C++_string类
目录
前言:
????????C++中的string类是专门用于处理字符串的,比如对字符串的增删查改、以及对字串进行各种操作,当然,上面说到的这些在c语言中一样可以使用字符数组实现,那为什么还要费尽心思的去专门实现一个类来解决字符串相关的问题呢,原因就是C++中的string类对边界访问更严格,并且用string类操作字符串相对于c语言中操作字符数组更加简便。
一、string的模拟实现
? ? ? ? string类是STL(标准模板库)中的八大容器之一,STL又是C++中标准库的一部分,简单来说就是库里面已经写好了一个string类,程序员只需要调用该string类就能操作字符串(使用库里的string类要包含头文件<string>),调用该类很简单,但是只有通过了解string类的底层实现是如何实现,并且自己模拟实现出一个string,才能更进一步的了解string类。
1、初始化字符串
? ? ? ? 首先写一个类,可以实现字符串的创建和打印,初始化字符串代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
size_t size()const//私有域不可直接被外部访问,因此需要用函数返回_size
{
return _size;
}
char& operator[](size_t i)//为了让外部能用[]访问字符串的内容
{
assert(i < _size);
return _str[i];
}
const char* c_str()//返回首元素地址(类似数组名的作用)
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1("hello world");
ZH::string st2;
for (size_t i = 0; i < st1.size(); i++)
{
cout << st1[i] << " ";
}
cout << endl;
for (size_t i = 0; i < st2.size(); i++)
{
cout << st2[i] << " ";
}
cout << endl;
cout << st1.c_str() << endl;//用c语言的打印字符串方式,传首地址打印
cout << st2.c_str() << endl;
return 0;
}? ? ? ? 运行结果:

? ? ? ? string类的成员变量具体含义作用如下图所示:

2、拷贝构造
? ? ? ? 我们知道拷贝构造如果不自己实现,那么系统会自动生成一个拷贝构造并且调用,但是系统自动生成的拷贝构造只能完成浅拷贝(即值拷贝)的场景,比如string类的拷贝就不能用浅拷贝完成,具体原因如下:
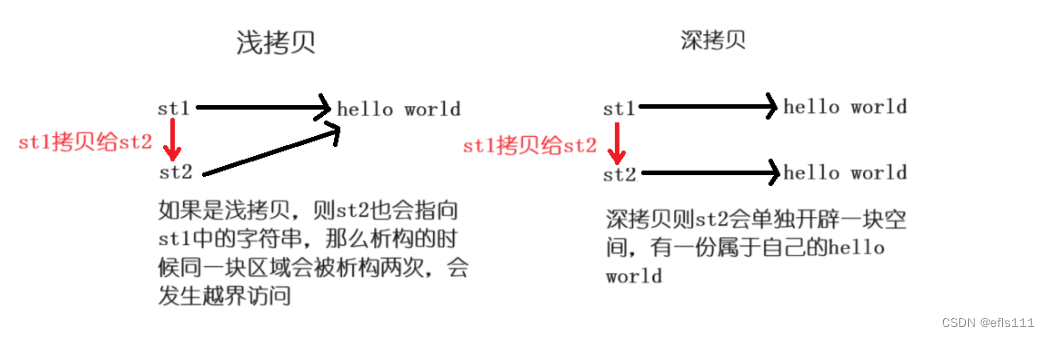
? ? ? ? 因此系统自己生成的浅拷贝不能完成这类场景的拷贝,需要我们手动写一个拷贝构造函数完成深拷贝。
? ? ? ? 演示拷贝构造代码如下(将拷贝构造代码放到上文的代码中也同样可以实现,这里省去了与拷贝构造代码无关的代码):
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
const char* c_str()//返回首元素地址(类似数组名的作用)
{
return _str;
}
string(const string& s)//深拷贝-拷贝构造
:_size(s._size)
, _capacity(s._capacity)
{
_str = new char[_capacity + 1];//开辟一块独立的空间
strcpy(_str, s._str);
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1("hello world");
ZH::string st2(st1);//将st1的内容拷贝给st2
cout << st1.c_str() << endl;//用c语言的打印字符串方式,传首地址打印
cout << st2.c_str() << endl;
return 0;
}? ? ? ? ?运行结果:

3、赋值重载?
? ? ? ? 赋值的时候要考虑以下几个问题:

? ? ? ? 由于以上几个问题涉及的点太多,而且过程过于复杂或造成不必要的消耗,因此库里面的string类在面对赋值时是重新开辟一块空间然后把s1的数据拷贝到该空间中,并且让s2指向该空间即可。
? ? ? ? 模拟实现的赋值重载代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
const char* c_str()//返回首元素地址(类似数组名的作用)
{
return _str;
}
string& operator=(const string& s)//赋值重载
{
if (&s != this)
{
char* temp = new char[s._capacity+1];//重新开辟一块空间
strcpy(temp, s._str);//把数据拷贝到该空间中
delete[] _str;//释放拷贝对象的原先空间内容
_str = temp;//让拷贝对象指向该空间
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1("hello world");
ZH::string st2("zdzdzzdzd");
st2 = st1;
cout << st1.c_str() << endl;//用c语言的打印字符串方式,传首地址打印
cout << st2.c_str() << endl;
return 0;
}? ? ? ? 运行结果:

4、迭代器
? ? ? ? 在string类中,他的迭代器可以理解成是由一个指针实现的,不仅可以遍历打印字符串,还能够修改字符串中的内容,因此string类中迭代器的实现很简单,只需要一个指向首元素的指针,和一个指向尾部的指针(注意:尾部表示最后一个元素的下一个位置,因为迭代器区间是一个左闭右开的区间)即可。

? ? ? ? 迭代器模拟实现代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
//用typedef来模拟迭代器的两种类型
typedef char* iterator;
typedef const char* const_iterator;
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
iterator begin()//返回首地址
{
return _str;
}
iterator end()//返回末尾地址
{
return _str + _size;
}
const_iterator end()const//const版本迭代器
{
return _str + _size;
}
const_iterator begin()const//const版本迭代器
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1("hello world");
ZH::string st2("hello world");
ZH::string::iterator it = st1.begin();
while (it!=st1.end())
{
(*it)++;
cout << *it << " ";
it++;
}
cout << endl;
ZH::string::const_iterator cit = st2.begin();
while (cit != st2.end())
{
//(*cit)++;//被const修饰的迭代器是不能通过该迭代器修改对象里面的内容
cout << *cit << " ";
cit++;
}
cout << endl;
return 0;
}? ? ? ? 运行结果:

? ? ? ? 总结:迭代器的模拟实现实际上就是begin()和end()两个成员函数的返回指针构成的。?
5、比较字符串
? ? ? ? 在字符数组中,只能通过strcmp函数对比两个字符串的大小(按照元素的ASCII码值进行比较),每次对比都需要调用strcmp,写起来也麻烦。然而在string类中可以使用比较运算符进行字符串的对比,比如:‘<','>','<=','>=','==','!=',这些平时用于内置类型的比较运算符如今也可以用在string类(自定义类型)中,原因就是类里面实现了运算符重载。
? ? ? ? 当对象支持了运算符重载,则对象与对象之间的对比写起来就更加简单了,模拟实现string运算符重载代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
//用typedef来模拟迭代器的两种类型
typedef char* iterator;
typedef const char* const_iterator;
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
bool operator>(const string& s)const
{
return strcmp(this->_str, s._str) > 0;
}
bool operator<(const string& s)const
{
return strcmp(this->_str, s._str) < 0;
}
bool operator==(const string& s)const
{
return strcmp(this->_str, s._str) == 0;
}
bool operator>=(const string& s)const
{
return !(*this < s);
}
bool operator<=(const string& s)const
{
return !(*this > s);
}
bool operator!=(const string& s)const
{
return !(*this == s);
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1("jello world");
ZH::string st2("hello world");
cout << (st1 > st2) << endl;//1
cout << (st1 < st2) << endl;//0
cout << (st1 == st2) << endl;//0
cout << (st1 != st2) << endl;//1
cout << (st1 <= st2) << endl;//0
cout << (st1 >= st2) << endl;//1
return 0;
}? ? ? ? 运行结果:

? ? ? ? 可以以上代码可以看到,实际上还是复用了strcmp这个函数,只不过对其进行了又一层的封装,这么做的目的就是为了在主函数中可以直接用‘<','>','<=','>=','==','!='进行对象之间的直接运算,总结就是:底层变得复杂,使用变得简单。
6、尾插字符、字符串
? ? ? ? 尾插数据时,需要考虑容量是否足够,实现尾插字符串时可以使用函数strcpy进行复用。尾插字符时就如同在数组插入新元素一样。
? ? ? ? 扩容函数为reserve,他的作用是单纯的开空间,增大容量,不会对空间内的数据进行修改,即只会改变_capacity的值,不会改变_size的值。(注意扩容的时候也要为’\0'单独开一块空间,但是不会把该空间记录到_capacity中)
? ? ? ? 尾插代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
void reserve(size_t n)//扩容函数
{
if (n > _capacity)//只有n大于_capacity才需要扩容
{
char* temp = new char[n + 1];
if (_str != nullptr)
{
strcpy(temp, _str);
delete[] _str;
}
_str = temp;
_capacity = n;
}
}
void push_back(char ch)//尾插字符
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size++] = ch;
_str[_size] = '\0';
}
void append(const char* str)//尾插字符串
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
const char* c_str()
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1;
st1.push_back('h');
st1.push_back('e');
st1.push_back('l');
st1.push_back('l');
st1.push_back('o');
st1.append(" world");
cout << st1.c_str() << endl;
return 0;
}? ? ? ? 运行结果:

????????如果每次尾插数据时还需要调用成员函数,则就体现不出string类的优势了,因此尾插数据的方式还能再进一步的优化,可以把尾插写成运算符重载,用'+='来实现尾插功能。
? ? ? ? 优化尾插功能代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
void reserve(size_t n)//扩容函数
{
if (n > _capacity)//只有n大于_capacity才需要扩容
{
char* temp = new char[n + 1];
if (_str != nullptr)
{
strcpy(temp, _str);
delete[] _str;
}
_str = temp;
_capacity = n;
}
}
void push_back(char ch)//尾插字符
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size++] = ch;
_str[_size] = '\0';
}
void append(const char* str)//尾插字符串
{
size_t len = strlen(str);
if (_size+len > _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
strcpy(_str + _size, str);
_size += len;
}
//两个运算符重载构成函数重载
string& operator+=(char ch)//尾插字符--运算符重载
{
push_back(ch);//复用尾插函数
return *this;
}
string& operator+=(const char* str)//尾插字符串--运算符重载
{
append(str);//复用尾插函数
return *this;
}
const char* c_str()
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1;
st1 += 'h';
st1 += 'e';
st1 += 'l';
st1 += 'l';
st1 += 'o';
st1 += " world";
cout << st1.c_str() << endl;
return 0;
}? ? ? ? ?运行结果:

7、resize
void resize(int n,char ch='\0')
//n表示期望字符串的长度,如果n>_capacity则会扩容
//当n大于_size时,后面n-_size个空间赋予ch值
//n小于_size则表示字符串长度从_size缩小了n,但是空间不会缩容????????resize的作用是控制字符串的长度,可能会改变_size也可能会改变_capacity,注意的是:resize会增大空间但是不会缩小空间,原因就是缩小空间的代价太大,需要重新开辟一块空间然后拷贝数据,因此reszie缩小字符串长度时不会减小该字符串所在的空间。具体代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
void reserve(size_t n)//扩容函数
{
if (n > _capacity)//只有n大于_capacity才需要扩容
{
char* temp = new char[n + 1];
if (_str != nullptr)
{
strcpy(temp, _str);
delete[] _str;
}
_str = temp;
_capacity = n;
}
}
void resize(int n,char ch='\0')
{
if (n < _size)//当n小于_size则更新_size并且直接将该位置的元素赋\0
{
_size = n;
_str[_size] = '\0';
}
else//n大于_size时,_size后面的_size-n个值赋ch
{
if (n > _capacity)//n大于当前空间的容量则需要扩容
{
reserve(n);
}
while (_size!=n)
{
_str[_size] = ch;
_size++;
}
_str[_size] = '\0';
}
}
const char* c_str()
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1("hello world");
ZH::string st2("hello world");
st1.resize(20, 'x');
st2.resize(5, 'x');
cout << st1.c_str() << endl;
cout << st2.c_str() << endl;
return 0;
}? ? ? ? 运行结果:

? ? ? ? 通过调试可以发现resize缩小字符串长度时,并没有对其空间容量进行缩小:

8、中间插入数据、删除数据
8.1 插入数据
? ? ? ? 中间插入数据时要注意扩容问题,并且从某个位置插入时,原本该位置的数据要往后挪动,具体示意图如下:

? ? ? ? 某个位置插入数据的代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
void reserve(size_t n)//扩容函数
{
if (n > _capacity)//只有n大于_capacity才需要扩容
{
char* temp = new char[n + 1];
if (_str != nullptr)
{
strcpy(temp, _str);
delete[] _str;
}
_str = temp;
_capacity = n;
}
}
void Insert(size_t pos, char ch)//插入字符
{
assert(pos <= _size);//判断位置是否合规
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size + 1;//从此处刚好可以把\0拷贝过去
while (end > pos)
{
//采用的是指向位置的前一个位置的元素拷贝给指向位置
_str[end] = _str[end - 1];
end--;
}
_str[end] = ch;
_size++;
}
void Insert(size_t pos, const char* str)//插入字符串
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + len;
while (end >= pos + len)
{
//采用的是指向位置的前len个位置的元素拷贝给指向位置
_str[end] = _str[end - len];
end--;
}
strncpy(_str + pos, str, len);
_size = _size + len;
}
const char* c_str()
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
};
}
int main()
{
ZH::string st1("hello world");
st1.Insert(3, 'z');
st1.Insert(3, "aaa");
cout << st1.c_str() << endl;
return 0;
}? ? ? ? ?运行结果:

8.2 删除数据
void erase(size_t pos, size_t n = npos)
//删除pos位置数据,n表示从pos位置起要删除n个数据
//npos表示-1,-1的正整数表示四十多亿,其实就是表示从pos位置开始后面数据全部删除? ? ? ? npos可以用静态成员来定义,因为静态成员属于所有对象,属于整个类,删除的物理逻辑也和插入的物理逻辑相似,即删除一个数据后,后面的数据往前面挪动。

????????删除数据的代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
void reserve(size_t n)//扩容函数
{
if (n > _capacity)//只有n大于_capacity才需要扩容
{
char* temp = new char[n + 1];
if (_str != nullptr)
{
strcpy(temp, _str);
delete[] _str;
}
_str = temp;
_capacity = n;
}
}
void erase(size_t pos, size_t n = npos)//删除pos位置数据,n表示从pos位置起要删除n个元素
{
assert(pos <= _size);//判断要删除的位置是否合格
if (n == npos || n + pos >= _size)//如果用的是缺省值nops,则表示从该位置起后面全部删除
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + n);//用拷贝的形式实现删除
_size -= n;
}
}
const char* c_str()
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
static size_t npos;//定义一个静态成员变量
};
}
size_t ZH::string::npos = -1;//-1的正整数表示一个40多亿的数
int main()
{
ZH::string st1("hello world");
ZH::string st2("hello world");
st1.erase(3, 7);//从位置3开始删除7个元素
st2.erase(3);//从位置3开始后面全部删除
cout << st1.c_str() << endl;
cout << st2.c_str() << endl;
return 0;
}? ? ? ? 运行结果:

9、查找数据
? ? ? ? 逻辑就是遍历字符串,找到了就返回该元素的下标,没找到可以返回npos,示例代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
size_t find(char c, size_t pos = 0)//查找字符
{
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == c)
{
return i;//找到了返回该元素的下标
}
}
return npos;//没找到返回npos
}
size_t find(const char* str, size_t pos = 0)//查找字符串
{
assert(pos < _size);
char* poi = strstr(_str + pos, str);//复用strstr函数
if (poi != nullptr)
return poi - _str;//找到了通过指针-指针得到整数返回该数值
else
return npos;//没找到返回npos
}
const char* c_str()
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
static size_t npos;//定义一个静态成员变量
};
}
size_t ZH::string::npos = -1;//-1的正整数表示一个40多亿的数
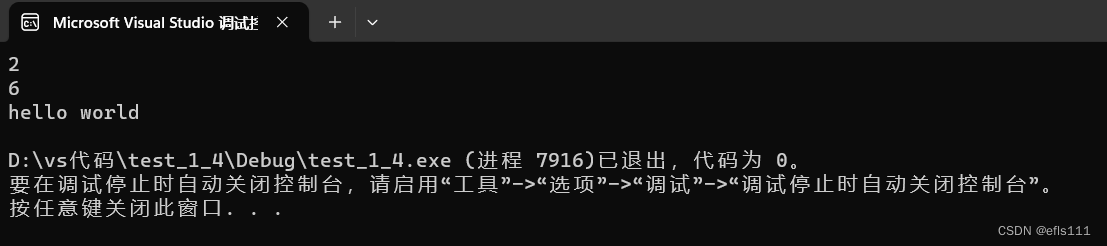
int main()
{
ZH::string st1("hello world");
cout << st1.find('l') << endl;
cout << st1.find("wor") << endl;
cout << st1.c_str() << endl;
return 0;
}? ? ? ? 运行结果:
10、打印对象(流插入、流提取)
? ? ? ? 以上打印字符串用的方法都是传首地址打印方式,可以对流插入、流提取符号:‘<<'和'>>'进行运算符重载,就可以直接使用‘<<'和'>>'打印对象。
? ? ? ? 代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;
namespace ZH//把string放在命名空间中,放在与库里的string重名
{
class string
{
public:
string(const char* str = "")//构造函数初始化对象
:_size(strlen(str))
{
_capacity = _size;
//实际上会给\0开一个空间,但是capacity不记录该空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
void reserve(size_t n)//扩容函数
{
if (n > _capacity)//只有n大于_capacity才需要扩容
{
char* temp = new char[n + 1];
if (_str != nullptr)
{
strcpy(temp, _str);
delete[] _str;
}
_str = temp;
_capacity = n;
}
}
void push_back(char ch)//尾插字符
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size++] = ch;
_str[_size] = '\0';
}
void append(const char* str)//尾插字符串
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
//两个运算符重载构成函数重载
string& operator+=(char ch)//尾插字符--运算符重载
{
push_back(ch);//复用尾插函数
return *this;
}
string& operator+=(const char* str)//尾插字符串--运算符重载
{
append(str);//复用尾插函数
return *this;
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
const char* c_str()const
{
return _str;
}
~string()//析构函数,释放_str申请的空间
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;//在堆上开辟一块空间用于存放字符串
size_t _size;//记录字符串的总字符数
size_t _capacity;//记录所开辟空间的大小
static size_t npos;//定义一个静态成员变量
};
ostream& operator<<(ostream& out, const string& str)//流插入
{
cout << str.c_str()<< endl;
return out;
}
istream& operator>>(istream& in, string& str)//流提取
{
str.clear();//每次输入数据的时候把之前数据清空
char ch;
ch = in.get();
size_t i = 0;
char buff[128];//用buff作为一个缓冲区的概念,减少每次+=字符串的消耗
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
buff[128] = '\0';//因为是一个字符的往buff里面输入,因此buff是没有\0的,要手动添加
str += buff;//数组满了就一次性+=到str
i = 0;
}
ch = in.get();
}
if (i != 0)//把数组剩余的数据+=到str中
{
buff[i] = '\0';
str += buff;
}
return in;
}
}
size_t ZH::string::npos = -1;//-1的正整数表示一个40多亿的数
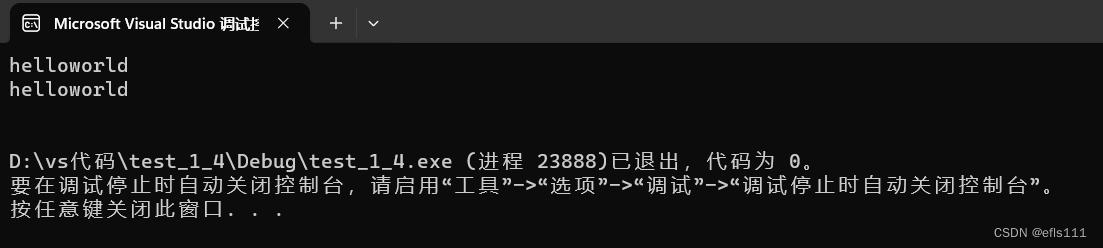
int main()
{
ZH::string st1("ssssssssssssssssssssssssss");
cin >> st1;
cout << st1 << endl;
return 0;
}? ? ? ? 运行结果:
? ? ? ? 这里注意库里面的流提取是每次输入新的数据时,旧的数据会直接清空,因此每次调用流提取函数时会先调用clear()函数清空之前的数据。
结语:
? ? ? ? 以上就是关于string类的实现和讲解,只有了解了string底层是如何实现的,才能帮助我们进一步了解和使用string类。最后希望本文可以给你带来更多的收获,如果本文对你起到了帮助,希望可以动动小指头帮忙点赞👍+关注😎+收藏👌!如果有遗漏或者有误的地方欢迎大家在评论区补充,谢谢大家!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- flowable-startEvent[开始事件]相关配置[表单、执行监听器]
- ECharts实现简单饼图和柱状图
- 【Java核心基础】一文带你了解Java中super关键字的重要作用
- 跨国文件传输需要注意什么?企业如何进行跨国传输大文件?
- element ui Checkbox 多选框组件 lable不支持Object类型的值的问题
- git怎么删除远程分支
- 教你三招该如何制作家具样本册
- 【Linux】Linux中的日志查询方法
- YOLOv8使用自定义改进后的模型同时《加载官方预训练权重》教程,附代码
- EMC噪声的本质