动静态库链接
一 制作静态库
1?如何使用其它源文件的函数

????????首先我们的主函数是在main.c,然后mymanth.c里面有一个函数是用来计算的,我们如何在main函数内使用这个mymath.c里的函数呢?
????????方法1?直接将mymath.c和对应的.h文件都给使用者,使用者包含了头文件,gcc直接链接对应的源文件,就可以使用了。那在vs下包含我们自己写的头文件,编译器如何知道链接哪个.o文件呢,貌似是在同一个工程下创建的源文件都会被编译,不是靠头文件名判断链接哪个源文件,头文件的最大作用就是提供声明,免得链接前就报错说找不到函数,最终链接哪个源文件是看主函数用了哪个.o文件的函数。若是不想给源代码给别人看到,又想别人能使用,就用下面的方式。
????????方法2?提供一个库和头文件,库是代码文件被编译成.o文件然后打包形成的,为什么要有头文件呢?这个头文件一方面是给用户看的说明书,因为库里面包含的已经是.o文件了,全都是二进制了,谁能从一堆二进制中看出函数如何使用,如何传参,还有一方面这是大佬制定的语法规定,使用前必须声明,所以需要头文件把函数变量声明放在使用前。妙,不仅可以不让自己的实现代码给别人看,还能让别人使用。
2 接下来了解什么是库?
????????库的制作思路:先将源文件编译形成一个个.o文件,然后再打包到一起,为什么要打包呢,因为是一个个.o文件,我们后面使用是要一个个链接的,太麻烦,所以就合并到一起。要gcc +所有源文件名一起编译链接才可以。
????????也就是说库里面都是.o文件? 那为什么是.o文件呢,因为这些库本质就是一个一个的源文件,为了减少使用者的工作量,就帮我们处理到.o文件,我们只需要链接即可,而且还可以保密,这个链接动作肯定是我们编译器做的,虽然将源文件转为汇编也可以保密,但是会增加使用者的工作量,因为此时的代码还不能链接,还要使用者将代码处理成.o文件才可以。

????????形成同名.o文件时的可不带-o选项来指定文件名。

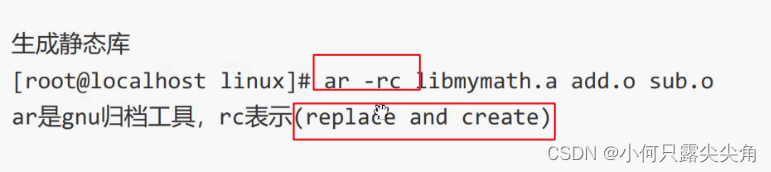
3?生成库
????????那如何打包:用如下命令即可将多个.o文件归在一起。r是replace的缩写,貌似是会将库内的重复直接代替,不存在重复的就正常归入库内,c是creat的缩写,就是创建库,如果库存在带-c应该没意义的。
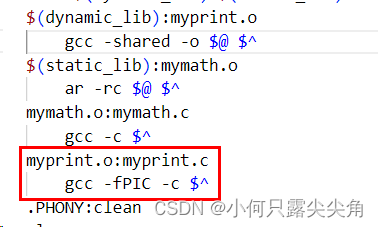
makefile文档
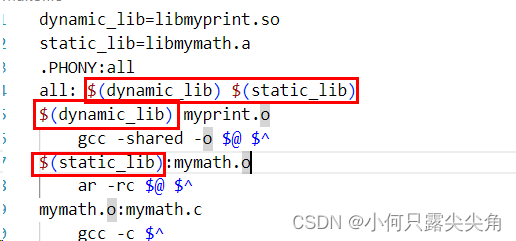
dynamic_lib=libmyprint.so
$(dynamic_lib):myprint.o
gcc -shared -o $@ $^????????makefile语法格式:dynamic_lib = libmyprint.so其实是在定义变量,dynamic_lib是变量名,后面是变量的值,这个变量在使用时类似于宏替换,$(变量名,例如dynamic_lib)会直接将变量的值替换到使用处,那如果写成dynamic_lib : libmyprint.so那就意味我们要用后面的依赖文件生成一个文件,名为dynamic_lib,意义是不一样的,好,那为什么不直接写成下面这样呢?
libmyprint.so:myprint.o
gcc -shared -o $@ $^????????因为方便修改文件名呗,如果有多个地方都要用到libmyprintf.so,一旦这个文件名修改了,所有地方都要改变,如果用了这样宏替换的方式,只要改=后面的即可。
? ? ? ? 如下,如果libmyprint.so和libmymath.a的文件名变了,只要改两处地方,不用这样的替换方式,则要修改六处地方,维护成本大大增加了。
4 发布库
????????也就是把库的头文件和库放在某个文件夹下,之后直接给别人这个文件夹即可,因为可能要给别人提供多个不同功能的库,然后这些库又各自有一个头文件,总不能把库文件和头文件一起丢给使用者吧,所以就按如下目录分开存储。

????????我们先就制作了两个库,一个是动态库libmyprint.a,内部是Print函数实现,也就是打印传入的字符串。

????????还有一个是静态库libmymath.so,内部是加减乘除四个函数的具体实现,制作和使用后面提。

二 如何使用自己的静态库
1?包含头文件
? ? ? ? 显然第一步就是在main.c中包含的头文件,然后像平常写代码一样,直接用库里的函数。

????????然后我们用gcc编译一下,它说找不到头文件,显然这里展开头文件首先要找到头文件,而我们只给了一个头文件名,却没给头文件的路径,所以当然会找不到,那我们换一种包含头文件的方式。先前发布库时提过头文件和库文件的路径。

????????这个时候就找到了,虽然还有错误,但这是链接错误,证明和解决后提,当然上面包含头文件带路径,虽然解决找到头文件的问题,但是不适用,而且我们平时写代码记头文件名就够难受了,怎么可能记住每个头文件的路径呢,还得看下面的方法。
2?找到头文件方法
? ? ? ? 方法1:gcc编译时带-I选项让编译器去指定目录下找。有意思的是,如果我仅仅只是包含一个头文件,然后不用库的函数,gcc可以编译通过,不会出错,如下图。
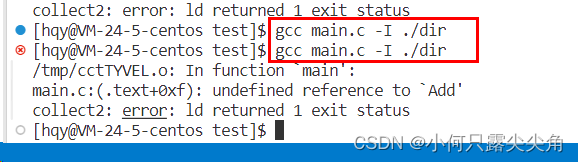
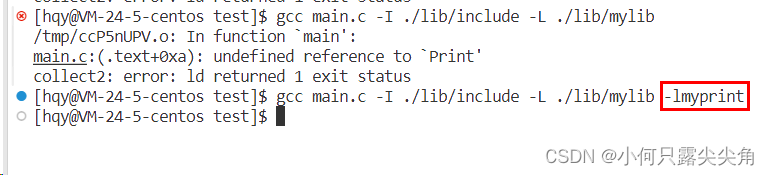
????????一旦用了里面的函数,就会出新的错误,这个错误称为链接错误,先前没出错我觉得是因为我们并没有使用库的函数,此时就不会去链接对应的库,也就不会出现链接错误。
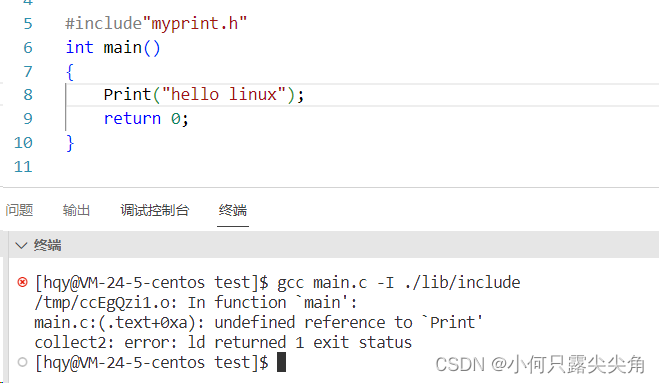
????????如何验证是链接错误呢??如下图,gcc -c选项就不会报错,就说明代码编译的前三个步骤没问题。
(具体步骤我在博客曾提及编译器对代码的处理,分阶段介绍 (1)-CSDN博客)??????
????????当然头文件还得指定路径,因为头文件查找是预处理的步骤,-c是处理完汇编步骤,因为预处理在汇编之前。
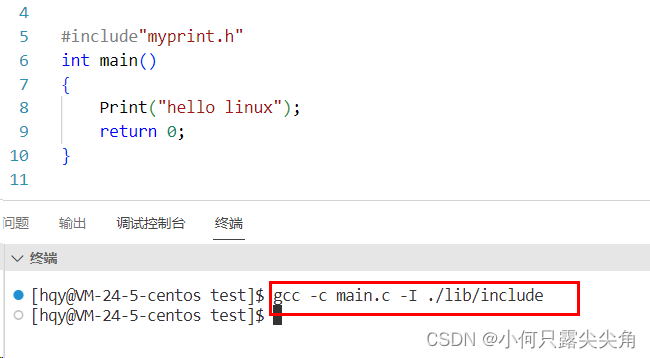
?????????gcc main.c -L和gcc -c main.c -L区别,前者是将mian.c处理完,此时带-L指定库链接才有意义,而后者仅仅将源文件处理到.o文件,没到链接阶段,那些选项没意义。

????????方法2:那我以前写代码也包含了头文件,例如stdio.h,当时gcc也没有指定路径,当时就没出问题,显然这些系统头文件是保存在某个系统路径下,所以我们可以选择将自己的头文件丢到系统的默认路径下,此时gcc命令就不用带-I选项了。
????????也可以用刚刚学到的知识,把软链接存到这个系统默认的查找路径下,存硬链接我实验后发现不可以,我觉得是因为系统默认保存头文件的路径和我们的代码文件路径不属于同一个文件系统,然后硬链接只能拿到inode,然后由于文件系统的不同,确认错了分区,也就找不到文件。

3 解决链接错误
? ? ? ? 为什么会有链接错误呢,首先我们只是包含了头文件,要链接什么库,gcc是不知道的,因为这个是我们自己写的头文件,gcc不知道哪个库与之对应,所以我们就要用gcc-L指定找库文件的路径,-l选项指定库名,大佬设计时就是-L和-l选项分别跟路径和名称,别管为什么不合并。
????????为什么要指定库名呢,因为编译器不认识第三方库,所以要指定链接库名,gcc是必须认识,c语言,c++官方的库以及系统调用,这样我们在使用时包含一下头文件,编译器会去默认路径找头文件,而且也知道包含哪个库文件,如果有哪个编译器说自己不认识官方库,要程序员自己指定库名,这个编译器绝对没人去用,太不方便了。
? ? ? ? 什么叫不认识第三方库呢,因为编译器不知道你包了这个头文件后,要对应哪个库文件,库文件在哪,所以要带-L指定库的路径,-l指定库名,而库一般放在一个路径下,所以一次-L指定即可,但是要多次-l指定库名。
? ? ? ? 这两个选项缺一不可,库名可不是库的文件名,是去掉前缀和后缀的,什么是前缀,lib就是前缀,静态库后缀就是.a,动态库是.so,因为这个库的命名是规则固定的,所以绝对会存在前缀和后缀。? ?
?4?命令简化 ? ?
????????编译一次又是-I,又是-L,还要-l,如何简化呢???

????????先前解决如何找头文件时我们提到,gcc编译时只会去默认的路径上找头文件,同理库文件也是如此,所以我们想要包含头文件和库文件的时候不写路径就可以借鉴找头文件的方法2,总结如下。
1?把头文件放在系统默认的路径上/usr/include,库文件放在/lib64下,这又叫安装。
2?在系统路径下建立软链接
????????软链接可以和头文件同名,但是就要让给每个头文件建立软链接,这样比较繁琐,由于头文件一般都统一放在一个目录下的,如下,都放在include目录下。
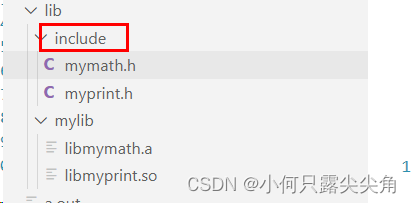
????????所以可以给这个目录建立一个软链接,gcc -l(小L)指定了库名,-I(大写i),之所以头文件不用指定名称,是因为我们在包含的时候写了,然后使用如下。
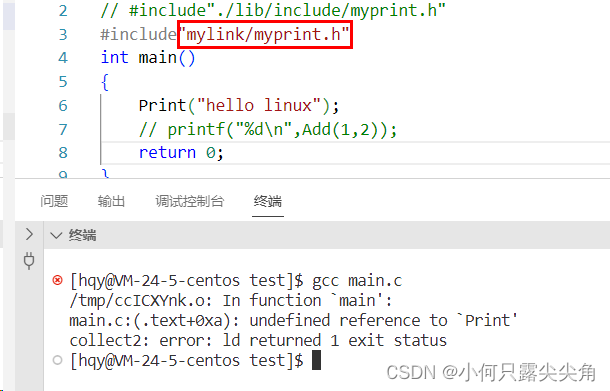
????????我们就发现此时报的是链接错误,说明头文件能找到,包含头文件的时候路径也不是特别长,也还能接受,
3 库文件的软链接的名字要和库文件名相同
????????如果也是和目录建立软链接,使用如下,那这个软链接其实是没有意义的。对gcc命令的简化有限。

5?要点补充
? ? ? 1? ?软链接的链接对象的路径最好用绝对路径。

? ? ?2? ? ldd可以查看可执行程序的动态链接库,有动选动,没动有静只能选静态库,不带-static也会去链接静态库。什么叫有动选动,无动选静,我-l不是指定库名了吗,动态库和静态库的库名是一样的,所以才说有动选动,无动态库才选静态库。
三 如何制作动态库
? ? ? ? 当我们学会了静态库的制作,就知道动态库的制作首先肯定是要把.c文件编译成.o文件,因为动态库也是要被gcc链接的,而链接只链接.o文件,然后打包,接下来我们就把下面的.c文件打包生成动态库。
1 生成.o文件
???????????????gcc -fpic -c +源文件,静态库是直接-c生成.o文件,而动态库却会多带一个fpic选项,选项用处最后提,没错是最后面才提及,因为真的需要很多前置知识,现在不好理解。
2 打包生成库
????????gcc -shared -o +动态库名 +(要打包的.o文件)
????????gcc内置了动态库的打包方式,为什么没有静态库的打包方式呢,不知道啊,估计gcc设计者希望你多用动态库。
? ? ? ? 我们发现动态库有x权限,静态库没有,这意味着动态库可以被执行,但不可被单独执行。

????????也就是说我们不可以直接./libmyprint.so,但是我们知道动态库的代码是会被其它进程使用,cpu会跳转到动态库执行代码,所以这个文件带有x权限也不奇怪。
? ? ? ? 但是cpu不会跳转到静态库去执行代码,因为静态库并不单独存在于内存中,它直接被复制到各个进程的代码文件中,所以静态库文件没有x权限。
????????我们先前提过我们生成了一个libmymath.a和libmyprint.so,显然前者为静态库,后者为动态库,现在我们要用makefilr同时生成动态和静态库并发布。

????????all: $(dynamic_lib) $(static_lib)这句的意思是要生成一个all文件,依赖文件就是两个库文件,而我们又没写对这两个文件的处理方法,这个时候就会先生成两个库文件。

????????然后发布一下,把库文件和头文件放在lib目录下的不同子目录中。
四 使用动态库?
????????1?让gcc知道动态库
显然使用动态库也要用-I和-L分别指定头文件和库文件路径,再用-l指定库名,我这不用加是因为先前建立了软链接。

????????2?让加载器知道动态库
什么叫让加载器知道动态库,咋突然冒出个加载器,首先gcc编译链接动态库,此时应该是加载器让动态库加载到了内存,因为最后代码处理动作都要交给cpu执行,因为cpu只和内存打交道,那此时不是已经让加载器加载了吗,为什么./a.out报错说找不到动态库呢?

? ? ? 第一次加载,gcc -L和-l给加载器提供了路径,使其可以被找到,但是./a.out还要加载一次,这次没有告诉库路径,所以会报错。当然这个理解还有点小问题,不过我们首先要意识到./a.out,此时磁盘上的a.out和库要再次被加载器访问。
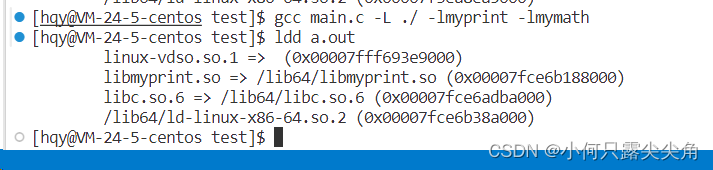
????????如上图,我们可以发现a.out在被编译完后ldd就能获取到它的动态链接库的路径信息,是因为a.out内有动态库的链接信息,ldd获取的就是这个链接库的信息,那问题来了,为什么下面这个图ldd发现a.out的动态库没找到不立刻报错,

????????因为动态链接的延迟机制决定了,动态库的报错是在运行到具体找动态库的代码处才报错,当然我写的代码比较少,所以看起来是./a.out一运行就报错了,其实是代码太少,一下子就执行到找动态库的代码了,然后就报错了。
3?如何让加载器找到库
? ? ? ? 前面我们只是稍微提及了一下为什么加载器会找不到库,接下来就来解决一下。
因为加载器也会有一个默认搜索路径,所以要解决加载器找动态库的方法,和之前让gcc找动静态库解决方法相同。
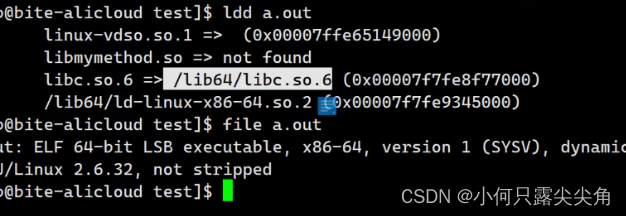
????????1 将库文件拷贝到/lib64或者/usr/lib64,这个路径就是加载器的默认搜索路径。

2?在系统目录下建立软链接,要同名,实际上这一步我们已经提过了,因为先前库链接错误解决方法也是在系统路径下建立软链接,不过当时我们验证了和库文件的当前目录相连接,gcc也可以找到,就是还要带-L,但是对于加载器来说,就得把同名软链接保存到系统路径下,不用同名加载器找不到。
3?环境变量
????????把动态库文件路径保存到LD_LIBRARY_PATH中,显示这只是暂时有效。?还有永久有效的方法,弄到系统环境变量文件中。
4?在/etc/ld.so.conf.d下创建一个.conf结尾的文件,文件内保存路径即可。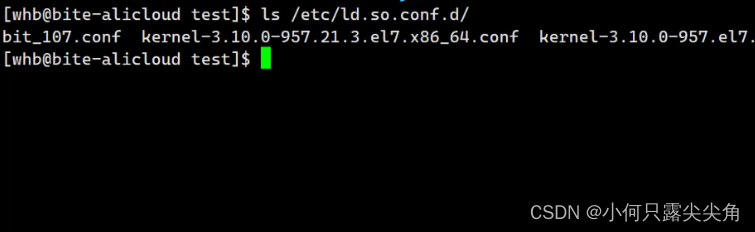
? ? ? ? ldconfig:重新导入文件,才会重新加载这些文件,然后加载器才能看到这些路径。这一步要小心。
????????显然一个动态库可以被多个程序使用,那动态库就被所有进程共享了。那如果os存在多个库,必然要对其进行管理,动态库如何被多个进程共享的呢?
五?动态库如何被共享
1?大致原理
????????代码编译时,printf这个库函数大致就被转为某个地址,动态库肯定要被加载到内存,不然我空有地址有什么用呢,那进程如何看到这个动态库呢?显然要通过页表。
????????那动态库就要在页表内有映射关系,那动态库要映射到哪个区域呢?是进程的代码段还是共享区?设计者让共享区映射动态库。为什么是共享区呢?????????代码段不可以吗?共享区和代码段虽然都存代码,但代码段的区域属于进程私有,而动态库显然是属于多个进程共享的,如果非把动态库放到代码段,那动态库所在的内存页标志就设成不共享的了,那别的进程估计就不能用了。
????????若动态库里的全局变量被多个进程修改,此时是否会影响进程独立性。不会,因为在用户空间,所以会发生写时拷贝。而内核空间是os使用的,其它所有进程偶尔会访问这个内核空间,所以我认为这个内核应该算是所有进程共享,本就不属于某个进程,不会发生写时拷贝。
????????虽然我们大致知道动态库是要被加载到内存,然后用页表将虚拟地址转为物理地址,可是还有些问题被忽略了,1 什么是物理地址,2 什么是虚拟地址,虚拟地址怎么来的,但是有一点我是先前提过的,代码中的变量和函数调用都会被转为某个地址,而这个地址一定是虚拟地址,os不可能让你拿到物理地址(初识进程以及父子进程-CSDN博客),这篇博客中我提过程序用的地址都是虚拟地址。
3 cpu如何得知正文段什么地方有指令,如何访问下一个指令?这些都要在下面一一解释。
2 程序未加载前的地址
? ? ? ? 首先编译好的文件内部已经有地址了,这个地址就是虚拟地址的源头,还要再转化一下就可以直接填入到页表左侧,也就是说编译的时候为了方便os加载,方便建立映射关系,提前把文件分段编译好了,为产生虚拟地址做准备。所以为什么编译器要把程序分段编译,就是为了照顾操作系统建立虚拟地址,此时我可以稍微打破学科界限,噢,怪不得编译原理没说为什么要分段编译,上来就说怎么分段的,原来答案在操作系统。?????
? ? ? ? 我们在vs下写代码,进入汇编时发现每句指令前面都会有地址,这个地址其实就是虚拟地址,那这个地址是存在文件里的吗?之后这个文件加载到内存时,这个地址会给页表我理解,给完后这些就舍弃了吗?感觉太浪费了,os不会做这么多意义不大的工作,所以我觉得文件里绝对不是像下面显示的那样存一个地址,然后存一个指令或者数据,因为没必要给每句指令存地址。

? ? ?前面说了可执行程序是分段编译好的的,一般可执行程序只存各段的起始地址,可是函数调用不是要被转为call +?函数虚拟地址吗,只有段地址如何算出虚拟地址?
????????首先肯定是cpu计算出的,cpu如果获取了每句指令大小结合段地址,是不是就可以算出每句指令的地址,这点加减法cpu肯定能算出来,所以如果我调用了func()函数,代码编译的时候就要找到func函数定义的位置,然后计算它的虚拟地址,最后填到func()函数的调用处,转为call+虚拟地址的指令,那指令大小如何获得,下面说。
? ? ? ?可是cpu是执行代码首先应该能认识我这句代码吧,那cpu如何认识的我们这句代码,并去做对应动作的?
????????首先cpu内部内置了一个一个的指令集合,这些指令集合是有名称的,这个名称是二进制序列的,而每句代码最后都会被转为一个个的指令集合名,然后cpu就根据名称找对应的指令集合去执行。????????原先我以为二进制编程就是不停地输入10,让计算机对01进行响应,也就是开关某个电路,最后不停对各个电路接通闭合最终达到某种效果,原来是输入一个又一个的指令名称,后来为了方便记忆这些名称,就有了助记符,也就是下面的push,move,此时就进入了汇编编写代码的时代。那是谁在cpu内置了这些指令集合呢,显然是做cpu的工程师。
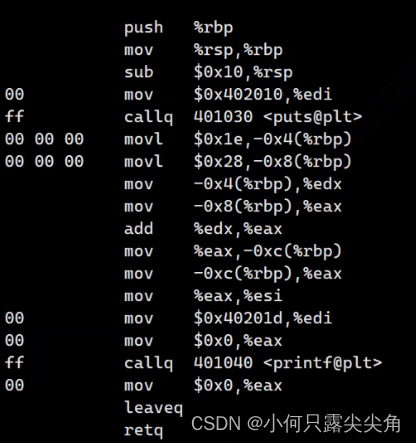
? ? ? ? 综上,我们就知道为什么cpu能认识我们的代码了,因为编译器会把代码转为二进制,显然这种二进制有某种格式,能让cpu能从一堆二进制区分哪些指令集合名,哪里到哪里是一句完整指令,然后去执行指令,此时我们就知道原来我们用的c,c++是如何来的了,是先有cpu上的指令集合,再有助记符和指令集合名称做映射,然后高级语言对多个汇编再封装,形成一句普通的代码。
????????既然一句完整指令的二进制都被读取了,那这句指令的大小不就知道了,这个下一句指令的地址就是当前地址再+当前指令大小,就可以啦。此时我们就解释了代码文件(包括动态库)中的虚拟地址是怎么来的了,还有就是稍微知道cpu如何找到下一条指令了。
3 程序加载后的地址
? ? ? ? 当指令加载到内存后,天然就有了物理地址,我们指令访问数据,跳转函数用的是虚拟地址。cpu如何执行第一条指令?
? ? ? ? 前面说过可执行程序是分段编译时,会有表头记录各段的起始地址,也就记录了程序的入口地址,cpu通过进程拿到这个表头后,就会通过页表映射去找在内存的指令,前面说了读取一条指令时,也就知道了这条指令的长度,然后起始地址+长度,到下一条指令,然后继续去页表,周而复始,代码就跑起来了。
4?动态库的地址
? ? ? ?再次强调代码文件会被分段编译,这个段地址是从0到全F编址的,也就是说对于一个代码文件来说,它认为自己是独享下面这个进程地址空间内的所有虚拟地址的。
????????首先肯定不会和其它进程冲突,因为即便虚拟地址一样,页表映射后也会不一样,其次,进程内部也没有谁会和自己抢正文段,虽然后面会有线程的概念,但是其它的次线程都是在共享区的,栈,堆,正文段都是给主线程的,所以不会冲突。
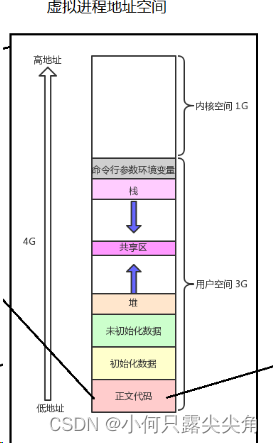
?????????此时,我们回到动态库的问题上,我们知道动静态库内部的编址是使用前就编好了,显然gcc如果真的要对库文件像前面的代码文件一样内部编址,肯定每个动态库都认为共享区是自己的,都是从共享区的起始地址开始分配,如下图。
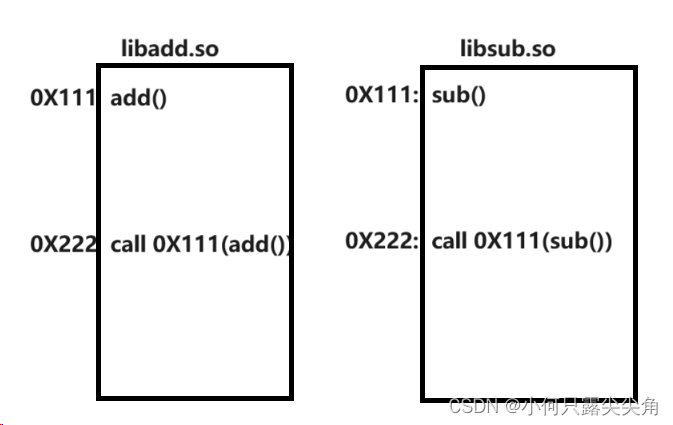
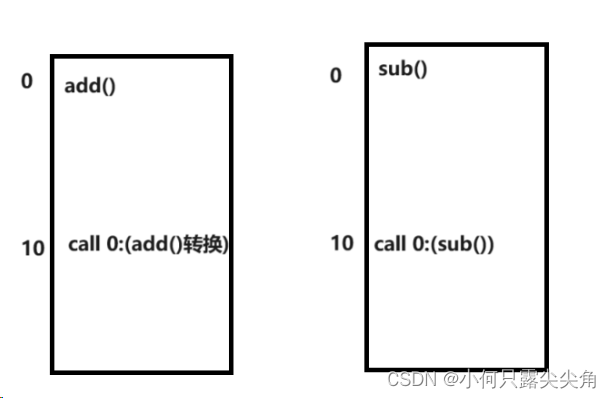
????????多个库一起加载时不就冲突了吗,每个库都认为0X111处是自己内部要调用函数的地址,冲突的源头就是这个编址的方式,固定了每个库只能加载到特定位置,所以大佬们设计出了偏移量编址法。库内的add()调用不是转为某个虚拟地址,而是一个偏移量。
????????因为调用函数肯定是在库里的,而且的库起始地址是会被保存起来的,所以只需要偏移量+说明一下是哪个库的函数,就肯定可以找到函数定义,显然这种方式让库可以加载到共享区的任意位置
????????什么叫库的起始地址会被保存呢,首先我们知道os会加载多个动态库到内存,os肯定要管理它们,方便对它们增删查改,管理动态库不需要os直接面对动态库,只需要用一个结构体描述,并且对应一个动态库,随后os用链表将一个个结构体对象串联到一起,此时对动态库的管理就变成对了对链表的增删改查,结构体内部就有着许多对动态库的描述信息,其中就包括起始虚拟地址。
至于为什么这么管理,得看我这篇博客,里面介绍了os的管理概念。
????????fpic用处:此时终于可以说fpic的作用了:与位置无关码,就是让gcc对动态库编译的时候内部编码采用偏移量,不要把动态库当成普通代码文件用分段地址去编码。
????????写这个博客中我自己在vscode下是做了不少实验的,验证上述结论,而且我们知道找到头文件,库文件方法是比较多的,大家验证的时候一定要记得,做了哪一步,免得过段时间打开电脑重新验证,发现能跑过,奇怪,不是找不到文件吗,最后才发现自己在系统路径下建立了软链接,忘记了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!