【Jmeter】Jmeter基础7-Jmeter元件介绍之后置处理器
发布时间:2023年12月17日
- 后置处理器主要用于处理请求之后的操作,通常用来提取接口返回数据
2.7.1、JSON JMESPath Extractor
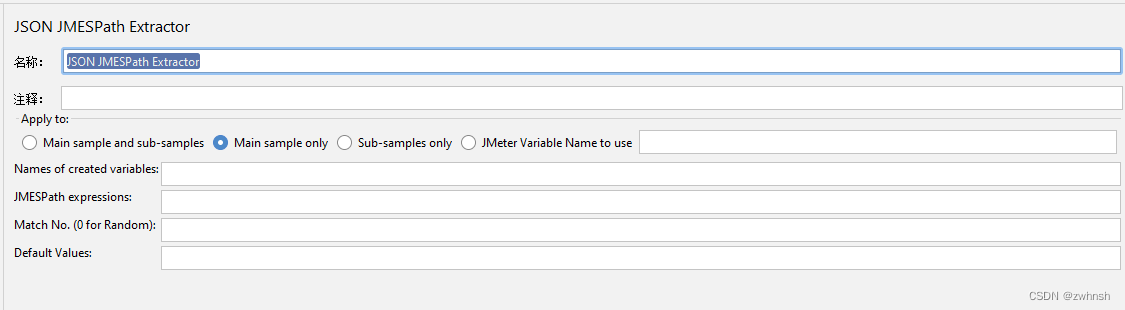
- 作用:可以通过JmesPath语法提取所需要的值
- 使用场景:取样器返回格式为json
- JmesPath语法:参考https://jmespath.org/tutorial.html
- 参数说明:
- Apply to:
- Main sample and sub-samples:匹配范围包括当前父取样器和子取样器
- Main sample only:默认;匹配范围仅包括当前父取样器
- Sub-samples only :仅匹配子取样器
- JMeter Variable Name to use:支持对Jemter变量值进行匹配,输入框内可输入jmeter的变量名称
- Name of created variables:请求要引用的变量名称
- JMESPath expressions:JMESPath表达式
- Match No. (0 for Random):匹配数字,0代表随机取值,n取第几个匹配值,-1匹配所有
- Default Value:未匹配到值时,给参数一个默认值
- Apply to:
- 示例:
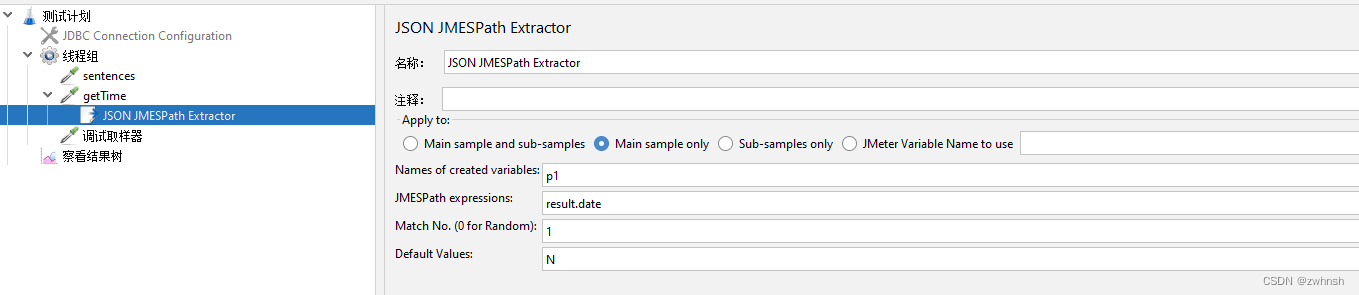

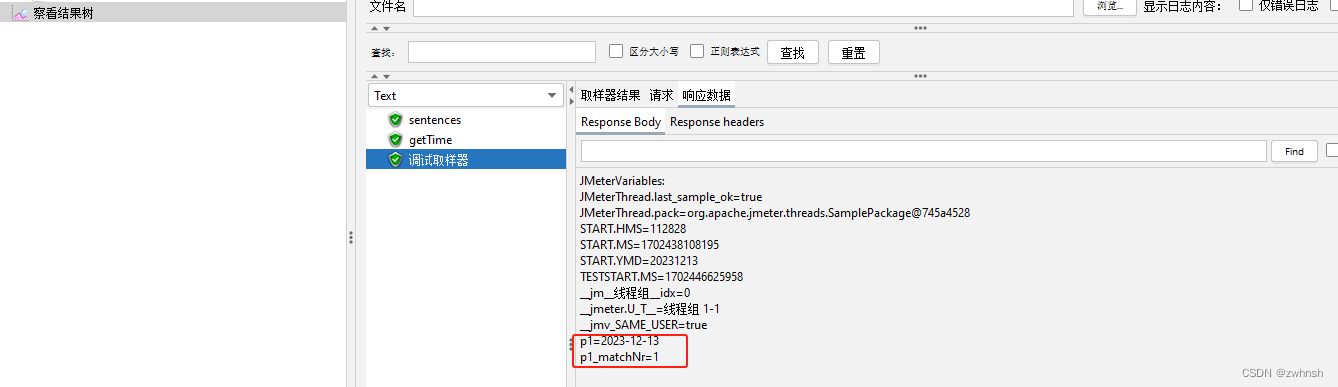
2.7.2、JSON提取器
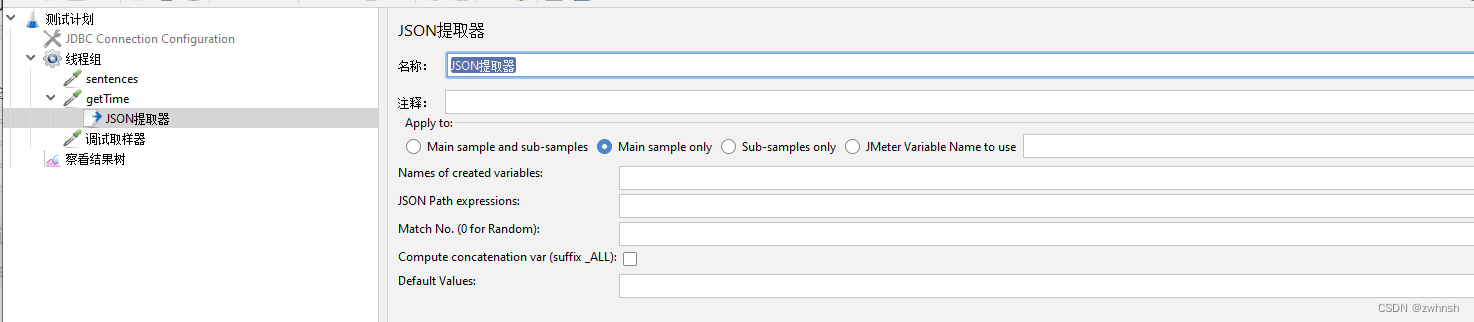
- 功能:可以通过JsonPath提取所需要的值
- 使用场景:取样器返回格式为json
- JsonPath语法:参考https://goessner.net/articles/JsonPath/
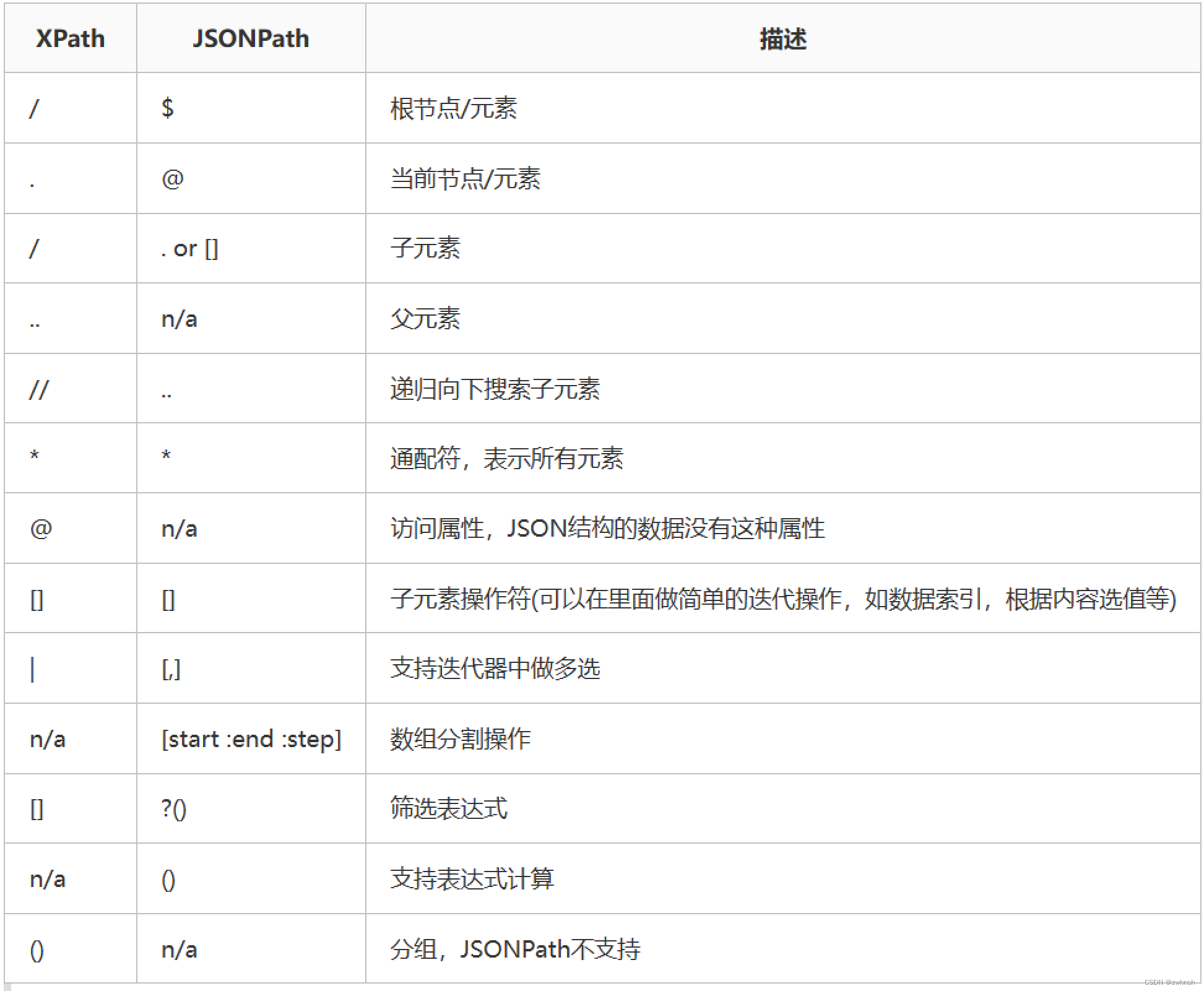
- jsonpath表达式在线生成:http://jsonpath.com/
- 参数说明:
- Compute concatenation var(suffix _ALL):计算连接变量。如果找到许多结果,则插件将使用‘,’分隔符将它们连接起来,并将其存储在名为 _ALL的var中
- 示例:
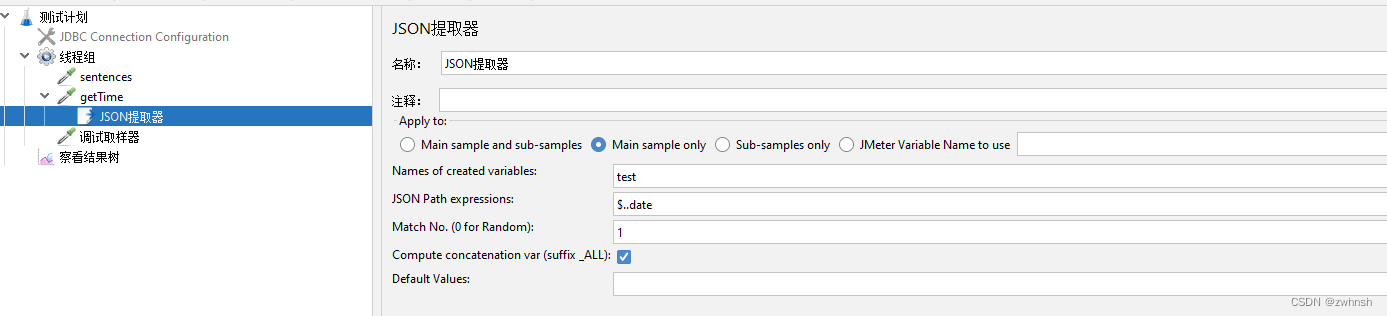
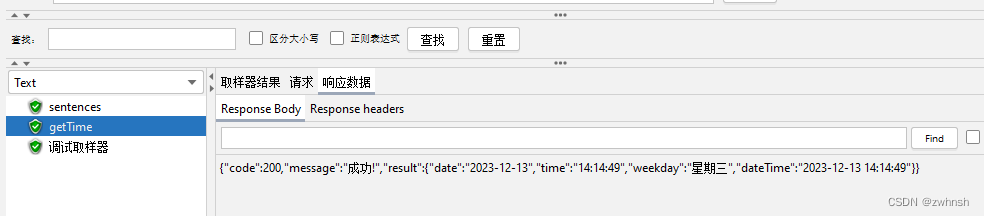
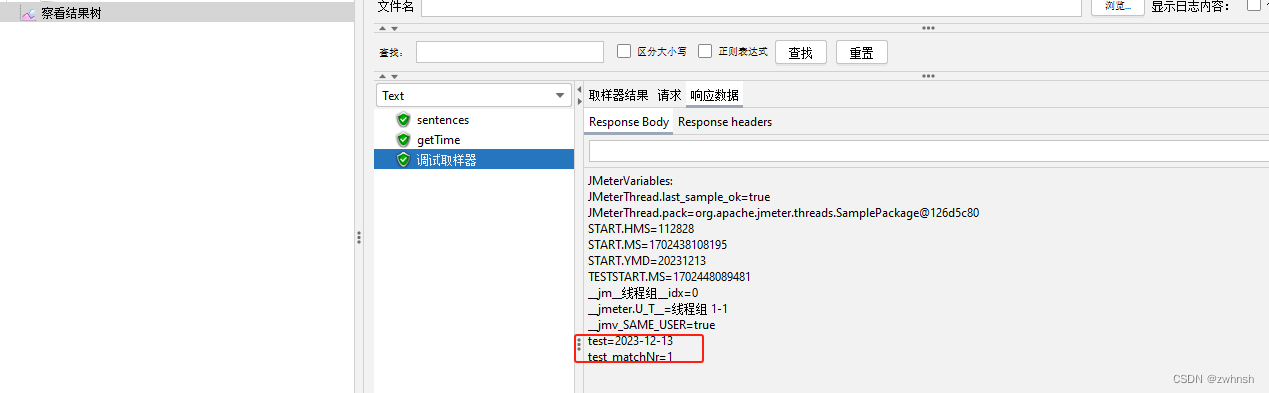
2.7.3、正则表达式提取器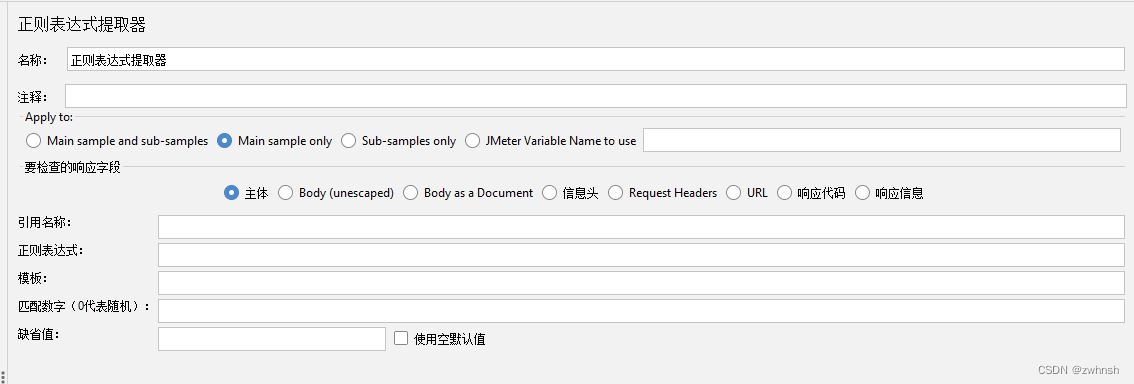
- 作用:可以通过正则表达式提取所需要的值,
- 注意事项:左边界和右边界不能缺失,如果有特殊字符必须用\转义符
- 参数说明:
- 要检查的响应字段:
- Body:响应体,不包含响应头; 最常用
- Body(unescaped):响应体,替换了所有HTML转义符;不建议使用
- Body as a Document:返回内容作为一个文档进行匹配
- 信息头:响应头
- Requeste Headers:请求头
- URL:URL
- 响应代码:响应码
- 响应信息:响应信息
- 引用名称:接收提取值的变量名
- 正则表达式:正则表达式匹配规则,如:“code”😦.?),“message”:"(.?)"
- 模板:对应正则表达式组号,从1开始,$1$表示取code值,$2$表示取message值,$0$表示全文匹配
- 匹配数字(0代表随机):当匹配出现多个值匹配时,通过该数字确认取哪一个,从1开始,0表示取随机,负数表示取所有
- 缺省值:未匹配到时,指定的默认值
- 要检查的响应字段:
- 示例:
- 服务器返回如下:
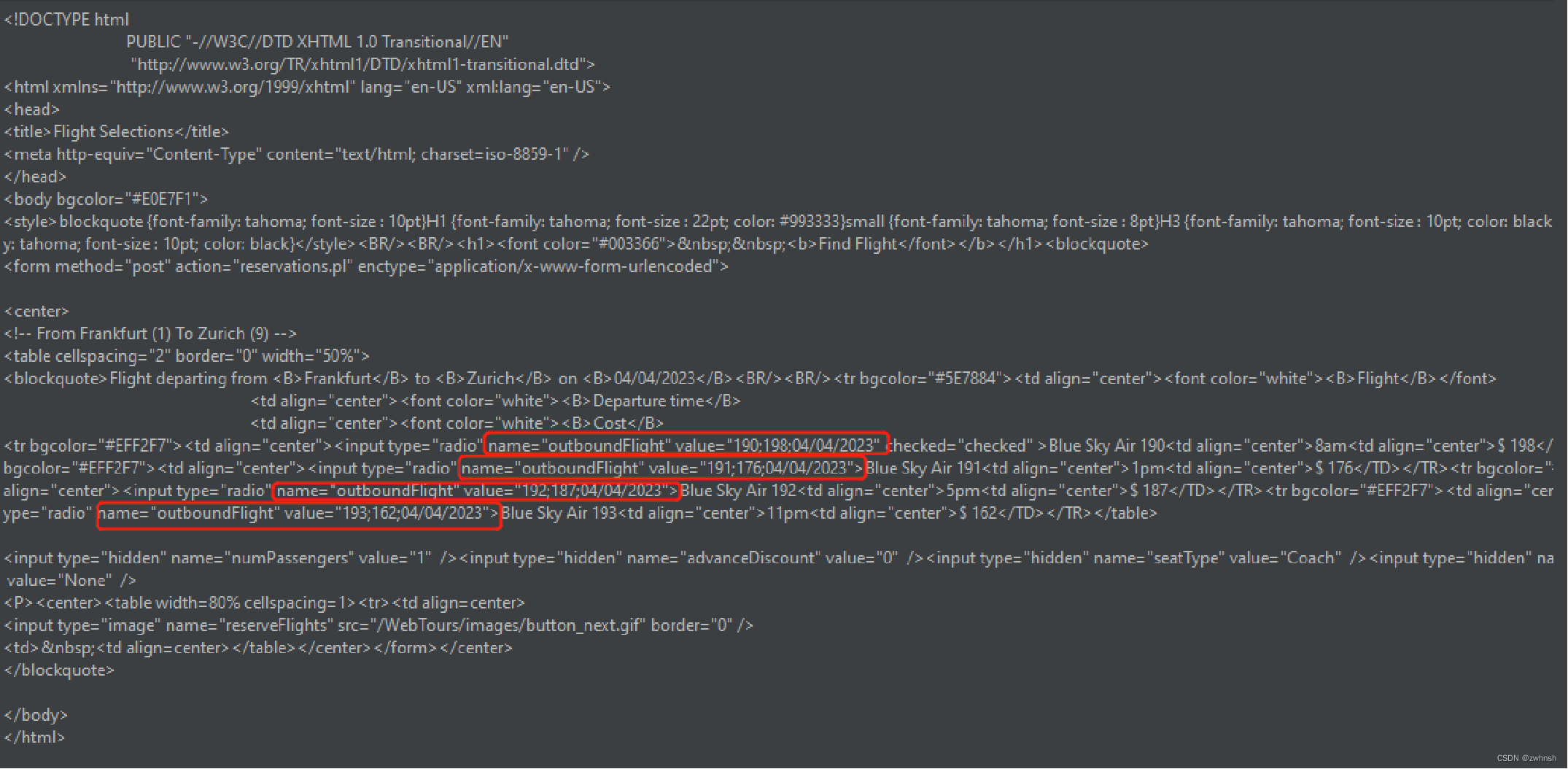
- 正则表达式提取器如下:

- 查看结果:
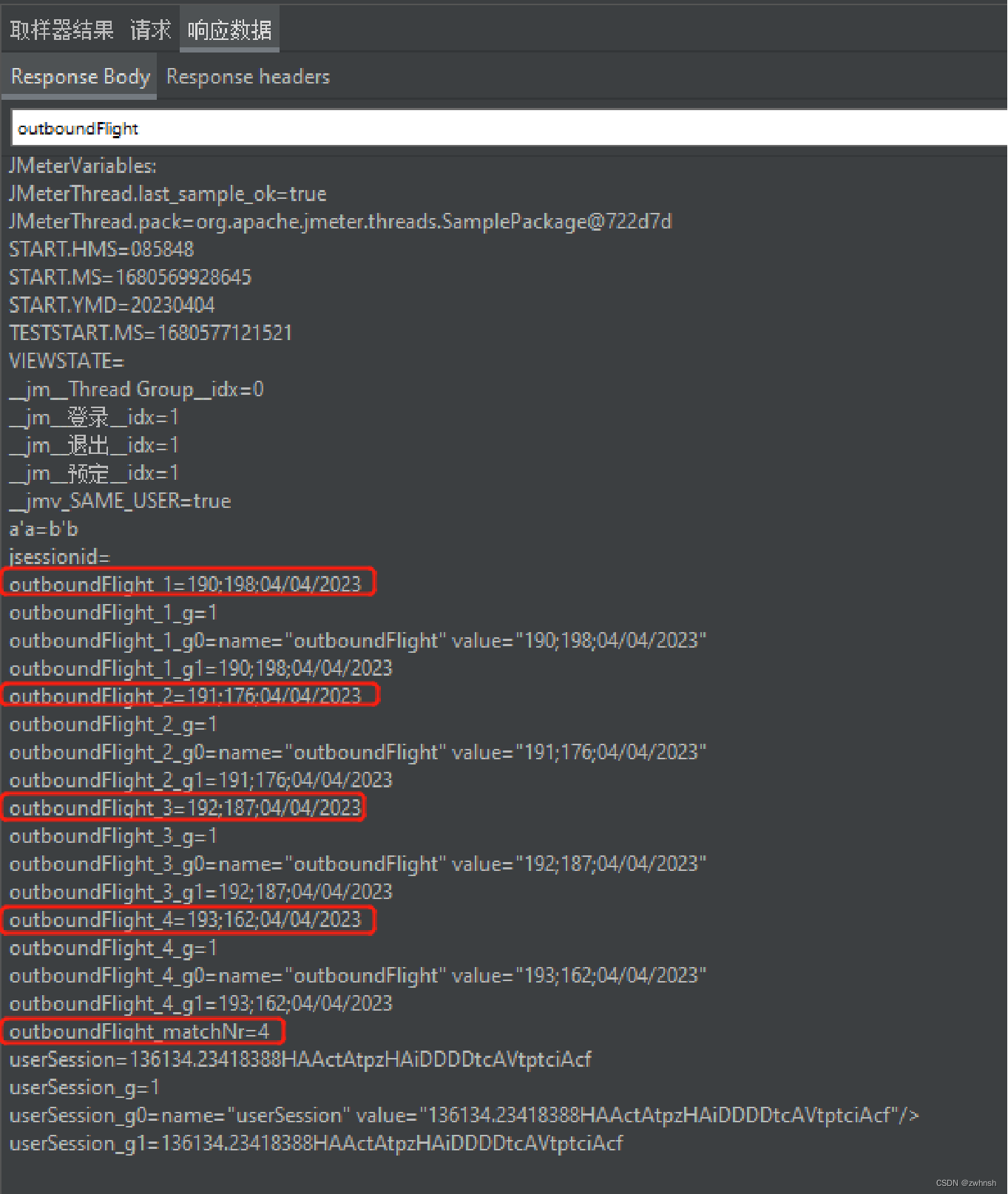
- 服务器返回如下:
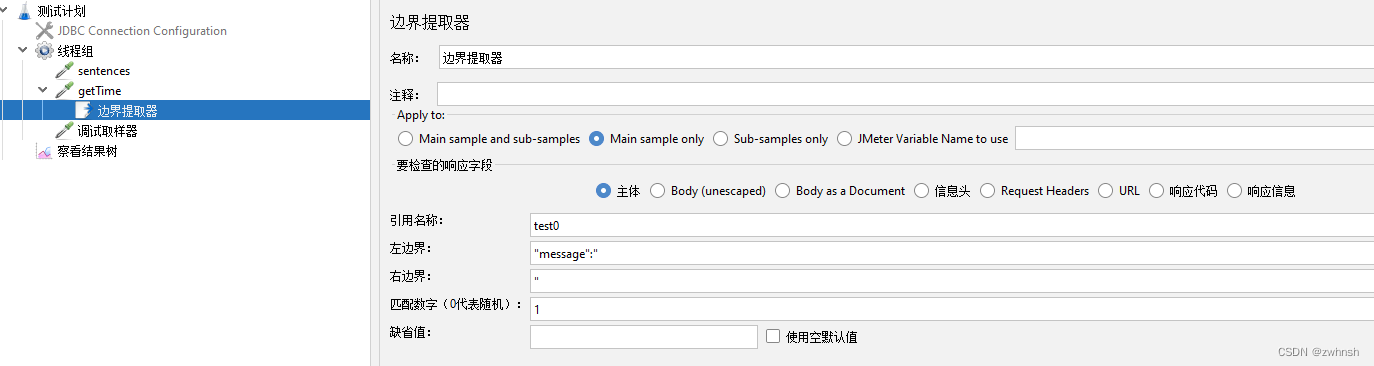
2.7.4、边界提取器
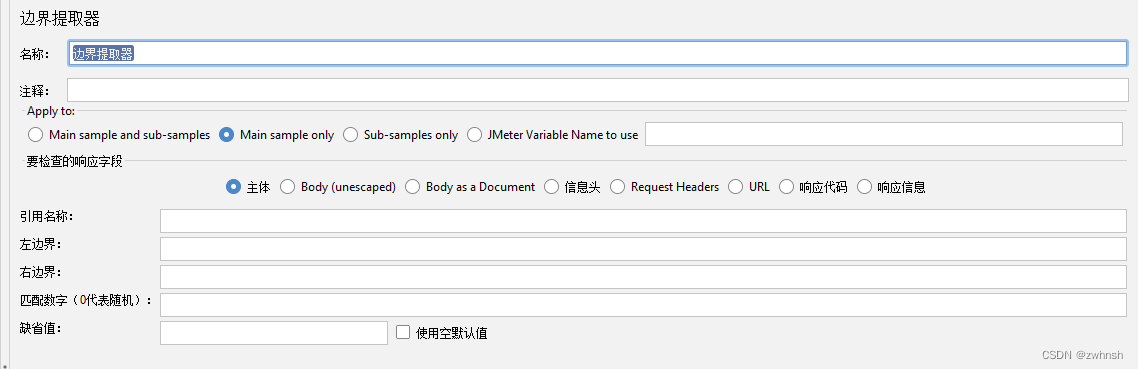
- 作用:根据左右边界提取所需的值,简单实用
- 参数说明:
- 左边界:需提取值的左边界
- 右边界:需提取值的有边界
- 匹配数字(0代表随机):取第几个值(0:随机,默认;-1所有;n第n个值),非必填
- 缺省值:匹配不到值的时候取该值,非必填
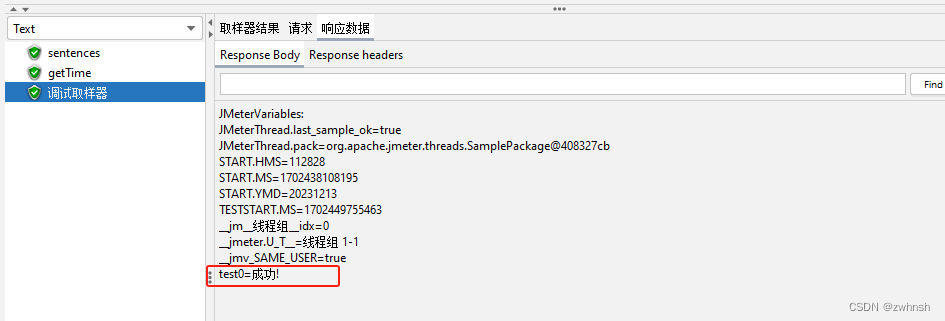
- 示例:

2.7.5、Xpath提取器
- 作用:使用Xpath语法提取所需要的参数
- xpath语法参考:https://www.runoob.com/xpath/xpath-syntax.html
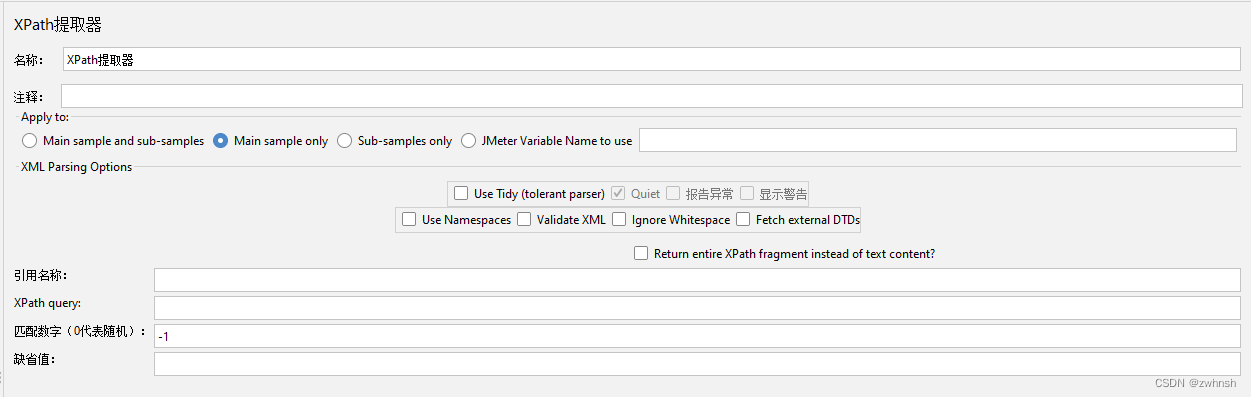
- 参数说明:
- XML Parsing Options:
- Use Tidy (tolerant parser):当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中
- Quiet:表示只显示需要的HTML页面
- 报告异常:表示显示响应报错
- 显示警告:表示显示警告
- Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨
- Validate XML:根据页面元素模式进行检查解析
- Ignore Whitespace:忽略空白内容
- Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容
- Return entire XPath fragment instead of text content?:返回文本内容的整个XPath片段
- 引用名称:存放提取出的值的参数
- XPath Query:用于提取值的XPath表达式
- 匹配数字(0代表随机):0代表随机取值,n取第几个匹配值,-1匹配所有
- 缺省值:未匹配到值时的默认值
- XML Parsing Options:
- 示例:
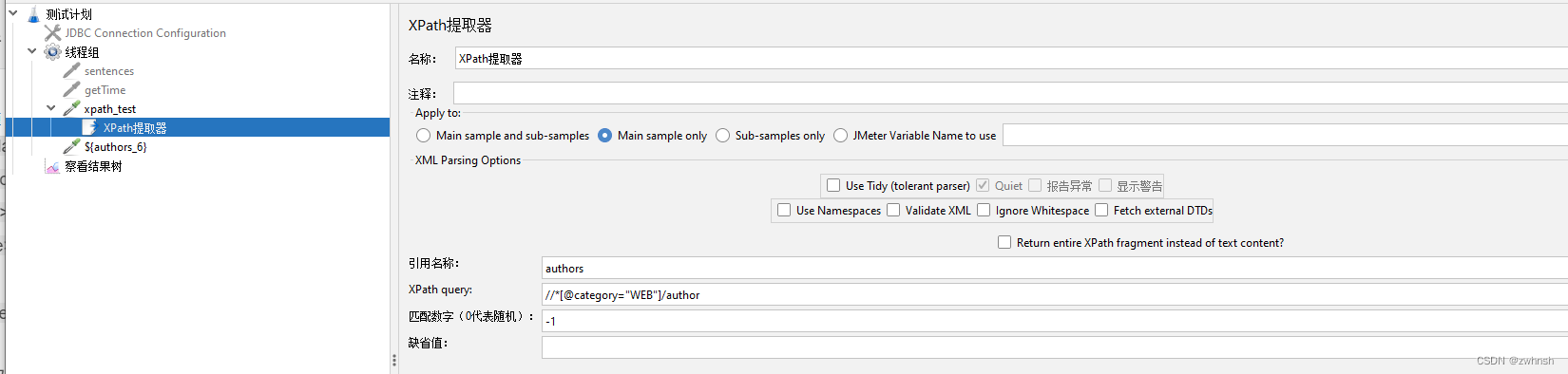
- 请求地址:https://www.runoob.com/try/xml/books.xml,响应如下:
<!-- Edited by XMLSpy? --> <bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore> - xpath提取器:
- 结果如下:
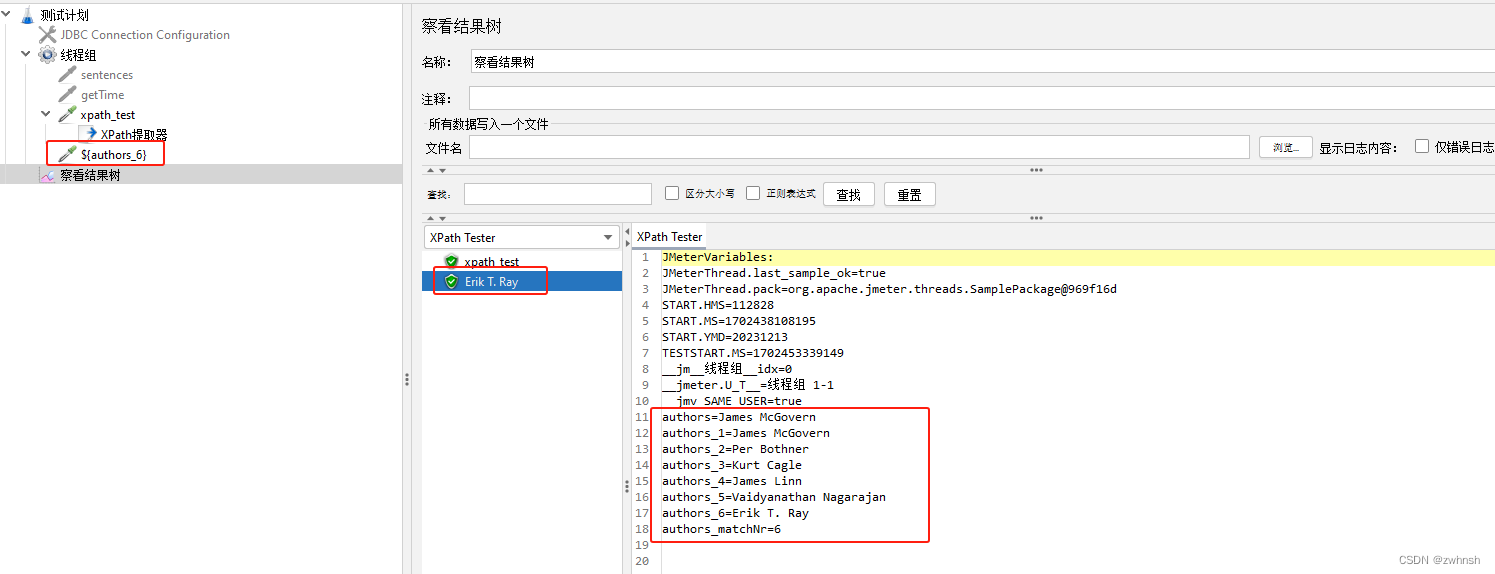
- 请求地址:https://www.runoob.com/try/xml/books.xml,响应如下:
2.7.6、XPath2 Extractor
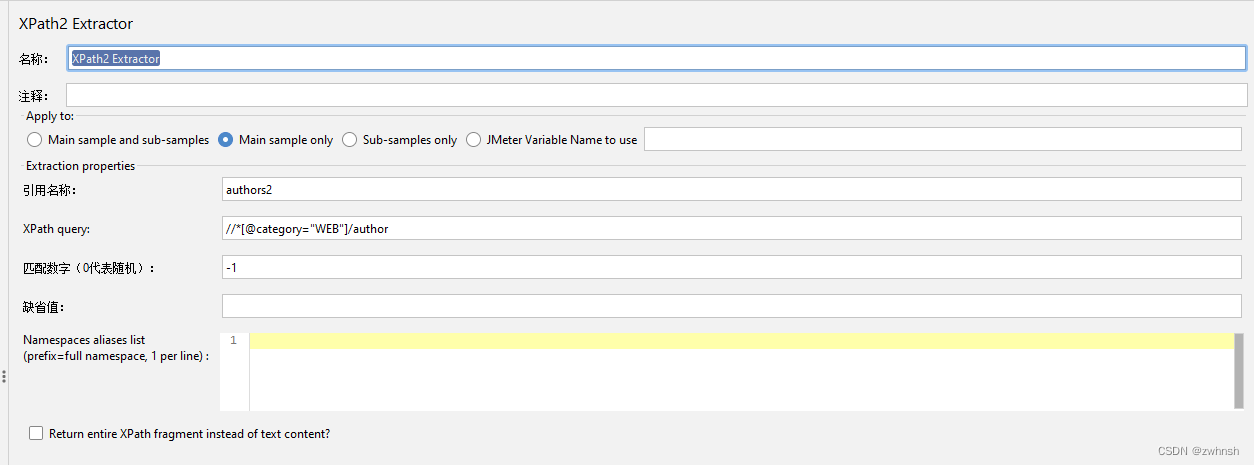
- 作用:使用Xpath语法提取所需要的参数,使用方法和xpath提取器大体相同。
- 参数说明:
- Namespaces aliases list (prefix=full namespace, 1 per line):命名空间别名列表。区别于xpath提取器的功能。有关命名空间的介绍,可参考:https://www.w3school.com.cn/xml/xml_namespaces.asp
- Return entire XPath fragment instead of text content?:返回文本内容的整个XPath片段。
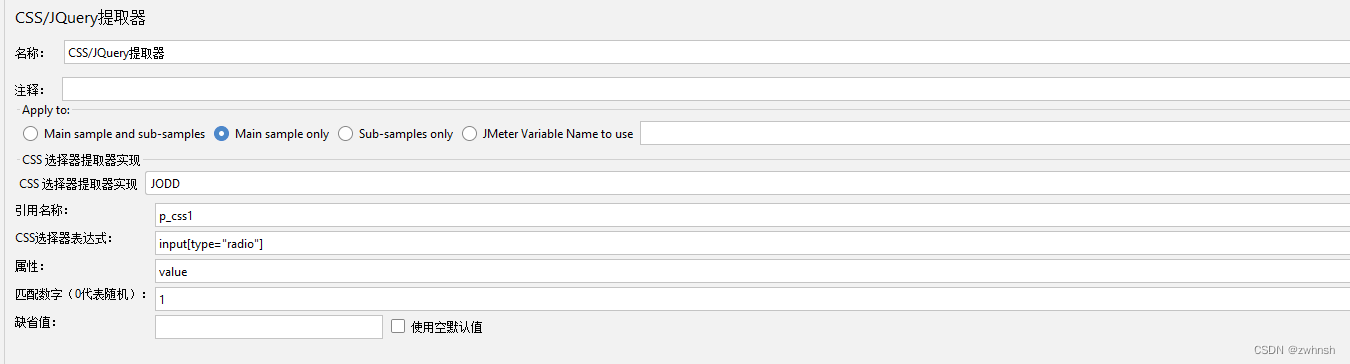
2.7.7、CSS/JQuery提取器
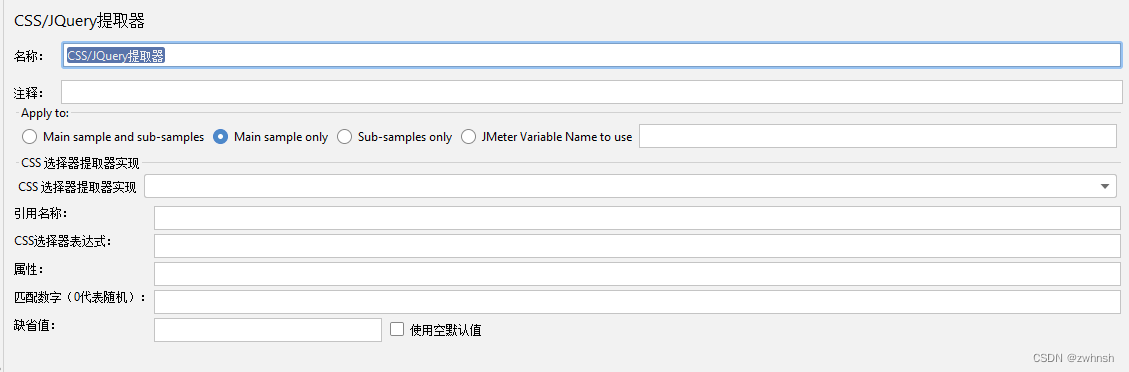
- 作用:通过css选择器定位页面元素并读取数据
- 参数说明:
- CSS 选择器提取器实现
- JSOUP:默认,不选时也采用该格式
- JODD:JODD格式
- 引用名称:存放提取出的值的参数
- CSS选择器表达式:CSS表达式
- 属性:要提取的元素的属性
- 匹配数字(0代表随机):0 代表随机取值,n取第n个匹配值,-1匹配所有
- 缺省值:未匹配到时的默认取值
- CSS 选择器提取器实现
- 常用的css选择器:
- id选择器:#id,如#kw
- class选择器:.class,如:.telA
- 元素选择器:element,如:input
- 属性选择器:[attribute=value],如[id=“kw”]
- 群组选择器:s1,s2,s3
- 后代选择器:s1 s2
- 子代选择器:s1>s2
- 更多参考:https://jsoup.org/cookbook/extracting-data/selector-syntax
- 示例:
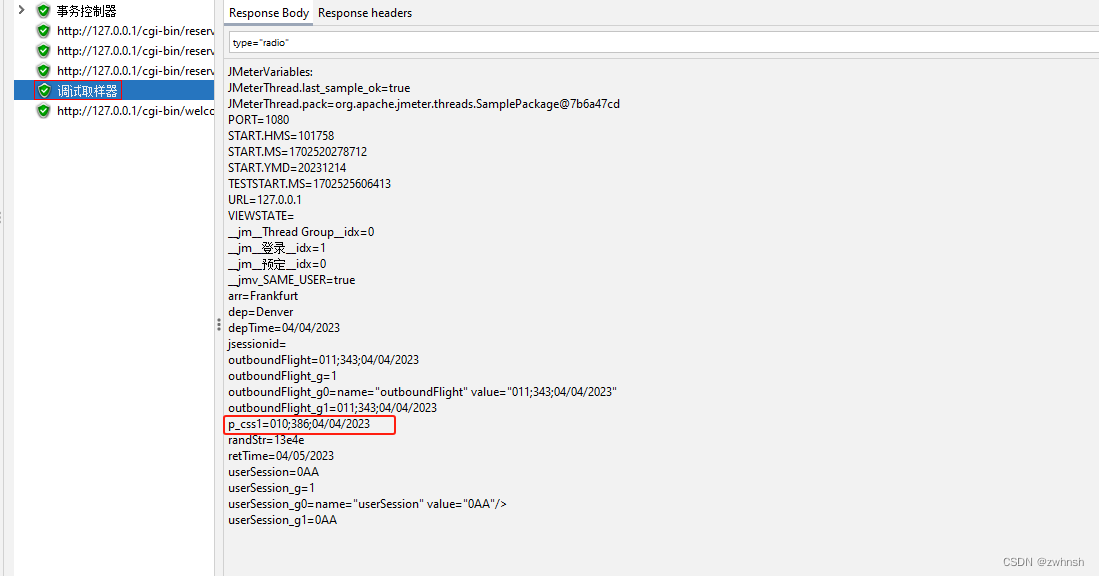
- 请求返回如下,包含type="radio"属性的input标签共4个,需要提取value属性值:
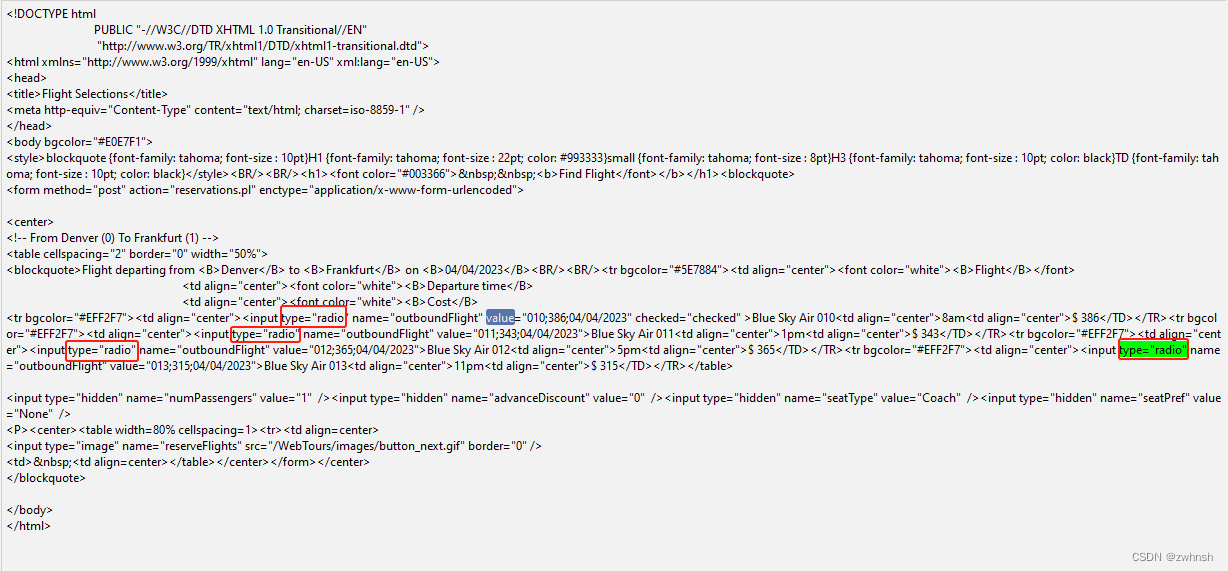
- 请求返回如下,包含type="radio"属性的input标签共4个,需要提取value属性值:
- css提取器如下,引用名称为p_css1,css表达式为包含type="radio"的input标签,提取value的属性值,取第一个结果(下标从1开始):
- 查看结果:
- 查看结果:
2.7.8、结果状态处理器
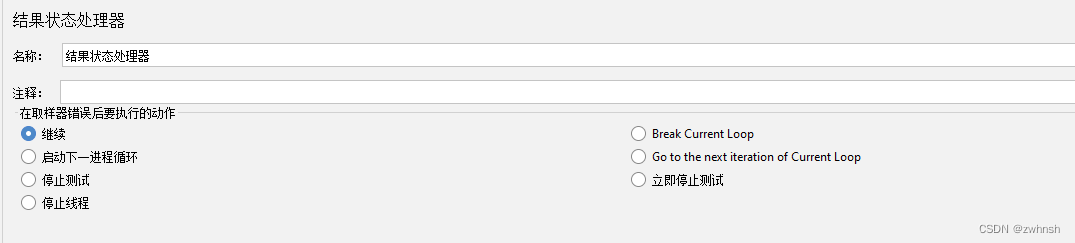
- 作用:测试用例失败之后进行的一些操作设置,能针对单一取样器设置运行错误的处理逻辑。
- 参数说明:
- 继续:忽略错误继续执行。
- Break Current Loop:跳出当前迭代
- 启动下一进程循环:本次线程不执行,开始执行下一个线程迭代
- Go to the next iteration of Current Loop:继续当前线程的下一个迭代,报错后,本次迭代不执行,执行本线程的下一个迭代
- 停止测试:执行完本次迭代,再停止测试
- 立即停止测试:立刻停止线程组
- 停止线程:将异常的线程移出线程组,不再执行,其他线程继续执行。
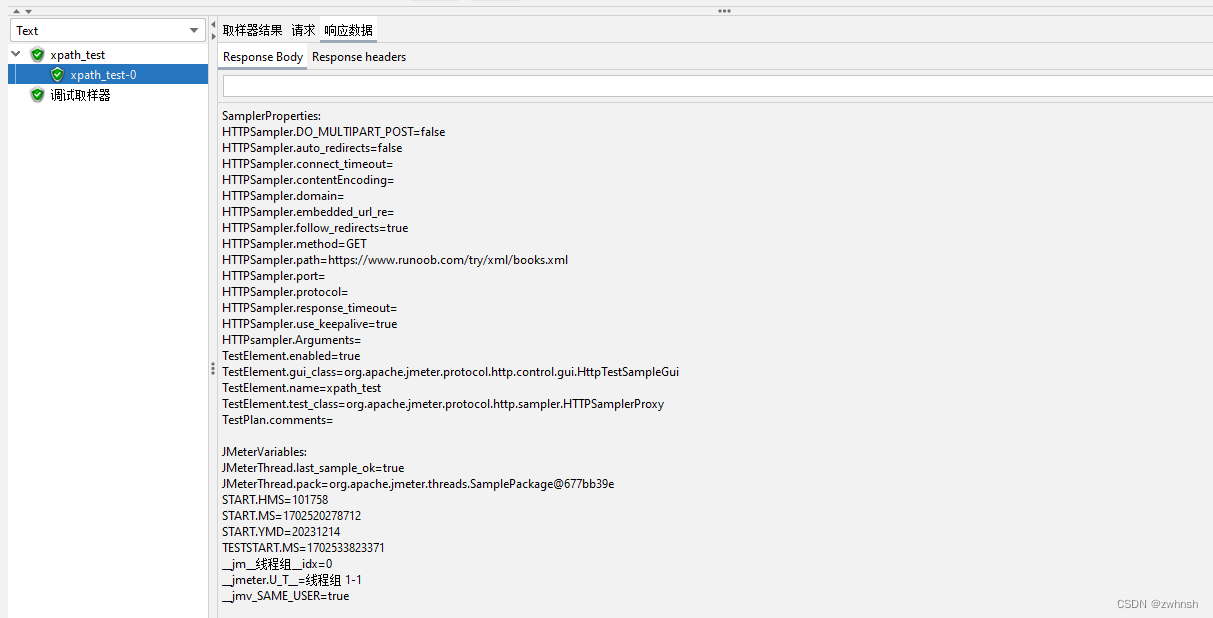
2.7.9、Debug PostProcessor

- 调试后置处理程序,一般用于脚本调试,配合查看结果树,可以看到取样器的变量、参数等,和调试取样器功能类似。
- 参数说明:
- JMeter属性:在Jmeter启动时加载到内存的Jmeter使用到的配置参数,由jmeter.properties定义,一般变化不大,通常无需显示(False)
- JMeter变量:由用户定义的参数,默认为True
- 取样器属性:提取服务器响应数据得到的参数,默认True
- 系统属性:操作系统层面设置的各种参数,如JAVA_HOME等,默认False
- 示例:
2.7.10、JDBC后置处理程序
- 作用:在取样器完成后执行SQL语句
- 使用方法参考JDBC 预处理程序。
2.7.11、JSR223后置处理程序
- 参考JSR223预处理程序
2.7.12、BeanShell后置处理程序
- 参考BeanShell预处理程序
文章来源:https://blog.csdn.net/weixin_42115131/article/details/134968403
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java进程内存总览
- 羊奶是控制血糖的新选择吗?
- 交易大师的成长之路:每个阶段都是一次觉醒
- GBASE南大通用 访问其他数据库服务器
- 创业公司该怎么进行季度绩效考核?
- windows vs cmake项目+vcpkg
- 矩阵式键盘实现的电子密码锁
- 【VTKExamples::VisualizationAlgorithms】第一期 SingleSplat单个溅落点
- 【JAVA基础(对象和封装以及构造方法)】----第四天
- 3、python-常见数据类型-元组(tuple)