AI的智慧精华:解锁知识蒸馏的秘密
1.定义
化学蒸馏是一种物质分离的方法,通过加热物质混合物,使其其中一种或多种成分的沸点低于其他成分的沸点,从而使其蒸发,然后通过冷凝使其凝结,最终得到纯净的成分。
蒸馏通常用于分离液体混合物中的组分。在蒸馏过程中,混合物被加热,使其中沸点较低的成分先蒸发,然后通过冷凝器冷却并凝结为液体。凝结后的液体称为蒸馏液或馏出液。沸点较高的成分则留在容器中,称为残渣。
而知识蒸馏就是把一个大的模型,称之为教师模型里面的知识萃取蒸馏出来,并浓缩到一个小的学生模型中!那知识就从教师模型迁移到学生模型中。 知识蒸馏(Knowledge Distillation)是一种用于模型压缩和迁移学习的技术,其主要思想是通过将一个大型模型的知识传递给一个小型模型来提高小型模型的性能。这种方法通常用于在计算资源有限或者移动设备上部署深度学习模型。
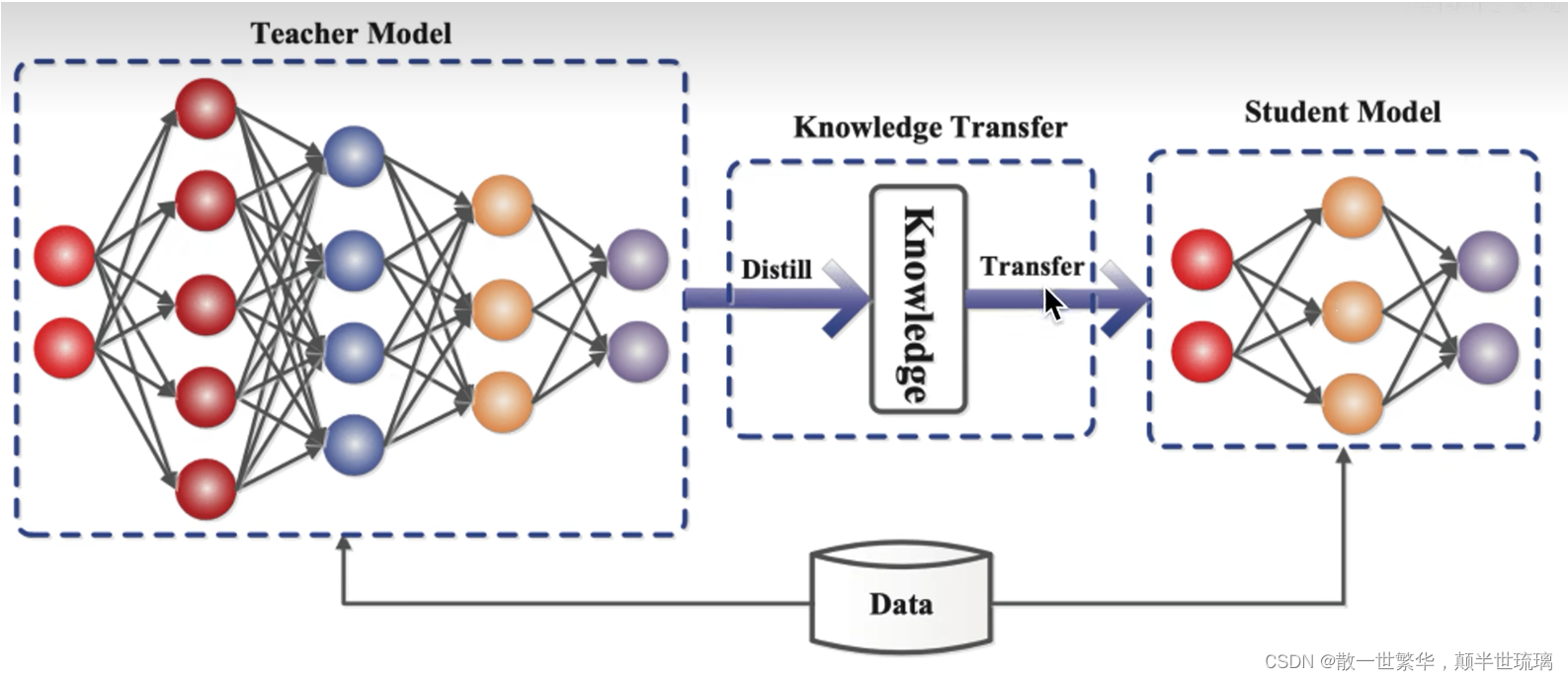
知识蒸馏(Knowledge Distillation)是一种模型压缩和迁移学习的技术,通过将一个大型模型的知识传递给一个小型模型,以提高小型模型的性能。以下是进行知识蒸馏的一些主要原因和优势:
-
模型压缩: 大型深度学习模型通常有大量的参数,占用较大的存储空间和计算资源。通过知识蒸馏,可以将大模型的知识压缩到小型模型中,从而减小模型的存储需求和计算成本,使得在资源有限的环境中更容易部署。
-
实时推理: 小型模型通常具有更快的推理速度,适用于对实时性要求较高的应用场景,例如移动设备上的图像识别或语音识别。知识蒸馏可以通过将大模型的知识传递给小模型来实现这种速度提升,同时保持相对高的性能。
-
迁移学习: 通过在一个任务上训练大型模型,并将其知识迁移到小型模型上,可以在小样本或不同任务上实现更好的泛化性能。这对于在具有有限标注数据的任务上表现良好的小型模型来说尤为重要。
-
模型融合: 知识蒸馏提供了一种将多个模型融合的方式。通过在蒸馏过程中结合多个大型模型的知识,可以生成更强大、更鲁棒的小型模型。
-
对抗风险: 在某些情况下,大型模型可能受到攻击,例如针对性攻击(adversarial attacks)。通过知识蒸馏,可以提高模型的鲁棒性,使其对抗攻击的能力更强。
-
资源节约: 在一些资源受限的环境中,如边缘计算设备或IoT设备,小型模型更容易部署,而知识蒸馏可以帮助小模型在这些环境中表现得更好。
总的来说,知识蒸馏是一种有效的技术,可以在保持相对高性能的情况下,将深度学习模型的规模缩小,从而适应更多应用场景。
有关知识蒸馏的创世之作发表在顶级学术会议NIPS 2014中!
Distilling the Knowledge in a Neural Network论文下载链接
2.人物介绍
知识蒸馏的创世之作是由Geoffrey Hinton和Jeff Dean两位大家所写!
Geoffrey Hinton 是一位在人工智能领域取得杰出贡献的研究者,他的工作对深度学习和神经网络的发展产生了深远的影响。他是深度学习三巨头之一,他用一己之力奠定了整个深度学习和神经网络的算法基础设施,比如优化参数,用反向传播算法,怎么防止过拟合,用dropout等,并获得了2019年图灵奖。
以下是他在人工智能领域的主要贡献:
-
反向传播算法: Hinton 是反向传播算法的先驱之一。反向传播是一种用于训练神经网络的优化算法,它通过反向计算梯度来调整网络参数,从而最小化损失函数。这一算法为训练深层神经网络提供了可行的方法,成为深度学习的基础。
-
深度信念网络: Hinton 提出了深度信念网络(Deep Belief Networks,DBN)的概念。DBN 是一种多层次的概率图模型,利用无监督学习方法进行预训练,然后可以用于监督学习任务。这一框架在图像和语音处理等领域取得了显著的成果。
-
限制玻尔兹曼机: Hinton 在限制玻尔兹曼机(Restricted Boltzmann Machine,RBM)的研究上取得了重要突破。RBM 是一种能量模型,用于表示概率分布,特别适用于无监督学习。
-
图灵奖: 2018年,Hinton 因他在深度学习方面的开创性工作和对神经网络的重要贡献而获得了计算机科学领域的最高荣誉,即图灵奖。这个奖项承认了他对计算科学的杰出贡献,尤其是在人工智能领域。
-
学术教育: 作为一名教授,Hinton 在多伦多大学培养了众多学生,他的教育工作为深度学习领域培养了一批优秀的研究者,这对于该领域的发展起到了积极的推动作用。
总体而言,Geoffrey Hinton 通过引领和推动神经网络和深度学习的研究,为人工智能领域的进步和创新做出了卓越的贡献。
Jeff Dean 是一位在计算机科学和人工智能领域取得卓越成就的美国计算机科学家。
有一个笑话:编译器从来不会给Jeff Dean报错,都是Jeff Dean给编译器报错
以下是关于 Jeff Dean 的一些重要信息:
-
职业生涯: Jeff Dean 是谷歌(Google)公司的高级副总裁,Google Research 的主管之一。他在Google的工作时间非常长,为公司的很多重要项目和创新做出了贡献。
-
工作成就: Jeff Dean 是谷歌的工程师之一,对于许多关键的系统和算法的设计和实现都有重要影响。他是谷歌文件系统(Google File System,GFS)和MapReduce的共同作者之一,这两者成为了大规模分布式系统的基石。
-
TensorFlow: Jeff Dean 是 TensorFlow 深度学习框架的主要设计者之一。TensorFlow 是一个开源的机器学习框架,被广泛用于深度学习任务的开发和部署。
-
DistBelief: 在TensorFlow之前,Jeff Dean 领导了DistBelief项目,这是Google内部的一个机器学习框架,对深度学习的发展起到了重要作用。
-
Spanner: Jeff Dean 也参与了Google Spanner项目的设计和实现。Spanner 是一种全球分布式数据库系统,具有高可用性和一致性的特性。
-
硬件加速器: Jeff Dean 对硬件加速器的研究和应用也是他的研究方向之一。他在设计和推动使用专用硬件来加速深度学习和其他计算密集型任务方面有着丰富的经验。
-
图灵奖: 2021年,Jeff Dean 与其同事 Sanjay Ghemawat 一同因在大规模分布式计算方面的开创性工作而获得了计算机科学领域的最高荣誉,即图灵奖。
总体而言,Jeff Dean 是计算机科学和人工智能领域的杰出科学家,他在大规模分布式系统、机器学习框架和硬件加速等方面的工作为科学界和工业界带来了许多创新。
Distilling the Knowledge in a Neural Network这篇论文就是由这两位大家所写,可见这篇论文的含金量!
3.软标签的应用
软标签(Soft Labels)和硬标签(Hard Labels)是在机器学习和深度学习中常用的两种标签形式,用于表示样本的类别信息。它们在训练过程中有不同的应用和性质。
-
硬标签(Hard Labels):
- 定义: 硬标签是一种离散的、确定性的类别表示方式。每个样本被赋予一个明确的、唯一的类别标签。
- 示例: 在一个图像分类任务中,硬标签可以是一个整数,表示图像属于某个特定的类别,比如0表示猫,1表示狗等。
-
软标签(Soft Labels):
- 定义: 软标签是一种连续的、概率分布形式的类别表示方式。每个样本的标签是一个概率向量,表示它属于每个类别的概率。
- 示例: 对于同样的图像分类任务,软标签可以是一个包含了概率分布的向量,比如[0.8, 0.2],表示模型对该图像属于第一个类别的概率为 0.8,属于第二个类别的概率为 0.2。
应用和优势:
-
硬标签:
- 常用于传统的监督学习任务,如分类问题。
- 训练模型时,目标是使模型的输出概率分布尽可能接近硬标签的分布。
-
软标签:
- 常用于知识蒸馏(Knowledge Distillation)等场景,其中大型模型的输出可以作为软标签传递给小型模型。
- 软标签可以提供更多的信息,使得模型在训练时更容易学到复杂的决策边界。
- 在某些任务中,软标签还可以捕捉到模糊性,反映模型对不同类别的不确定性。
在知识蒸馏中,通常会使用大型模型的软标签来训练小型模型,通过优化小型模型的预测概率分布与大型模型软标签的相似程度,以达到模型压缩和迁移学习的目的。
因此,我们的目标已经明确了,我们要用教师网络预测出来的soft label作为训练学生网络的标签,因为soft label包含了更多了信息,用soft label训练学生网络效率会更高!
4.蒸馏温度
在知识蒸馏(Knowledge Distillation)中,蒸馏温度是一个超参数,它控制了模型预测的软标签分布的“软化”程度。蒸馏温度的作用是在生成软标签时引入一个温度参数,从而调整标签的相对概率分布。这个温度参数通常是一个正的实数。
在知识蒸馏(Knowledge Distillation)中,蒸馏温度(Temperature)是用于调整教师模型输出软标签(Soft Labels)的平滑程度的一个超参数。这个概念通常在软化softmax输出时使用。以下是相关的公式和解释:
蒸馏温度的应用
在普通的分类问题中,softmax函数用于将神经网络最后一层的输出转化为概率分布。标准softmax函数的公式为:
softmax ( z ) i = e z i ∑ j e z j \text{softmax}(z)_i = \frac{e^{z_i}}{\sum_{j}e^{z_j}} softmax(z)i?=∑j?ezj?ezi??
其中,( z ) 是网络最后一层的输出向量,( z_i ) 是该向量中的第i个元素。
在知识蒸馏中,softmax函数被修改以包含温度参数 ( T ):
softmax ( z / T ) i = e z i / T ∑ j e z j / T \text{softmax}(z/T)_i = \frac{e^{z_i/T}}{\sum_{j}e^{z_j/T}} softmax(z/T)i?=∑j?ezj?/Tezi?/T?
蒸馏温度的作用可以总结如下:
-
软标签的平滑性: 增加蒸馏温度会使软标签的概率分布更平滑。较高的温度将导致更平缓的概率曲线,使得模型更容易学到相对均匀的分布。这对于小型模型的训练过程中更容易捕捉大型模型的知识,因为软标签的平滑性有助于抑制训练时的过拟合。
-
控制标签的尖峰性: 较低的温度会使软标签的分布更接近硬标签,即更尖锐,更接近确定性。这可能使得模型更注重大型模型中预测概率最高的类别,但相对容易受到噪声的影响。
-
控制模型的自信程度: 蒸馏温度还可以影响模型的自信度。较高的温度导致模型更不确定,而较低的温度则会使模型更自信。这可以在训练过程中控制模型的泛化行为。
-
控制损失函数的平坦性: 由于知识蒸馏的损失函数通常涉及到交叉熵,温度参数也可以影响损失函数的平坦性。这有助于更稳定地训练小型模型,特别是当大型模型和小型模型结构不同或训练数据较小的情况下。
总体来说,蒸馏温度是一个用于调整软标签生成的超参数,可以影响训练过程中模型的学习行为,尤其是在知识蒸馏的场景中,它对平滑性、自信度和泛化等方面有一定的控制作用。
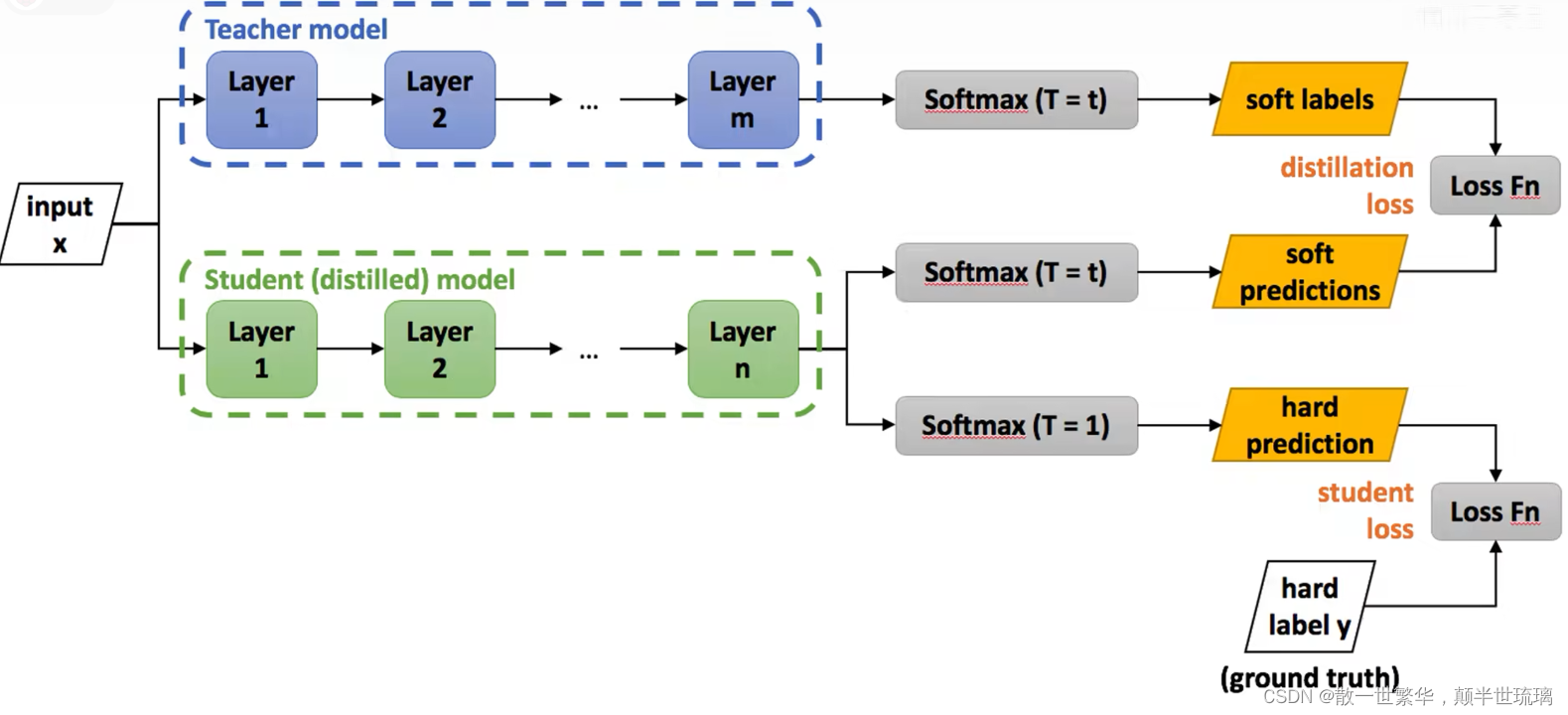
5.蒸馏过程
知识蒸馏是一种通过将一个大型模型的知识传递给一个小型模型来提高小型模型性能的技术。下面是知识蒸馏的详细过程:
1. 准备阶段:
- 大模型(Teacher Model): 选择一个在任务上表现较好的大型模型,例如深度神经网络,作为教师模型。
- 小模型(Student Model): 定义一个小型模型,通常拥有较少的参数,以便在资源受限的环境中进行部署。
2. 准备数据集:
- 使用训练数据集对大模型进行训练,得到大模型的参数。
- 使用相同的训练数据集生成硬标签(ground truth)和软标签(大模型的输出),以便用于小模型的训练。
3. 蒸馏训练阶段:
- 定义损失函数: 使用软标签进行训练的损失函数一般采用交叉熵损失,其中包括大模型的输出和小模型的输出。
- 反向传播优化: 通过反向传播和梯度下降等优化算法,调整小模型的参数,使其预测更接近大模型的输出。
4. 温度调整(可选):
- 蒸馏过程中的软标签通常受到温度参数的影响。可以尝试不同的蒸馏温度,以平衡模型的精确性和泛化性。
5. 评估阶段:
- 使用验证集或测试集对小模型进行评估,检查其性能。
- 比较小模型在蒸馏过程中和独立训练下的性能。
在知识蒸馏(Knowledge Distillation)中,通常同时会使用硬损失和软损失。硬损失用于确保模型能够正确地预测硬标签,而软损失则用于引导模型学习大型模型的知识。整体的损失函数可以写为硬损失和软损失的线性组合,其中温度参数通常用于控制软化的程度
6. 模型部署:
- 如果小模型的性能符合要求,可以将其部署到具体的应用场景中。
7. 超参数调整(可选):
- 根据小模型的性能和实际应用情境,对超参数进行微调,以进一步提升性能。
8. 迁移学习(可选):
- 在新任务上,可以使用小模型进行迁移学习,利用已学到的知识来加速模型的收敛。
知识蒸馏通过在训练中引入大模型的知识,使小模型能够在相对较小的规模下获得较好的性能。这对于在资源受限的环境中部署深度学习模型具有重要意义。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【C++项目报错】Cannot combine with previous ‘void‘ declaration specifier 【及解决方法】
- Hadoop——分布式计算
- kubectl命令中常用的缩写
- 电子学会C/C++编程等级考试2020年09月(三级)真题解析
- openGauss 5.0.0企业版一主一备安装部署
- 得物商品状态体系介绍
- 虎头金猫分享:最新Clion 2023.3.2 安装和试用教程
- oracle mybatis-plus使用in查询超过1000条限制解决办法
- 微软好听的tts语音包下载,粤语,韩语,日语
- 只要具备管理员级别的权限,就能更改MySQL根用户密码