[论文分享]TimeDRL:多元时间序列的解纠缠表示学习

论文题目:TimeDRL: Disentangled Representation Learning for Multivariate Time-Series
论文地址:https://arxiv.org/abs/2312.04142
代码地址:暂无
关键要点:多元时间序列,自监督表征学习,分类和预测
摘要
在许多现实世界的应用程序(例如,医疗保健和工业)中,多变量时间序列数据信息丰富,但由于缺乏标签和高维,具有挑战性。
最近在自监督学习方面的研究已经显示了它们在不依赖标签的情况下学习丰富表征的潜力,但它们在学习解纠缠嵌入和解决归纳偏差问题(例如,变换不变性)方面存在不足。为了解决这些挑战,我们提出了TimeDRL,这是一个通用的多元时间序列表示学习框架,具有解纠缠的双层次嵌入。TimeDRL具有三个新特征:(i)使用[CLS]令牌策略从修补的时间序列数据中分离出时间戳级和实例级嵌入的派生;(ii)利用时间戳预测和实例对比任务进行解纠缠表示学习,前者优化带有预测损失的时间戳级嵌入,后者优化带有对比损失的实例级嵌入;(iii)避免使用增强方法来消除归纳偏差,例如从裁剪和屏蔽中获得的变换不变性。在6个时间序列预测数据集和5个时间序列分类数据集上的综合实验表明,TimeDRL持续优于现有的表征学习方法,预测MSE平均提高57.98%,分类准确率平均提高1.25%。
此外,广泛的研究证实了TimeDRL体系结构中每个组件的相对贡献,半监督学习评估证明了它在现实场景中的有效性,即使有有限的标记数据。
1 介绍
在时间序列域中直接应用SSL面临两个挑战:
1)学习解纠缠的双级表示。现有的方法侧重于派生时间戳级别的嵌入或实例级别的嵌入,但不能同时派生两者。时间戳级别的嵌入对于异常检测和预测是有效的,而实例级别的嵌入则适合于分类和聚类任务。
理论上我们可以通过使用池化方法从时间戳级嵌入中提取实例级嵌入来避免显式地派生实例级嵌入,但这种方法通常会导致各向异性问题,其中嵌入被限制在嵌入空间中的一个狭窄的锥形区域,从而限制了它们的表达性。
2)归纳偏差。归纳偏差是指在学习过程中采用数据增强方法的假设和先验知识,以增强模型对未知数据的泛化能力。其他领域的数据增强方法引入的归纳偏差不适用于时间序列数据。
2 创新点
-
解纠缠双级嵌入的普遍适用性:我们介绍了TimeDRL,一个操作于解纠缠双级嵌入的多元时间序列表示学习框架。这种设计可以广泛适用于各种时间序列下游任务。TimeDRL利用专用的[CLS] token与patched的时间序列数据相结合,允许实例级嵌入通过扩展时间序列范围来捕获更全面的语义信息。
-
两个借口任务:TimeDRL使用时间戳预测任务来优化时间戳级嵌入,使用实例对比任务来优化实例级嵌入,确保在两个级别上有效学习。
-
减轻归纳偏倚:为了避免归纳偏倚,TimeDRL在时间戳预测任务中使用了一种没有屏蔽的重建误差方法,并在实例对比任务中利用dropout层的随机性,确保无偏数据表示。
-
在11个真实世界基准测试中的有效性能:TimeDRL在时间序列预测和分类基准测试中始终优于最先进的性能,证明了所提出的方法在真实世界应用中的通用性。
3 方法
采用Siamese网络架构,使用Transformer作为编码器fθ,通过利用编码器内dropout层的固有随机性从相同的输入生成两个不同的嵌入视图,从而消除了对数据增强的需要。为了优化编码器,采用了两个pretext任务:以时间戳级嵌入为目标的时间戳预测任务和以实例级嵌入为重点的实例对比任务。

3.1 解纠缠的双级嵌入
transformer在下游时间序列任务中取得了显著的成功,但在时间序列的自监督学习领域,基于cnn和基于rnn的模型通常优于transformer,这表明transformer在时间序列表示学习中的全部潜力尚未得到充分利用。此外,BERT和RoBERTa等模型已被证明在生成高质量的句子嵌入方面取得了成功,这使得Transformer Encoder成为我们框架的合适选择。
我们采用Transformer Encoder作为TimeDRL的主要架构,采用了PatchTST中的Patch概念,将相邻的时间步长聚合到一个基于Patch的token中。该技术大大减少了transformer所需的上下文窗口大小,显著降低了培训成本,并大大增强了培训过程的稳定性。
在BERT和RoBERTa中,[CLS]令牌用于捕获句子级嵌入,这促使我们采用它来提取时间序列域中的实例级嵌入。虽然理论上可以通过池化方法(例如,全局平均池化)从时间戳级嵌入派生实例级嵌入,这种方法会导致各向异性问题。当时间戳级嵌入被限制在嵌入空间中的一个狭窄区域时,就会出现这个问题,从而降低了它们有效捕获各种信息的能力。NLP中的研究表明,与传统的池化方法相比,通过对比学习优化[CLS]令牌可以获得更好的结果。这一发现与我们的实验结果一致。
具体框架:
1)给定一个输入时间序列样本,我们首先应用实例归一化和Patch得到一系列token
2)在这些token的开头添加一个[CLS] token,得到编码器的输入
3)编码器由一个线性token编码层,一个线性位置编码层和一系列自关注块组成
4)得到编码器输出后,将第一个token([CLS]token)对应的嵌入指定为实例级嵌入zi,将后续的嵌入视为时间戳级嵌入zt
3.2 TimeDRL中的时间戳预测任务
时间戳预测任务的目的是在不引入归纳偏差的情况下推导时间戳嵌入。考虑到不同时间序列数据集之间特征的巨大差异,我们将TimeDRL设计为一个通用框架,避免了任何转换不变性的考虑。因此,我们在TimeDRL中引入了非增强的时间戳预测任务,重点研究了在没有数据增强方法的情况下对经过patch的时间序列数据进行重建。
给定时间戳级嵌入zt,通过时间戳预测头pθ(没有激活函数的线性层)进行处理以生成预测,预测损失LP计算xpatch与预测输出之间的MSE:
![]()
实例级嵌入zi不会从MSE损失中更新,总LP是对两个视图的LP取平均。
3.3 TimeDRL中的实例对比任务
为了捕获整个序列的整体信息,我们开发了一个实例对比任务,通过对比损失来派生实例级嵌入。在对比学习中,需要两个不同的嵌入视图来计算损失。NLP中的SimCSE应用对比任务来改进来自[CLS]令牌的句子级嵌入,利用dropout层来引入变化,而不依赖于任何外部增强方法。
为了与我们避免数据增强的承诺保持一致,我们在编码器内使用dropout层来引入输出嵌入的随机性,通过两次将数据通过编码器,从相同的输入生成两个不同的嵌入视图。对于每个嵌入,我们提取第一个位置作为我们的实例级嵌入。
此外,只使用这种技术无法解决对比学习中的抽样偏差。当随机选择的负样本与正样本相似时,就会发生抽样偏差,这是由于周期模式的存在而在时间序列域中常见的情况。为了缓解这一问题,本文提出的方法结合了一个额外的预测头和一个停止梯度操作,以防止模型崩溃。
使用负余弦相似度计算损失,总LC是对两个视图的LC取平均。
![]()
最后,联合训练时间戳预测任务和实例对比任务,并使用λ在两种损失之间进行调整:
![]()
4 实验
4.1 下游任务
将数据集划分为三个部分:60%用于训练,20%用于验证,20%用于测试,除非存在预定义的训练-测试分割。
我们使用transformer作为编码器的架构fθ。使用线性层设计了时间戳预测头pθ,使用中间有BatchNorm和ReLU的两层MLP设计了实例对比头pθ。
在时间序列预测任务中,我们将通道独立与补丁结合在一起。该方法将多变量时间序列视为多个单变量序列,由单个模型进行综合处理。对于时间序列分类,我们发现忽略信道无关性会产生更好的结果。
4.1.1 预测
为了评估TimeDRL时间戳级嵌入的有效性,我们对时间序列预测进行了线性评估。这包括使用借口任务对编码器进行预训练,然后冻结编码器权重,并在下游预测任务上附加线性层进行训练。
针对多变量和单变量都进行了预测实验。
ETT的所有特征都用于多变量预测,而单变量预测仅使用油温特征。
Exchange包括8个国家从1990年到2016年的每日汇率。对于多变量预测,使用来自所有这些国家的数据,而对于单变量预测,特别关注新加坡。
Weather提供近1600个美国地区4年来的当地气候数据。对于多变量预测,考虑所有特征,而对于单变量预测,我们会特别关注’web bulb’ 特征。
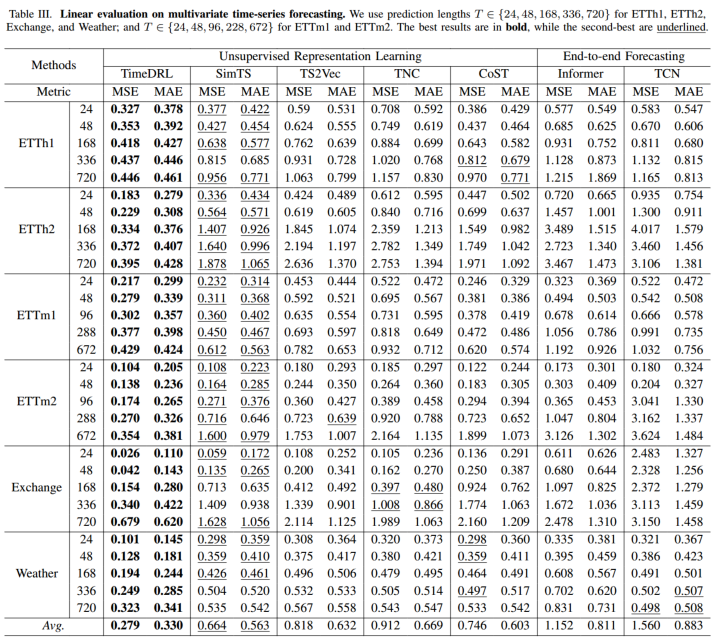

4.1.2 分类
为了评估TimeDRL实例级嵌入的有效性,我们使用线性评估方法进行时间序列分类。采用与预测评估类似的方法,我们首先使用自监督学习训练编码器,冻结其权重,然后附加一个线性层用于分类任务的训练。

4.1.3 半监督实验
首先在大型未标记数据集上训练编码器以学习丰富的表示,然后在下游任务头部使用有限的标记数据进行微调,编码器权重在微调期间被调整。为了模拟有限标签数据可用性的情况,我们在数据集中随机保留一部分标签。仅使用标记数据(监督学习)与结合未标记和标记数据(带微调的TimeDRL)的比较结果如图所示。结果表明,将未标记的数据与TimeDRL结合可以显著提高性能,特别是在可用的标记数据很少的情况下。值得注意的是,即使100%的标签可用,TimeDRL预训练阶段的好处也是显而易见的。

4.2 消融实验
1)pretext 任务
时间戳预测任务侧重于将损失专门应用于时间戳级嵌入,而实例对比任务则针对实例级嵌入。我们的实验研究了每个任务对表征学习有效性的影响。

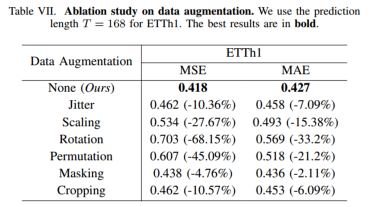
2)数据增强方法
实验了6种特定于时间序列的数据增强方法。
-
抖动通过加性高斯噪声模拟传感器噪声。
-
缩放通过将数据与随机标量相乘来调整数据的大小。
-
旋转通过排列特征的顺序和可能翻转特征值的符号来修改数据集。
-
排列将数据分割成段,然后随机排列这些段以创建新的时间序列实例。
-
屏蔽将时间序列数据中的值随机设置为零。
-
裁剪将删除时间序列实例的左右区域,并用零填充空白以保持相同的序列长度。
对于时间序列,采用掩蔽和裁剪增强的危害相对较小,但它们仍然会导致性能下降。该实验支持了我们最初的假设,即完全避免增强方法对于消除归纳偏置至关重要,从而确保TimeDRL的最佳性能。
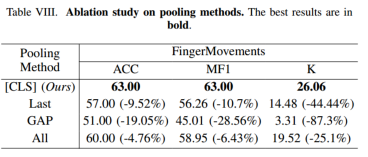
3)cls token 的 pool方式
对实例级嵌入的其他3种不同池化策略进行了实验。
-
Last利用最后一个时间戳级嵌入作为实例级表示。
-
GAP使用全局平均池,在时间轴上平均时间戳级嵌入,以聚合实例级嵌入。
-
All 将所有时间戳级嵌入Flatten,以创建单个实例级表示。
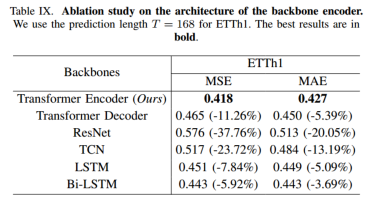
4)encoder结构
使用5种不同的模型进行了实验。
-
Transformer Encoder使用屏蔽自注意。这确保了每个时间戳的嵌入只关注前面的时间戳,而不是后面的时间戳。
-
ResNet采用了计算机视觉的著名架构ResNet18,用适合于时间序列数据的一维卷积进行修改。
-
TCN[49]将扩张和残差连接与因果卷积结合起来,专门用于时间序列的自回归预测。
-
LSTM使用长短期内存单元来捕获顺序数据中的依赖项。使用单向LSTM,关注过去和现在的数据,以防止未来的数据泄漏。
-
Bi-LSTM遵循LSTM结构,但包含双向处理,允许模型集成来自过去和未来时间戳的信息。
Transformer Decoder的性能下降,突出了双向自我注意在实现对整个序列的全面理解中的关键作用。同样,当比较LSTM和Bi-LSTM时,后者表现出更高的性能,因为它能够访问过去和未来的信息。
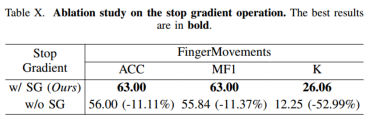
5)停止梯度
为了解决抽样偏差,我们的方法包括一个额外的预测头和一个停止梯度操作。这种不对称设计,一条路径带有额外的预测头,另一条路径带有停止梯度,在防止模型崩溃方面被证明是有效的。
5 总结
-
分离了时间戳级和实例级嵌入
-
引入两个优化目标
-
对patch后的数据进行重建
-
采用编码器内的dropout层实现不同视图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 超过80%大厂都在用,Jetpack Compose现代Android界面开发的未来
- vue3生命周期
- MYSQL语句 | find_in_set()
- Gradle的安装及源替换步骤详解
- 贪心算法理论基础
- 【springboot+vue项目(零)】开发项目经验积累(处理问题)
- 第九部分 使用函数 (四)
- 阿里云大模型数据存储解决方案,为 AI 创新提供推动力
- 什么是Vue.js的响应式系统(reactivity system)?如何实现数据的双向绑定?
- 智慧路灯网关R40——点亮城市之光首选