我的隐私计算学习——隐私集合求交(2)
笔记内容来自多本书籍、学术资料、白皮书及ChatGPT等工具,经由自己阅读后整理而成。
前篇可见:我的隐私计算学习——隐私集合求交(1)
(三)PSI应用场景问题
?在目前的实际应用中,衍生出一些新的需求,例如除了不泄露参与计算的集合的ID和特征的基础上,要求集合的基数也不泄露; 或者是在隐私集合求交过程中,只返回交集大小,不返回具体的交集 ID; 或者是在进行集合求交的过程中,增加了集合筛选条件,只返回满足筛选条件的交集。
此外,最流行的基于不经意传输协议的隐私集合求交方案是限定对手模型是半诚实模型的前提下的安全求交协议。隐私集合求交技术作为基础应用技术,其性能仍有提升需求。目前的各种技术方案,缺少标准的对抗手段来证明其确实在实际应用中保护了数据安全。以及缺少基于隐私集合求交的各种标杆性应用。
? 由于 PSI 协议的求交结果般都首先由一方获得并同步给另一方,为了方便描述,此处我们定义首先获得求交结果的一方为结果方,另一方为数据方。恶意模型主要存在以下两个问题:
(1)大多数高效的 PSI 使用 Cuckoo Hash 作为数据结构,那么数据方的每一个元素都必须发送其 n 个对应位置(假设 Cuckoo Hash 使用 n 个 hash)的伪随机函数值给结果方,若数据方恶意少发送数据,则求交结果会缺失。
(2)求交结果一半都存在于一方(结果方),然后同步给另一方,如果此时恶意的结果方隐瞒一些结果集,那么数据方将无法获得完整求交结果。
? 在恶意模型中,协议需要使用额外的手段来防止上述攻击的可能,因此恶意模型下安全的协议的复杂程度和开销往往远大于半诚实模型下安全的协议,如何设计性能接近半诚实方案的恶意 PSI 方案仍旧是一个挑战。另外,这也引发我们的进一步思考,即恶意模型下 PSI 是否有必要,是否可以通过多方安全计算技术以外的手段来避免恶意模型的发生?例如,设置足够严厉的处罚措施,并设立不定期抽查机制来防止恶意行为的发生。
几种典型的应用场景问题如下:
-
非对称隐私集合求交
在某些实际应用场景里。一个参与方 A 的样本量远远小于另一参与方 B,这里称拥有样本量少的 A 为弱势方,称拥有样本量多的 B 为强势方,也就是出现非对称隐私集合求交的问题。
解决方案:针对上述非对称联邦学习场景,在 PSI 流程中,提出从强势方的ID集合中随机抽取部分密文 ID 数据混入最终交集中,可以得到如下效果。
(1)最终计算得到的 PSI 交集由真实交集和混淆集合组成,其中混淆集合全部来自强势方的样本 ID。
(2)弱势方可以获得 PSI 交集,同时可以通过对比本地 ID 集合和 ID 交集得到真实的样本 ID 交集,但是无法获取混淆交集部分的样本 ID( 由密文保护) ,保护了强势方的数据安全。
(3)强势方可以获得 PSI 交集,但是无法判断哪些样本属于真实 ID 交集。
(4)在实际场景中,当弱势方和强势方数据量之比在 1: 100 时,只需要取真实交集与强势方集合数据量之比为 1: 10,即可将弱势方数据的安全性提升 10 倍。
-
金融领域的斜向联邦学习
- 金融联合建模
- 金融联合统计
- 金融联合营销
— —斜向联邦学习?
— —在斜向联邦学习场景里,参与方 A 和参与方 B 各拥有一部分特征,且两个参与方分别拥有一部分由两方 PSI 获得的交集中的样本的标签信息。两方斜向联邦学习适用的场景是联邦学习的两个参与方 A 和 B 的训练数据有重叠的数据样本,两方拥有的数据特征却不同,两方数据特征空间形成互补,类似于纵向联邦学习场景。与纵向联邦学习不同的是,在两方斜向联邦学习里,参与方 A 和参与方 B 各拥有一部分 PSI 交集里的样本对应的标签信息,甚至参与方 A 和参与方 B 可能同时拥有一部分样本的标签信息。因此,从标签信息维度看,斜向联邦学习又类似于横向联邦学习。
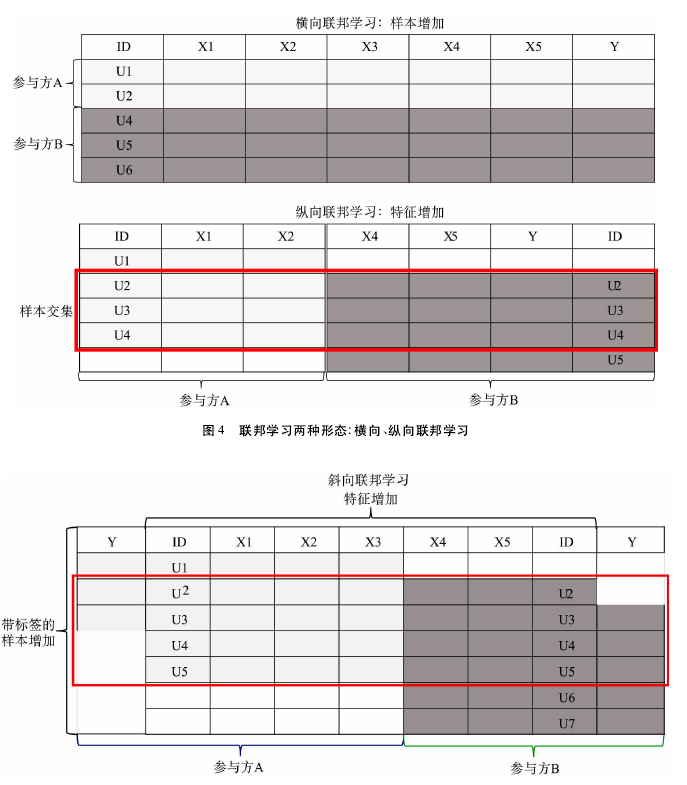
斜向联邦学习的应用场景常见于金融领域。不同的金融机构( 如银行与支付平台) 拥有的数据特征不一样,且可能各自拥有一部分样本的标签信息。
斜向联邦学习的算法协议可以从纵向联邦学习演化发展得到。例 如,在两方纵向联邦逻辑回归 ( LogisticRegression,LR ) 协议里,拥有标签信息的一方称为Guest,另外一方称为 Host。在两方斜向联邦 LR 协议里,可以请两个参与方 A 和 B 分别轮流担任 Guest 和 Host 的角色,这样就可以分别使用参与方 A 和 B 拥有的标签信息。需要注意的是,在进行小批次 ( Mini-batch) 数据划分时,每个小批次中的训练样本的标签信息必须属于同一个参与方。
-
阈值PSI
阈值 PSI 指当交集的基数大于或等于门限值时,接收方才能获得隐私集合交集.如网约顺风车,在不泄露陌生人路径的情况下如何共享双方的公共路径是该场景的重点问题。
(四)典型的PSI算法过程
? 掌握了核心思想,就可以再理解 PSI 的整个过程。以纵向联邦学习的 PSI 算法为例,纵向联邦的模式是一个主体的特征分布在两家以上的组织,那么在一起联合训练的时候,需要把一个主体的特征进行串联,这个过程包含:
- 初始化:
- Server侧的样本 ID 集合 { hc1, hc2, …,hcv },Client 侧的样本 ID 集合 { hs1, hs2, hsw }
- Server产生 RSA 加密的公钥与秘钥,秘钥保留在 Server 端,公钥(e,n)下发到 Client 端。
- Full-Domain Hash H。(小于 n,并且与 n 互质,数据量特别大的情况下要考虑空间问题)。
- Client 随机数 R。(小于 n,并且与 n 互质)
- 交互:



? 首先基于 RSA 公钥加密算法。Client 侧拥有公钥 e 和随机数,Server 侧用于私钥 d 和公钥 e,最终加密的拼接键通过私钥 d 进行加密,基于 RSA 因式分解的复杂性,client 侧通过加盲然后去盲的方式获得基于私钥 d 的加密,但是他自己没法生成。Server 侧当然可以生成,但是 Server 侧也无法解开 Client 侧发来寻求协助私钥 d 生成的加密的拼接键,因为有盲。所以除了端到端的方式中间过程没法破解。
10月份新开了一个GitHub账号,里面已放了一些密码学,隐私计算电子书资料了,之后会整理一些我做过的、或是我觉得不错的论文复现、代码项目也放上去,欢迎一起交流!Ataraxia-github
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【JAVA语言-第15话】集合框架(二)——List、ArrayList、LinkedList、Vector集合
- MacOS - 如何在 Mac 苹果电脑中打开 gif 图片
- 鸿蒙Harmony(十)动画
- 6类典型场景的无线AP选型和部署方案
- 论文阅读:Making Large Language Models A Better Foundation For Dense Retrieval
- Springboot+RocketMQ通过事务消息优雅的实现订单支付功能
- 噬菌体序列分析工具PhaVa的使用和使用方法
- 线程学习(3)-volatile关键字,wait/notify的使用
- c++语言基础17-判断集合成员
- #Prompt##提示词工程##AIGC##LLM#使用大型预训练语言模型的关键考量