
t
a
(
?
)
Meta(\bullet)
Meta(?)
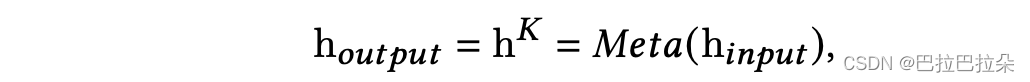
meta attention
输入就是专家输出embedding
E
i
E_i
Ei?与task的embedding
T
t
T_t
Tt?,通过meta unit
M
e
t
a
(
?
)
Meta(\bullet)
Meta(?)调制之后,再通过一个向量映射成注意力分值常数。meta unit是场景相关的,input又是task相关的,这样就同时学习到多场景和多任务之间的关系。
这里softmax计算注意力分数的时候,
j
j
j表示专家,这里
M
M
M可能有误?专家总数按上文应该是
k
k
k
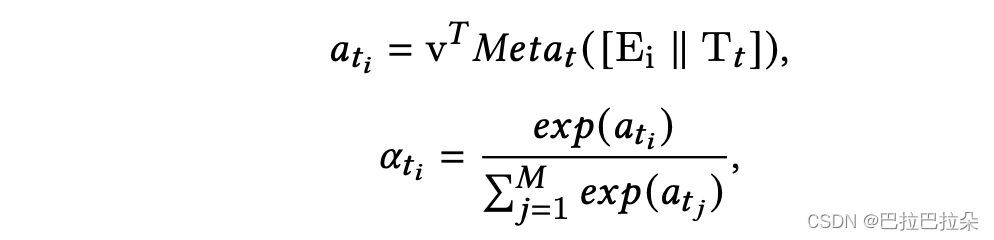
最后任务的表示如下,专家输出的加权求和。
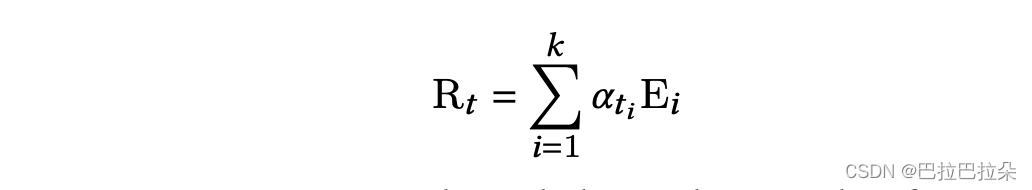
meta tower
其实就是个残差网络,即能保留原始的输入,也能提取得到经过meta unit之后的输入
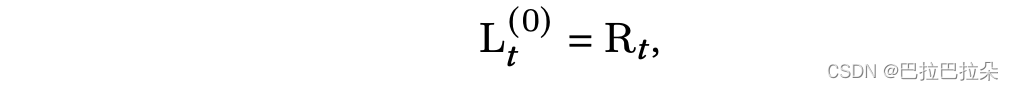
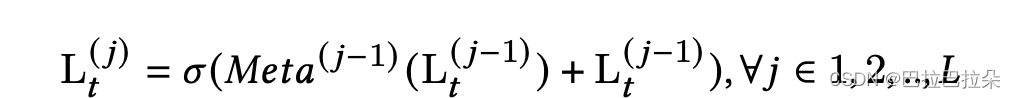
第三阶段:Poisson Based Multi-Task Learning,通过泊松损失从多场景中预测多任务
loss
对于离散数据,使用泊松loss计算
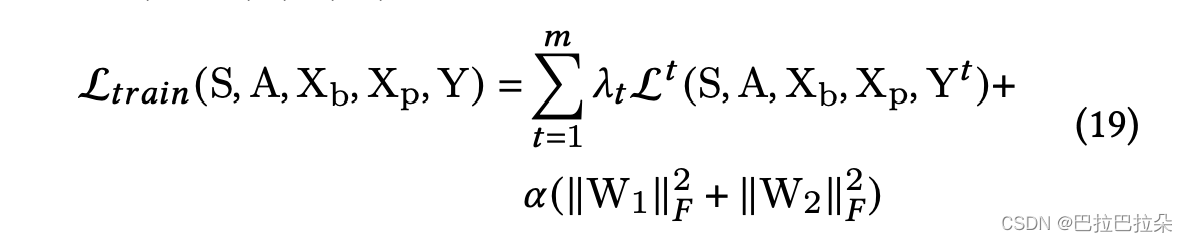
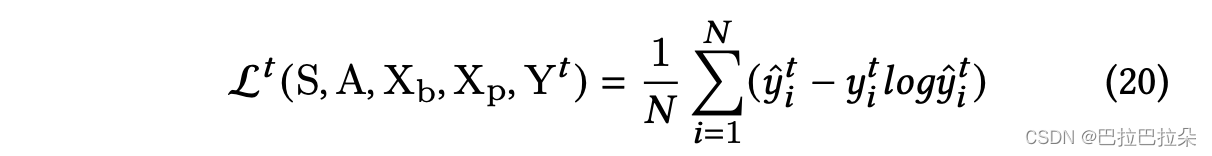
评估指标
对于回归问题,MAPE(Mean Absolute Percentage Error)和NMAE(Normalized Mean Absolute Error)
但是因为pv、clicks很可能是0,因此使用 SMAPE (Symmetric Mean Absolute Percentage Error),
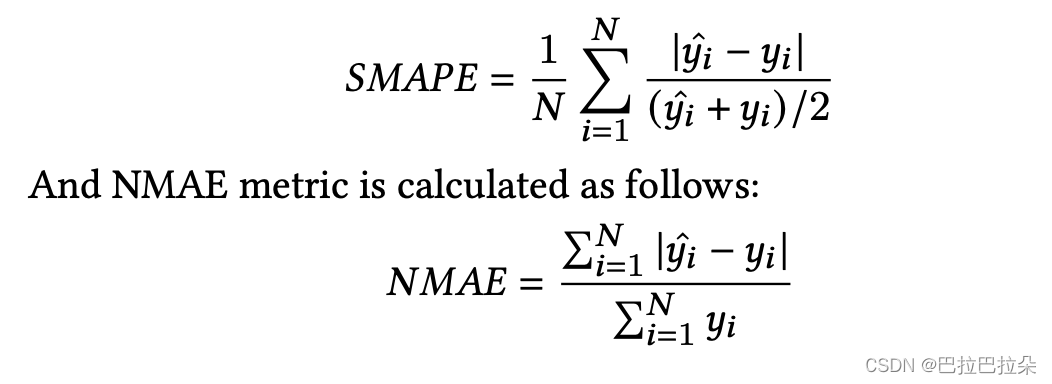
评估结果
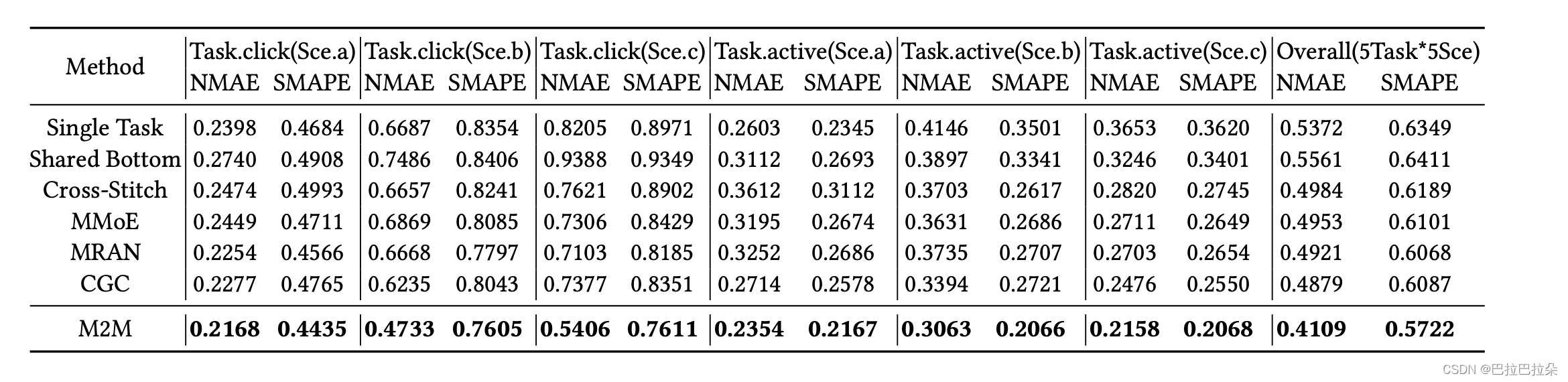
消融分析
w/o meta tower module (MT).
w/o meta attention module (MA)
w/o transformer Layer (TL).
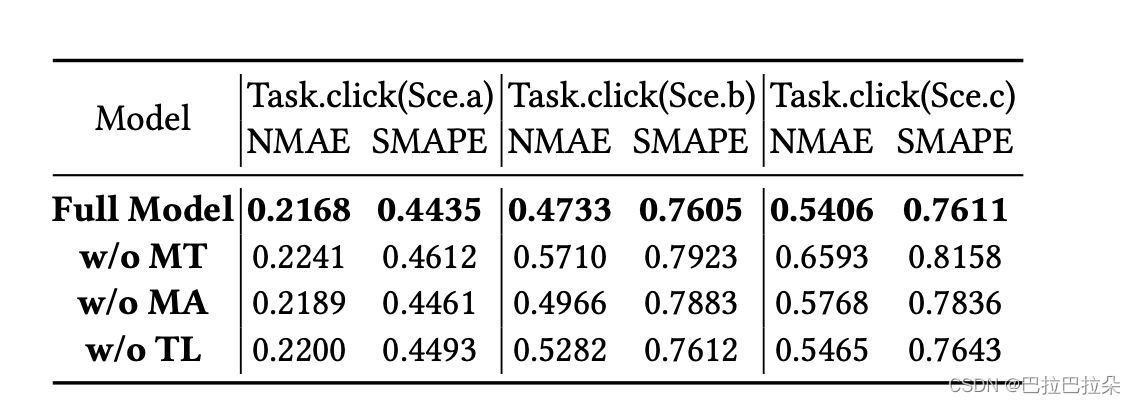
超参数分析
序列长度影响,过长文章说可能引入了较多噪声,导致反而变差
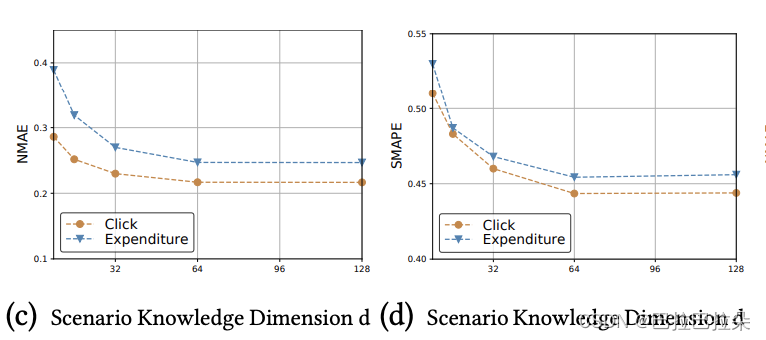
场景Embedding维度,到64维后就不再降低
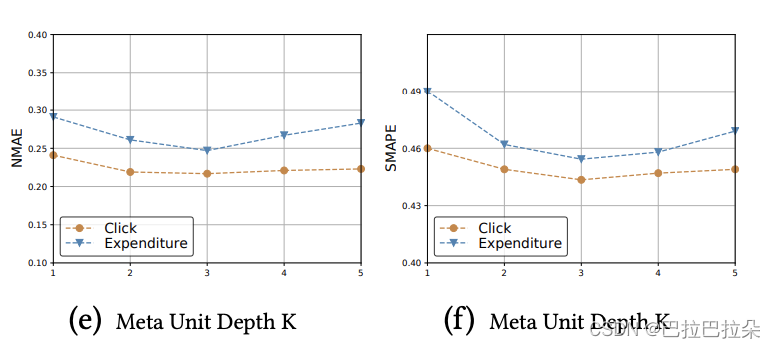
meta unit的层数,越深反而效果变差,文章说可能是越深越容易过拟合
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 博弈类问题
- Linux centos7安装redis 6.2.14 gz并且使用systemctl为开机自启动 / 彻底删除 redis
- 抖店怎么上架商品?
- pod进阶
- 方案分享:如何做好云中的DDoS防御?
- XTU-OJ-1452-完全平方数-笔记
- 【优化技术专题】「性能优化系列」针对Java对象压缩及序列化技术的探索之路
- matlab读取pwm波数据,不用timer的方法,这里可以参考。Matlab/Simulink之STM32开发-编码器测速
- 07-抽象工厂
- DDD领域驱动设计(五)