【Python数据分析案例】基于泰坦尼克船员数据的完整数据分析全过程
此案例展现了完整的数据分析流程,思路可作用于数据分析、建模等工作。
如果想看更多Python数据分析基础内容可参考:?
https://codeknight.blog.csdn.net/article/details/135565847![]() https://codeknight.blog.csdn.net/article/details/135565847
https://codeknight.blog.csdn.net/article/details/135565847
=======================================================================?
目录
3、embarked其实是embark_town的缩写所以表达重复,删掉一个
8、将转换成数字的变量拼接在data中并删除object型变量
1、划分特征变量(自变量\独立变量)与响应变量(因变量\依赖变量)
前提准备
编程开始前,我们获取到数据集:
Python数据分析+机器学习+深度学习教程源码: Python数据分析+机器学习+深度学习教程源码 - Gitee.com
在我的gitee仓库中下载此文件:

这个就是我们本次使用的案例数据

编译环境还是我们熟悉的Anaconda3 Jupyter Notebook,不了解的同学依旧参考此篇:
https://codeknight.blog.csdn.net/article/details/135565847
?函数库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlinenow,废话不多说,让我们开始本次数据分析之旅!
=============================================================》》》
第一步:读取数据
data = pd.read_csv('./seaborn-data/titanic.csv')
各列信息的具体含义
\tsurvived\tpclass\tsex\tage\tsibsp\tparch\tfare\tembarked\tclass\twho\tadult_male\tdeck\tembark_town\talive\talone
\t幸存\t船舱等级\t性别\t年龄\t兄弟姐妹数\t父母子女数\t票价\t登船港口\t船舱等级\t姓名\t成年男性\t甲板号\t登船城市\t?存活\t独自一人
第二步:数据分析
#统计存活人数
sns.set_style('darkgrid')#style : dict, or one of {darkgrid, whitegrid, dark, white, ticks}
sns.countplot(x='survived',data=data)#Show the counts of observations in each categorical bin using bars.
#统计存活人数
data['survived'].value_counts()
data[data['survived']==1].describe()
#分析死亡人数的男女比例
sns.set_style('darkgrid')#style : dict, or one of {darkgrid, whitegrid, dark, white, ticks}
sns.countplot(x='survived', hue="sex",data=data,palette='rainbow')#Show the counts of observations in each categorical bin using bars.
data[data['survived']==1]["sex"].value_counts()#data[data['survived']==1]-->&data
#各船舱级别死亡与存活人数统计
sns.countplot(x='class', hue="survived",data=data)
#分析船员的年龄分布
sns.displot(data['age'].dropna(),kde=True,color='darkred',bins=40)#分布图
data['age'].hist(bins=30)
#带有家庭成员的人数统计
sns.countplot(x='sibsp',data=data)
sns.countplot(x='alone',data=data)
data['fare'].hist(color='blue',bins=30,figsize=(10,5))?
第三步:缺失值检测
1、缺失数据检测
data.isnull() #或者isna()
#用图像的方式更加直观的显示
sns.heatmap(data.isnull())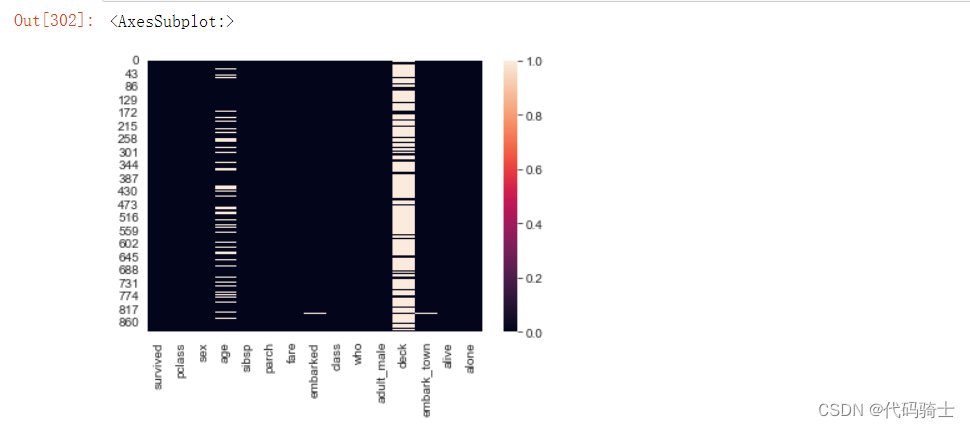
2、寻找缺失数据
有四列数据含有缺失值,分别是age、embarked、deck和embark_town
#图像显示彩色
sns.heatmap(data.isnull(),yticklabels=False,cbar=False,cmap='rainbow')?
3、统计各缺失数量,选取合适的解决办法
#age数据缺失的个数
data['age'].isnull().sum()#age数据缺失率
data['age'].isnull().sum()/(data['age'].count()+data['age'].isnull().sum())#data['age'].count()表示age存在的个数,分母=891#embarked数据缺失的个数
data['embarked'].isnull().sum()#embarked数据缺失率
data['embarked'].isnull().sum()/891#deck数据缺失的个数
data['deck'].isnull().sum()#deck数据缺失率
data['deck'].isnull().sum()/891#embark_town数据缺失个数
data['embark_town'].isnull().sum()#embark_town数据缺失个数
data['embark_town'].isnull().sum()/891
第四步:数据清洗
1、处理年龄缺失值
根据船员中age与class之间的关系,将年龄分为三个不同的级别,然后求出各个不同级别年龄的平均值,用该值替代表中的缺失部分。
plt.figure(figsize=(12, 7))
sns.boxplot(x='pclass',y='age',data=data)
箱型图,也被称为箱线图,是一种描述数据离散分布情况的图形,可以直观地识别异常值和偏态。这种图表可以比较不同组别间的集中趋势、方差和偏度,并能够探索数据特征和异常值。
在阅读箱型图时,主要需要关注以下几个部分:
- 箱体:箱体的上下边界分别是第三四分位数(Q3)和第一四分位数(Q1),箱体的高度代表了中间50%的数据范围。
- 须子:须子的顶端是上四分位数(Q4),底端是下四分位数(Q2)。
- 中线:中线位于箱体的中心,表示数据的中位数。如果数据是正态分布的,那么中线应该穿过箱体的中心。
- 异常值:任何超出箱体范围的点都被视为异常值,通常用一个点来表示。
此外,箱型图还可以进行分组比较和假设检验,并且能够显示离群点的信息和数据的分组、峰度等。但需要注意的是,虽然箱型图具有诸多优点,但它也存在一定的局限性。
年龄按船舱级别获取中位数?
data[data['pclass']==1]['age'].median()#Return the median of the values(中位数) over the requested axis.data[data['pclass']==2]['age'].median()data[data['pclass']==3]['age'].median()
def addage(x):#x是一个列表,可以用下标取值
Age = x[0]#年龄
Pclass = x[1]#船舱等级
if pd.isnull(Age):#如果年龄为空,根据船舱等级中位数进行填补
if Pclass == 1:
return 37
elif Pclass == 2:
return 29
else:
return 24
else:#年龄不为空,还是原来值
return Agedata[['age','pclass']]
#对data数据age列赋值(通过addage函数将缺失值按照不同级别的船舱的年龄中位数进行填补)
data['age'] = data[['age','pclass']].apply(addage,axis=1)这段代码定义了一个名为addage的函数,该函数接受一个包含年龄和舱位等级的列表作为输入。如果年龄为空(即缺失值),则根据舱位等级返回一个默认的年龄值。如果年龄不为空,则直接返回年龄值。最后,使用apply函数将addage函数应用于数据框data的'age'和'pclass'列,并将结果存储在新的'age'列中。
#用图像的方式更加直观的显示
sns.heatmap(data.isnull())
由此可见,年龄的缺失值已经填充好了。
2、处理deck缺失值
因为deck表示港口号,而港口号和我们想要预测的存活/死亡的结果影响不大,又因为大部分港口号缺失严重的原因,此列可以直接删掉。
data['deck'].isnull().sum()/891data.drop('deck',axis=1,inplace=True)#inplace if False, return a copy. Otherwise, do operation
sns.heatmap(data.isnull(),yticklabels=False,cbar=False,cmap='rainbow')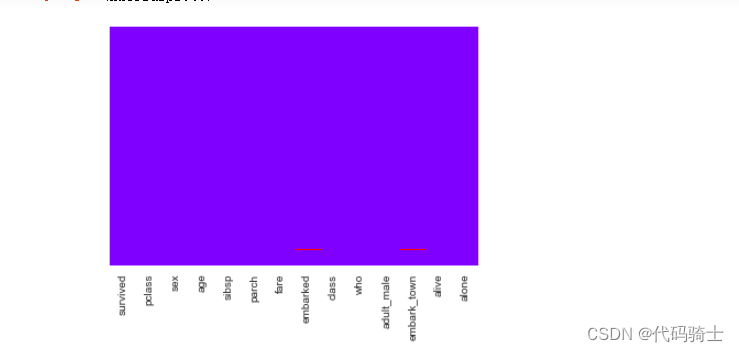
3、embarked其实是embark_town的缩写所以表达重复,删掉一个
data.drop('embark_town',axis=1,inplace=True)#inplace if False, return a copy. Otherwise, do operation
sns.heatmap(data.isnull(),yticklabels=False,cbar=False,cmap='rainbow')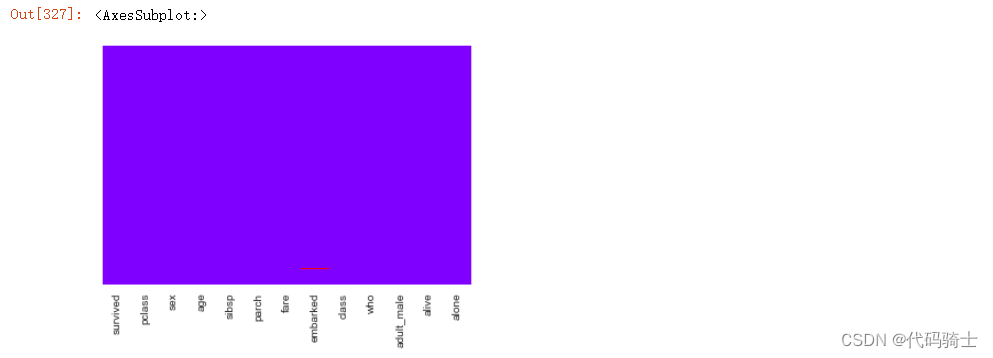
?4、处理embarked缺失值
data["embarked"].isnull().sum()
因为缺失数量很小,可以忽略不计,通过后面使用虚拟变量替换时,自动填充。
第五步:数据类别转换
data.info()
#类似于name这种敏感信息一般是对分析数据无意的,所以项目中一般会进行脱敏处理或者直接忽视
在data中主要有两种不同的数据类型,一种是数字型(Number),一种是对象(object)。前者主要是整数或者浮点数,可直接用来计算,而后者一般为字符串,不适合数值计算,需要通过虚拟变量替换手段将字符改变为数字表示。
主要有以下五种object列:
sex
embarked(含有缺失值)
class
who
alone
alive
还有bool类型的adult_male、alone后续也将处理
1、处理sex
data['sex'].value_counts()
pd.get_dummies(data['sex'])
get_dummies函数是Python的pandas库中的一个函数,用于将分类变量转换为虚拟/指示变量。它的主要作用是将类别变量转换为0和1的形式,以便于进行机器学习模型的训练。
因为female和male是sex的两种不同的属性,且当一个为真时,另一个一定为假,所以不存在00或11的情况,只存在01或10情况,所以只需要一个bit位就能表示sex的男女了,如1表示男,0表示女。
那么,便可以通过调整get_dummies()函数里的参数来控制变量的多少。(drop_first=True)
pd.get_dummies(data['sex'],drop_first=True)
sex = pd.get_dummies(data['sex'],drop_first=True)#用变量将转换完的sex列存储起来
2、处理embarked
data[data['embarked'].isna()]
data['embarked'].value_counts()

data['embarked'].unique()
pd.get_dummies(data['embarked'])#用同样的方式替换变量,发现nan值直接忽略了,因为本身nan值的个数只有两个,所以关系不大,不用考虑
#同理,因为三种结果是互斥的,只要用两个bit位就能表示出三种不同结果了如C:00、S:01、Q:10
pd.get_dummies(data['embarked'],drop_first=True)
embark = pd.get_dummies(data['embarked'],drop_first=True)embark.value_counts()?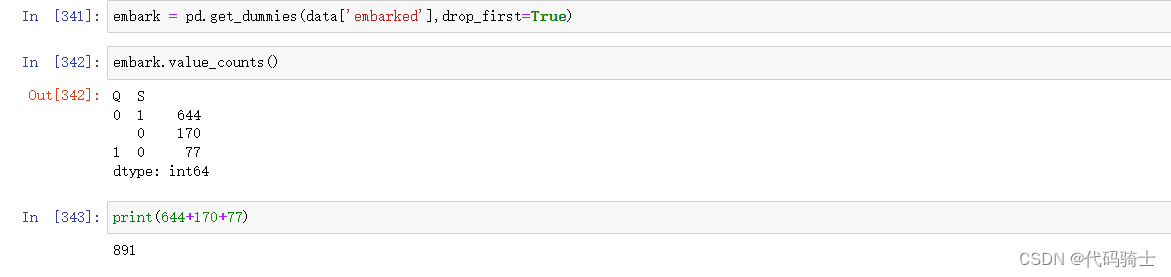
可以和之前的embark进行数据对比发现,Nan值已经被归入了C:00中。(自动补充)?
?3、处理class
class_ = embark = pd.get_dummies(data['class'],drop_first=True)
class_#00_1, 10_2, 01_3
4、处理who
data["who"].value_counts()
who = embark = pd.get_dummies(data['who'],drop_first=True)
who
5、处理alone
data["alone"].value_counts()alone = pd.get_dummies(data['alone'],drop_first=True)
alone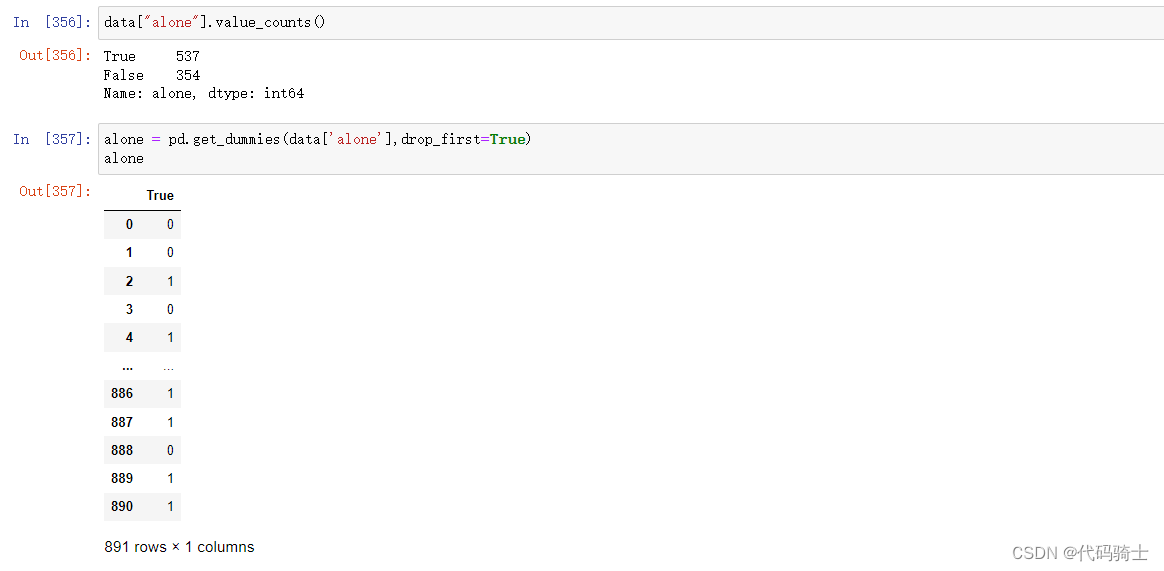
6、处理adult_male
data["adult_male"].value_counts()
因为who里面已经有值表示child的了,所以这里默认把非child的值当成adult_male,因此把此列当做冗余列删除掉。
data.drop('adult_male',axis=1,inplace=True)#inplace if False, return a copy. Otherwise, do operation
7、处理alive
data["alive"].value_counts()
因为alive和survived表达重复,故删除。
data.drop('alive',axis=1,inplace=True)
8、将转换成数字的变量拼接在data中并删除object型变量
data = pd.concat([data,sex,embark,class_,who,alone],axis=1)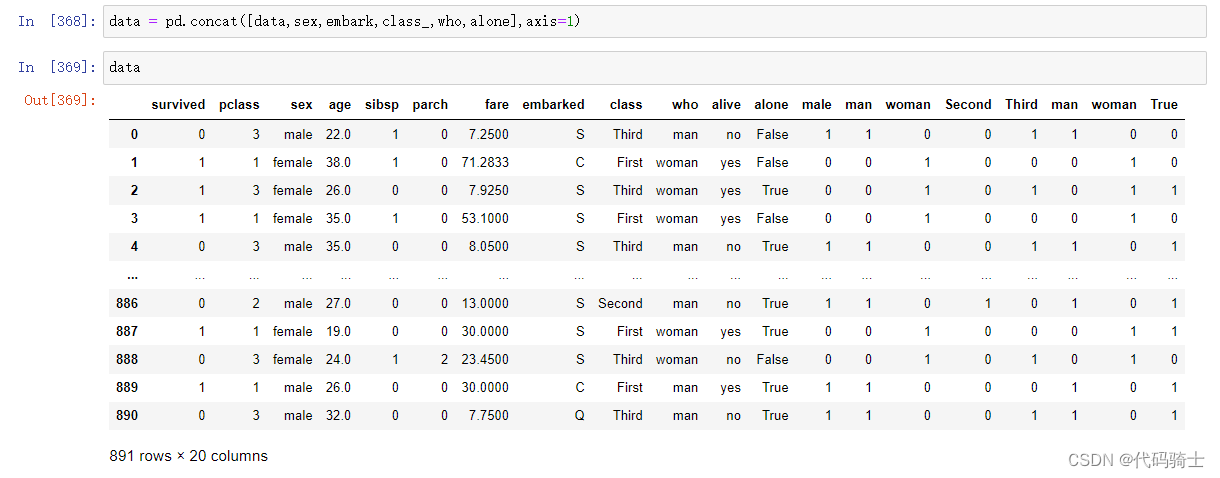
data.drop(['sex','embarked','class','who','alone'],axis=1,inplace=True)
**注:如果数据中还含有一些如手机号、身份证号码、姓名等敏感信息,则需要进行脱敏处理,如:只有不影响数据整体分析则直接可以drop。
第六步:数据建模
1、划分特征变量(自变量\独立变量)与响应变量(因变量\依赖变量)
#X--特征集:除了survived列外的其他列都作为特征
X=data.drop('survived',axis=1)
#响应列集
y=data['survived']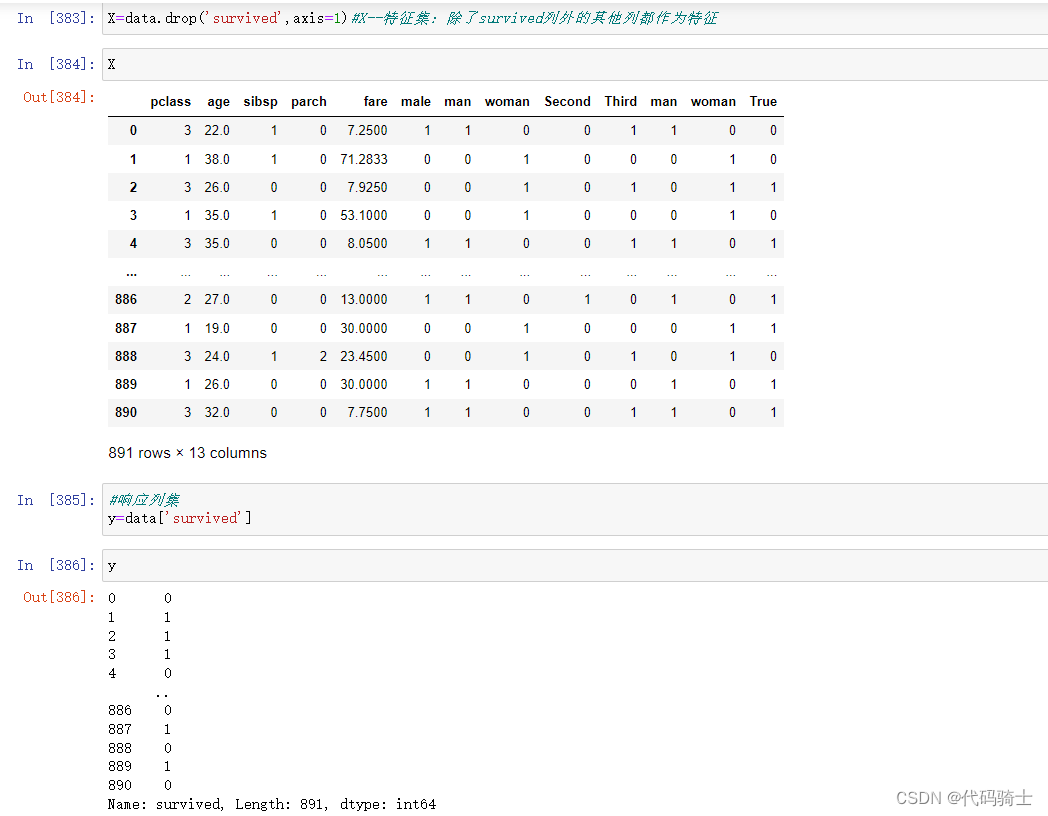
2、划分训练集与测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0)3、训练模型
from sklearn.linear_model import LogisticRegression
logitmodel = LogisticRegression()
logitmodel.fit(X_train,y_train)
#Increase the number of iterations (max_iter) or scale the data
#增加迭代次数或者缩放数据
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)

第七步:模型预测
y_predictions = logitmodel.predict(X_test)#获取预测结果#survived:pclass age sibsp parch fare male man woman Second Third man woman True
#0:3 22.0 1 0 7.2500 1 1 0 0 1 1 0 0
#1:1 38.0 1 0 71.2833 0 0 1 0 0 0 1 0
print(logitmodel.predict([[3,22.0,1,0,7.2500,1,1,0,0,1,1,0,0]]))print(logitmodel.predict([[1,38.0,1,0,71.2833,0,0,1,0,0,0,1,0]]))
第八步:模型评估
1、混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_predictions)
2、查看准确度
from sklearn.metrics import accuracy_score
accuracy=accuracy_score(y_test,y_predictions)
print(accuracy)

3、获取模型评估报告
from sklearn.metrics import classification_report
print(classification_report(y_test,y_predictions))
这个模型的评估报告包含了以下几个指标:
- 准确率(accuracy):0.81,表示模型在所有样本中正确分类的比例为81%。
- 精确率(precision):对于正例(label为1),精确率为0.76;对于负例(label为0),精确率为0.84。精确率表示模型预测为正例的样本中真正为正例的比例。
- 召回率(recall):对于正例(label为1),召回率为0.73;对于负例(label为0),召回率为0.86。召回率表示模型预测出的正例占实际正例的比例。
- F1-score:F1-score是精确率和召回率的调和平均值,用于综合评价模型的性能。对于正例(label为1),F1-score为0.74;对于负例(label为0),F1-score为0.85。
- 支持度(support):表示每个类别的样本数量,分别为168和100。
从报告中可以看出,模型的整体性能较好,准确率达到了81%。在正例和负例的分类任务中,精确率和召回率也相对较高。但是,对于负例的分类性能略优于正例。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!