Transformer简略了解
Transformer出自论文:《Attention Is All You Need》
该论文的提出,对RNN循环神经网络产生了冲击,席卷了自然语言处理(NLP)领域,后续的GPT4.0版本也是根据其进行训练优化的
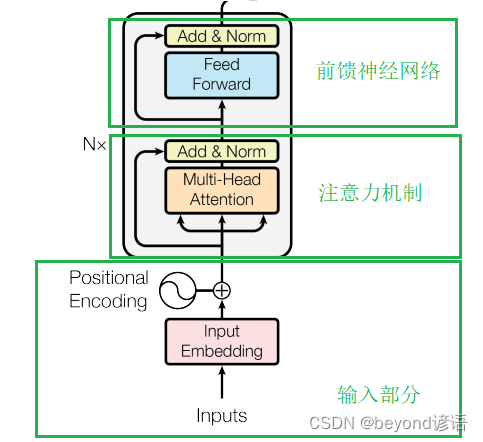
一、Transformer主体架构
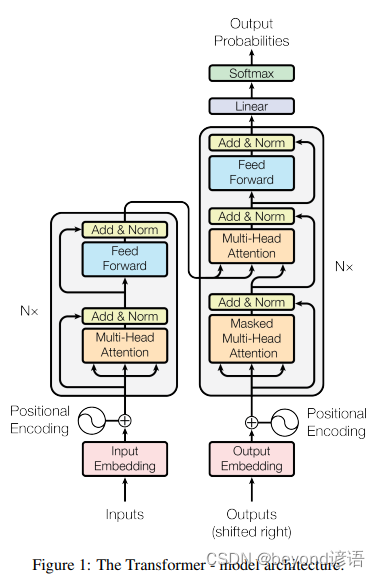
可以简化分为Encoders和Decoders,之所以是复数,其主要是由于N个所决定的,论文N的取值为6,每个Encoder结构都是一样的;同理每个Decoder也是相同的结构。但Encoder和Decoder结构大相径庭了
简化流程:输入 —> Encoders(6个Encoder) —> Decoders(6个Decoder) —> 输出
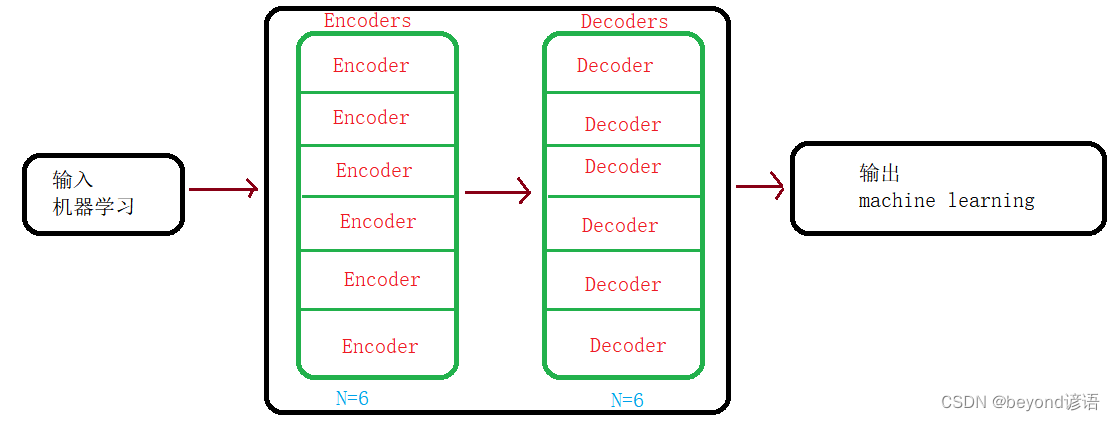
Ⅰ、Encoders
Encoders由N个Encoder所组成,其中N在论文中取值为6
Ⅱ、Decoders
Decoders由N个Decoder所组成,其中N在论文中取值为6
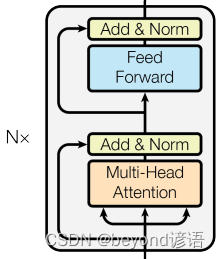
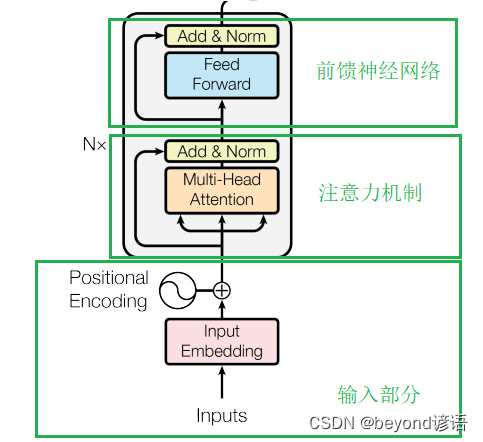
二、Encoder
单挑出一个Encoder进行分析,其主要可分为三部分:
①输入部分、②注意力机制、③前馈神经网络
Ⅰ,输入部分
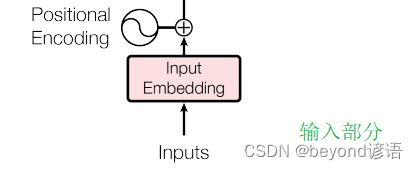
输入部分主要包括:Embedding和Positional Encoding位置编码

RNN中翻译:家驹
RNN结构中,是需要接收前面的数据之后再进行学习,先传入家,驹的学习是依据家为基准进行的,需要考虑到前面的数据
而在Transformer中,多头注意力机制是可以并行处理数据的,家,驹是一并输入的,并不需要考虑之前的汉字之间的前后关系,故需要Positional Encoding位置编码告诉模型哪个字在前哪个字在后
例如:创建一个维度为512的词向量
1.Embedding
以翻译为例:把每个对应的字对应生成不同维度的向量,从而生成一个向量表,方便后续学习,共计512维度
2.Positional Encoding位置编码
论文中给出的位置编码公式: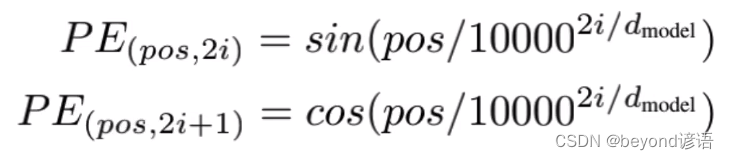
其中pos表示单词或字的位置;2i代表偶数,2i+1代表奇数
在偶数的位置使用sin,在奇数位置使用cos
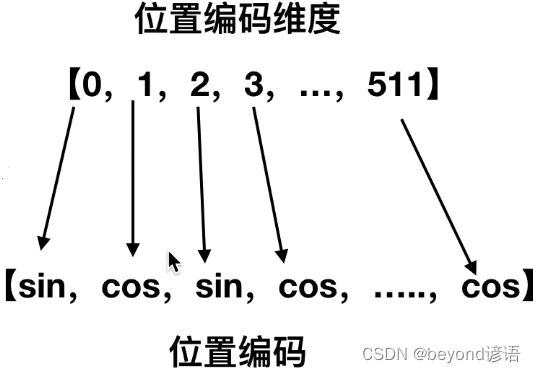
将Embedding得到的512维度和Positional Encoding得到的512维度信息进行相加,得到一个最终的512维度信息,作为整个Transformer的输入

问:为什么位置嵌入是有用的?
答:正余弦函数,对于同一个Position,不同的函数可以得到一个绝对的位置信息

但,这种相对位置信息会在注意力机制那里消失
Ⅱ、注意力机制
1.基本的注意力机制
i)注意力机制的本质
带着问题看图片:婴儿在干嘛?

颜色深的地方为人们的主要关注的地方
那么如何将关注的区域和这句话进行相互关联,这就是注意力机制所要解决的问题
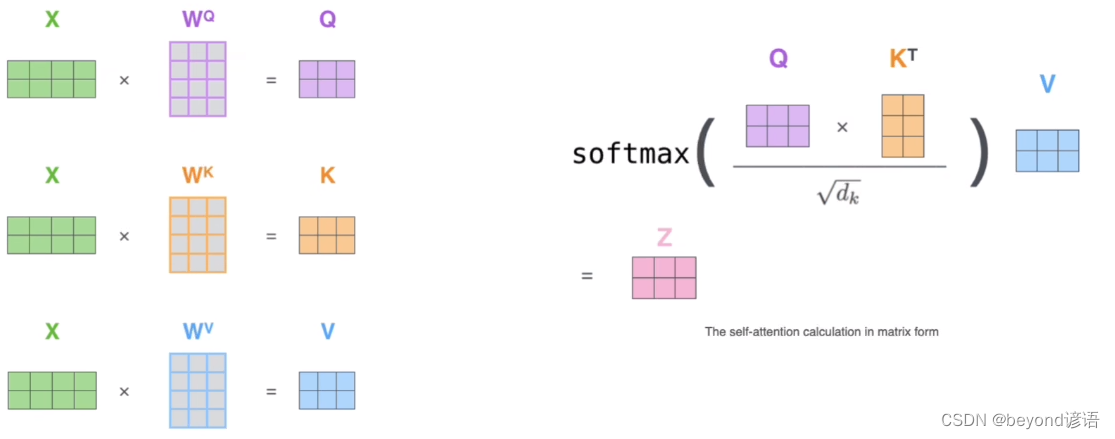
论文中给出的注意力机制公式: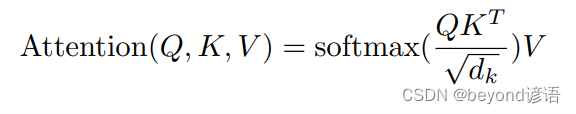
其中Q,K,V为三个矩阵,通过softmax进行归一化,得到一个相似度向量,然后再乘以V矩阵,最终得到一个加权的和
首先拿到一张图片,将图片进行上下左右四分割,并生成四个Key
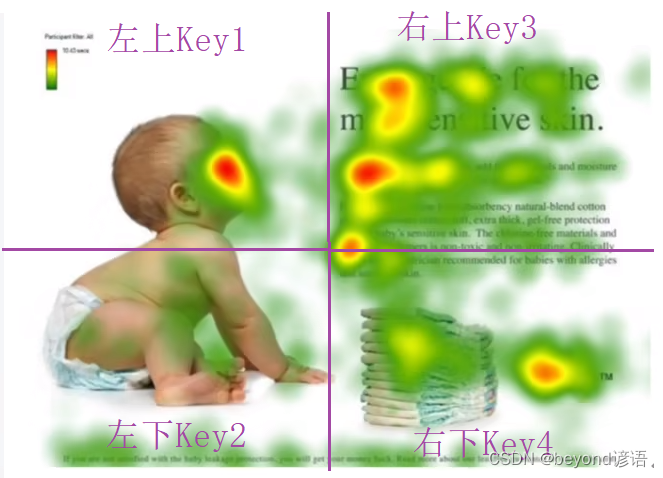

公式中的Q:Query这里传入的是婴儿
K为这里对于生成的Key1、Key2、Key3、Key4
V为Key1-Key4所对应的某种值向量,Value1,Value2,Value3,Value4
点乘:一个向量在另一个向量上投影的长度,是一个标量,可以反应两个向量的相似度。即两个向量点乘结果越大,两个向量越相似
Transformer中原理过程:
婴儿分别与Key1-Key4进行点乘操作,看哪个结果最大,表明越关注哪块区域
例如:婴儿与Key3点乘结果最大,表明更关注右上区域
之后在与V矩阵相乘,得到最终的加权和Attention Value
ii)获取Q、K、V矩阵
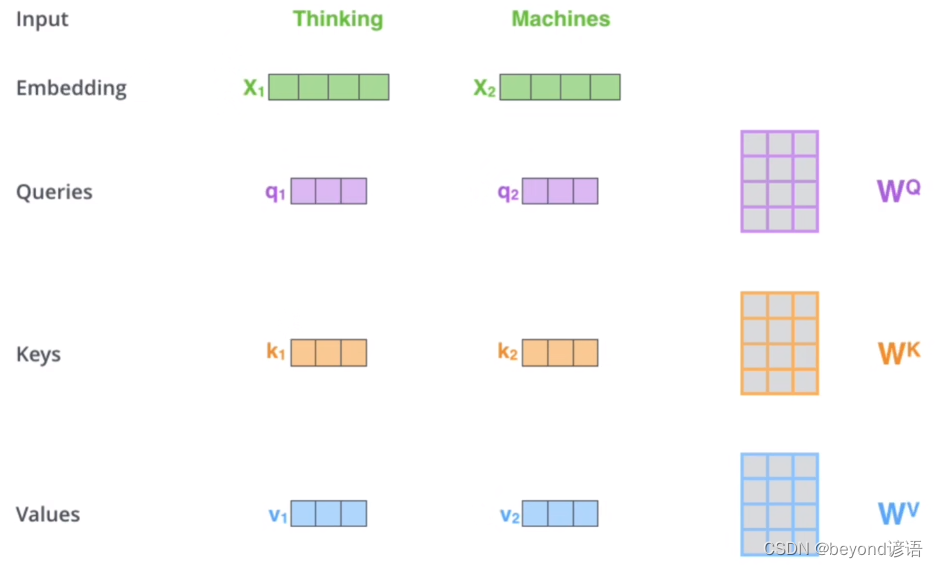
以X1为例,X2也类似: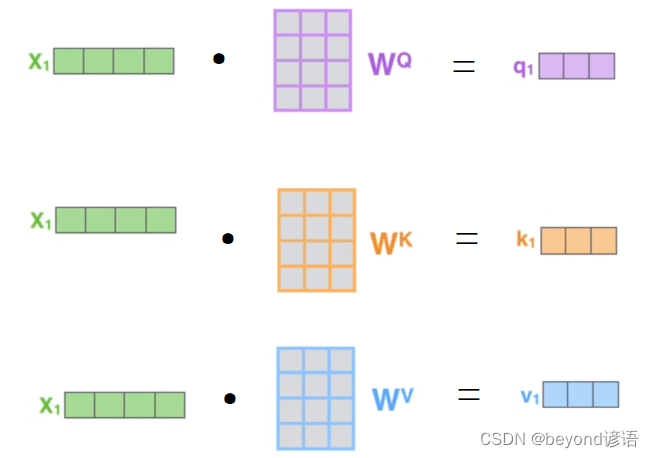
得到Q、K、V之后带入公式即可
实际代码使用的是矩阵,方便并行运算
多头注意力机制主要是因为参数有多套,得到的Q、K、V也有多套
多头相当于把原始数据信息映射到不同的空间
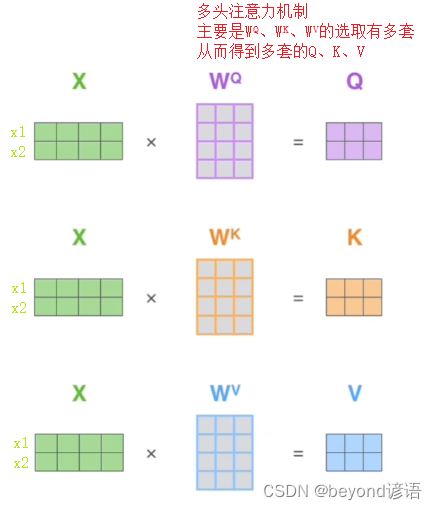
例如将原始信息进行映射到两个空间
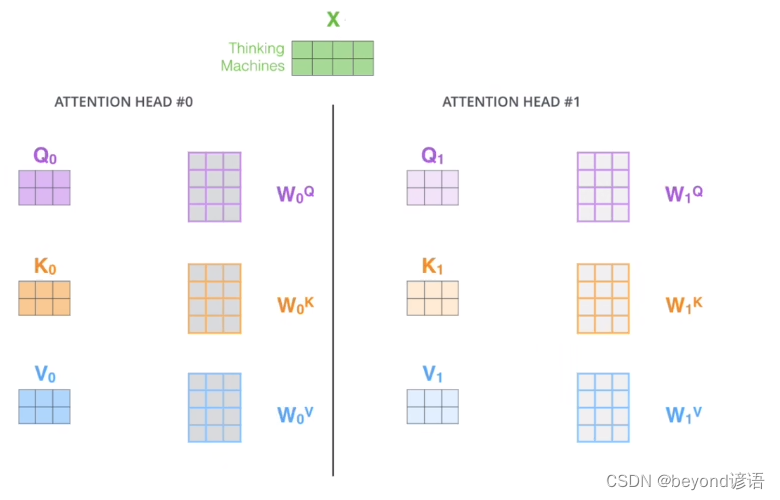
将映射到不同空间最终的输出信息进行合并,乘以一个矩阵即得到一个多头注意力机制的输出
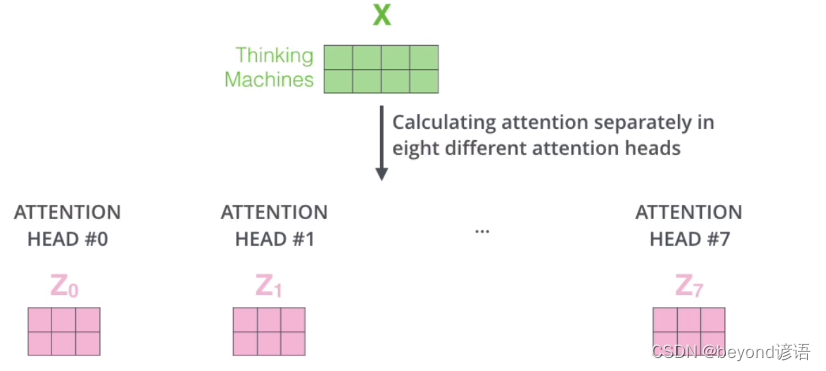
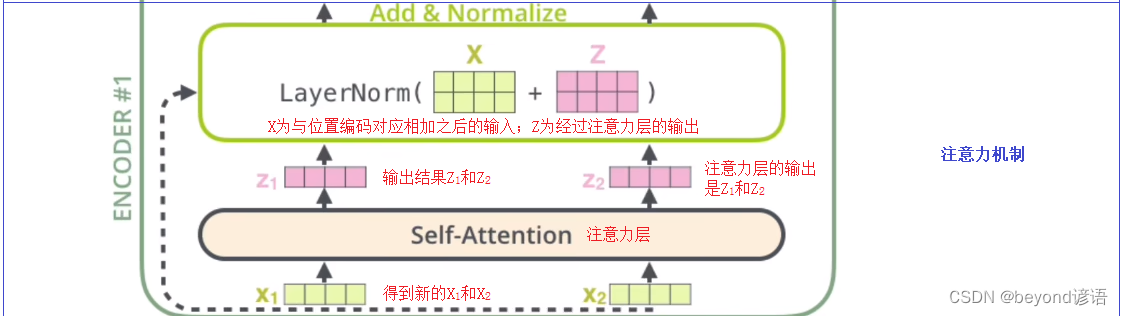
2.残差和LayNorm
i)残差
X作为输入,经过两层网络,这两层网络统一归为函数F(X)
输入参数X通过两层网络得到输出F(X)
残差:将输入X原封不动的与得到的输出F(X)进行对位相加,得到最终的输出
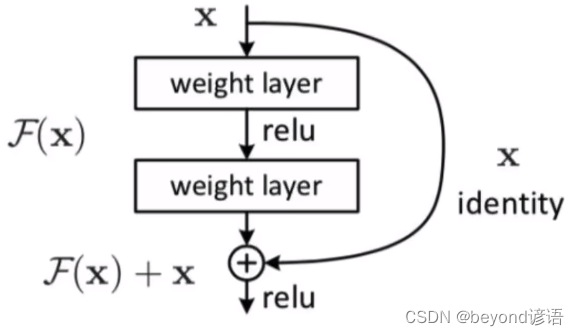
梯度消失一般情况下是因为连乘的原因,连乘的过程中出现了较小的数,导致越乘越小,从而产生梯度消失
而在残差网络中,通过反向传播链式法则可以看到,因为1的出现导致无论多小的数,确保梯度不为零,从而有效克服了梯度消失的出现,这也是NLP中使用了残差网络就可以使得网络层数更深的原因

ii)Layer Normalization
Batch Normalization效果差,所以不用
在NLP中,BN使用的很少,一般都是以LN
①Batch Normalization背景
其核心是Feature Scaling,主要是为了让模型收敛的更快
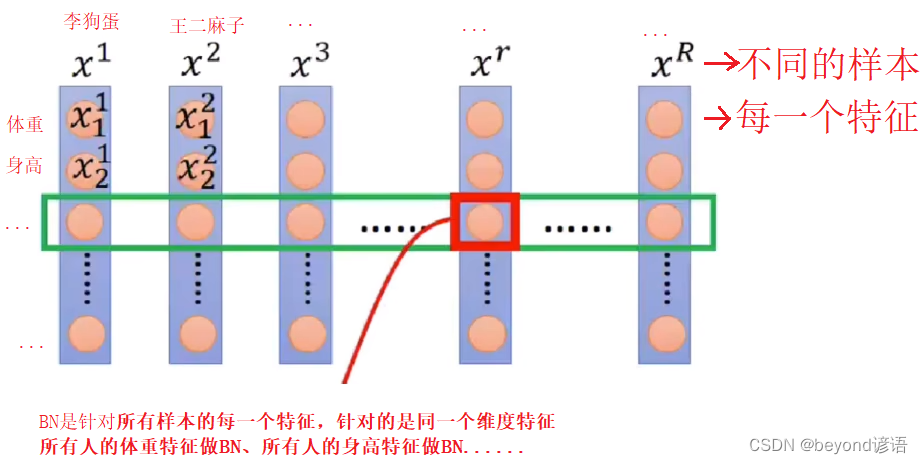
BN重点在于:针对整个Batch中的样本在统一维度特征下进行处理
BN的过程使用的是:整个batch中的样本的均值和方差来模拟全部数据的均值和方差
②Batch Normalization的优缺点
优点:
1,可以解决内部协变量偏移
2,可以缓解梯度饱和问题
缺点:
1,当batch_size较小的时候,BN效果较差
因为BN是整个batch中的样本的均值和方差来模拟全部数据的均值和方差;若batch_size较小的情况下,就很难代表全部数据
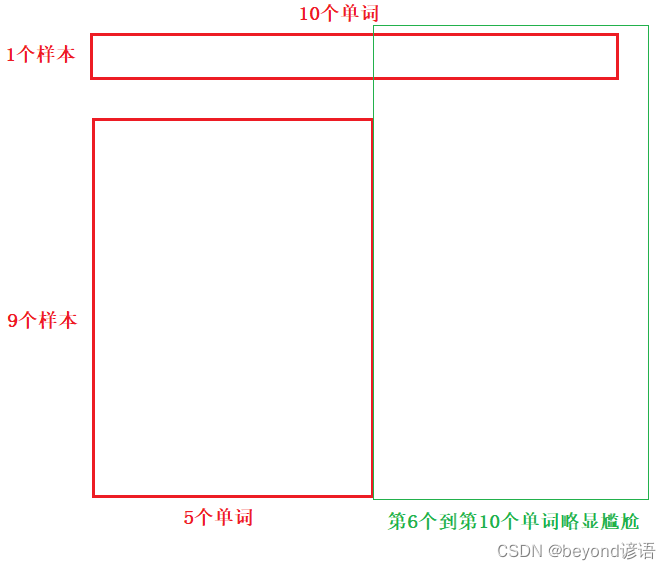
2,在RNN中效果较差
因为RNN的输入是动态的;若有10个样本,其中9个样本长度为5个单词,1个样本长度为10个单词;在输入的时候,前5个单词可以使用10个样本进行计算均值和方差;但,第6个单词到第10个单词,均值和方差就尴尬了,因为只有1个样本有第6到第10个单词,若只用这一个样板进行计算,又变成了缺点1,batch_size小,不能够得到整个batch_size下的均值和方差
③为什么使用Layer-norm
为什么LayerNorm单独对一个样本的所有单词做缩放可以起到效果?
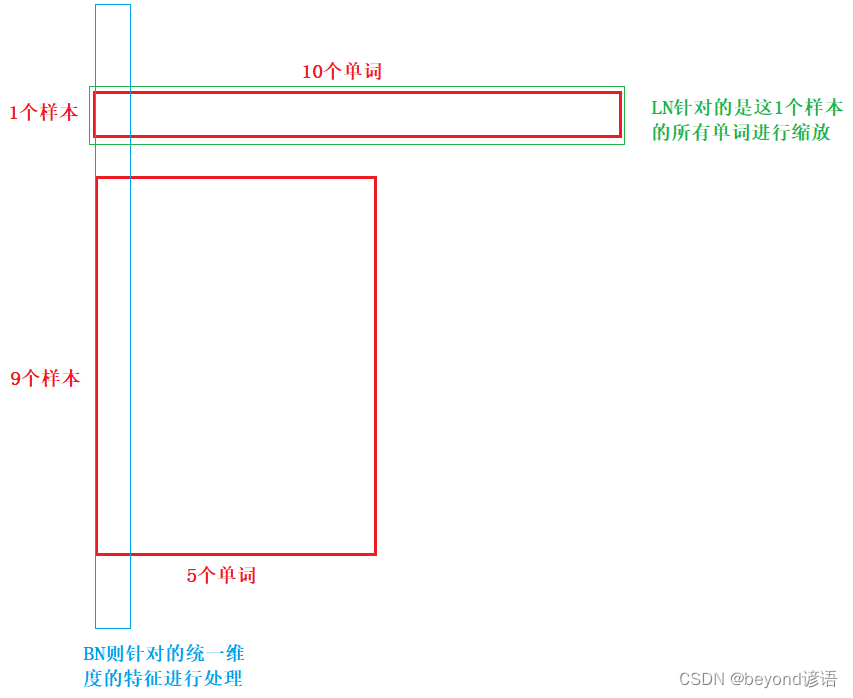
因此BN在NLP中是存在问题的!
BN在处理NLP任务中,会将仍和用当成同一个语义信息及性能处理,这边出现了问题
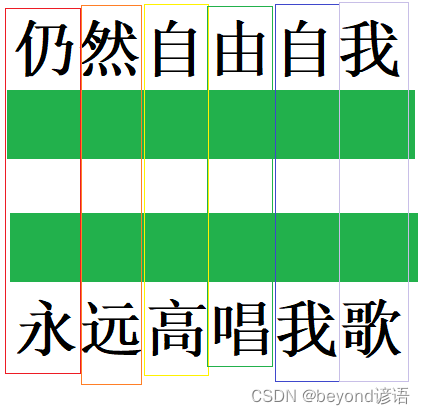
LN则将整个样本进行处理,每个样本都是在同一个语义信息当中的,所以LN是可以理解的

Ⅲ、前馈神经网络
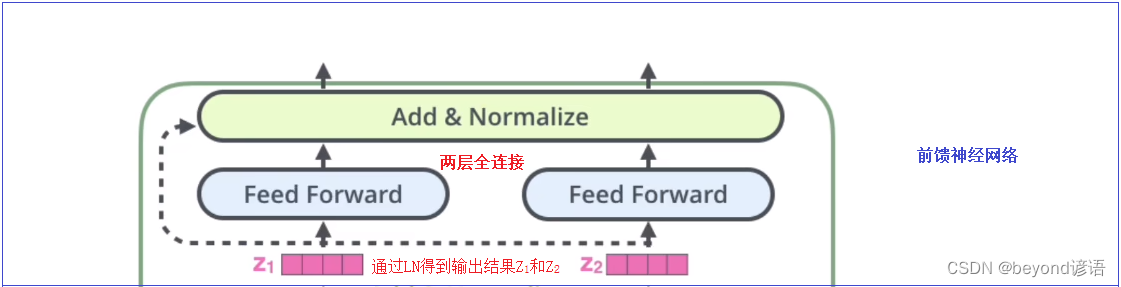
Ⅳ、总结
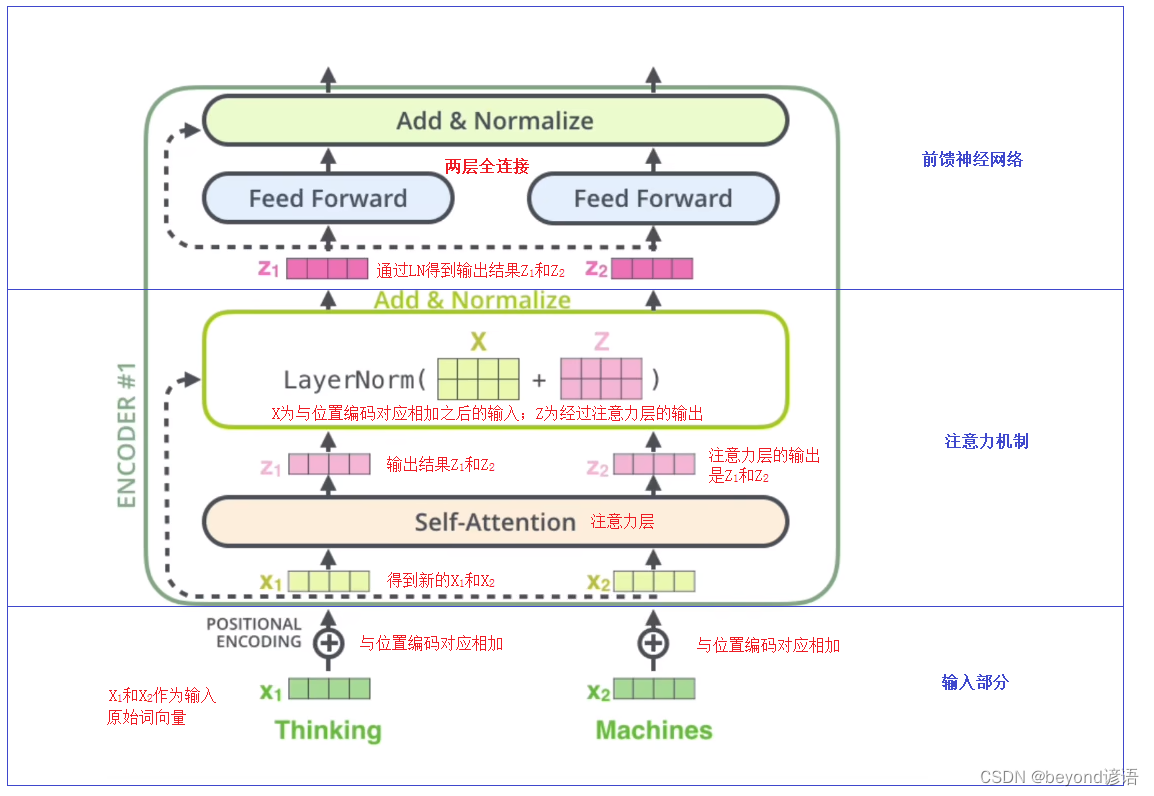
首先,Inputs输入,得到一个Input Embedding,然后与Positional Encoding位置嵌入进行对位相加,作为整体的输入
得到多头注意力机制,通过残差结构,与多头注意力机制进行相加,得到残差结构的结果,在进行LN得到最终的注意力机制模块的输出结果
然后进行两层Feed Forward全连接,输出结果保持不变,通过残差结构进行相加,然后通过LN得到最终的输出结果
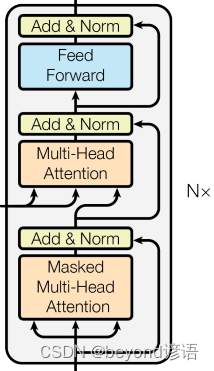
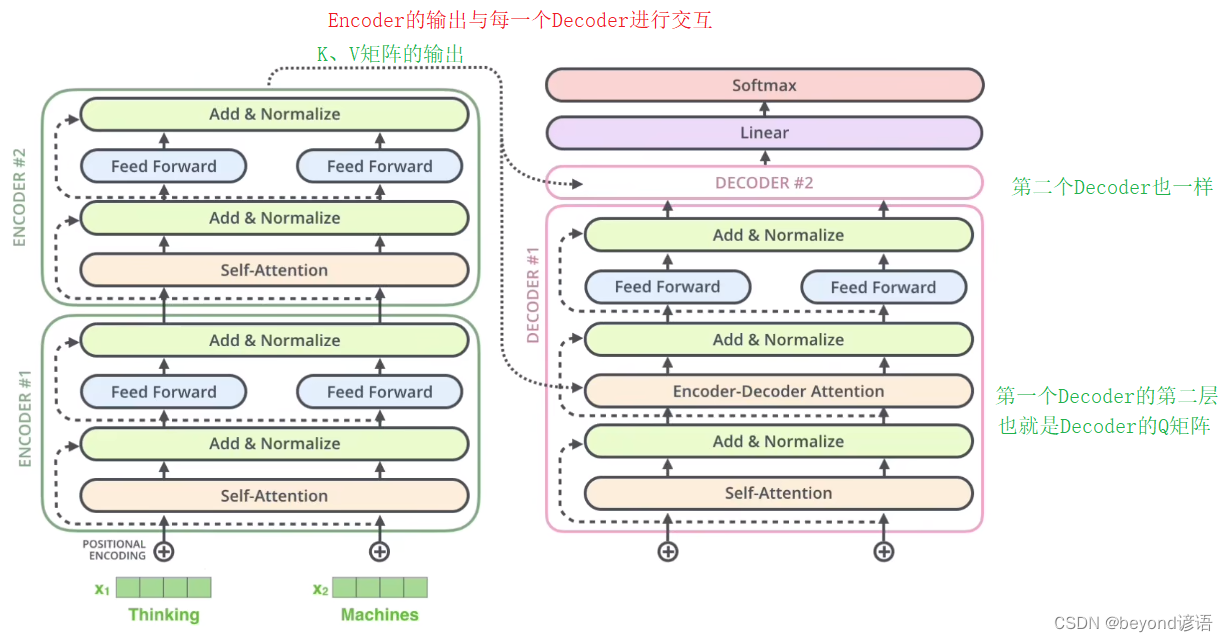
三、Decoder
Decoder和Encoder类似,均由N个完全相同的大模块堆叠构成,论文中N为6
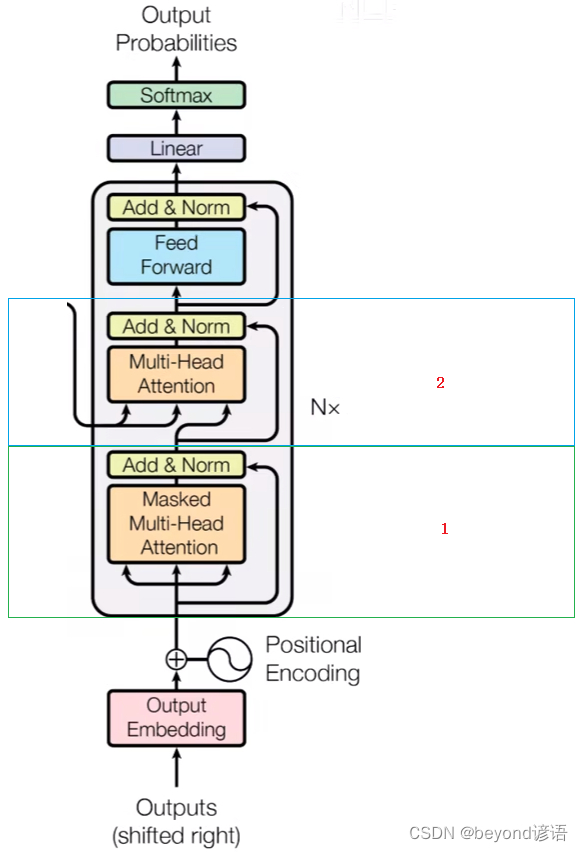
Ⅰ,Masked Multi-Head Attention掩膜多头注意力机制
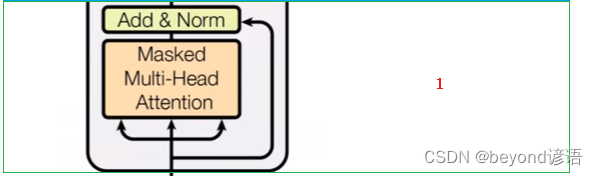
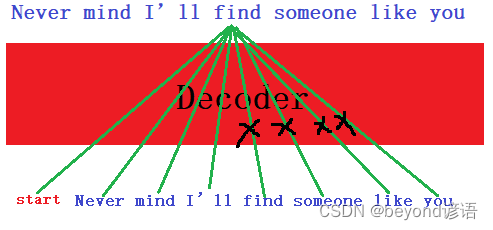
对输入的单词进行mask掩膜操作
mask的作用
正常情况下的机器翻译

若Decoder中没有mask,和Encoder一模一样的多头注意力机制话;若到生成find的时,所有的单词都会为生成find进行提供相应的语义信息;但模型在预测的时候,find之后的信息是不知道,没有find someone like you这些信息的,模型是看不见未来的单词的,此时就需要mask掉find someone like you这些信息
模型训练find的时候看到了find someone like you未来信息,但是预测的时候是看不到未来信息的,故需要进行mask操作

此时需要mask掉find someone like you
Ⅱ,交互层
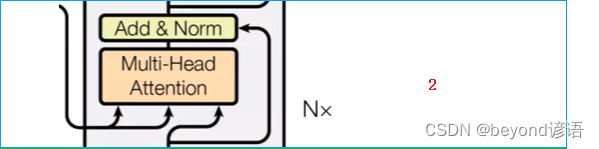
这里是Multi-Head Attention,没有mask
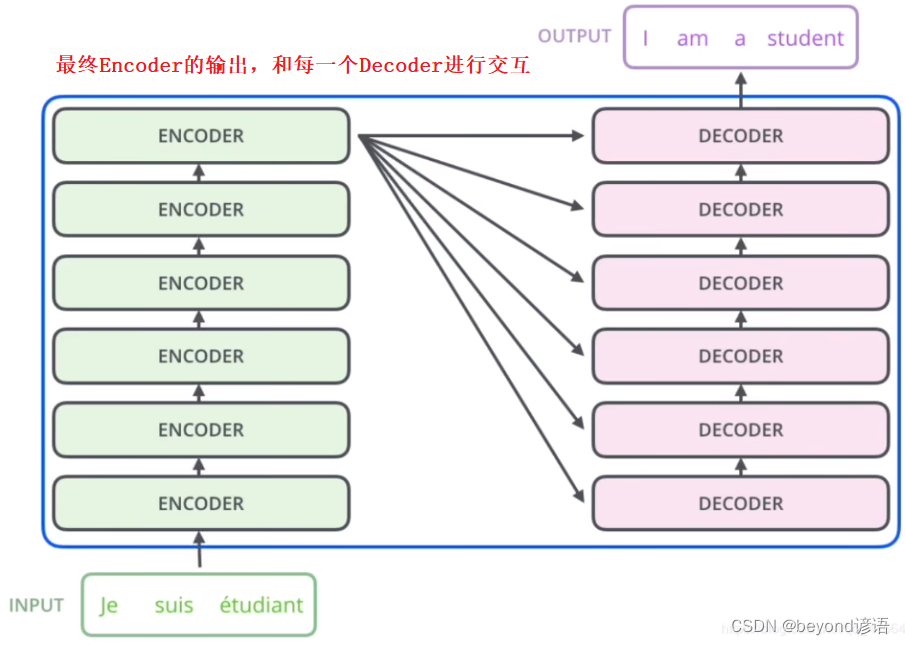
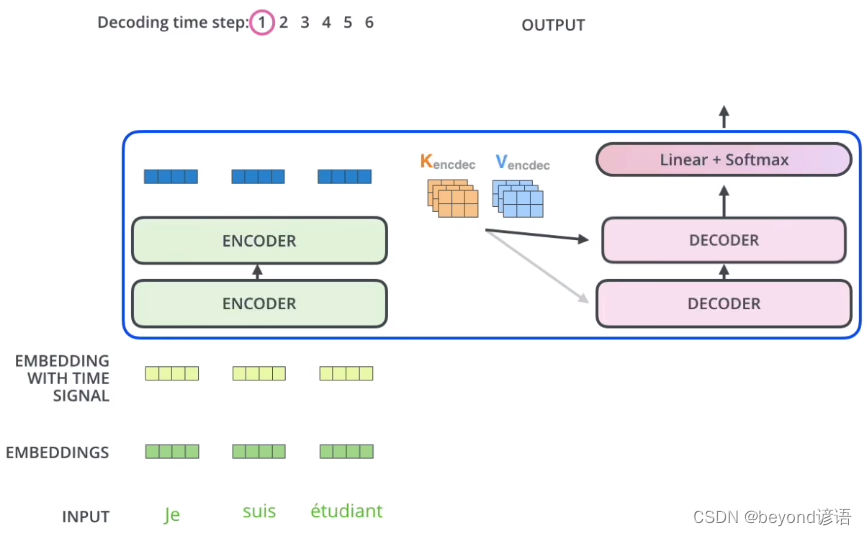
Encoder生成的是K、V矩阵
Decoder生成的是Q矩阵
多头注意力机制由K、V、Q三个矩阵
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 鹅厂有料有趣的程序员交流圈重磅官宣!加入立享福利
- 汽车行业里的DPM条码扫描解析
- 接口自动化测试实战经验分享(附教程)
- 制图新手首选!6款在线软件,让制图变得简单易学!
- 阿里云RDS MySQL 数据如何快速同步到 ClickHouse
- vue+springboot+mybatis-plus实现乡村公共文化服务系统
- 误删除的备忘录恢复方法是什么?备忘录不小心删除了怎么找回?
- 深度解析ShardingJDBC:Java开发者的分库分表利器
- C语言链表、树、图的实现(结构体)
- C++项目:my_vector的裸实现