接口幂等也没这么简单啊
作者简介:大家好,我是码哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
阶段4、深入jdk其余源码解析
阶段5、深入jvm源码解析
有一个问题在面试中常被问到:
你能介绍下项目中是如何保证接口幂等性的吗?
上述问题还有一个升级版:
你们是如何保证MQ不重复消费的?
很多工作1~2年的初学者(特别是做外包的同学),在写接口时未必会考虑到幂等性,往往是接口抛异常时才会拍着大腿懊悔地说:焯,忘做幂等了。
你觉得这很丢脸?不不不,自己写的接口因为抛异常被BUG机器人发到群里固然有点社死,但好歹数据库没有插入重复数据,而这多亏了组长在设计表结构时做了唯一键约束。如果连唯一约束都没有做,那就连最后一层屏障也被攻破了。万一这个接口恰好做的是虚拟币充值,公司可就亏大了。
如何保证接口幂等
回到开头的问题上来:怎么保证接口的幂等呢?一般来说,最简单的办法就是:先查一遍,看看数据是否存在(或已经处理过),如果存在就return结束,如果不存在则插入(或处理)。
public void sendPrize(Long userId, Integer prizeType, Integer num) {
// 先查发奖流水
PrizeSendRecord record = this.getPrizeSendRecord(userId, prizeType);
if (record != null) {
log.info("奖品已发放, userId:{}, prizeType:{}", userId, prizeType);
return;
}
// 发放奖品
this.sendPrize(userId, prizeType, num);
}一般来说,我们会给t_prize_record再加一个UNIQUE KEY作为底层保障(唯一索引原理和上面代码差不多,也要先查一遍,只不过这个操作被下推到MySQL内部去了):
ALTER TABLE `promotion`.`t_prize_record`
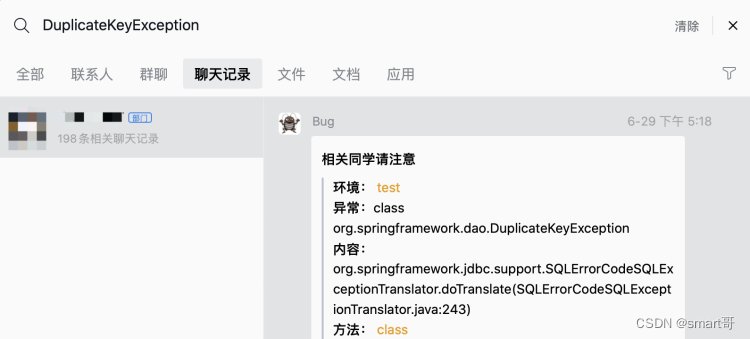
ADD UNIQUE INDEX `uk_user_id_prize_type`(`user_id`, `prize_type`) USING BTREE COMMENT '用户奖品发放记录唯一索引';给数据库建立唯一索引,这个大家都没什么异议,但眼尖的同学早就按奈不住心中的喜悦:嘿嘿,B老师这里写错了,“先查后写”这样的非原子操作,在高并发的场景下是不可靠的!
确实,假设两个线程同时达到this.getPrizeSendRecord()方法,它们查询到的结果都是null,所以都会向下执行this.sendPrize(),最终还是会insert两次,并由于数据库设置了唯一索引,所以会在第二次插入时抛出DuplicateKeyException。
解决办法很简单:加锁,而且还是分布式锁,够牛逼了吧8. 分布式锁和同步器 · redisson/redisson Wiki
public void sendPrize(Long userId, Integer prizeType, Integer num) {
RLock lock = this.redisson.getLock(PRIZE_KEY_PREFIX + ":" + user_id + ":" + prizeType);
// 尝试获锁,最多等待1秒;如果获取到锁,最多持有0.5秒;执行结束finally手动释放锁
boolean res = lock.tryLock(1000, 500, TimeUnit.MILLISECONDS);
if (res) {
try {
// 先查发奖流水
PrizeSendRecord record = this.getPrizeSendRecord(userId, prizeType);
if (record != null) {
log.info("奖品已发放, userId:{}, prizeType:{}", userId, prizeType);
return;
}
// 发放奖品
this.sendPrize(userId, prizeType, num);
} finally {
lock.unlock();
}
}
}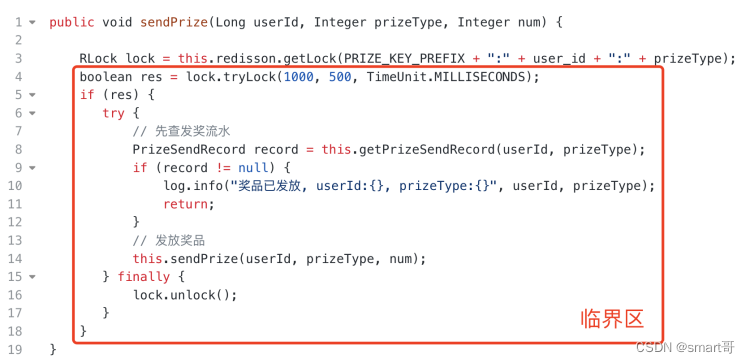
由于临界区内同一时刻只允许一个线程进入,当A线程完成操作并退出时,B线程才能进入临界区,此时getPrizeRecord()得到的结果已经有数据了(刚刚A线程插入的),于是直接return不再继续向下,也就避免了DuplicateKeyException。
不加个事务保证ACID?
实际开发中,一个发奖流程可能会比上面Demo要复杂一些,这里假设发奖后还有一个操作:
public void sendPrize(Long userId, Integer prizeType, Integer num) {
RLock lock = this.redisson.getLock(PRIZE_KEY_PREFIX + ":" + user_id + ":" + prizeType);
boolean res = lock.tryLock(1000, 500, TimeUnit.MILLISECONDS);
if (res) {
try {
// 先查发奖流水
PrizeSendRecord record = this.getPrizeSendRecord(userId, prizeType);
if (record != null) {
log.info("奖品已发放, userId:{}, prizeType:{}", userId, prizeType);
return;
}
// 发放奖品
this.sendPrize(userId, prizeType, num);
// 【另外一个操作】
this.anotherWriteOperation();
} finally {
lock.unlock();
}
}
}有两个写入操作,此处需要保证事务。之前在知乎上回答说前东家没用分布式事务,大家都觉得不可思议,但实际上我们的接口没那么脆弱,很少会动不动就奔溃导致事务不完整,而且大部分业务都没有严重到一点都不能错,事后手动补偿经常是允许的。但毕竟没事务让人觉得心里不安,这里就加上吧。
@Transactional(rollbackFor = Exception.class) // 【加个本地事务】
public void sendPrize(Long userId, Integer prizeType, Integer num) {
RLock lock = this.redisson.getLock(PRIZE_KEY_PREFIX + ":" + user_id + ":" + prizeType);
boolean res = lock.tryLock(1000, 500, TimeUnit.MILLISECONDS);
if (res) {
try {
// 先查发奖流水
PrizeSendRecord record = this.getPrizeSendRecord(userId, prizeType);
if (record != null) {
log.info("奖品已发放, userId:{}, prizeType:{}", userId, prizeType);
return;
}
// 发放奖品
this.sendPrize(userId, prizeType, num);
// 另外一个操作
this.anotherWriteOperation();
} finally {
lock.unlock();
}
}
}然后你会发现,你的接口又开始偶发性地抛DuplicateKeyException了...这是个很有意思的问题。我们都知道,MySQL的隔离级别分为4种:
- 读未提交(READ UNCOMMITTED)
- 读已提交(READ COMMITTED)
- 可重复读(REPEATABLE READ)
- 串行化(SERIZLIZABLE)
隔离级别从上至下越来越高,相应地效率越来越低,而MySQL默认的隔离级别是可重复读,大部分公司也不会去更改MySQL的默认事务隔离级别。
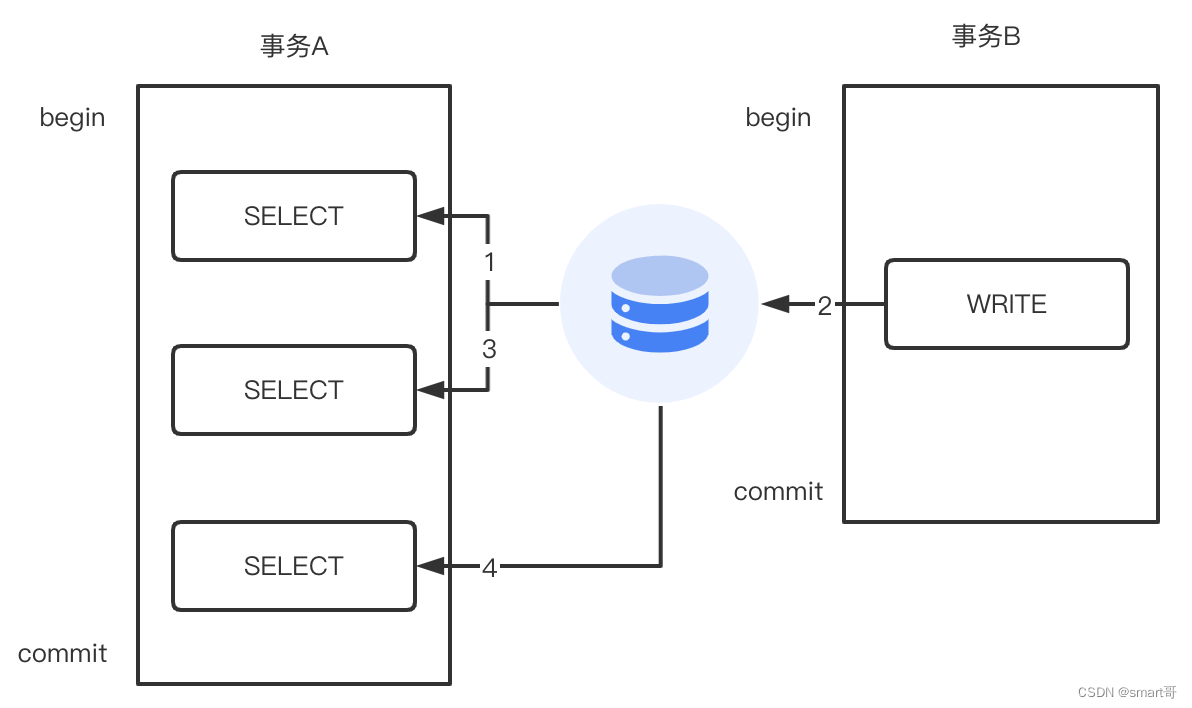
- 读未提交:第3步SELECT就可以查询到第2步更新的数据
- 读已提交:第4步SELECT才可以查询到第2步更新的数据
- 可重复读:事务A在自己的事务中,无论多少次读取,结果都与第1步SELECT时结果一致,即无法读到第2步的数据
分析到这,一部分同学已经知道答案了。我们一起来梳理一下。

我们可以看到,t1(蓝色线程)完成①插入并②刚出临界区,此时t2(绿色线程)就可以③获取到锁进入临界区,并做了④查询。按我们上面的理解,对于可重复读来说,无论t1有没有提交事务,t2在第④步都是读不到最新记录的。
这里顺便回顾一下快照读和当前读的概念。一般来说SELECT都是快照读,所谓快照就是一个字段在某个时刻的数据版本,比如在18:00 age=18,18:01 age=20,那么这就是两个快照版本。而快照读会受隔离级别影响,不同隔离级别的读取规则不同,即使现在age=22了,但事务A在某个隔离级别下读到的可能是age=18,而事务B在另一个隔离级别下读到的却是age=20。总之对于快照读来说,它看到的数据是“漂浮在真实数据上面的某一个时刻的版本数据”。
对于SELECT,我们可以手动在末尾加上FOR UPDATE之类的语句,把它强制变成当前读。所谓当前读,就是忽略一切“障眼法”、刺破一切漂浮着的版本数据,直接拿到当前这一刻最真实的数据,该是什么就是什么。
这么一分析你就明白了,t2用的是普通SELECT,也就是快照读。虽然t1已经插入记录,但t2仍然看不到,SELECT为null,于是继续执行WRITE,最终发生DuplicateKeyException(因为它们插入相同的数据)。
你看,这就是你们整天喊的“没有事务的工程都是垃圾”,现在给你事务了,你能保证自己处理得好吗?
最简单的幂等方案
让我们回到原点重新思考一下这个接口到底想干嘛:无非就是多个操作,既要保证事务,又要在方法级别保证幂等。先不考虑幂等,你要怎么保证事务?
@Transactional(rollbackFor = Exception.class)
public void sendPrize(Long userId, Integer prizeType, Integer num) {
// 先查发奖流水
PrizeSendRecord record = this.getPrizeSendRecord(userId, prizeType);
if (record != null) {
log.info("奖品已发放, userId:{}, prizeType:{}", userId, prizeType);
return;
}
// 发放奖品
this.sendPrize(userId, prizeType, num);
// 另外一个操作
this.anotherWriteOperation();
}很简单对吧,我们以前就是这么做事务的,它能保证方法内部的多个操作要么同时成功、要么同时失败。只不过在此基础上,我们还希望能做幂等,所以加了一个“先查后写”的前置操作。
然而,“先查后写”无法保证幂等。为什么?是因为请求太快了吗?绝对不是!一个线程无论多快,都是线性的,都是先查后写,一旦发现不为null就直接返回了。根本原因是多个线程同时查,同时判断为null,同时向下执行写入操作。也就是说,多线程是根本原因!
但此时加锁也有点问题:在当前线程 [解锁后~事务提交前] 的这段间隙,如果有另一个线程进入临界区做查询,会因为快照读的限制,看不到最新的数据。
这种情况下,一般就两种方案:
- 修改数据库隔离级别(读未提交)
- 过滤掉多余的线程
你猜你的组长会因为你要做某个接口的幂等而专门修改隔离级别吗?
那么解决办法很简单,把多余的线程过滤掉,反正它们是“重复”的,只要有一个就行(之前说过,一个线程即使再快也是顺序性的,不会出现并发问题)。
@Transactional(rollbackFor = Exception.class)
public void sendPrize(Long userId, Integer prizeType, Integer num) {
// 【过滤重复请求】
if(this.isDuplicated(userId, prizeType)) {
log.warn("重复请求");
return;
}
// 先查发奖流水
PrizeSendRecord record = this.getPrizeSendRecord(userId, prizeType);
if (record != null) {
log.info("奖品已发放, userId:{}, prizeType:{}", userId, prizeType);
return;
}
// 发放奖品
this.sendPrize(userId, prizeType, num);
// 另外一个操作
this.anotherWriteOperation();
}
private boolean isDuplicated(Long userId, Integer prizeType) {
RLock lock = this.redisson.getLock(PRIZE_KEY_PREFIX + ":" + user_id + ":" + prizeType);
try {
// 没锁上,说明有相同的请求正在处理,直接丢弃当前这个【重复】的请求
return !lock.tryLock(0L, 1L, TimeUnit.SECONDS);
} catch (InterruptedException e) {
log.error("上锁失败", e);
}
return true;
}
Redis不是关系型数据库,没有完整的事务实现,也没有所谓的隔离级别,而且还是单线程的,具有排他性,刚好用来做分布式锁。抢不到锁的请求,直接被丢弃,同一时刻只保证一个请求执行操作。
仔细比较一下上面的方案和最开始方案,你会发现这是两种思路:多余的尽量丢弃 VS 多余的等待执行。个人认为,既然都认定是重复请求了,就没有等待执行的必要了。
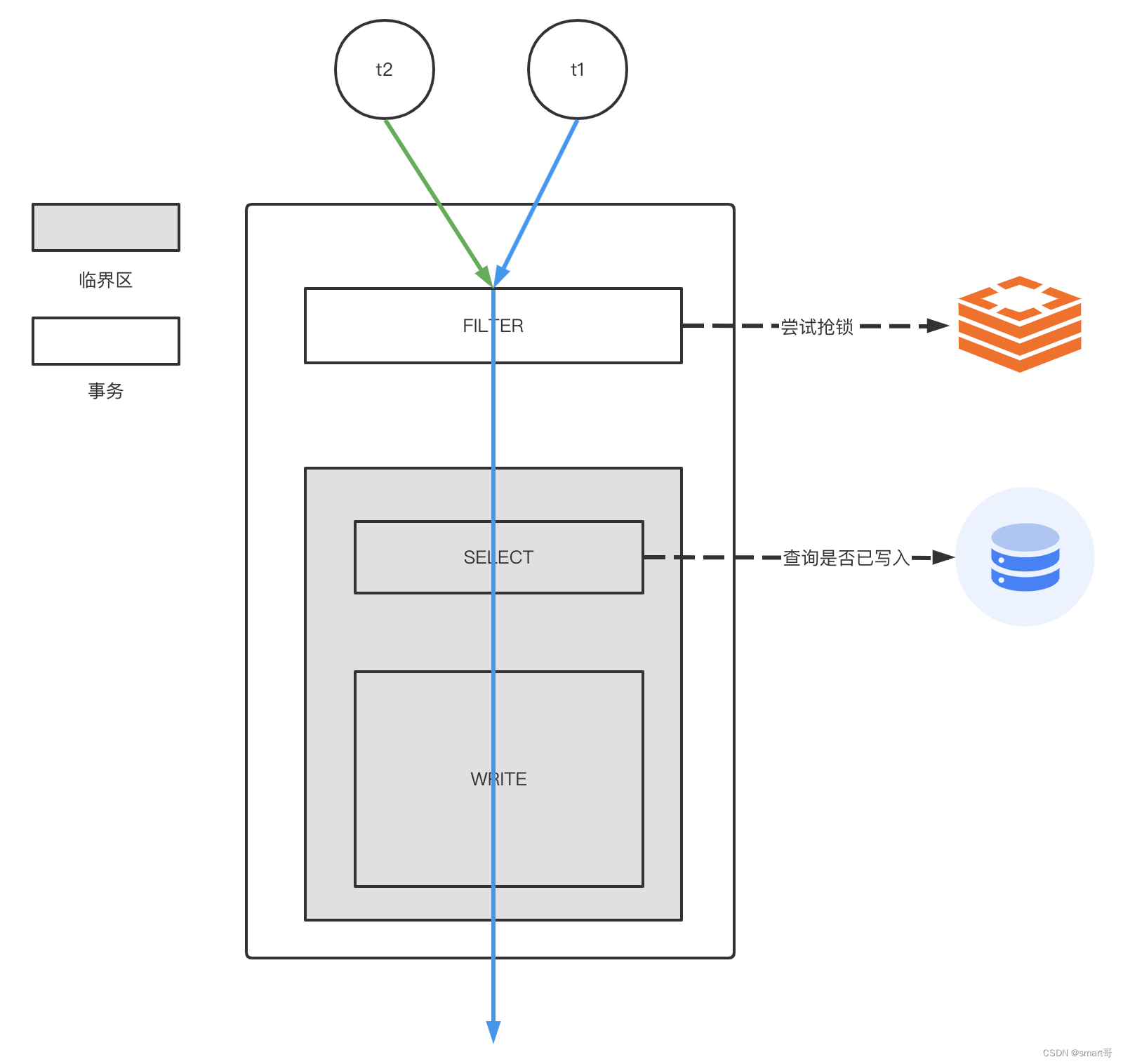
当然,上面的代码仍然比较简陋,有赌的成分:假设t1执行时间超过1秒,那么锁会被自动释放。此时t3(新的请求)进来SELECT,还是看不到t1写入的数据(t1还没提交事务,但锁被释放了),就会重复插入。当然,你可以把自动释放锁的时间适当设长一些,比如5秒。不用担心会妨碍其它请求,你的lock key只对相同参数的请求互斥,而相同参数的请求有什么理由要发起多次呢?
重复请求可以分为两种类型:
瞬时N个相同请求(高速重复、由Redis做过滤)
分多次相同请求(低速重复、这种可以被“先查后写”拦下)
这么看来,我们目前的方案理论上可以防下常规的重复请求,起码同一批重复请求(1秒内发了好多个)都会被丢弃。要想攻破这道防线,除非 再来一批重复请求 && 上一次锁被释放 && 上一次执行事务还没提交。而“多余的等待执行”这种方案,由于当初同一批的重复请求都阻塞等待进入临界区,那么一旦锁被释放(事务还未提交),原本阻塞的请求就会重新竞争进入临界区,很大概率还是存在数据可见性问题。

好几个重复请求在门口等着呢...上一个事务还没提交,其中一个就冲进来了
其他解决方案
其实幂等性的保证没那么简单,很多方案的引入似乎又带来了其他的困惑。所以幂等性到最后,一般还是由数据库唯一索引做兜底方案,代码层面只是辅助,尽可能地过滤一些重复请求。如果恰好方法使用了事务,那么原本棘手的幂等又会因为事务可见性问题变得更加复杂。最后要提一下,把DuplicateKeyException直接抛到客户端是不合理的,可以在上层进行统一拦截,返回友好提示:烫烫烫,CPU在高速运转,你点那么多次闹着玩呢?前端也可以配合做一些优化,比如点击后按钮置灰。
写到这,我突然想到另一个方案:通过设置注解属性,可以修改@Transactional的事务隔离级别为“读未提交”(仅针对当前Session),但不是很推荐。
MQ如何不重复消费
最后简单聊一下MQ如何保证不重复消费。
目前主流的MQ中间件都很少、或无法在生产端做到Exactly Once(恰好消费一次),所以极端情况下仍旧有可能同一个消息被发送多次。倒也不是它们不愿意,主要得不偿失而且效果还不好。其中最难搞定的或许是网络问题,因为你没法保证网络一直是稳定的。当网络不稳定,生产端收不到Broker的ACK时就可能会重发,而实际上这条消息已经发过了。
所以目前主流的做法通常是要求消费者自身(消息下游)去保证接口幂等,所以这个问题本质上和第一个问题是一样的,就是消费者接口如何保证幂等性。当消费者接口自身保证幂等时,那么无论是否有重复消息,数据都是安全的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!