Web自动化之验证码识别彻底解决方案
🍅 视频学习:文末有免费的配套视频可观看
🍅?关注公众号【互联网杂货铺】,回复 1?,免费获取软件测试全套资料,资料在手,涨薪更快
验证码识别解决方案
对于web应用程序来讲,处于安全性考虑,在登录的时候,都会设置验证码,验证码的类型种类繁多,有图片中辨别数字字母的,有点击图片中指定的文字的,也有算术计算结果的,再复杂一点就是滑动验证的。诸如此类的验证码,对我们的系统增加了安全性的保障,但是对于我们测试人员来讲,在自动化测试的过程中,无疑是一个棘手的问题。

1、web自动化验证码解决方案
一般在我们测试过程中,登录遇到上述的验证码的时候,有以下种解决方案:
- 第一种、让开发去掉验证码
- 第二种、设置一个万能的验证码
- 第三种、通过cookie绕过登录
- 第四种、自动识别技术识别验证码
2、自动识别技术识别验证码
前三种解决方案,想必大家都比较了解,本文重点阐述第四种解决方案,也就是验证码的自动识别,关于验证码识别这一块,可以通过两个方案来解决,
- 第一种是:OCR自动识别技术,
- 第二种是:通过第三方打码平台的接口来识别。
OCR识别技术
OCR中文名称光学识别, tesseract是一个有名的开源OCR识别框架,它与Leptonica图片处理库结合,可以读取各种格式的图像并将它们转化成超过60种语言的文本,可以不断训练自己的识别库,使图像转换文本的能力不断增强。如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。那么接下来给大家介绍一下如何使用tessract来识别我们的验证码。
关于OCR自动识别这一块,需要大家安装Tesseract,并配置好环境,步骤如下:
1)安装tesseract
适用于Tesseract 3.05-02和Tesseract 4.00-beta的
Windows安装程序下载地址:https://github.com/UB-Mannheim/tesseract/wik。
2)加入培训数据
tesseract 默认只能识别英文,如果您想要识别其他语言,则需要下载相应的培训数据
下载地址:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files,
下图为中文数据包

我们只做中文,暂时下载一个中文的文字训练数据就可以 ,然后将.traineddata文件复制到安装之后的'tessdata'目录中。C:\OCR\Tesseract-OCR\tessdata
3)配置环境变量
要从任何位置访问tesseract-OCR,您可能必须将tesseract-OCR二进制文件所在的目录添加到Path变量中C:\OCR\Tesseract-OCR。
- 安装后tesseract之后 ,并不能直接在python中使用,我们要想在python中使用,需要安装pytesseract模块我们可以通过 pip 安装
pip install pytesseract
- python中识别验证码图片内容
安装好后。找一张验证码图片,如下图(命名为test.jpg),放在当前python文件同级目录下面,

使用 PIL中的Image中的open方法打开验证码图片,调用pytesseract.image_to_string方法,可以识别图片中的文字,并且转换成字符串,如下面代码所示。
import pytesseract
from PIL import Image
pic = Image.open('test.jpg')
# pic 为打开的图片,lang指定识别转换的语言库
text = pytesseract.image_to_string(pic,lang='chi_sim')
print(text)通过上述方法能识别简单的验证码,但是存在一定的问题,识别的精度不高,对于一些复杂一点,有干扰线的验证码无法正确识别出结果。
接下来给大家介绍一下第二种识别的方案,第三方的打码平台识别
- 打码平台识别验证码
第三方的打码平台相对于OCR来讲,优势在于识别的精准度高,网络上的第三方打码平台很多,百度随便一搜就有几十个,这个给大家列举几个,如下所示:

网络上的第三方打码平台众多,这里小编选择超级鹰这个第三方的平台来给大家做演示。
首先登录我们需要注册登录超级鹰这个网站 www.chaojiying.com,进入之后我们找到python对应的开发文档并下载,
下载开发文档

下载之后解压缩,得到如下文件

第三方打码平台的接口分析
我们打开chaojiying.py这个文件后,会发现这个文件中给出了的接口非常简单,如下所示

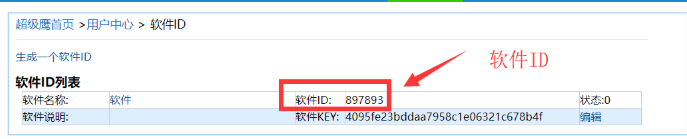
首先第一步创建一个用户对象:三个参数(账号,密码,软件ID),账号密码就是该网站的账号密码,那么软件ID呢?软件ID我们可以在用户中心找到软件ID,然后进去点击生成一个软件ID(如下图),
第二行代码就是打开一个要识别的验证码图片,并读取内容,
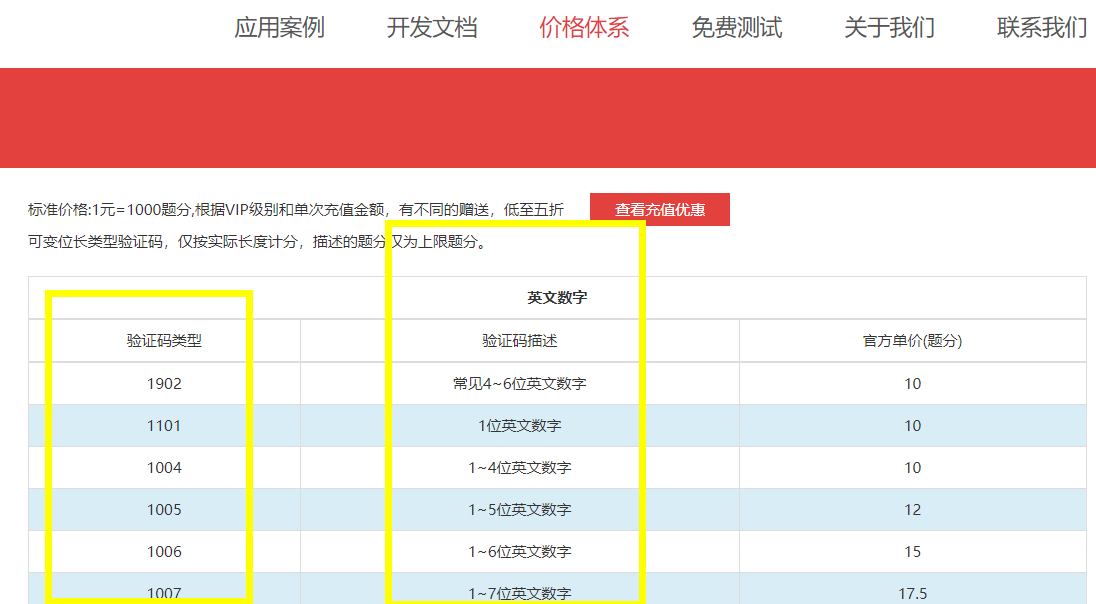
第三行,调用PostPic方法识别验证码,两个参数(验证码图片内容,验证码类型),关于验证码类型,请参考该网站的价格体系(如下图),根据验证码类型选择对应的数值传入。
结果提取:
PostPic返回的是一个字典类型的数据,识别的验证码在该字典中的pic_str这个键中
res = cjy.PostPic(im, 1902) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
data = res['pic_str']
print(data)第三方接口给大家介绍到这里,接下来我们实际应用到登录中去。
提示:打码平台一般都是收费的(差不多是一分钱,识别一次)
3、自动识别验证码登录案例
登录案例
接下来以超级鹰这个网站为列,使用web自动化测试框架selenium来实现验证码识别自动登录,
需要用到的库有selenium、pillow、time,和我们上面下载的超级鹰的接口文件
环境安装
1、selenium安装
pip install selenium
2、chromedriver 安装下载地址 http://chromedriver.storage.googleapis.com/index.html
下载和自己chrome浏览器对应的chromedriver版本,
配置环境变量
3、pillow模块安装(处理图像的库)
pip install pillow
实现步骤分析
1、获取账号密码输入框:输入账号密码
2、获取验证码图片
- 将当前页面截图
- 选择图片元素,获取上下左右位置
- 使用PIL模块对页面图片进行再次截图(获取验证码图片)
- 将验证码图片保存
3、调用第三方接口识别验证码
4、输入验证码结果
5、点击登录
具体代码实现
1、selenium打开登录页面
import time
from selenium import webdriver
from PIL import Image
from chaojiying import Chaojiying_Client
# 创建一个浏览器
browser = webdriver.Chrome()
# 访问登录页面
url = 'http://www.chaojiying.com/user/mysoft/'
browser.get(url)
time.sleep(1) # 暂停一秒钟2、获取账号密码输入框:输入账号密码
# 选择账号、密码输入栏,输入对应的账号密码
input_user=browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input')
# 输入账号
input_user.send_keys('账号')
input_pwd=browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input')
# 输入密码
input_pwd.send_keys('密码')2、获取验证码图片
- 将当前页面截图
# 对当前页面进行截图
browser.save_screenshot('login.png')- 选择图片元素,获取上下左右位置
# 选择验证码图片的元素
yzm_btn = browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/div/img')
# 获取图片元素的位置
loc = yzm_btn.location
# 获取图片的宽高
size = yzm_btn.size- 获取验证码上下左右的位置,此处要注意查看电脑显示的缩放比列(如下图),根据比列乘以相应的系数,我这边的显示比列是125,那么对于的系数就是1.25(如果你的是150,那么就乘以1.5)
left = loc['x']*1.25 # 计算左边界
top = loc['y']*1.25 # 计算上边界
right = (loc['x'] + size['width'])*1.25 # 计算右边界
botom = (loc['y'] + size['height'])*1.25 # 计算下边界
# 将上下左右边界值放到元祖中(注意顺序:左 上 右 下)
local = (left, top, right, botom)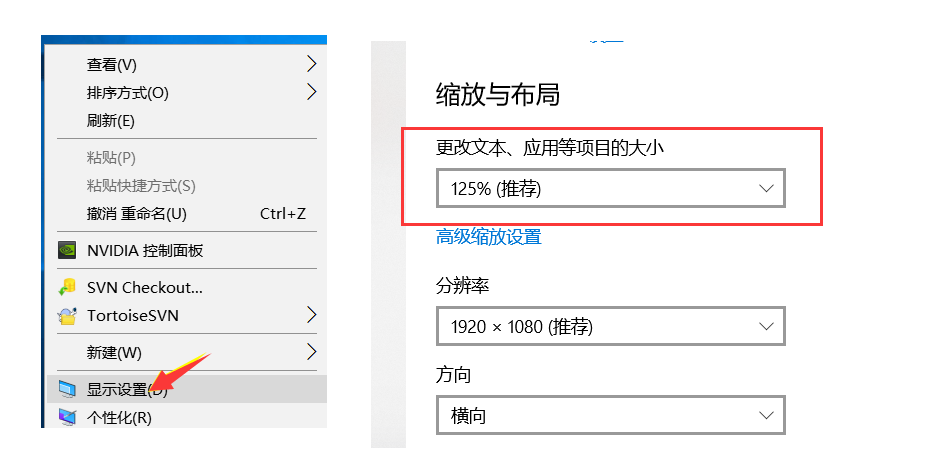
- 使用PIL模块对页面图片进行再次截图(获取验证码图片),将验证码图片保存
pic = PIL.Image.open('file')
pic.crop(local)
pic.sava('zym,png')3、调用第三方接口识别验证码
# 识别验证码
cjy = Chaojiying_Client('账号', '密码', '软件ID') # 用户中心>>软件ID 生成一个
im = open('yzm.png', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
res = cjy.PostPic(im, 1902) # 1902 验证码类型
data = res['pic_str']
print(data)4、输入验证码结果
# 在输入框输入验证码
yzm_input = browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input')
yzm_input.send_keys(data)5、点击登录
# 点击登录
submit = browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input')
submit.click()完整代码如下(账号密码自行修改):
import time
from selenium import webdriver
from PIL import Image
from chaojiying import Chaojiying_Client
# 创建一个浏览器
browser = webdriver.Chrome()
# 访问登录页面
url = 'http://www.chaojiying.com/user/mysoft/'
browser.get(url)
time.sleep(1) # 暂停一秒钟
# 选择账号、密码输入栏,输入对应的账号密码
input_user = browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input')
input_user.send_keys('账号')
input_pwd = browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input')
input_pwd.send_keys('密码')
# 获取验证码的图片,并进行识别,将识别的结果,输入到验证码输入框中
# 对当前页面进行截图
browser.save_screenshot('login.png')
# 选择验证码图片的元素
yzm_btn = browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/div/img')
# 获取图片元素的位置
loc = yzm_btn.location
# 获取图片的宽高
size = yzm_btn.size
# 获取验证码上下左右的位置
left = loc['x']*1.25
top = loc['y']*1.25
right = (loc['x'] + size['width'])*1.25
botom = (loc['y'] + size['height'])*1.25
val = (left, top, right, botom)
# 打开网页截图
login_pic = Image.open('login.png')
# 通过上下左右的值,去截取验证码
yzm_pic = login_pic.crop(val)
yzm_pic.save('yzm.png')
# 识别验证码
cjy = Chaojiying_Client('账号', '密码', '软件ID') # 用户中心>>软件ID 生成一个替换 96001
im = open('yzm.png', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
res = cjy.PostPic(im, 1902) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
data = res['pic_str']
print(data)
# 在输入框输入验证码
yzm_input = browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input')
yzm_input.send_keys(data)
# 点击登录
submit = browser.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input')
submit.click()最后祝大家都能找到心仪的工作,快乐工作,幸福生活,广阔天地,大有作为。我也整理了一波之前发布的软件测试文档【点击文末小卡片免费领取】,无套路领取!
同时,在这我为大家准备了一份软件测试视频教程(含面试、接口、自动化、性能测试等),就在下方,需要的可以直接去观看,也可以直接【点击文末小卡片免费领取资料文档】
软件测试视频教程观看处:
【2024最新版】Python自动化测试15天从入门到精通,10个项目实战,允许白嫖。。。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 17、 序列实例化
- 「用户与社区的深度对话」2023年度IvorySQL满意度调研
- kubernetes-日志系统Loki
- 《成才之路》期刊投稿方式发表论文要求
- 统一网关 Gateway【微服务】
- Apifox 最新更新:迭代分支功能上线、在线文档支持多格式导出!
- mysql 锁 事务 脏读 不可重复读 幻读
- Java版工程行业管理系统源码-专业的工程管理软件- 工程项目各模块及其功能点清单
- 数模学习day08-拟合算法
- C++继承与派生——(1)继承的层次关系