【Databend】行列转化:一行变多行和简单分列
发布时间:2024年01月13日
数据准备和需求
行列转化在实际工作中很常见,其中最常见的有一行变多行,有下面一份数据:
drop table if exists fact_suject_data;
create table if not exists fact_suject_data
(
student_id int null comment '编号',
subject_level varchar null comment '科目等级',
subject_level_json variant null comment '科目等级json数据'
);
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (12,'china e,english d,math e','{"china": "e","english": "d","math": "e"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (2,'china b,english b','{"china": "b","english": "b"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (3,'english a,math c','{"english": "a","math": "c"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (4,'china c,math a','{"china": "c","math": "a"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (5,'china d,english a,math c','{"china": "d","english": "a","math": "c"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (6,'china c,english a,math d','{"china": "c","english": "a","math": "d"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (7,'china a,english e,math b','{"china": "a","english": "e","math": "b"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (8,'china d,english e,math e','{"china": "d","english": "e","math": "e"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (9,'china c,english e,math c','{"china": "c","english": "e","math": "c"}');
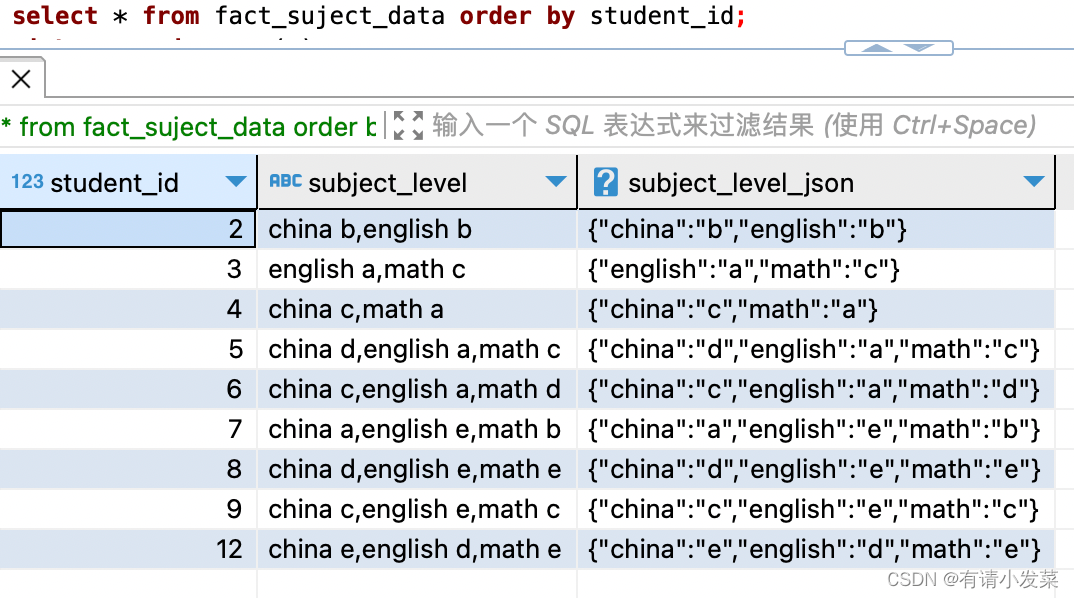
需求是将学生学科等级和等级分隔成多行,效果如下:
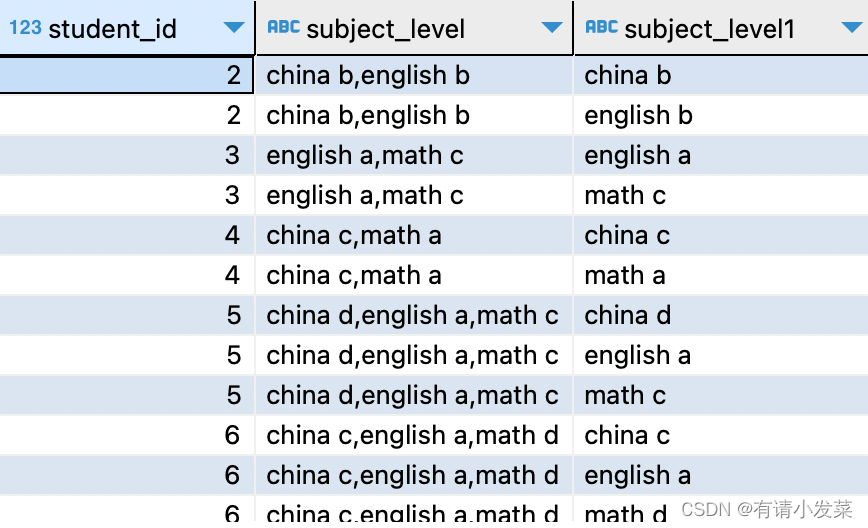
生成序列和分隔函数
Databend 生成序列有专门的函数 generate_series(,
select generate_series as n from generate(1, 10);
select generate_series as n from generate(1, 10, 2);
+---+
| n |
+---+
| 1 |
+---+
| 3 |
+---+
| 5 |
+---+
| 7 |
+---+
| 9 |
+---+
select generate_series as n from generate_series('2024-01-01'::date, '2024-01-07'::date);
+---------------+
| calendar_date |
+---------------+
| 2024-01-01 |
+---------------+
| 2024-01-02 |
+---------------+
| 2024-01-03 |
+---------------+
| 2024-01-04 |
+---------------+
| 2024-01-05 |
+---------------+
| 2024-01-06 |
+---------------+
| 2024-01-07 |
+---------------+
- split(<input_string>,):使用指定的分隔符拆分字符串,并将结果部分作为数组返回。
- split_part(<input_string>,, ):使用指定的分隔符拆分字符串并返回指定的部分。
- unnest(array):将数组拆分成多行。
select subject_level
, split(subject_level, ',') as split_char
, split_part(subject_level, ',', 1) as part1
from (select 'china e,english d,math e' as subject_level) as a
+--------------------------+----------------------------------+------------+
| subject_level | split_char | part1 |
+--------------------------+----------------------------------+------------+
| china e,english d,math e | ['china e','english d','math e'] | china e |
+--------------------------+----------------------------------+------------+
select subject_level
, unnest(split(subject_level, ',')) as unne_char
from (select 'china e,english d,math e' as subject_level) as a;
+--------------------------+------------+
| subject_level | unne_char |
+--------------------------+------------+
| china e,english d,math e | china e |
+--------------------------+------------+
split_part() 函数与 Mysql 中的 substring_index() 类似。
根据分隔符变多行
根据上面函数讲解,
方法一:我们可以使用 split(<input_string>,) 和 unnest(array) 函数实现。
select t1.student_id,t1.subject_level
,unnest(split(t1.subject_level,',')) as subject_level1
from fact_suject_data as t1
order by t1.student_id;
方法二:也可以使用 split_part(<input_string>,, ) 单独实现。
select t1.student_id
, t1.subject_level
, t2.n
, split_part(t1.subject_level, ',', t2.n) as subject_level1
from fact_suject_data as t1
left join (select generate_series as n from generate_series(1, 30)) t2
on t2.n <= (length(t1.subject_level) - length(replace(t1.subject_level, ',', '')) + 1)
order by t1.student_id;
通过 generate_series() 生成的序列数值作为 split_part() 的分隔参数即可实现,与 Mysql 行列变换《你想要的都有》中分隔原理一致。
JSON 数据简单分列
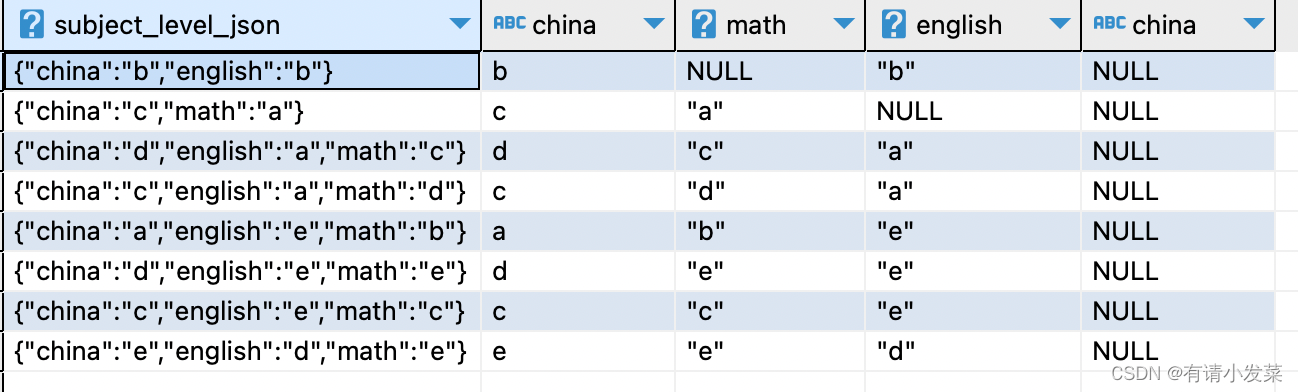
对于 subject_level_json 列数据,我们可以使用 json 独有的函数实现分列透视的效果。
select subject_level_json
, replace(json_path_query(subject_level_json, '$.china'), '"', '') as china
, get(subject_level_json, 'math') as math
, get(subject_level_json, 'english') as english
from fact_suject_data as t1
order by t1.student_id;
总结
数据分列和一行变多行的应用非常常见,通过本文的学习,相信基本上能处理类似问题,遇到面试相关问题也能完美解决,赶紧动手实操看看效果吧!!!
参考资料:
- Databend Array Functions:https://docs.databend.com/sql/sql-functions/array-functions/
- Mysql 行列变换《你想要的都有》:https://blog.csdn.net/weixin_50357986/article/details/134161183
- Databend 基础函数应用:https://blog.csdn.net/weixin_50357986/article/details/135535471
文章来源:https://blog.csdn.net/weixin_50357986/article/details/135568736
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 低代码开发:数字化“装配线”的崛起
- obs-studio build
- 鸿鹄电子招投标系统:企业战略布局下的采购寻源解决方案
- 什么是ERP 企业资源计划(ERP)系统功能作用详细介绍
- python元类为类的全部方法添加装饰器
- H6225L 降压恒压芯片 输入8V-60V降压12V 60V降压5V 60V降压3.3V/1.3A
- go从0到1项目实战体系十三:全局/局部变量
- 易点易动设备管理系统:解决企业设备管理难题的利器
- 【unity】【WebRTC】从0开始创建一个Unity远程媒体流app-设置输入设备
- 跨境电商ERP源码的10大利弊及解决方案