MIT 6.s081前置xv6教材总结——第一章 操作系统接口
系列文章目录
MIT 6.s081前置xv6教材总结——第一章 操作系统接口
文章目录
概述
?? 进程:每个正在运行的程序,称为进程,都有包含指令、数据和堆栈的内存。
?? 内核(kernel):内核是一个特殊的程序,为正在运行的程序提供服务,一台给定的计算机通常有许多进程,但只有一个内核。
?? 系统调用:当一个进程需要调用一个内核服务时,它会调用一个系统调用,相当于内核空间开放给用户空间使用的一个接口。系统调用进入内核;内核执行服务并返回。因此,一个进程在用户空间和内核空间之间交替执行。

| 系统调用 | 描述 |
|---|---|
| int fork() | 创建一个进程,返回子进程的PID |
| int exit(int status) | 终止当前进程,并将状态报告给wait()函数。无返回 |
| int wait(int *status) | 等待一个子进程退出; 将退出状态存入*status; 返回子进程PID。 |
| int kill(int pid) | 终止对应PID的进程,返回0,或返回-1表示错误 |
| int getpid() | 返回当前进程的PID |
| int sleep(int n) | 暂停n个时钟节拍 |
| int exec(char *file, char *argv[]) | 加载一个文件并使用参数执行它; 只有在出错时才返回 |
| char *sbrk(int n) | 按n 字节增长进程的内存。返回新内存的开始 |
| int open(char *file, int flags) | 打开一个文件;flags表示read/write;返回一个fd(文件描述符) |
| int write(int fd, char *buf, int n) | 从buf 写n 个字节到文件描述符fd; 返回n |
| int read(int fd, char *buf, int n) | 将n 个字节读入buf;返回读取的字节数;如果文件结束,返回0 |
| int close(int fd) | 释放打开的文件fd |
| int dup(int fd) | 返回一个新的文件描述符,指向与fd 相同的文件 |
| int pipe(int p[]) | 创建一个管道,把read/write文件描述符放在p[0]和p[1]中 |
| int chdir(char *dir) | 改变当前的工作目录 |
| int mkdir(char *dir) | 创建一个新目录 |
| int mknod(char *file, int, int) | 创建一个设备文件 |
| int fstat(int fd, struct stat *st) | 将打开文件fd的信息放入*st |
| int stat(char *file, struct stat *st) | 将指定名称的文件信息放入*st |
| int link(char *file1, char *file2) | 为文件file1创建另一个名称(file2) |
| int unlink(char *file) | 删除一个文件 |
xv6系统调用(除非另外声明,这些系统调用返回0表示无误,返回-1表示出错)
1. 进程和内存
1.1 fork系统调用
一个进程可以使用fork系统调用创建一个新的进程。Fork创建了一个新的进程,其内存内容与调用进程(称为父进程)完全相同,称其为子进程。Fork在父子进程中都返回值。在父进程中,fork返回子类的PID;在子进程中,fork返回0。
// fork()在父进程中返回子进程的PID
// 在子进程中返回0
int pid = fork();
if(pid > 0) {
printf("parent: child=%d\n", pid);
pid = wait((int *) 0);
printf("child %d is done\n", pid);
} else if(pid == 0) {
printf("child: exiting\n");
exit(0);
} else {
printf("fork error\n");
}
意思是一个进程从调用fork开始,之后的代码便有两份一模一样在同时运行,但内存和寄存器并不相同。他们互不影响,运行的速度也不确定,所以不一定是父进程比子进程优先运行。
1.2 exec系统调用
使用从文件系统中存储的文件所加载的新内存映像替换调用进程的内存。
char* argv[3];
argv[0] = "echo";
argv[1] = "hello";
argv[2] = 0;
exec("/bin/echo", argv);
printf("exec error\n");
相当于把原来程序的内存用于新程序的调用,并且如果新程序不报错,不会再返回原本的程序。传递的参数为可执行文件的文件名和字符串参数数组。
1.3 wait系统调用
wait系统调用返回当前进程的已退出(或已杀死)子进程的PID,并将子进程的退出状态复制到传递给wait的地址;如果调用方的子进程都没有退出,那么wait等待一个子进程退出。如果调用者没有子级,wait立即返回-1。如果父进程不关心子进程的退出状态,它可以传递一个0地址给wait。
1.4 exit系统调用
exit系统调用导致调用进程停止执行并释放资源(如内存和打开的文件)。exit接受一个整数状态参数,通常0表示成功,1表示失败。exit(0)和exit(1)在中止程序的方面两者没有区别,只不过是为了区分当前是正常退出还是异常退出。
1.5 shell
xv6的shell使用上述调用为用户运行程序。主循环使用getcmd函数从用户的输入中读取一行,然后调用fork创建一个shell进程的副本。父进程调用wait,子进程执行命令。例如:当用户向shell输入echo hello时,将以echo hello为参数被调用来执行实际命令。对于“echo hello”,它将调用exec。如果exec成功,那么子进程将从echo而不是runcmd执行命令,在某刻echo会调用exit,这将导致父进程从main中的wait返回。
2. I/O和文件描述符
2.1 文件描述符
文件描述符是一个小整数,表示进程可以读取或写入的由内核管理的对象。我们通常将文件描述符所指的对象称为“文件”;文件描述符接口将文件、管道和设备之间的差异抽象出来,使它们看起来都像字节流。按照惯例,文件描述符0为(标准输入),文件描述符1为(标准输出),文件描述符2为(标准错误)。
2.2 read系统调用
read(fd,buf,n)从文件描述符fd读取最多n字节,将它们复制到buf,并返回读取的字节数,引用文件的每个文件描述符都有一个与之关联的偏移量。read从当前文件偏移量开始读取数据,然后将该偏移量前进所读取的字节数:(也就是说)后续读取将返回第一次读取返回的字节之后的字节。当没有更多的字节可读时,read返回0来表示文件的结束。
2.3 write系统调用
系统调用write(fd,buf,n)将buf中的n字节写入文件描述符,并返回写入的字节数。只有发生错误时才会写入小于n字节的数据。与读一样,write在当前文件偏移量处写入数据,然后将该偏移量向前推进写入的字节数:每个write从上一个偏移量停止的地方开始写入。
2.4 I/O重定向
close系统调用释放一个文件描述符,使其可以被未来使用的open、pipe或dup系统调用重用。新分配的文件描述符总是当前进程中编号最小的未使用描述符。
举例说明:cat命令的效果大致是从标准输入读取字节,再打印到标准输出上,现在通过以下代码可以实现从txt文件内读取数据并打印,因为close系统调用释放了文件描述符0,open操作就会优先使用当前进程中编号最小的未使用描述符,即文件描述符0,此时标准输入就被重定向到input.txt。
char* argv[2];
argv[0] = "cat";
argv[1] = 0;
if (fork() == 0) {
close(0);
open("input.txt", O_RDONLY);
exec("cat", argv);
}
2.5 文件偏移量
文件偏移量是和文件描述符深度绑定的,哪怕是访问同一个文件,不同的文件描述符之间的偏移量互不影响。但通过fork操作的获得的文件描述符共享。下列代码父进程会wait子进程写入完成并退出,然后接着子进程的偏移量继续写入。
if (fork() == 0) {
write(1, "hello ", 6);
exit(0);
} else {
wait(0);
write(1, "world\n", 6);
}
dup系统调用复制一个现有的文件描述符,返回一个引用自同一个底层I/O对象的新文件描述符。两个文件描述符共享一个偏移量,就像fork复制的文件描述符一样。
fd = dup(1);
write(1, "hello ", 6);
write(fd, "world\n", 6);
3. 管道
管道是作为一对文件描述符公开给进程的小型内核缓冲区,一个用于读取,一个用于写入。将数据写入管道的一端使得这些数据可以从管道的另一端读取。
3.1 管道实现进程间通信
管道为进程提供了一种通信方式。下面的示例代码使用连接到管道读端的标准输入来运行程序wc:
int p[2];
char *argv[2];
argv[0] = "wc";
argv[1] = 0;
pipe(p);
if (fork() == 0) {
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
exec("/bin/wc", argv);
} else {
close(p[0]);
write(p[1], "hello world\n", 12);
close(p[1]);
}
这是fork之后的状态,父进程和子进程都有p[0]和p[1]分别指向管道的读取端和写入端。
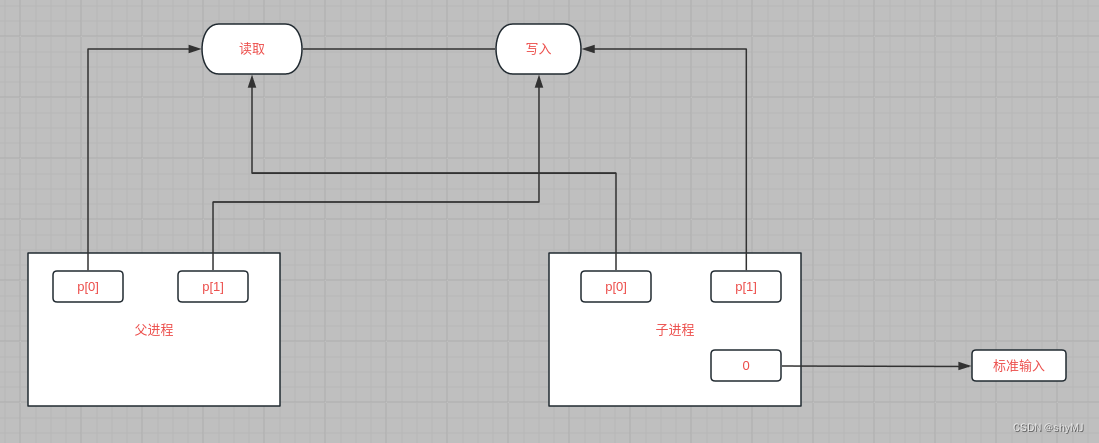
这时候子进程close文件描述符0,同时dup(p[0]),由于被close的文件描述符会被优先使用,所以此时由文件描述符0指向管道读取端,接着关闭原本的p[0],p[1],调用wc文件将从0读取的输入接入程序。
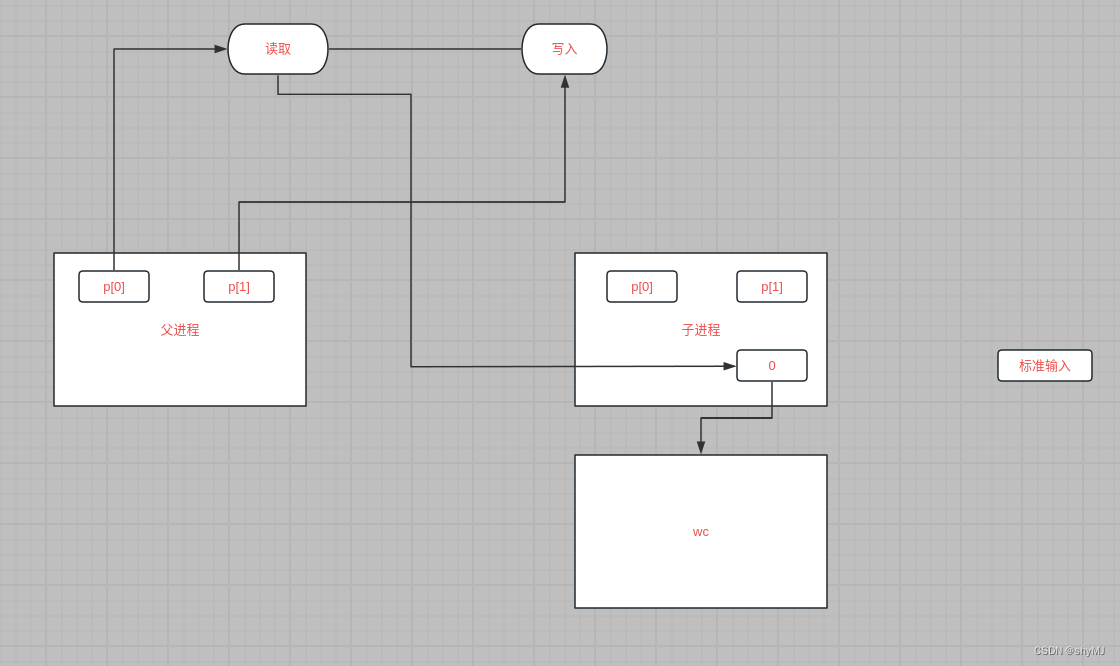
另一边父进程关闭p[0],并向p[1]写入数据,然后关闭p[1],这样写入的数据就能通过管道传递至子进程调用的wc程序,实现进程间的通信。
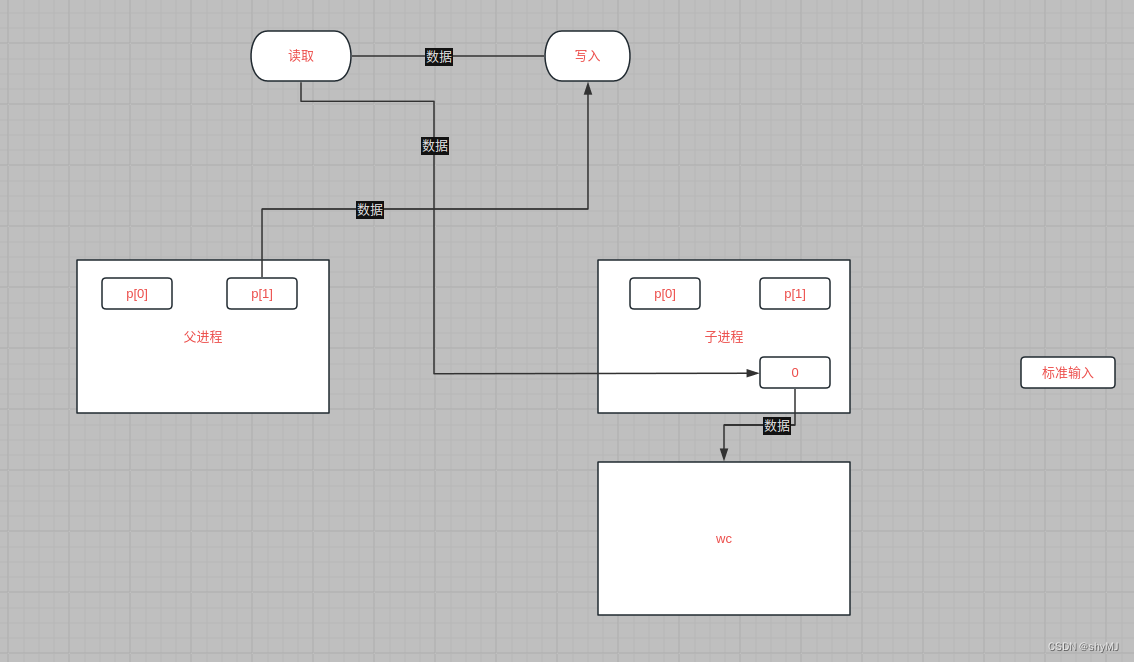
为什么写完数据之后要关闭p[1]? 如果没有可用的数据,则管道上的read操作将会一直阻塞,直到有新数据写入或所有指向写入端的文件描述符都被关闭,在后一种情况下,read将返回0,就像到达数据文件的末尾一样。
3.2 管道实现连续指令
Xv6 shell以类似于上面代码的方式实现了诸如grep fork sh.c | wc -l之类的管道。
pcmd = (struct pipecmd*)cmd;
if(pipe(p) < 0)
panic("pipe");
if(fork1() == 0){
close(1);
dup(p[1]);
close(p[0]);
close(p[1]);
runcmd(pcmd->left);
}
if(fork1() == 0){
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
runcmd(pcmd->right);
}
close(p[0]);
close(p[1]);
wait(0);
wait(0);
break;
整体的流程大概是创建一个pipe之后,fork两个子进程,分别连接pipe的读取端和写入端,左边的子进程执行完命令后将结果传入管道,右边的子进程从管道读取数据执行命令。
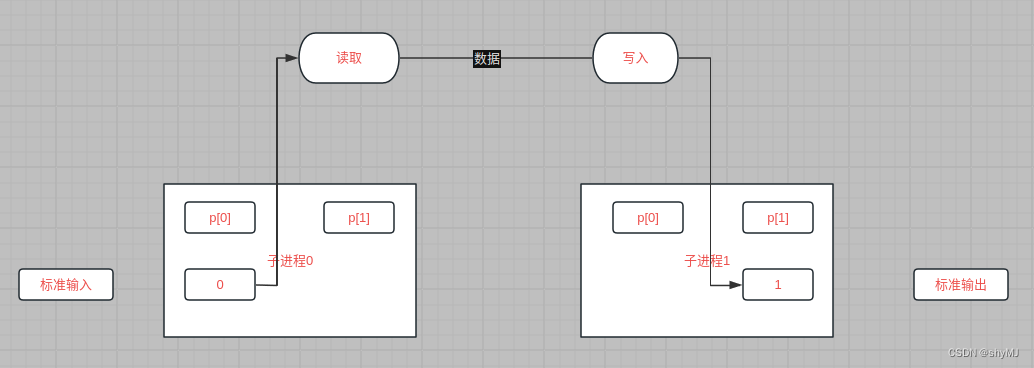
管道的右端可能是一个包含一个另一个管道的命令(例如,a | b | c),该管道本身fork为两个新的子进程(一个用于b,一个用于c)。因此,shell可以创建一个进程树。这个树的叶子是命令,内部节点是等待左右两个子进程完成的进程。
3.3 管道相较于临时文件的优点
-
管道会自动清理自己;在文件重定向时,shell使用完/tmp/xyz后必须小心删除
-
管道可以任意传递长的数据流,而文件重定向需要磁盘上足够的空闲空间来存储所有的数据。
-
管道允许并行执行管道阶段,而文件方法要求第一个程序在第二个程序启动之前完成。
-
如果实现进程间通讯,管道的阻塞式读写比文件的非阻塞语义更高效。
4. 文件系统
一个文件的名字和文件本身是不同的;同一个底层文件(叫做inode,索引结点)可以有多个名字(叫做link,链接)。每个链接都包含一个文件名和一个inode引用。Inode保存有关文件的元数据(用于解释或帮助理解信息的数据),包括其类型(文件/目录/设备)、长度、文件内容在磁盘上的位置以及指向文件的链接数。
fstat系统调用从文件描述符所引用的inode中检索信息,并将信息填充到一个stat类型的结构体里:
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Device
struct stat {
int dev; // 文件系统的磁盘设备
uint ino; // Inode编号
short type; // 文件类型
short nlink; // 指向文件的链接数
uint64 size; // 文件字节数
};
每个文件都有一个独一无二的inode,可以有多个名字link到这个inode。下面的代码片段创建了一个名字既为a又为b的新文件:
open("a", O_CREATE | O_WRONLY);
link("a", "b");
unlink系统调用从文件系统中删除一个名称。只有当文件的链接数为零且没有文件描述符引用时,文件的inode和包含其内容的磁盘空间才会被释放:
unlink("a");
这是创建没有名称的临时inode的惯用方法,该临时inode将在进程关闭fd或退出时被清理。
fd = open("/tmp/xyz", O_CREATE | O_RDWR);
unlink("/tmp/xyz");
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue-预览public(本地)文件下的pdf文件方式
- 【SpringBoot3】命令行运行jar包报错可能的一些原因
- 【漏洞利用】One-Fox综合工具箱 v6.0 公开版——最强单兵作战工具箱
- Java中利用Redis,ZooKeeper,ZooKeeper等实现分布式锁(遥遥领先)
- nodejs-day1——模块、第三方包管理
- 2024 年最适合高级用户的 11 个 Linux 发行版
- 借着期末作业,写一个JavaWeb项目
- Leetcode-102.二叉树的层序遍历(Python)
- 【Python 千题 —— 基础篇】整数输入
- 2023,真人漫改走上IP高地