【YOLO系列】 Smooth L1 Loss、IOU、GIOU、DIOU、CIOU(附代码实现)
????????Smooth L1 Loss、IOU、GIOU、DIOU和CIOU都是用于评估模型预测准确性的指标,但它们在计算方式和应用场景上有所不同。
一、Smooth L1 Loss
????????Smooth L1 Loss主要用于回归问题,是由微软的Ross Girshick大神在Fast R-CNN论文中提出的。将Smooth L1 Loss之前应该先从L1、L2 Loss说起。
????????1. L1 Loss
????????(1)简介
????????L1, 也就是平均绝对误差(Mean Absolute Error)
????????(2)公式
????????当假设x为预测值和真实值之间的差值时,公式可以写为L1=|x|.
????????(3)导数
????????则求导为
????????(4)特点
? ? ? ?a.? 可以看出L1 Loss在零点处不可导,即不平滑,因此在零点时学习慢
? ? ? ? b. L1 Loss在x≠0处的导数为常数,在训练后期,无论x怎么变化,如果学习率不变,损失函数的波动几乎处于稳定,这样就很难收敛到更高的精度。
????????2. L2 Loss
????????(1)简介
????????L2 Loss为均方差误差(Mean Square Error),也被称为最小均方误差(Least Squares Error)
????????(2)公式
????????当假设x为预测值和真实值之间的差值时,公式可以写为L2=x2.
????????(3)导数
?
????????(4)特点
? ? ? ? a. L2 Loss由于是平方增长,因此学习较快;
? ? ? ? b. L2 Loss导数呈线性递增变化,x很大时,导数也很大,因此可能导致L2 Loss在loss中占据主导位置,进而导致训练初期不稳定。
? ? ? ? c. 当函数的输入值距离中心值较远时,使用梯度下降法求解的时,梯度可能会很大,可能会导致梯度爆炸。
????????3. Smooth L1 Loss
????????Smooth L1 Loss结合了L1、L2的优点,同时弥补了它们的缺点,在距离最优解较远出能较快的收敛,在距离最优解很近时能缓慢求导至最优。
????????(1)公式
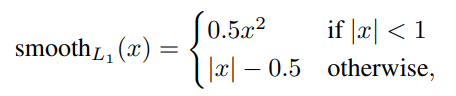
????????x为预测值和真实值之间的差值
????????(2)导数
????????(3)特点
? ? ? ? a. Smooth L1 Loss相比L1改进了L1在零点不平滑的问题(其实L2 也改进了,只是Smooth L1 Loss更平滑了)
? ? ? ? b. 相比L2 Loss,在x较大时不会对异常值敏感,梯度变化较缓慢,训练时不容易跑飞。
????????以上Loss函数常用于回归问题,当用于计算目标检测的bbox Loss时,求出4个点(x,y,w,h)Loss后,再相加得到最终的Loss,这种做法的假设是4个点事相互独立的,但实际上是有一定相关性的。
????????在目标检测时,实际是用IOU来作为评价目标框的指标,而上述Loss函数与IOU是不等价的,多个目标框可能有相同大小的Smooth L1 Loss,但是他们的IOU可能差异很大,因此为了解决这个问题就引了IOU Loss函数。
二、IOU(Intersection over Union)
????????1. 定义
????????交并比(Intersection over Union),简称IOU,主要用于目标检测任务的评估指标。它衡量的是预测框与真实框(GT)的重叠程度。是Jiahui Yu在2016年提出来的:“UnitBox: An Advanced Object Detection Network”。
????????2. 公式
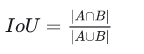
????????3. 特点
? ? ? ? a. 可以反映预测框与真实框的接近程度;
? ? ? ? b. 具有很好的尺度不变性,也就是尺度不敏感,在regression问题中,判断 prediction box和GT的差距最直接的指标就是IOU。
????????4. IOU
????????(1). L1、L2回归问题
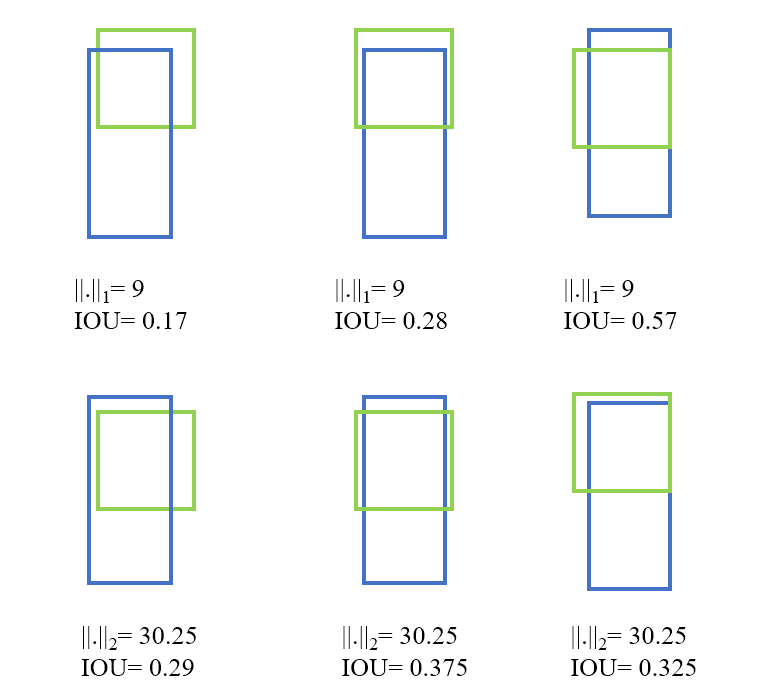
????????(2). 图中的红色点表示目标检测网络结构中Head部分上的点(i,j),绿色的框表示GT框, 蓝色的框表示Prediction的框,IoU loss的定义如上,先求出2个框的IoU,然后再求个-ln(IoU),现在很多是直接定义为IoU Loss = 1-IoU
5. 代码实现

import numpy as np
import math
import torch
def box_iou(b1, b2):
'''
Return iou tensor Parameters
----------
b1: tensor, shape=(4), x_center, y_center, w, h
b2: tensor, shape=( 4), x_center, y_center, w, h
Returns
-------
iou: tensor, shape=(j)
'''
b1_xy = b1[:2]
b1_wh = b1[2:4]
b1_wh_half = b1_wh / 2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
b2_xy = b2[:2]
b2_wh = b2[2:4]
b2_wh_half = b2_wh / 2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = np.maximum(b1_mins, b2_mins)
intersect_maxes = np.minimum(b1_maxes, b2_maxes)
intersect_wh = np.maximum([intersect_maxes - intersect_mins, 0.])
intersect_area = intersect_wh[0] * intersect_wh[1]
b1_area = b1_wh[0] * b1_wh[1]
b2_area = b2_wh[0] * b2_wh[1]
iou = intersect_area / (b1_area + b2_area - intersect_area)
return iou6. IOU作为损失函数存在的问题(缺点)
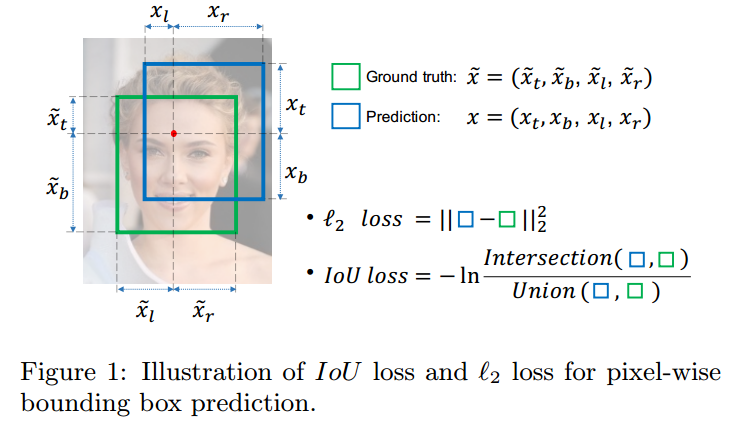
????????如果两个框没有相交,那么IOU=0,则不能反映两者的距离大小(重合度)。同时因为Loss=0,则没有梯度回传,就无法进行学习训练。
????????IOU无法精确的反映不同预测框与GT框的重合度大小。如下图所示,三种情况IOU都相等,但看得出来他们的重合度是不一样的,左边的回归效果最好,右边最差。
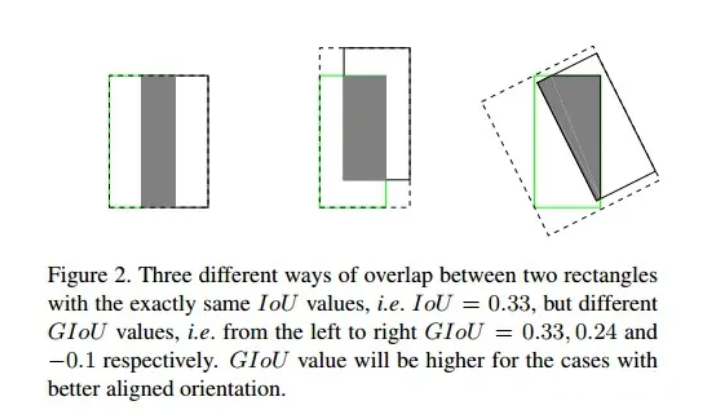
三、GIOU(Generalized Intersection over Union)
????????1. 定义
????????GIOU是一种扩展的IOU,是2019年Hamid Rezatofighi学者在Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression文中提出的,就是为了解决IOU值不能反映两个框是如何相交问题的。
????????由于IOU是比值的概念,对目标物体的scale是不敏感的,然而在检测任务中的bbox的回归损失优化和IOU优化不是完全等价的,而且Ln范数对物体的scale也比较敏感,IOU无法直接优化没有重叠的部分。
????????2. 公式
????????论文中,定义GIOU为
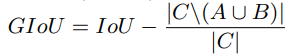
????????C为两个框的最小闭包区域面积,即同时包含了预测框与真实框的最小框的面积。
????????上述公式是先计算出IOU,在计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IOU减去这个比重得到GIOU。
????????3. 特性
? ? ? ? a. 与IOU相似,GIOU也是一种距离度量,作为损失函数的时,满足损失函数的基本要求;
? ? ? ? b. GIOU对scale不敏感;
? ? ? ? c. GIOU是IOU的下界,在两个框无限重合时,IOU=GIOU=1;
? ? ? ? d. IOU=[0,1],但GIOU=[-1, 1]。两者重合时取最大值1,在两者无交集且无限远时取最小值-1,因此GIOU是一个非常好的距离度量指标;
? ? ? ? e. 与IOU只关注重叠区域不同,GIOU不仅关注重叠区域,还关注其他的非重叠区域,能更好得反映两者的重合度。
????????4. 代码实现

def Giou(box1, box2):
"""
计算 GIOU 分数
:param box1: 预测边界框,形状为 shape=(4), x_center, y_center, w, h
:param box2: 实际边界框,形状为 shape=(4), x_center, y_center, w, h
:return: GIOU 分数
"""
# 计算IOU
iou = box_iou(box1, box2)
# 计算并集区域
b1_xy = box1[:2]
b1_wh = box1[2:4]
b1_wh_half = b1_wh / 2.
b1_xmin, b1_ymin = b1_xy - b1_wh_half
b1_xmax, b1_ymax = b1_xy + b1_wh_half
b2_xy = box2[:2]
b2_wh = box2[2:4]
b2_wh_half = b2_wh / 2.
b2_xmin, b2_ymin = b2_xy - b2_wh_half
b2_xmax, b2_ymax = b2_xy + b2_wh_half
# 计算最小闭包
area_c = (np.max([b1_xmax, b2_xmax])-np.min([b1_xmin, b2_xmin]))*(np.max([b1_ymax, b2_ymax])-np.min([b1_ymin, b2_ymin]))
# 计算交集
intersect_xmin = np.maximum([b1_xmin, b2_xmin])
intersect_ymin = np.maximum([b1_ymin, b2_ymin])
intersect_xmax = np.minimum([b1_xmax, b2_xmax])
intersect_ymax = np.minimum([b1_ymax, b2_ymax])
intersect_w = np.maximum([intersect_xmax - intersect_xmin, 0.])
intersect_h = np.maximum([intersect_ymax - intersect_ymin, 0.])
intersect_area = intersect_w * intersect_h
# 计算并集
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
area_sum = b1_area + b2_area - intersect_area
# 闭包区域中不属于两个框的区域占闭包区域的比重
scale_loss = (area_c - area_sum)/area_c
# 计算GIOU
giou = iou - scale_loss
return giou四、DIOU(Distance Intersection over Union)
????????1. 定义
????????DIOU是在IOU的基础上引入了距离损失函数,用于优化目标检测模型。它考虑了预测边界框与实际边界框之间的欧氏距离,使得模型在训练过程中能够更好地拟合数据分布。是Zhaohui Zheng在2019年提出来的“Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression”。
????????它针对了GIOU中的不足,将目标与anchor之间的距离,重叠率以及尺度都考虑进去, 使得目标框回归变得更加稳定,不会像IOU和GIOU一样出现训练过程中发散等问题。
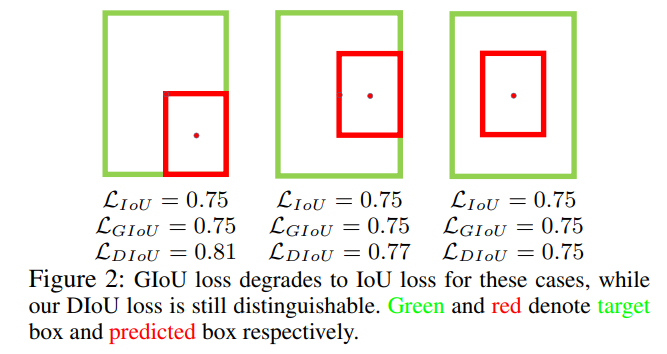
????????基于IOU和GIOU存在的问题,作者提出了两个问题:
? ? ? ? (1)直接最小化预测框与GT框之间的归一化距离是否可行,以达到更快的收敛速度
? ? ? ? (2)如何使用回归在与GT框有重叠甚至包含时更准确、更快。
????????2. 公式
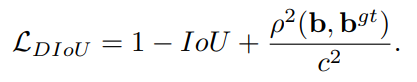
????????其中,b,bgt分别代表了预测框和GT框的中心点,且ρ代表的是计算两个中心点的欧氏距离。c代表的是能够同时包含预测框和GT框的最小闭包区域的对角线距离。
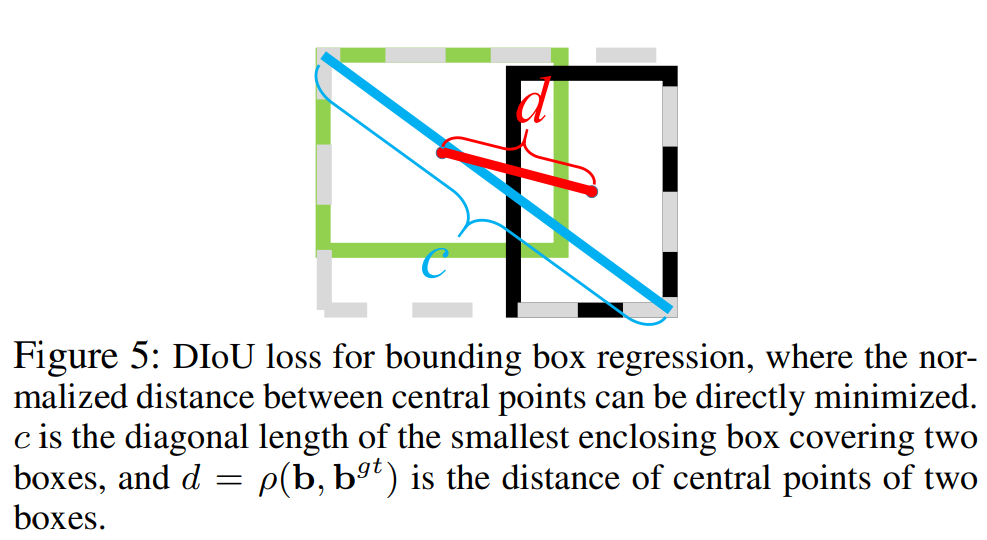
????????3. 特点?
? ? ? ? a. 与GIOU loss类似,DIOU loss在与目标框不重叠是,仍然可以为边界框提供移动方向;
? ? ? ? b. DIOU loss可以直接最小化两个目标框的距离,因此比GIOU loss收敛更快;
? ? ? ? c. 对于包含两个框在水平方向和垂直方向上这种情况,DIOU损失可以使回归非常快,而GIOU损失几乎退化为IOU损失;
? ? ? ? d. DIOU还可以替换普通的IOU评价策略,应用于NMS中,使NMS得到的结果更加合理和有效。
????????4. 代码实现
def Diou(box1, box2):
"""
计算 DIOU 分数
:param box1: 预测边界框,形状为 shape=(4), x_center, y_center, w, h
:param box2: 实际边界框,形状为 shape=(4), x_center, y_center, w, h
:return: DIOU 分数
"""
b1_xy = box1[:2]
b1_wh = box1[2:4]
b1_wh_half = b1_wh / 2.
b1_xymin = b1_xy - b1_wh_half
b1_xymax = b1_xy + b1_wh_half
center_x1, center_y1 = b1_xy
b2_xy = box2[:2]
b2_wh = box2[2:4]
b2_wh_half = b2_wh / 2.
b2_xymin = b2_xy - b2_wh_half
b2_xymax = b2_xy + b2_wh_half
center_x2, center_y2 = b2_xy
iou = box_iou(box1, box2)
out_max_xy = np.max(b1_xymax, b2_xymax)
out_min_xy = np.min(b1_xymin, b2_xymin)
inter_diag = (center_x2 - center_x1) ** 2 + (center_y2 - center_y1) ** 2
outer = np.max([(out_max_xy - out_min_xy), 0])
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
diou = iou - (inter_diag) / outer_diag
return diou
五、CIOU(Complete Intersection over Union)
????????1. 简介
????????CIOU其实是DIOU的作者在考虑到bbox回归三要素中长宽比还没被考虑到计算中,因此进一步在DIOU的基础上提出了CIOU。
????????2. 公式
![]()
????????其中α是权重函数,而v用来度量长宽比的相似性,定义为
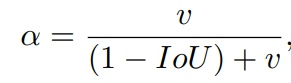
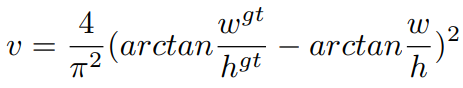
????????完整的CIOU损失函数为:
![]()
????????最后,CIOU loss的梯度类似于DIOU loss,但还要考虑v的梯度
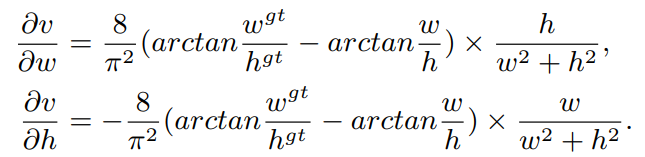
????????在长宽在[0,1]的情况下,w2+h2的值通常很小,会导致梯度爆炸,因此1/(w2+h2)在实现时将替换成1。
????????3. 代码实现
def Ciou(box1, box2):
"""
计算 CIOU 分数
:param box1: 预测边界框,形状为 shape=(4), x_center, y_center, w, h
:param box2: 实际边界框,形状为 shape=(4), x_center, y_center, w, h
:return: CIOU 分数
"""
b1_xy = box1[:2]
b1_wh = box1[2:4]
b1_wh_half = b1_wh / 2.
b1_xymin = b1_xy - b1_wh_half
b1_xymax = b1_xy + b1_wh_half
center_x1, center_y1 = b1_xy
b2_xy = box2[:2]
b2_wh = box2[2:4]
b2_wh_half = b2_wh / 2.
b2_xymin = b2_xy - b2_wh_half
b2_xymax = b2_xy + b2_wh_half
center_x2, center_y2 = b2_xy
iou = box_iou(box1, box2)
out_max_xy = np.max(b1_xymax, b2_xymax)
out_min_xy = np.min(b1_xymin, b2_xymin)
inter_diag = (center_x2 - center_x1) ** 2 + (center_y2 - center_y1) ** 2
outer = np.max([(out_max_xy - out_min_xy), 0])
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
u = (inter_diag) / outer_diag
with torch.no_grad():
arctan = torch.atan(b2_wh[0] / b2_wh[1]) - torch.atan(b1_wh[0] / b1_wh[1])
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(b2_wh[0] / b2_wh[1]) - torch.atan(b1_wh[0] / b1_wh[1])), 2)
S = 1 - iou
alpha = v / (S + v)
w_temp = 2 * b1_wh[0]
ar = (8 / (math.pi ** 2)) * arctan * ((b1_wh[0] - w_temp) * b1_wh[1])
ciou = iou - (u + alpha * ar)
return ciou
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 1.2.3OSI参考模型(一)
- 基于ssm小区物业管理系统设计的论文
- PostgresSQL数据库中分区和分表的区别以及PostgresSQL创建表分区分表示例
- iOS技术博客:App备案指南
- 外汇天眼:Alpha Group International在2023财年实现营收同比增长12%
- [足式机器人]Part2 Dr. CAN学习笔记-自动控制原理Ch1-6根轨迹Root locus
- 【算法】算法设计与分析 期末复习总结
- Mybatis 动态 SQL - if
- 【无标题】
- 风力发电防雷监测浪涌保护器的应用解决方案