Debezium系列之:Debezium JDBC 连接器支持批量同步数据
Debezium系列之:Debezium JDBC 连接器支持批量同步数据
一、设置批次
由于我们之前的版本主要关注核心功能,因此我们的最新版本致力于解决与连接器相关的主要痛点:性能。
- 目标是提高每秒处理的事件数 (EPS) 的吞吐量。为了实现这一目标,我们重新访问了连接器以支持批量事件的处理。
- 您现在可以使用新属性来微调批次的大小:batch.size。
- batch.size 属性定义尝试批处理到目标表中的记录数。然而,值得注意的是,处理记录的实际大小取决于 Kafka Connect 工作线程的 Consumer.max.poll.records 属性。
- 需要注意的是,如果您将 Connect Worker 属性中的 Consumer.max.poll.records 设置为低于batch.size的值,则批处理将受到consumer.max.poll.records和预期batch.size的限制。可能无法实现。
二、配置消费者最大轮询记录
- 如果您不想在 Connect 工作线程上全局配置consumer.max.poll.records 属性,则可以选择使用consumer.override.max.poll.records 为特定连接器设置底层消费者的max.poll.records连接器配置。
- 要启用每个连接器的配置属性并覆盖默认工作线程属性,请将以下参数添加到工作线程属性文件中:connector.client.config.override.policy。
- 此属性定义连接器可以覆盖哪些配置。默认实现是“All”,但其他可能的策略包括“None”和“Principal”。
- 当 Connector.client.config.override.policy=All 时,属于工作线程的每个连接器都可以覆盖工作线程配置。您现在可以使用以下覆盖前缀进行接收器连接器配置:consumer.override.。
- 值得注意的是,即使您设置了 max.poll.records(默认值为 500),您收到的记录也可能会更少。这是由于其他属性可能会影响从主题/分区获取记录。
| 参数 | 默认值 |
|---|---|
| fetch.max.bytes | 52428800 (52MB) |
| max.partition.fetch.bytes | 1048576 (1MB) |
| message.max.bytes | 1048588 (1MB) |
| max.message.bytes | 1048588 (1MB) |
因此,根据您预期的有效负载大小调整这些,以达到所需的轮询记录数。
三、性能测试结果
性能测试的目的是了解批量支持如何改进 EPS。因此,这些数字并不反映任何实际场景,而是展示了与旧 JDBC 版本相比的相对改进。
用于测试的配置
所有测试均在 ThinkPad T14s Gen 2i 上执行
CPU:Intel? Core? i7-1185G7 @ 3.00GHz(8 核)
内存:32GB
磁盘:512G??B NVMe
Docker 容器内的所有必需组件(Kafka、Connect、Zookeeper 等)。
用于测试的表具有以下结构:
CREATE TABLE `aviation` (
`id` int NOT NULL,
`aircraft` longtext,
`airline` longtext,
`passengers` int DEFAULT NULL,
`airport` longtext,
`flight` longtext,
`metar` longtext,
`flight_distance` double DEFAULT NULL
)
测试计划
我们计划执行这些测试:
- 来自单个表的 100K 事件
- MySQL 批处理与无批处理
- 来自三个不同表的 100K 事件
- MySQL 批处理与无批处理
- 来自单个表的 100 万个事件
- MySQL 批处理,批处理大小:500、1000、5000、10000 与无批处理
- MySQL 批处理,批量大小:500、1000、5000、10000(使用 JSONConverter)
- MySQL 批处理,批处理大小:500、1000、5000、10000(使用 Avro)
- MySQL 批处理,批处理大小:500、1000、5000、10000,使用 Avro,目标表上没有索引
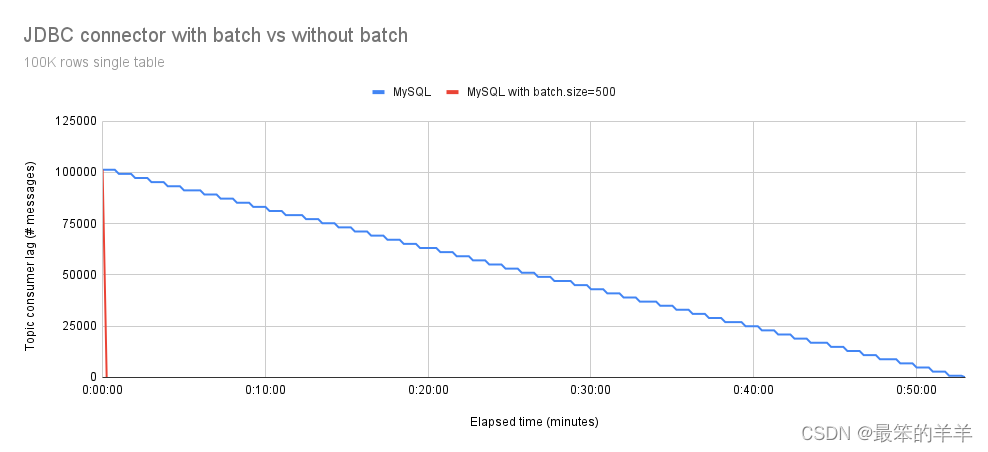
图 1 说明了处理单个表中 100,000 个事件所需的总执行时间,比较了具有和不具有批处理支持的 MySQL 连接器。
尽管batch.size和consumer.max.poll.records的默认值都设置为500,但由于有效负载大小的考虑,观察到的实际大小被减少到337条记录。
正如预期的那样,我们可以观察到具有批量支持的 Debezium JDBC 连接器速度更快。
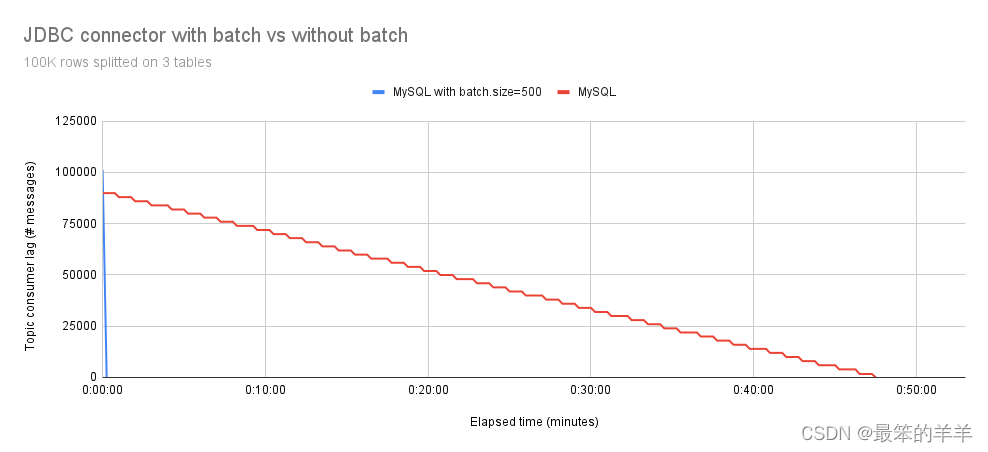
在图 2 中,我们观察到将 100,000 个事件拆分到三个表中不会影响结果。与非批处理版本相比,具有批处理支持的 Debezium JDBC 连接器仍然更快。
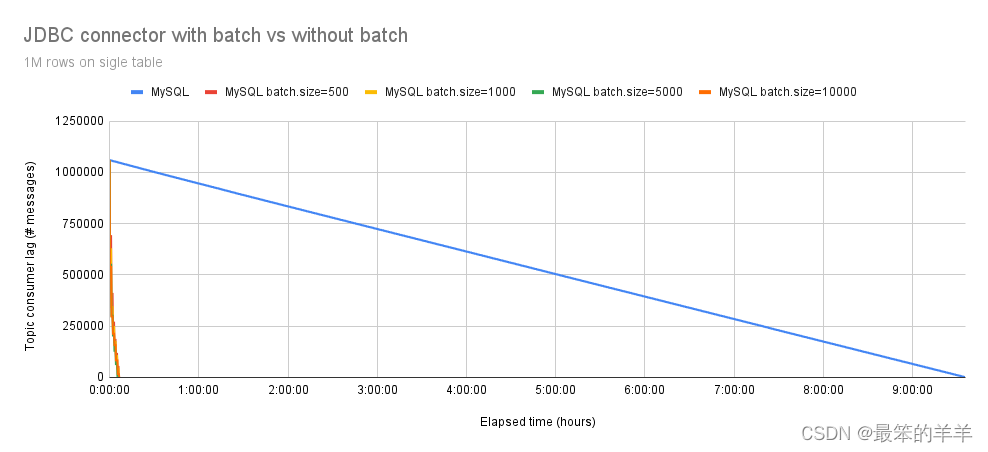
在图 3 中,很明显,当事件数达到 1,000,000 时,性能提升变得更加明显。具有批量支持的 Debezium JDBC 连接器大约需要 7 分钟才能插入所有事件,平均吞吐量为 2300 eps,而没有批量支持的过程需要 570 分钟(9.5 小时)。因此,具有批量支持的 Debezium JDBC 连接器比不具有批量支持的版本快 79 倍。
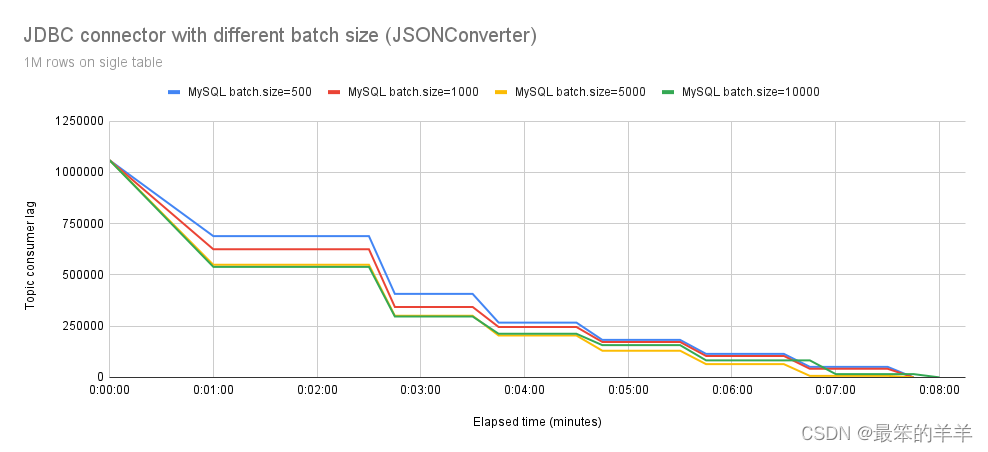
在图 4 中,我们观察 Debezium JDBC 连接器使用 org.apache.kafka.connect.json.JsonConverter 转换器并使用不同的 batch.size 设置写入 MySQL 的行为。虽然最初的差异很明显,但吞吐量明显持续下降。平均而言,所有batch.size配置大约需要7分钟来处理所有事件。
这引起了我们的担忧。在进行彻底的分析(分析)后,我们发现了另一个问题:事件反序列化。这很有可能是导致batch.size设置不可扩展的原因。
尽管序列化提高了可扩展性,但我们仍然缺乏关于测试运行期间 EPS 减速的答案。一个假设可能涉及某处某种类型的缓冲区。
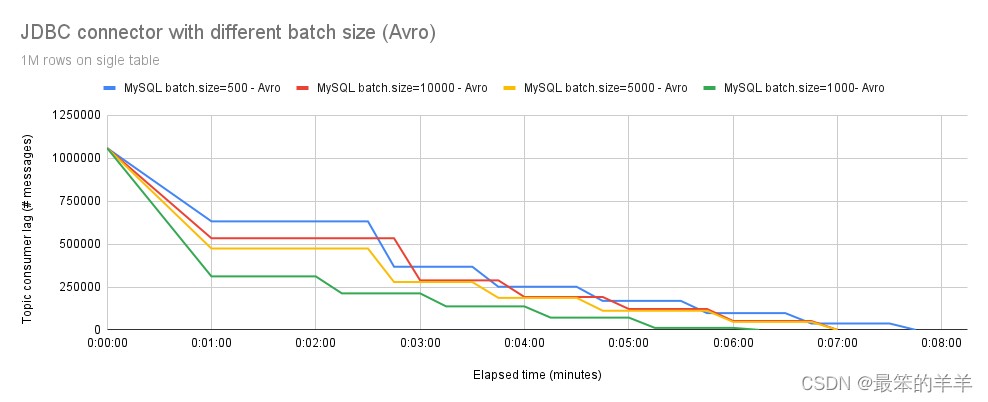
然后我们使用 Avro 进行了实验,如图 5 所示,结果显示了显着的改进。正如预期的那样,使用batch.size = 500处理1,000,000个事件比使用batch.size = 10000慢。值得注意的是,在我们的测试配置中,batch.size 的最佳值为 1000,从而实现最快的处理时间。
虽然结果比 JSON 更好,但仍然存在一些性能下降。
为了识别代码中的潜在瓶颈,我们添加了一些指标,发现大部分时间都花在了在数据库上执行批处理语句。
进一步的调查显示,我们的表在主键上定义了一个索引,这会减慢插入速度。
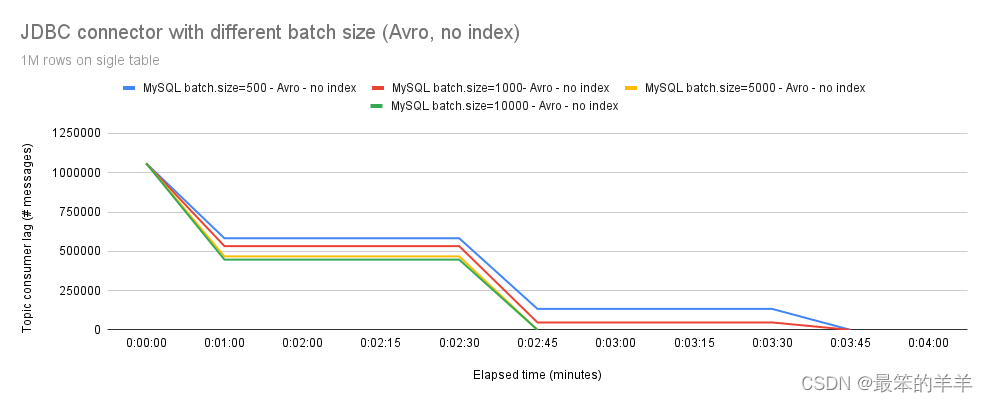
在图 6 中,您可以看到使用 Avro 且没有主键索引时性能的提高。较高的batch.size 值也可以明显提高性能。
四、结论
我们探索了调整batch.size如何增强Debezium JDBC连接器的性能,并讨论了最大化其优势的正确配置。同样重要的是遵守针对特定数据库量身定制的高效插入的性能提示和一般准则。
这里有一些例子:
- MySQL - 优化 INSERT 语句
- MySQL - 性能扩展
- PostgreSQL - 填充数据库
虽然某些设置可能特定于某些数据库,但一些通用原则适用于大多数数据库。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!