2024-01-23(MongoDB&&ElasticSearch)
附上:MongoDB详解,用心看这篇就够了【重点】-CSDN博客
1.MongoDB中的副本集
是一组维护相同数据集得mongodb服务。副本集可以提供冗余和高可用性,是所有生产部署的基础。也可以说,副本集是类似于有自动故障恢复功能的主从集群。
主节点,从节点,仲裁节点。
2.MongoDB副本集中主节点的选举原则:
MongoDB在副本集中,会自动进行主节点的选举,主节点的选举的触发条件:
1)主节点故障
2)主节点网络不可达(默认心跳为10s)
3)人工干预
选举规则:
票数最高;如果票数相同,数据新的节点获胜(数据的新旧是根据操作日子oplog来对比的)
在选举过程中,优先级很重要,优先级越高,获得其他人的投票的几率就越大。
3.我定义好后端接口规范,前端为我传递我所需要的参数。
4.分片集群
分片集群是一种跨多台机器分布数据的方法,MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署。换句话说:分片是指将数据拆分,将其分散存在不同的机器上的过程。将数据分散到不同机器上,不需要功能强大的大型计算机就可以存储更多的数据,处理更多的负载。
5.MongoDB分片集群包含以下组件:
1)分片(存储):每个分片包含分片数据的子集。每个分片都可以部署为副本集。
2)mongos(路由):mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。
3)config servers(“调度”的配置):配置服务器存储集群的元数据和配置设置。
6.MongoDB的安全认证:
默认情况下,MongoDB不会对连接客户端进行用户验证,这是十分危险的。为了保证mongodb的安全可以做以下几个步骤:
1)使用新的端口,默认27017端口如果一旦知道了ip就可以连接上,不安全。
2)设置mongodb的网络环境,最好将mongodb部署到公司服务器的内网中,这样外网是访问不到的,公司内部使用vpn等。
3)开启安全认证。认证要同时设置服务器之间的内部认证方式,同时要设置客户端连接到集群的账号密码认证方式。
7.什么是elasticsearch:
elasticsearch是一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能。
8.什么是elastic stack(ELK):
是以elasticsearch为核心的技术栈,包括beats(用来做数据收集)、logstash(用来做数据收集)、kihana(用来做数据展示)、elasticsearch(负责数据的搜索,存储等核心功能)。
9.什么是Lucece:
elasticsearch的底层就是基于Lucece来实现的。Lucece是Apache的开源搜索引擎类库,提供了搜索引擎的核心API。
10.正向索引和倒序索引:
传统数据库(mysql)使用正向索引,
elasticsearch采用倒序索引:
文档:每条数据就是一个文档
词条:文档按照语义分成的词语
eg:

用elasticsearch搜索的流程案例:
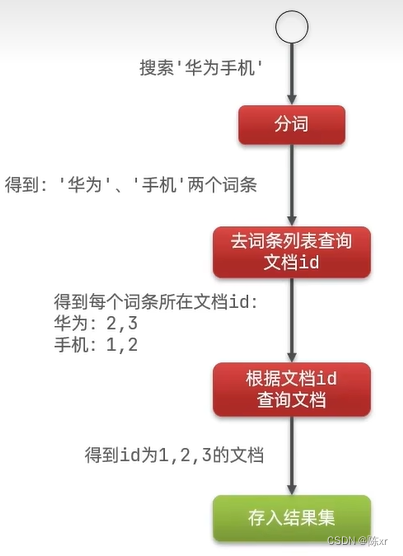
11.elasticsearch的倒排索引的含义是:
传统是根据文档去找词条,但是es是根据词条去找文档。这就是倒排索引的含义。
12.总结:
文档:每一条数据就是一个文档。
词条:对文档中的内容分词,得到的词语就是词条
正向索引:基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条。
倒排索引:对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时现根据词条查询文档id,而后获得文档。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 阿里云国外服务器价格表
- 大数据毕业设计:商品推荐系统+可视化+2种协同过滤推荐算法 Django框架 计算机毕业设计(附源码+论文)?
- 记一次:Python的学习笔记四(Gatway网关配置python服务)
- STM32 学习(二)GPIO
- axios封装
- HarmonyOS4.0系统性深入开发21PageAbility组件概述
- 日期处理第四篇(终)- Java日期时间处理大总结
- git merge和git rebase区别
- 基于Java+SpringBoot+vue+elementui的校园文具商城系统详细设计和实现
- maven pom中的内置变量及引用