基于TriDet的时序动作检测算法训练自己的slowfast数据
????????最近一直在研究时序动作识别和检测,也一直关注着目前的最新进展,有好的算法,我都会在我自己的数据集上运行看看,一方面是为自己累积相关算法,另一方面也是想看看,目前最新的算法是否可以应用到一些项目上。这次我运行2023年新出来的算法-时序动作检测TriDet。算法的论文地址和github地址如下:
论文地址:https://arxiv.org/pdf/2303.07347.pdf
GitHub地址:https://github.com/dingfengshi/TriDet
????????算法讲解百度上有,作者自己在bilibil上也有视频讲解,有需要的可以自己去看看。
????????该作者在算法上测试了epic-kitchens,activityNet和thumos14数据集的slowfast特征和I3D特征,而且在代码里的datasets也对应了每种数据集的加载方式,结合自己的项目,因此我这次选用使用的slowfast特征且用epic_kitchens进行加载和训练自己的数据集。
一、环境配置
1.1、安装slowfast算法环境
??????? 这个没啥说的,就是根据github上的SlowFast算法结束的安装环境。
1.2、安装TriDet算法环境
??????? 这个也没啥说的,也就是根据?github上的TriDet算法结束的安装环境。可能存在部分安装包冲突,这个就是看哪个包的版本高了就降一点,没啥大的问题。
二、数据准备
??????? 根据官网的训练配置文件和其提供的公开数据,需要两个文件,一个是放所有的视频特征文件,一个是数据划分的参数json文件。
这里显示一下json文件的内容格式,基本包含的内容,如下:
"version": "epic-action-noun",
? "database": {
??? "video_A": {
????? "annotations": [{"label": "1", "label_id": 0,"segment": [0.0,0.3333333333333333]
??????? },{"label": "2","label_id": 1,"segment": [48.4,49.4},"resolution": [800,800],"duration": 49.4,"subset": "training"},....,"video_B": {
????? "annotations": [{"label": "46", "label_id": 45,"segment": [0.0,0.5]
??????? },{"label": "48","label_id": 47,"segment": [48.4,49.4]},"resolution": [800,800],"duration": 49.4,"subset": "validation"}}
上面的version就是数据格式,database里就包含了每个视频里每个动作的
label(动作名称),
label_id(分类id),
segment(分割的时间点),
resolution(图像大小),
duration(视频的总时长),
subset(数据类型:训练/验证)
而每个视频通过slowfast运行的特征保存成.npy格式数据。
????????因此要制作自己的数据集,那就要准备两部分工作,首先是将视频分割成每个子视频,并记录每个子视频在整个视频里的起始时间。而我以前做了slowfast训练自己的数据,因此我的数据都已经分割好了,只是图像而已,因此我的两部分工作是,第一通过分割好的图片生成上面对应的json文件;第二要生成对应的视频,再通过SlowFast提取特征。我的图片数据格式如下:
tridet_data:
----train
-----A1
-------a0_0? ->a0是label,0是label_id,如果label保存在一个文件里,如text,那可直接读取----------0.jpg
----------1.jpg
-------a1_1
----------0.jpg
----------1.jpg
-------------
2.1生成json文件,
????????我把生成json的代码,有需要的要根据自己的数据目录格式进行修改,运行后,我生成了一个epic_name_none.json文件
import cv2
import os
import json
import re
height=800
width=800
img_size=(width,height)
# print(size)
fps=30
def write_to_json(data,json_path):
with open(json_path, 'a', encoding='utf-8') as json_file:
json.dump(data, json_file, ensure_ascii=False, indent=2)
#读取label
def read_lable(label_path):
with open(label_path,'r',encoding='utf-8') as pbtxt_file:
content = pbtxt_file.read()
pattern = re.compile(r'(\w+)\s*:\s*(\S+)')
matches = pattern.findall(content)
new_content=match_pbtxt(matches)
return new_content
#生成数据格式
def statis_frames(root_path,label_content,all_data):
all_file_list = os.listdir(root_path)
sub_sig=root_path.split('/')[-2]
for file_name in all_file_list:
print('**************process the file is {}********************'.format(file_name))
all_data[file_name]={}
file_path = os.path.join(root_path, file_name)
sub_file_lists = os.listdir(file_path)
sub_files = sorted([int(sub_file_name.split('_')[-1]) for sub_file_name in sub_file_lists])
s,e=0,0
start_time,end_time=0,0
base_data=[]
for i in range(len(sub_files)):
img_base_data = {}
label=str(sub_files[i])#后面与标签文件对应
if label in label_content.keys():
label_name=label_content[label]
label_id=sub_files[i]
sub_file_path=os.path.join(file_path,file_name+'_'+str(sub_files[i]))
img_lists=os.listdir(sub_file_path)
len_img_lists=len(img_lists)-1
#计算分割时间
start_time=s/fps
e=e+len_img_lists
end_time=e/fps
s=e+1
img_base_data["label"]=label_name
img_base_data["label_id"]=label_id-1
img_base_data["segment"]=[start_time,end_time]
base_data.append(img_base_data)
all_data[file_name]["annotations"]=base_data
all_data[file_name]["resolution"]=img_size
all_data[file_name]["duration"] = end_time
if sub_sig=='train':
all_data[file_name]["subset"] = "training"
if sub_sig=='val':
all_data[file_name]["subset"] = "validation"
return all_data
def process_img_to_json(root_path,json_path,json_name,label_path):
sub_setes=["train","val"]
out_json_path = os.path.join(json_path, json_name)
json_data={}
all_data={}
#从原先的slowfast训练集里的pbtxt读取label
label_content = read_lable(label_path)
for sub_set in sub_setes:
# 原先的slowfast训练自己的数据是,frames30包含了每个子视频的所有帧图像
hig_root_path=os.path.join(root_path,sub_set,'frames30')
print("the path runing is {}*************".format(hig_root_path))
content=statis_frames(hig_root_path,label_content,all_data)
all_data=content
json_data['version'] = "epic-name-noun"
json_data["database"] = all_data
write_to_json(json_data, out_json_path)
print('配置文件json已生成************')2.2生成视频,并使用SlowFast算法提取动作特征
????????我也把生成视频的代码和对SlowFast算法添加的代码也都贴出来,有需要的,可以自己进行修改。
??????? (1)生成fps为30的视频代码。
import cv2
import os
import json
import re
height=800
width=800
img_size=(width,height)
# print(size)
fps=30
#批量处理将图片转换成视频
def img2video(root_path,all_out_video_path):
all_file_list=os.listdir(root_path)
if not os.path.exists(all_out_video_path):
os.makedirs(all_out_video_path)
for file_name in all_file_list:
print('**************process the file is {}********************'.format(file_name))
file_path = os.path.join(root_path, file_name)
out_video_path=os.path.join(all_out_video_path,file_name)
if not os.path.exists(out_video_path):
os.makedirs(out_video_path)
sub_file_lists = os.listdir(file_path)
files = sorted([int(sub_file_name.split('_')[-1]) for sub_file_name in sub_file_lists])
video = cv2.VideoWriter(os.path.join(out_video_path, file_name+'.mp4'), cv2.VideoWriter_fourcc(*"mp4v"), fps,
(width, height))
for i in range(len(files)):#一套动作的所有文件
img_file_name=file_name+'_'+str(files[i])
print('process the file is ',img_file_name)
files_path=os.path.join(file_path,img_file_name)
sub_imgs=os.listdir(files_path)
img_list = sorted([int((file.split('.')[0]).split('_')[-1]) for file in sub_imgs if file.endswith('.jpg')])
for j in range(len(img_list)):
img_name='img_'+'%05d'%img_list[j]+'.jpg'
img_path=os.path.join(files_path,img_name)
img=cv2.imread(img_path)
video.write(img)
video.release()
print('*****************process the file down,and the sum of files is {}***********'.format(len(all_file_list)))
def process_img_to_video(root_path,output_video_path):
sub_setes=["train","val"]
for sub_set in sub_setes:
#原先的slowfast训练自己的数据是,frames30包含了每个子视频的所有帧图像
hig_root_path=os.path.join(root_path,sub_set,'frames30')
print("the path runing is {}*************".format(hig_root_path))
img2video(hig_root_path,output_video_path)
print('视频数据已生成************')(2)SlowFast推理算法
????????改的地方有点多,可以去github上找到开源的代码,如果自己写的话,那就要读懂slowfast的结构和后面输出的特征,我就不将所有的代码贴出来了,因为那样的话,代码太多了,我就说一下,我修改了哪些地方,仅供大家参考。
??????? ①slowfast/visualization/utils.py
在TaskInfo类的后面添加下面代码:
def add_action_preds(self, preds):
"""
Add the corresponding action predictions.
"""
self.action_preds = preds
def add_feats(self, feats):
"""
Add the corresponding action predictions.
"""
self.feats = feats②slowfast/models/head_helper.py
在ResNetBasicHead类的forward
def forward(self, inputs):
assert (
len(inputs) == self.num_pathways
), "Input tensor does not contain {} pathway".format(self.num_pathways)
pool_out = []
for pathway in range(self.num_pathways):
m = getattr(self, "pathway{}_avgpool".format(pathway))
pool_out.append(m(inputs[pathway]))
x = torch.cat(pool_out, 1)
# (N, C, T, H, W) -> (N, T, H, W, C).
x = x.permute((0, 2, 3, 4, 1))
#添加下面两步
#save features
feat = x.clone().detach()
# flatten the features tensor
feat = feat.mean(3).mean(2).reshape(feat.shape[0], -1)
# Perform dropout.
if hasattr(self, "dropout"):
x = self.dropout(x)
x = self.projection(x)
# Performs fully convlutional inference.
if not self.training:
x = self.act(x)
x = x.mean([1, 2, 3])
x = x.view(x.shape[0], -1)
return x,feat③slowfast/visualization/predictor.py
在predictor类后面进行修改下面几处地方的代码
if self.cfg.DETECTION.ENABLE and not bboxes.shape[0]:
preds = torch.tensor([])
else:
#①得到feats
preds,feats = self.model(inputs, bboxes)
if self.cfg.NUM_GPUS:
preds = preds.cpu()
if bboxes is not None:
bboxes = bboxes.detach().cpu()
preds = preds.detach()
task.add_action_preds(preds)
#②将feats添加到task里面
task.add_feats(feats)
if bboxes is not None:
task.add_bboxes(bboxes[:, 1:])
return task④slowfast/models/video_model_builder.py
在ResNet类的forward的后面修改
if self.enable_detection:
x = self.head(x, bboxes)
return x
else:
x,feat= self.head(x)
return x,feat⑤tools/demo_net.py
在demo函数里修改
def demo(cfg):
if cfg.DETECTION.ENABLE and cfg.DEMO.PREDS_BOXES != "":
precomputed_box_vis = AVAVisualizerWithPrecomputedBox(cfg)
precomputed_box_vis()
else:
start = time.time()
if cfg.DEMO.THREAD_ENABLE:
frame_provider = ThreadVideoManager(cfg)
else:
frame_provider = VideoManager(cfg)
feat_arr= None
for task in tqdm.tqdm(run_demo(cfg, frame_provider)):
feat=task.feats
if len(feat)>0:
feat = feat.cpu().numpy()
if feat_arr is None:
feat_arr = feat
else:
feat_arr = np.concatenate((feat_arr, feat), axis=0)
return feat_arr⑥main函数代码,批量生成slowfast特征
def run_inference_batch(cfg, demo):
#这里的DEMO是我自己定义的配置文件,也可以直接输入文件路径,有需要的一定要改一下
input_folder = cfg.DEMO.INPUT_VIDEO
output_folder = cfg.DEMO.OUTPUT_FOLDER
cfg.TRAIN.CHECKPOINT_FILE_PATH = cfg.DEMO.CHECKPOINT1
print("Loading Video List ...")
file_video_list=os.listdir(input_folder)
print("Done")
print("----------------------------------------------------------")
vid_no=0
print("{} videos to be processed...".format(len(file_video_list)))
print("----------------------------------------------------------")
for video_file in file_video_list:
video_file_path=os.path.join(input_folder,video_file)
input_video = os.path.join(input_folder,video_file,video_file+'.mp4')
cfg.DEMO.INPUT_VIDEO = input_video
cfg.DEMO.OUTPUT_FOLDER = output_folder
print("{}. Processing {}...".format(vid_no, video_file))
out_file = video_file + ".npy"
if os.path.exists(os.path.join(video_file_path, out_file)):
print("{}. {} already exists".format(vid_no, out_file))
print("----------------------------------------------------------")
continue
feat_arr = demo(cfg)
feat_data = {}
feat_data['feats'] = feat_arr
os.makedirs(video_file_path, exist_ok=True)
np.save(os.path.join(video_file_path, out_file), feat_data)
vid_no=vid_no+1
print("Done.")
print("----------------------------------------------------------")
if __name__=='__main__':
run_inference_batch(cfg, demo)这样就可以生成每个视频的slowfast特征。
三、训练模型
??????? 当需要的数据都生成好了,将epic_slowfast_noun.yaml相关的地方修改成自己的数据地址,然后运行,python train.py ./configs/epic_slowfast_noun.yaml,就可以了,我的训练过程如下。
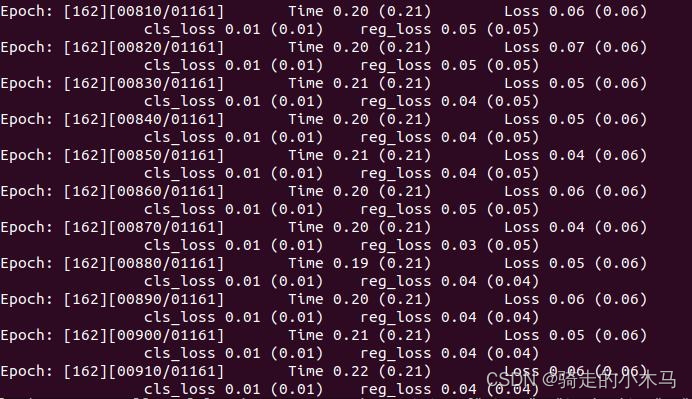
四、训练时出现的问题
????????①数据加载错误:提取的slowfast特征需要先转换成list,在使用slowfast提取特征保存时也采用字典形式,但是在TriDet加载时数据报错,需要做转换。
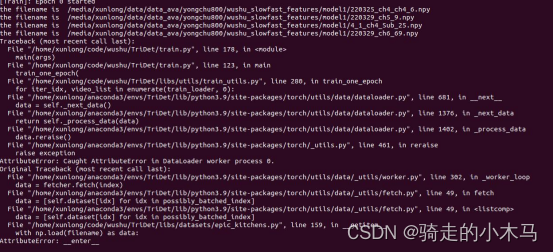
这个需要在libs/datasets/epic_kitchens.py代码的EpicKitchensDataset类里去修改
def __getitem__(self, idx):
# directly return a (truncated) data point (so it is very fast!)
# auto batching will be disabled in the subsequent dataloader
# instead the model will need to decide how to batch / preporcess the data
video_item = self.data_list[idx]
# load features
# print('*************',video_item)
filename = os.path.join(self.feat_folder,self.file_prefix + video_item['id'] + self.file_ext)
# print('the idx is {},and the filename is {}'.format(idx,filename))
#写入下面两行代码
data=np.load(filename)
feats=data.tolist()['feats'].astype(np.float32)
#将下面几行注释掉
# with np.load(filename) as data:
# feats = data['feats'].astype(np.float32)
# deal with downsampling (= increased feat stride)
feats = feats[::self.downsample_rate, :]
feat_stride = self.feat_stride * self.downsample_rate????????②问题2:提取的slowfast特征有问题,部分数据不是字典格式的,对所有的特征进行检测,发现有4个视频保存的特征是list。

????????这个需要检测生成的slowfast特征是否有问题,用代码读取一下就可以判断了,这里就不贴代码了。
????????③问题3,标签数错误,我的数据没有背景项,所有只有45类,但是该算法需要加上背景项,因此yaml文件里的num_class应设置为46。????????
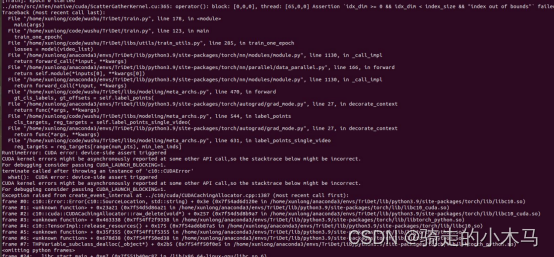
????????④问题4、训练参数设置问题,基于算法默认和经验值,对学习率和epoch进行设置,出现两种现象,当lr选择过大,cls_loss会出现NAN值,lr选择默认或者较小会导致loss无法下降,选择中间值,发现训练到后期出现震荡现象。
????????这个问题我还是没有好的办法解决,但是我将loss设置成0.0005,epoch设置成100、150,测试结果发现使用epic格式的数据准确度在epoch达到30左右分数最高,与论文里的结果差不多。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 配置测试MQtt
- 洛谷 P7993 [USACO21DEC] Lonely Photo B
- docker搭建minio集群
- Linux多版本cuda切换
- mysql — 生产环境发布DDL之避坑操作onlineDDL
- 计算属性和监听属性,生命周期钩子,组件介绍
- 漏油控制器有用吗?漏油监测器多少钱一个?
- vue对日期的年、月、日进行增加,转换成指定格式的字符串(yyyy-MM-dd)
- 使用 Picocli 开发 Java 命令行,5 分钟上手
- 【控制篇 / 策略】(7.4) ? 02. 地理地址对象在策略中的应用 ? FortiGate 防火墙