注意力机制与其变体
文章目录
引言
在深度学习和人工智能领域,注意力机制已经成为一种创新且强大的工具,它模仿了人类视觉注意力的功能——专注于观察范围内最重要的部分,而忽略其他信息。这种机制在处理大量数据时特别有用,因为它允许模型动态地集中注意力,从而提高了处理效率和效果。
注意力机制的起源
注意力机制最早是在神经网络的序列到序列(Seq2Seq)模型中提出的,特别是在机器翻译任务中。在这些任务中,模型需要处理和生成长序列数据,注意力机制帮助模型更有效地编码和解码信息,尤其是在处理长距离依赖时。
自注意力和多头注意力的发展
自注意力机制是注意力的一种形式,它允许模型在处理一个序列时,将每个元素与序列中的其他元素进行比较。这种机制在Transformer模型中被广泛采用,因为它提供了一种更有效的方式来捕捉序列内的全局依赖。
多头注意力则是自注意力的扩展,它将注意力分割成多个头部,每个头部独立地关注输入数据的不同部分。这种方法提供了更复杂和灵活的方式来捕捉数据中的多种模式和特征。
1. 什么是注意力机制(Attention)
你会注意什么?
目的在于解决大数据的问题(重要的,不重要的?)
对于模型而言(CNN,LSTM),很难决定什么重要,什么不重要,由此,注意力机制诞生了
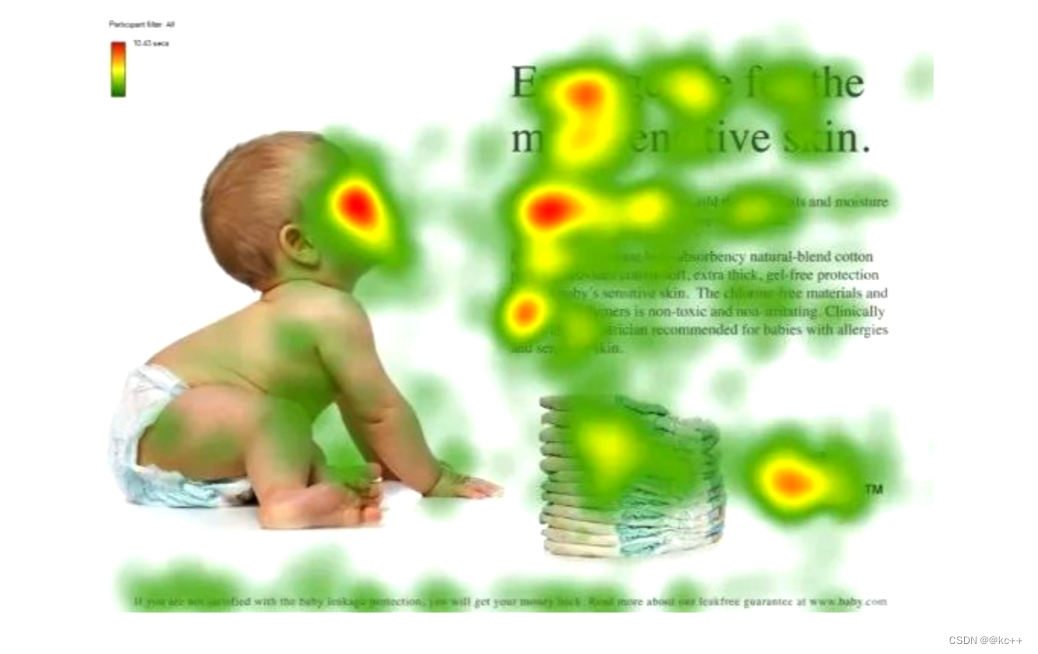
红色的是科学家们发现,如果给你一个图,你的研眼睛会聚焦在红色区域
人 --> 脸
文章 --> 标题
段落 --> 开头,落款
这些红色区域可能包含更多的信息,更重要的信息
怎么做注意力
我(查询对象Q),看这张图(被查询对象V)
我看这张图,第一眼,就会去判断哪些东西对我重要,哪些不重要(去计算Q和V里的事物的重要度)
重要度计算,其实就是计算相似度。
Q,K = k1, k2,… kn 我们一般使用点乘(求内积)方式
通过点乘的方法计算Q和K里的每一个事物的相似度,就可以拿到Q和k1的相似值a1,Q和k2的相似值a2,Q和kn的相似值an。
然后做一层softmax(a1,a2,…,an)就可以得到概率。进而找出哪个对Q而言更重要。
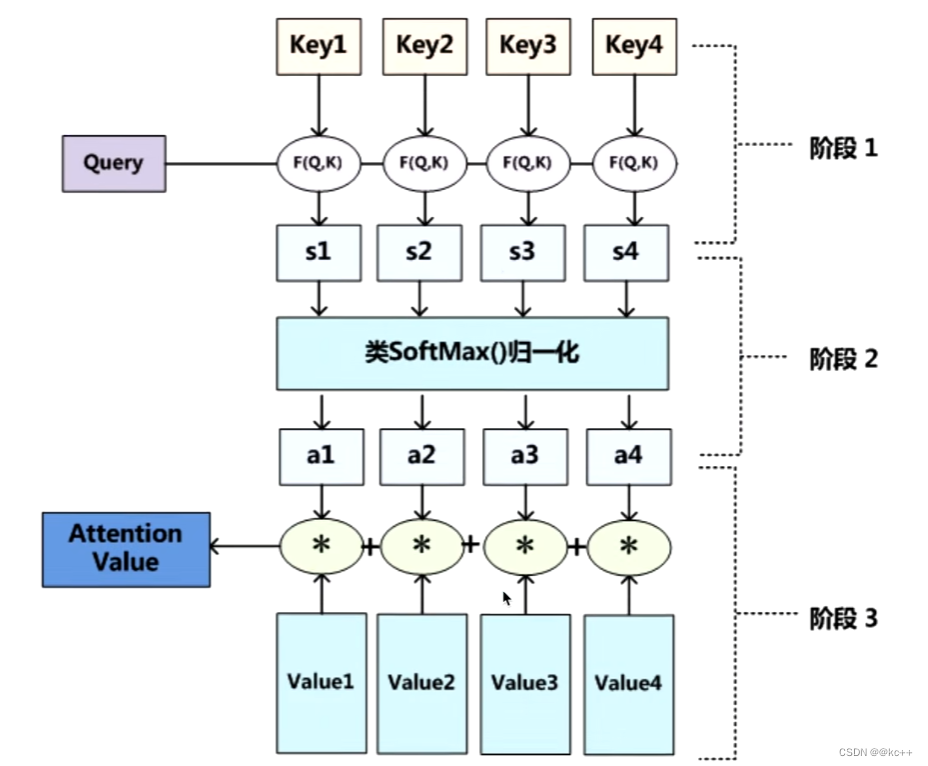
我们还得进行一个汇总,当你使用Q查询结束了后,Q已经失去了它的使用价值了,我们最终还是要拿到这张图片的,只不过现在的这张图片它多了一些信息(多了于我而言更重要,更不重要的信息)。
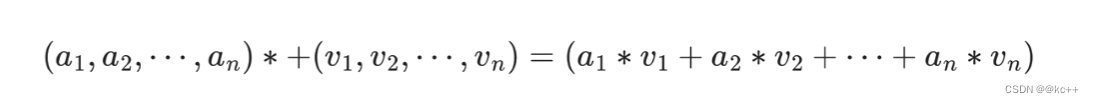
这样我们就得到了一个新的V,这个新的V就包含了,哪些更重要,哪些不重要的信息在里面,然后用新的V代替原本的V。
一般K = V,在 Transformer 里,K != V 也是可以的,但是 K 和 V 之间一定存在着某种联系,这样的 QK 点乘才能指导 V 哪些重要,哪些不重要
2. Self-Attention(自注意力机制)
第一眼看到一张图,不会把所有的信息都看完
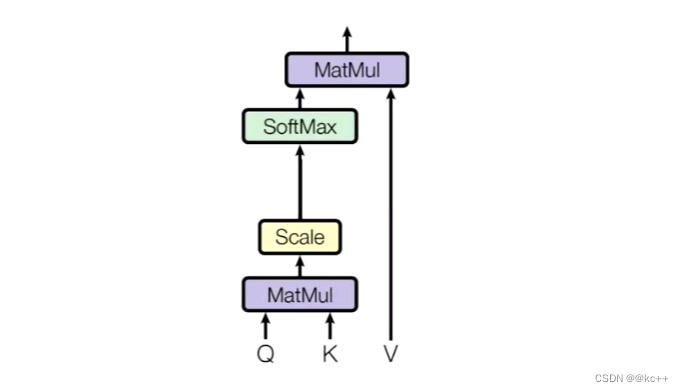
Q,K相乘求相似度,做一个scale,(未来做softmax的时候避免出现极端情况)
然后做Softmax得到概率
新的向量表示了 k 和 v (k == v) ,然后这种表示还暗含了Q的信息(于 Q 而言,K 里面最重要的信息),也就是说,挑出了 K 里面的关键点。
Self-Attention 的关键点在于,不仅仅是 K,V,Q来源于同一个 X,这三者是同源的。
通过 X 找到 X 里面的关键点
并不是 K=V=Q=X,而是通过三个参数Wq,Wk,Wv。
接下来的步骤和注意力机制一模一样
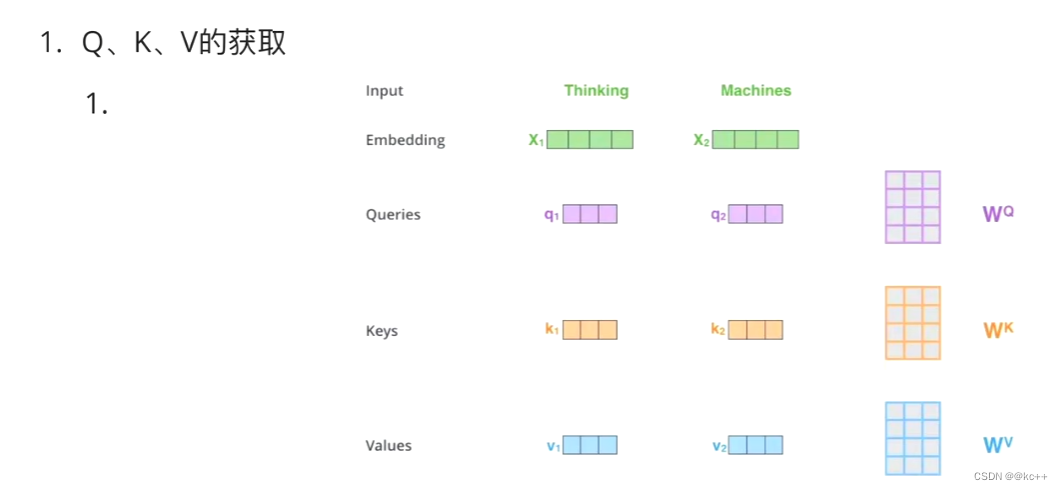
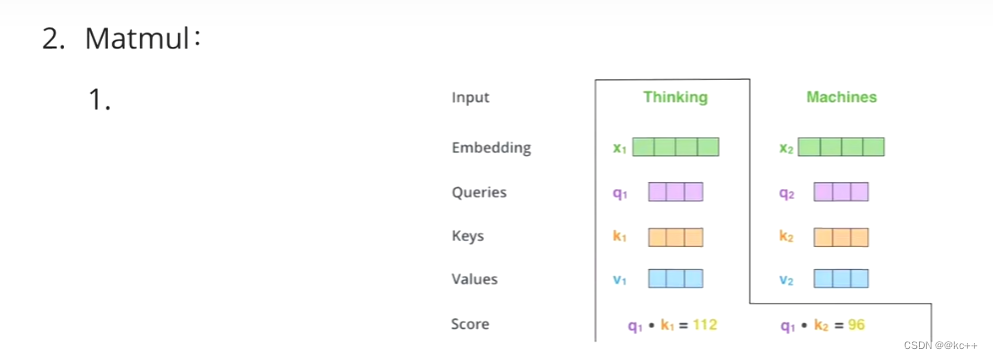
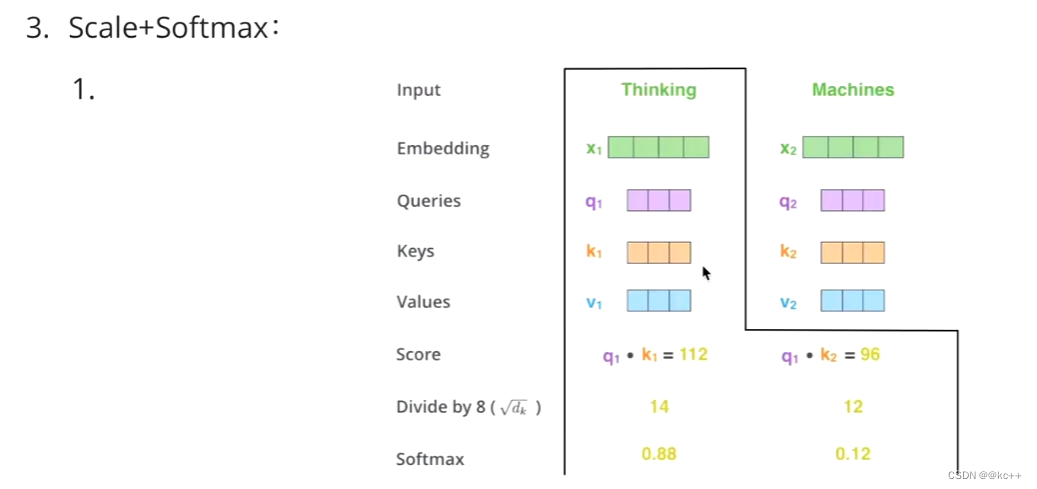
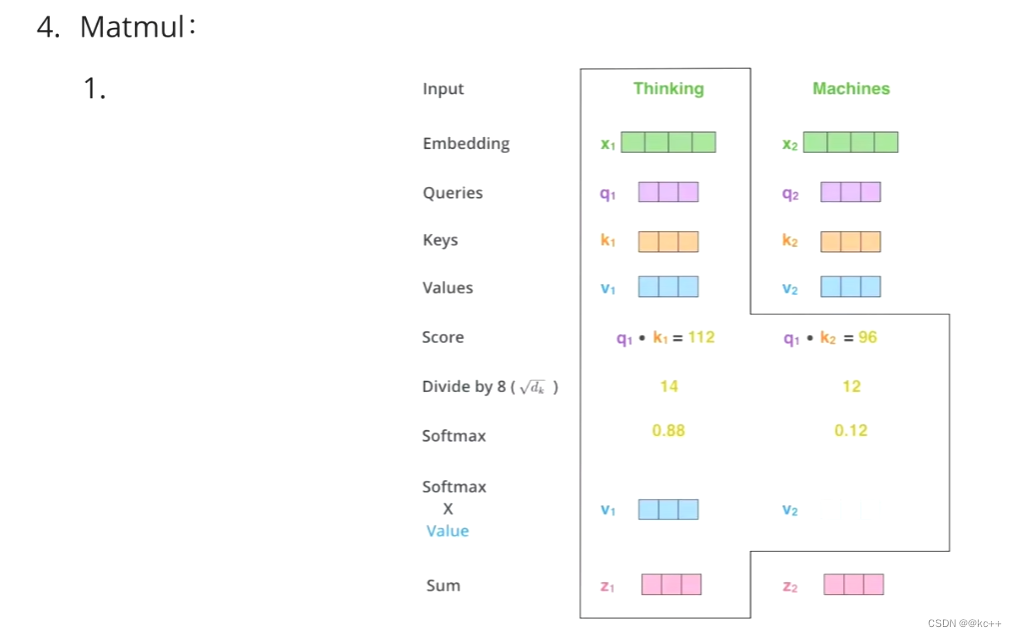
Z1表示的是 thinking 的新的向量表示
对于 thinking ,初始词向量为X1,
现在通过 thinking,machines 这句话去查询这句话里的每一个单词和 thinking 之间的相似度
新的 Z1 依然是 thinking 的词向量表示,只不过这个词向量的表示蕴含了 thinking,machines 这句话对于 thinking 而言哪个更重要的信息

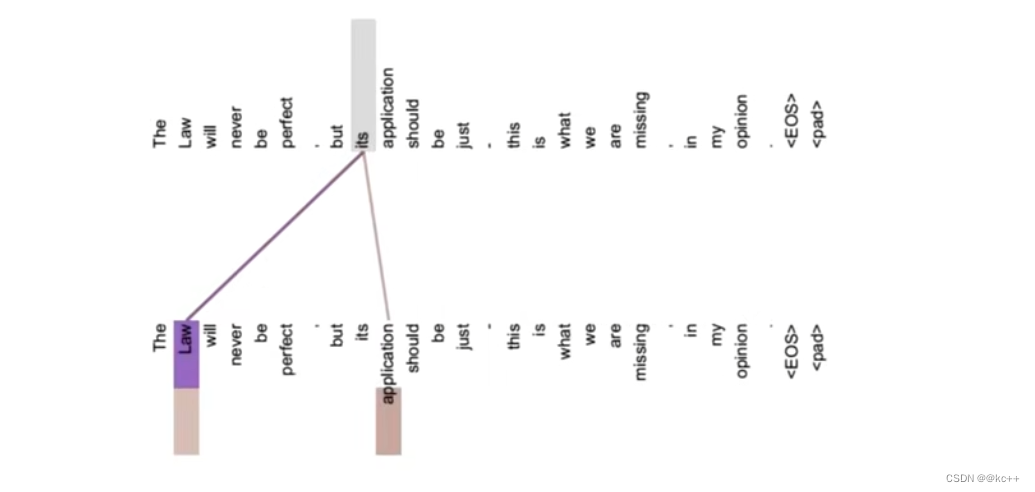
假设不做注意力,its 的词向量就是单纯的 its,没有任何附加信息
也就是说 its 有 law 这层意思,而通过自注意力机制得到新的 its 的词向量,则会包含一定的 laws 和 application 的信息。
3. Attention 和 Self-Attention 的区别
Attention(注意力机制)允许模型在处理一组输入时动态地专注于最重要的部分,通过为输入的不同部分分配不同的权重来实现这一点。而Self-Attention(自注意力),是注意力机制的一种特殊形式,它在处理序列数据时允许每个元素都与序列中的其他元素进行比较,从而捕捉内部依赖关系。这使得Self-Attention特别适用于处理像自然语言这样的数据,其中上下文关系对于理解意义至关重要。
3.1 Attention
注意力机制是一个很宽泛的概念,QKV相乘就是注意力,但是它没有规定QKV是怎么来的
注意力机制是通过一个查询变量 Q,去找到 V 里面比较重要的东西
假设 K == V,然后QK相乘求相似度 A,然后 AV 相乘得到注意力值 Z,这个 Z 就是 V 的另外一种形式的表示
Q可以是任何一个东西,V也可以是任何一个东西,K 往往是等同于 V 的(同源)
它没有规定 QKV怎么来,它只规定 QKV 怎么做
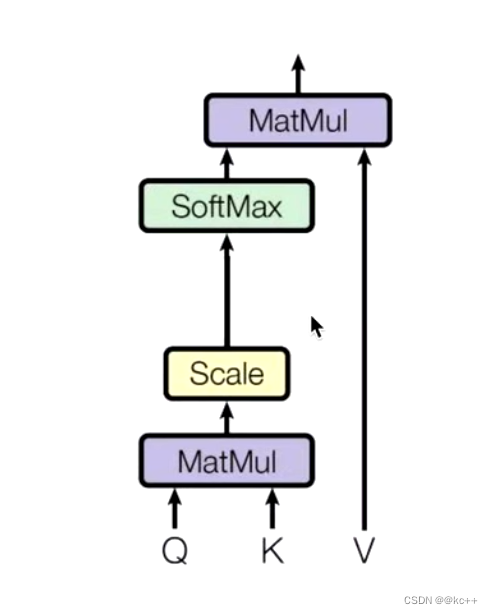
3.2 Self-Attention
自注意力机制,特别狭隘,属于注意力机制的,注意力机制包括自注意力机制
本质上 QKV 可以看做是相等的
对于一个词向量,做的是空间上的对应,乘上了参数矩阵,依然代表 X,只不过是 X 的另一种表达,或者说是空间上的一种对应。
不仅规定 QKV 同源,而且规定了 QKV 的做法
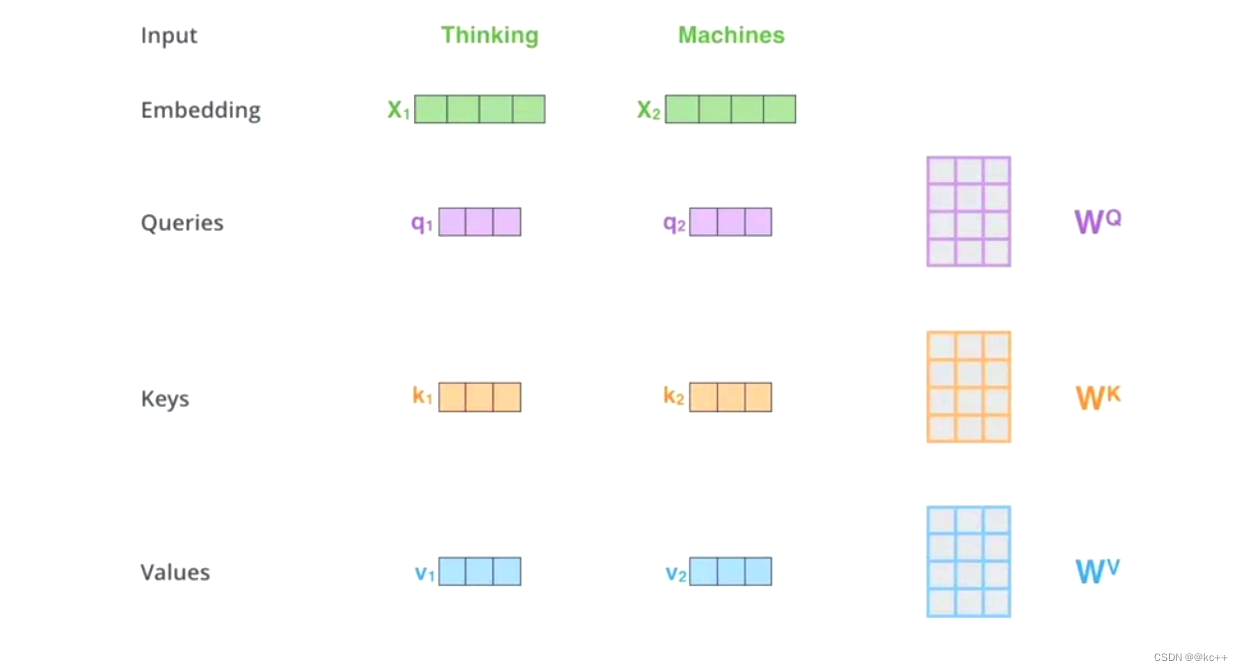
3.3 交叉注意力机制
交叉注意力机制和 Self-Attention 是同级的,都是隶属于注意力机制
Q 和 V 不同源吗,但是 K 和 V同源
4. Self-Attention 与 RNN 和 LSTM 的优缺点比较
4.1 Self-Attention 与 RNN
优点
- 并行处理:Self-Attention可以同时处理整个序列,这对于训练时间有显著的优势,因为它允许更高效的GPU利用率。
- 捕捉长距离依赖:Self-Attention能够更有效地捕捉长距离依赖,因为它直接计算序列中各元素之间的关系,而不依赖于固定的时间步。
缺点
- 计算复杂度:对于非常长的序列,Self-Attention的计算复杂度和内存需求可能会变得很高。
- 缺乏顺序感知能力:自注意力机制本身不考虑输入序列的顺序,通常需要额外的位置编码来引入顺序信息。
RNN
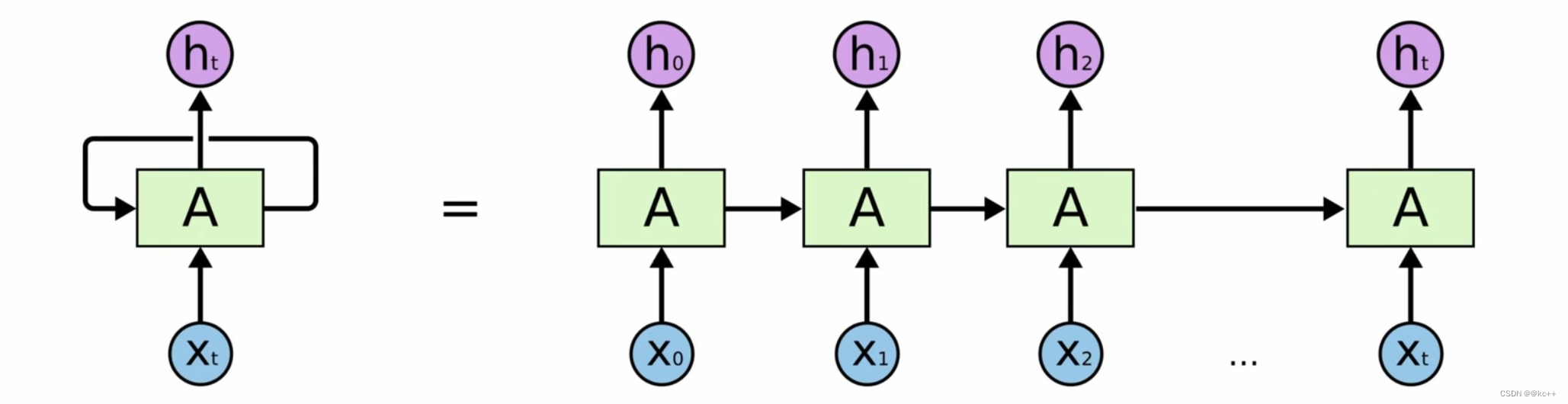
无法做长序列,当一段话达到 50 个字,效果就很差了
4.2 Self-Attention 与 LSTM
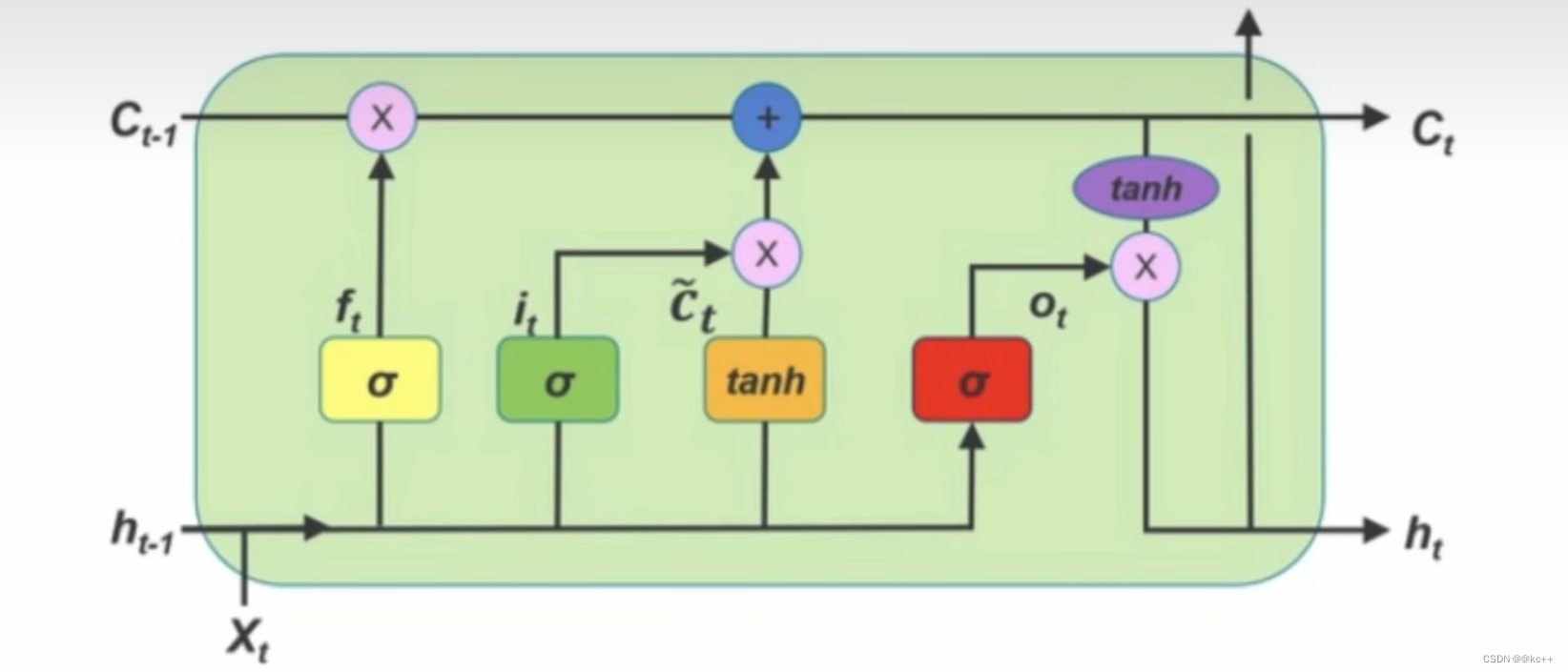
LSTM 通过各种门,遗忘门,选择性的可以记忆之前的信息
4.3 Self-Attention 与 RNNs的区别
RNNs 无法解决长序列依赖问题,无法做并行
Self-Attention 得到的新的词向量具有句法特征和语义特征(表征更完善)
句法特征
Self-Attention 会对句子中的每一个词都和句子中的其他每一个词做一个相似度计算
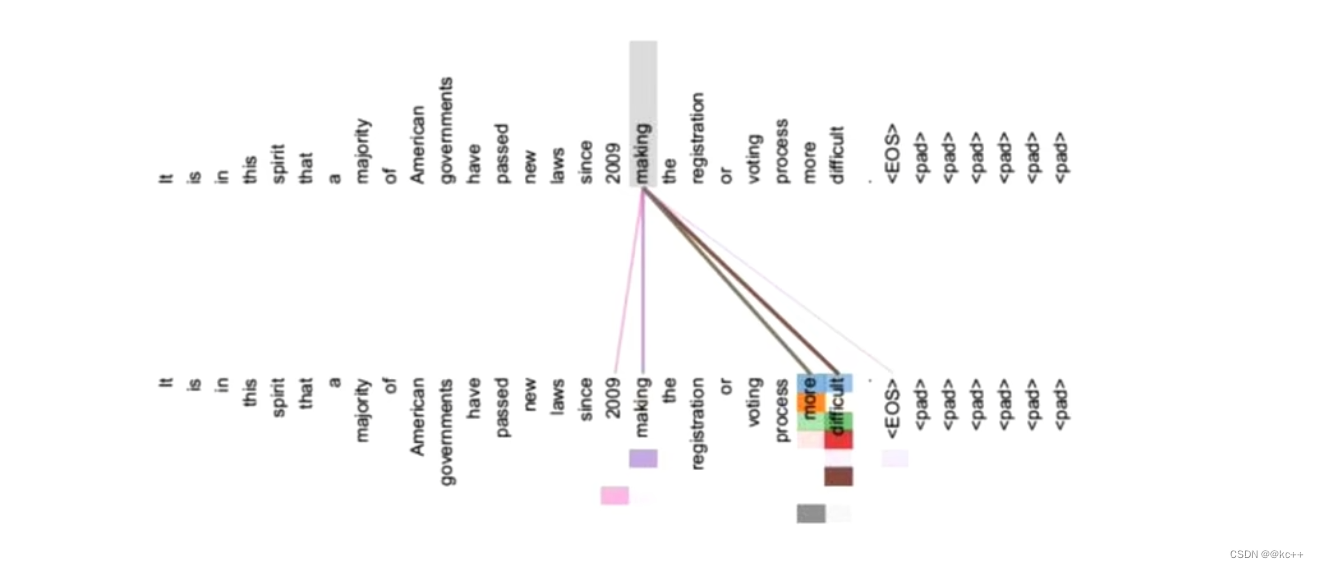
语义特征
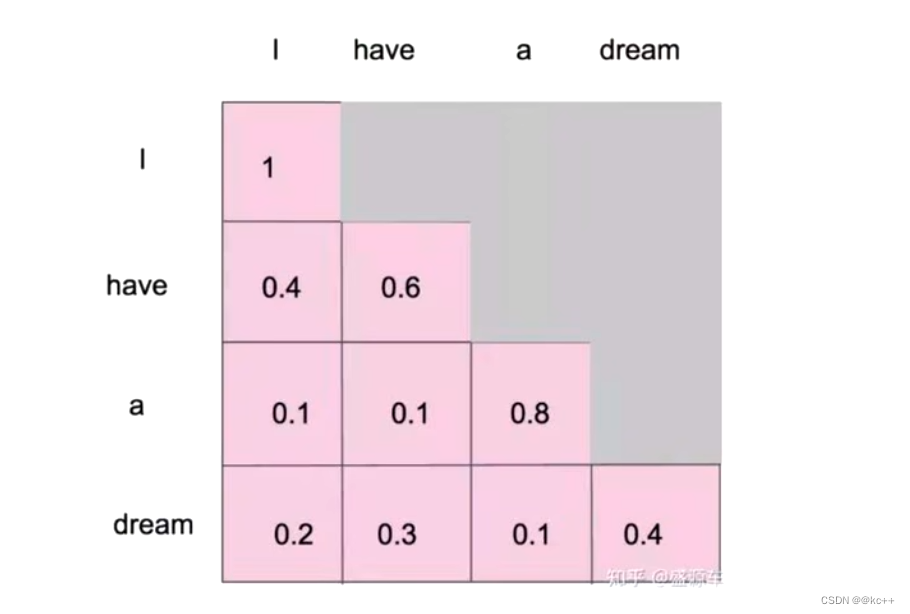
5. Maksed Self-Attention(掩码自注意力机制)
Attention
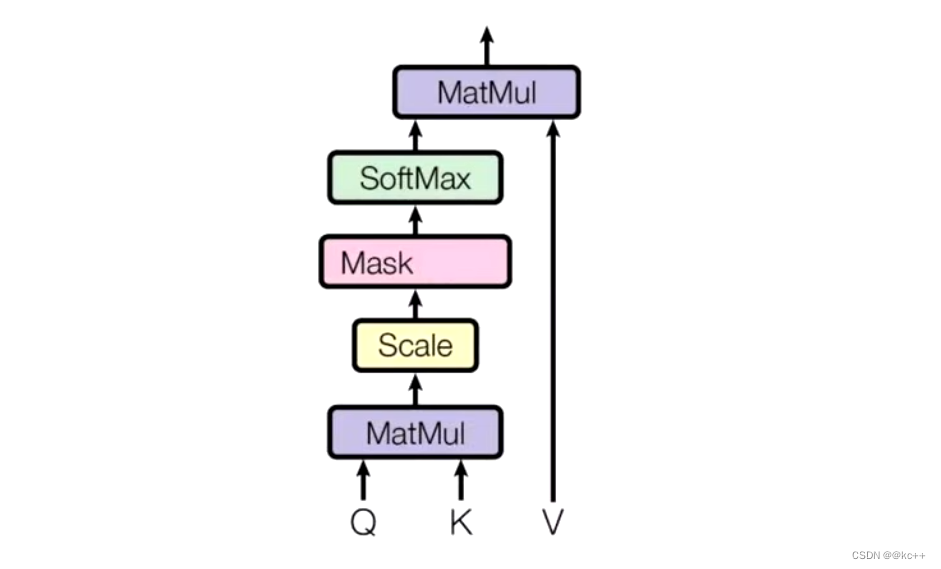
Self-Attention

当我们做生成任务的时候,我们也想对生成的这个单词做注意力计算,但是。生成的句子是一个一个单词生成的。但生成前面的单词的时候,是看不见后面将要生成的单词的,但是自注意力机制相当于一次性就看到了整个已经生成的句子了,相当于提前看到了答案,这显然是不合理的。所以,Maksed Self-Attention应运而生
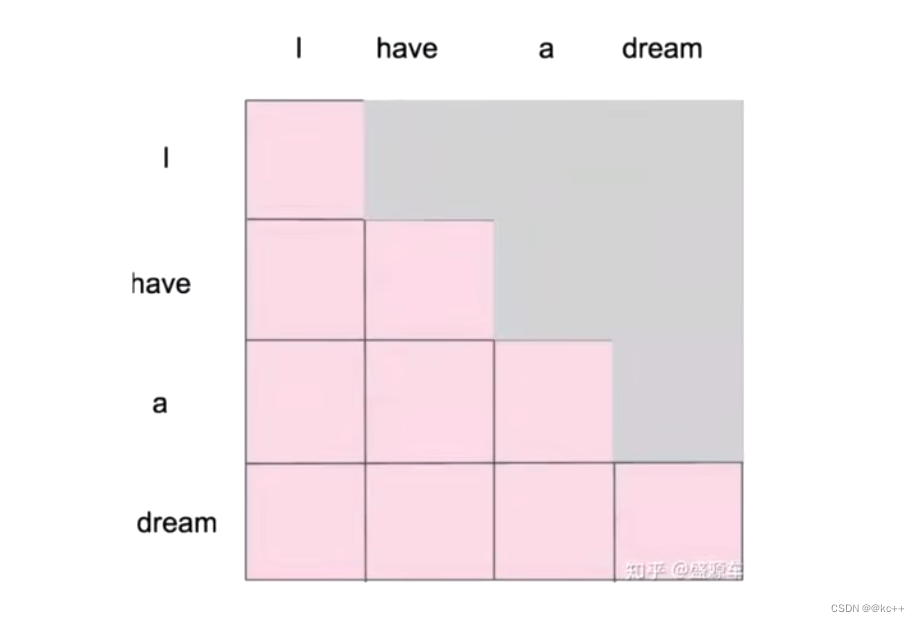
5. Multi-Head Self-Attention
Z 相比较 X 有了提升,通过Multi-Head Self-Attention ,得到的 Z* 相比较 Z 又有了进一步的提升
那么多头是什么?
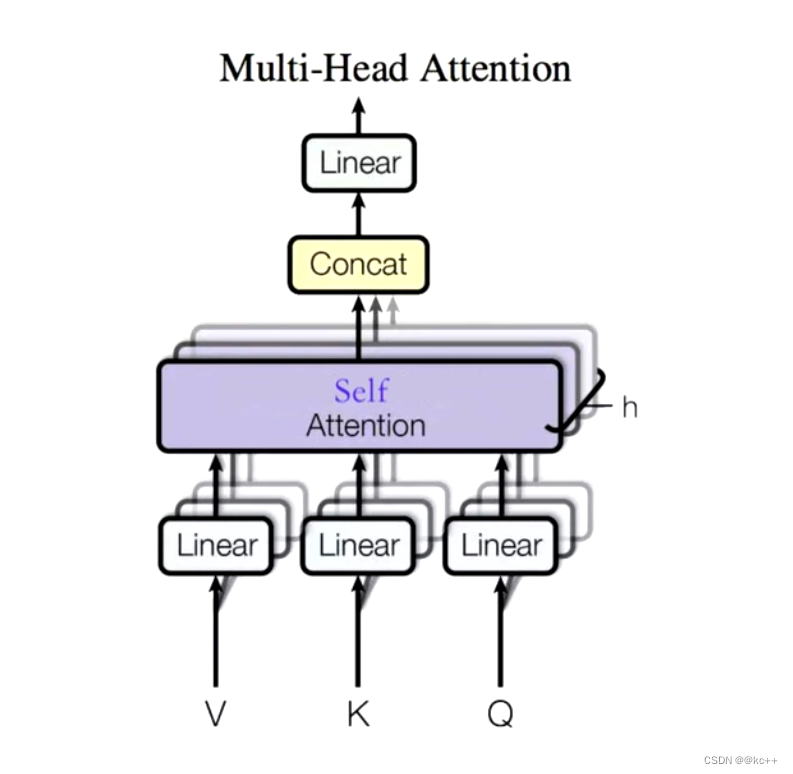
多头的个数一般用 h 表示,一般 h = 8,我们通常使用的是 8 头自注意力
如何多头 1
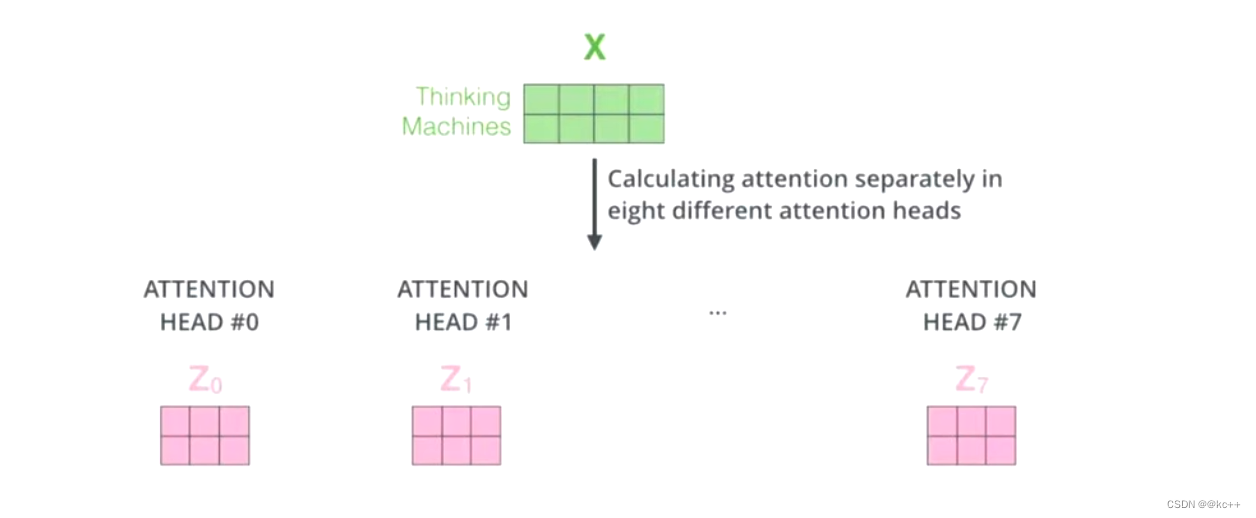
对于 X,我们不是说,直接拿 X 去得到 Z,而是把 X 分成了 8 块(8头),得到 Z0 - Z7
如何多头2
然后把 Z0 - Z7 拼接起来,再做一次线性变换(改变维度)得到 Z

有什么作用
机器学习的本质是什么:y = f(wx+b),实际上就是在做非线性变换,通过训练模型,让不合理的东西变得合理
非线性变换的本质又是什么,改变空间上的位置坐标,任何一个点都可以在维度空间上找到,通过变换,让一个位置不合理的点,变得合理
这就是词向量的本质
同理想象
Multi-Head Self-Attention使得原先在一个位置上的 X,去了空间上 8 个位置,通过对 8 个点进行寻找,找到更合适的位置
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【第一期】操作系统期末大揭秘:知识回顾与重点整理
- Ubuntu下Lighttpd服务器安装,并支持PHP
- C++ //练习 1.11 编写程序,提示用户输入两个整数,打印出这两个整数所指定的范围内的所有整数。
- 14个网页设计案例灵感网站,移动端/pc端网页设计应有尽有!
- 不同业务模式的跨境电商如何借助云桥通SDWAN组网做Tiktok生意?
- 力扣 | 11. 盛最多水的容器
- DevOps系列文章 : 使用dpkg命令打deb包
- 分享72个NodeJs项目源码总有一个是你想要的
- 通义千问Qwen模型运行异常解决记录:FlashAttention only supports Ampere GPUs or newer
- c#怎么访问 devexpress.xtrabars.barbuttonitem