跟我用路由器学Linux编程实例四
专栏目录
第一章 简单编程实现花生壳的ddns功能
第二章 让花生壳ddns脚本自动工作
第三章 同时解析多个花生壳域名的脚本
第四章 具有通用性的花生壳ddns脚本
用折腾路由的兴趣,顺便入门shell编程。
第四章 具有通用性的花生壳ddns脚本
前言
作者为了这个专栏准备了4个在线的路由(padavan、openwrt(amd64)、梅林380、梅林386)一台Linux主机(ubuntu),仅让4个路由全在线都废了不少事,各位看官能不踊跃订阅吗~
上一章我们只学了一个新命令let用于整数计算,但是我们重点学习了函数的写法,for循环的用法。这两个比什么新命令都重要!函数用花括号界定边界,for循环用do…done界定。上一章最后说了,这一章是要打造一个有脸放上github的脚本…
一、先复习一下
我们先把上一章最后完成的作品拿来再看看,看是否还缺点啥呢
#!/bin/sh
user="用户名"
pass="密码"
resolve() {
curl -s "http://$user:$pass@ddns.oray.com/ph/update?hostnam=$1"
}
for host in 'a.oray.com' 'b.oray.com' 'c.oray.com' 'd.oray.com'
do
resolve $host
sleep 5
done
好像写得挺好的啊,越看越有程序美感,最多缺了个使用说明README!
这个代码你自己用或交给程序员用,那是没什么问题了。可你交给普通用户用,你让用户去改你的代码吗?你不怕他改少了个引号吗?user=“user” ,普通用户能给你改出N朵花来哦~ 笔者亲自指导过亲妹妹填入一个网址用来连接我做的一个服务,她给我整成这样http://xxx.xxx.xxx:8080/xxx/xxx (在那个软件里中文冒号和英文冒号区别很小,又因为后面跟着//本来就分得比较开,仔细看都不能确定是不是全角符号,且后一个端口号前的冒号肯定是正确的)乍一看没什么问题啊,笔者就经历了从服务器上的业务代码到nginx的代理一条龙的找问题…不堪回首啊!这种跑几十公里插网线,改标点符号的事,搞运维的兄弟一说起来那满满的都是泪,三天也说不完!
所以我们得尽量避免这种低级错误,并且你也不能让普通用户去改你的代码,大概率会少掉或多出些一些标点符号和空格,因为在普通人看来少个标点、多个空格那叫问题吗?一点也不影响阅读理解嘛!但在程序看来是大问题,大概率就出错。
那么我们怎么办呢?直接给出一个文件让用户填写必要的信息,我们用前面学习过的cat命令来抓取,并且进行一些低级错误的修正。比如去掉空格,改正大小写等问题。
二、写一个配置文件
配置文件需要用户填写的内容也不多嘛,一个用户名、一个密码、n个域名
# 在=后面填写信息, “domain=”一行一个,可自行添加。不要删除本行内容!
user=
pass=
domain=
domain=
好了,我们给出这么一个文件当配置文件,可以起个有linux风格名字叫conf或者叫phddns.conf啥的看你喜欢了,把它和前面写的phddns放一起上传放入/jffs/scripts/。
现在我们去路由器看看吧:
admin@RT-AC3100-88B0:/jffs/scripts# cat phddns
#!/bin/sh
user="用户名"
pass="密码"
resolve() {
curl -s "http://$user:$pass@ddns.oray.com/ph/update?hostnam=$1"
}
for host in 'a.oray.com' 'b.oray.com' 'c.oray.com' 'd.oray.com'
do
# 笔者将这一行原本用来修改ddns解析的换成了显示网址,避免真去解析
echo "http://$user:$pass@ddns.oray.com/ph/update?hostnam=$host"
sleep 5
done
然后我们在conf文件中填入数据,故意多个空格啥的。我们假设信息是对的,只是格式有点问题,毕竟信息如果错了肯定没有拯救的必要。
admin@RT-AC3100-88B0:/jffs/scripts# cat phddns.conf
# 在=后面填写信息, “domain=”一行一个,可自行添加。不要删除本行内容!
user= user
pass=abcdef
domain=a.oray.com
domain= b.oray.com
domain =c.oray.com
domain= d.oray.com
admin@RT-AC3100-88B0:/jffs/scripts#
三、处理用户输入信息
我们先假设用户输入的信息大体是正确的,只是多了空格空行。我们需要读出数据,前文说过可以用cat 抓出文本内容。那么cat出来以后如何处理呢?显然第二行是用户名,第三行是密码,第四行之后是域名,却不知道有几行,shell有很多办法处理这个问题,我们用比较好理解的办法来解决:
cat phddns.conf | awk NR==2
user= user
cat phddns.conf | awk NR==2 | awk -F"=" '{print $2}'
user
cat phddns.conf | awk NR==2 | awk -F"=" '{print $2}' | tr -d ' '
user
笔者这里一步步演示了处理过程:
cat phddns.conf | awk NR==2前半句大家很熟了就是抓出配置文件的内容,|管道符表示前面cat得到的结果交给后面的awk来处理。这里的关键是awk NR==2这半句,awk这个命令用于文本分析很强大,参数较多,全写出来可以水好几章。我们只解释用到的,笔者肯定只写常用的!参数NR==2,表示我们只要第二行!好理解吧?awk -F"=" '{print $2}'再来看第二个管道符后面的:这里的参数是-F“=”,-F表示切割,-F"="就是以‘=’号切割了嘛,'{print $2}'这部分表示我只要打印切割出来的第2部分,这里还是$引用。tr -d ' ',tr是translate的Linux风格缩写,意为转换,-d表示删除,全句就是删除空格。它不加参数用来转换大小写,替换字符很方便,看下面的例子很容易明白大小写替换:
# A-Z表示从A到Z的26个大写字母,在ASCII表中,B比A大1,所以这个命令只能用于ASCII字符
# ASCII字符读者可以理解成标准键盘能直接输入的字符,中文什么的显然在键盘上找不到
echo "HeLLo WORld" | tr "A-Z" "a-z"
hello world
echo "HeLLo WORld" | tr "o" "O"
HeLLO WORld
- 顺便一说,估计有读者在嘀咕,几乎全部命令作者你都给出英文单词了,这个awk你是忘记了呢还是不知道呢?这个awk还真不是单词,是作者人名。
- 这里又学到了
|可以连用哦~ 实际只要最后一句,笔者这里是给出了分析过程和每一步的执行结果,读者对照着看就比较容易理解。
第三行我们显然可以用同样的办法得到密码,不过我们换一个命令来处理,多学点嘛:
cat phddns.conf | grep "pass="
pass=abcdef
cat phddns.conf | grep "pass=" |tr -d ' '
pass=abcdef
cat phddns.conf | grep "pass=" |tr -d ' '|awk -F"=" '{print $2}'
abcdef
- 因为用户名、密码、域名中是不可能包含空格的,所以我们可以都加上
tr -d ' '来去除空格。 - 这里又用了一个
grep命令,这个命令主要用于搜索文本,比较简单,一看就明白了,这是在文本中搜索含有“pass=”的行。因为域名中可能含有“pass”却不可能有“=”号,这个“pass=”又是我们事先给出的,我们可以认为用户不会去修改。 - 最后和上面一样用
awk命令以‘=’切割,只要第二部分,第一部分明显是‘pass’。 - 这里又学习了
grep搜索命令,虽然这个命令在前面用过。
这样我们就得到了用户名和密码,那么不知道有几行的域名怎么办呢?
admin@RT-AC3100-88B0:/jffs/scripts# cat phddns.conf |tr -d ' '
#在=后面填写信息,“domain=”一行一个,可自行添加。不要删除本行内容!
user=user
pass=abcdef
domain=a.oray.com
domain=b.oray.com
domain=c.oray.com
domain=d.oray.com
admin@RT-AC3100-88B0:/jffs/scripts# cat phddns.conf |tr -d ' '| tail +4
domain=a.oray.com
domain=b.oray.com
domain=c.oray.com
domain=d.oray.com
admin@RT-AC3100-88B0:/jffs/scripts# cat phddns.conf |tr -d ' '| tail +4 | sed -n'/domain/p'
domain=a.oray.com
domain=b.oray.com
domain=c.oray.com
domain=d.oray.com
admin@RT-AC3100-88B0:/jffs/scripts# arr=$(cat phddns.conf |tr -d ' '| tail +4 | sed -n '/domain/p')
admin@RT-AC3100-88B0:/jffs/scripts# echo $arr
domain=a.oray.com domain=b.oray.com domain=c.oray.com domain=d.oray.com
好了,这一部分比较复杂,用到了不少新知识,tr前面用好几次了就不说了:
tail +4,tail是英文尾巴的意思,这就好理解了,就是从最尾部到第4行。既然有尾巴肯定有头嘛,所以有另一个命令head这是从头部起到第几行,一般像这么用:head -4就是从第一行到第四行。这一头一尾命令就可以组合出任意第几行到第几行了,注意+、-号的区别。sed -n '/domain/p'这一句才是最麻烦的,和awk一样比较复杂,它很强大很好用,这命令和前面的grep、awk共同组成了shell文本处理三剑客,head和tail根本没有存在的必要!sed是流编辑器,s就是stream,流水的意思。这里只解释用到的参数:-n,表示不自动打印,也就是在读取的时候会自动打印一次,最后p也是打印的意思,如果没有-n会打印两次。/domain/表示匹配有domain字符的行,那么整句的意思就是找到带有domain字样的行并打印出来arr=$( )最后加了这么一个命令,这里arr是变量,$()表示切割成数组,数组就是多个同类元素的集合。这又牵扯出一个概念Internal Field Separator,(内部区域分隔符)也就是以什么来分割的问题,默认是以空格,tab制表符,换行符来切割的。在这个命令里就是以换行符‘\n’切割的。这个以后有机会再说吧,路由的数组功能不全的。先暂时有个映像就行了,这章的后面处理用户输入部分很多内容严重超过笔者原定的大纲了,已经超出入门水平所需要学习的知识了。
四、最后完成作品
前面一点一点把每一步都说得比较清楚了,最后就可以写出完整脚本代码:
#!/bin/sh
# 这里的$()表示引用括号内的运行结果,至于为什么前面是引用分割,这是shell自动判断的
user=$(cat phddns.conf | awk NR==2 | awk -F"=" '{print $2}' | tr -d ' ')
pass=$(cat phddns.conf | grep "pass" |tr -d ' '|awk -F"=" '{print $2}')
resolve() {
curl -s "http://$user:$pass@ddns.oray.com/ph/update?hostnam=$1"
}
arr=$(cat phddns.conf |tr -d ' '| tail +4 | sed -n '/domain/p')
for host $arr
do
resolve $host
# 替换成:echo "http://$user:$pass@ddns.oray.com/ph/update?hostnam=$host"
sleep 5
done
去路由运行一下看看这个脚本的执行结果,笔者还是把resolve部分换成echo显示
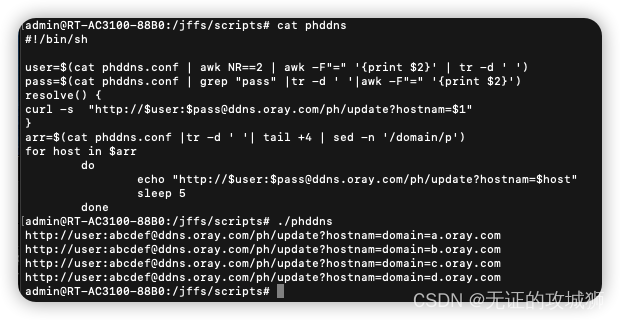
小结
本章的知识点有点多,难度系数比较高。主要难在文本的处理方面,对于只想入门的读者来说,没必要花太多时间去学会sed命令,数组也只需要略做了解,如果有足够多的人订阅,以后肯定要说明白数组的,shell的数组只有一维,其实很简单的。只要掌握了tail、head 命令以及 awk 的文中所说的两三个用法、grep 搜索的方法,大多数情况能够组合使用得到想要的结果就行了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 零基础入门网络安全必备五本书籍
- 数据表基本操作
- 微信小程序 - 龙骨图集拆分
- C++ 之LeetCode刷题记录(七)
- 第137期 Oracle的数据生命周期管理(20240123)
- 用Airtest快速实现手机文件读写与删除功能
- web等保评测需要实机查看的操作系统、服务器、数据库和应用部分
- centos7部署docker环境
- Python PIP安装pycorrector、kemln报错
- pyDAL一个python的ORM(4) pyDAL查询操作