日志平台搭建手册
1.?Java环境安装和配置
JDK要求安装1.8版本,安装可以参考《Linux安装JDK完整步骤》。
2.?创建用户
创建elk用户,用来管理elk相关的服务,包括:filebeat、logstash、elasticsearch、kibana。执行命令:
useradd elk #创建用户
passwd elk #设置elk用户密码采用同样的方法创建用户zookeeper和kafka,这两个用户分别管理zookeeper服务和kafka服务。
3.?Zookeeper安装和配置
本文档采用Zookeeper安装包为zookeeper-3.4.11.tar.gz,所有命令均由zookeeper用户操作执行,除特殊说明之外。
注意:配置操作请严格按照先单机配置,然后再进行集群配置。
3.1.?解压安装
执行命令,完成安装包的解压:tar -zxvf zookeeper-3.4.11.tar.gz,解压完成后在当前目录生成zookeeper-3.4.11目录,针对该目录创建软连接,方便以后软件升级,执行命令:ln -s zookeeper-3.4.11 zookeeper,创建完成之后,当前目录结构如下图:

3.2.?单机配置
3.2.1.?创建配置文件
将zookeeper/conf/zoo_sample.cfg拷贝重命名为zoo.cfg,命令如下:
cd ~/zookeeper/conf cp zoo_sample.cfg zoo.cfg
3.2.2.?创建目录
注意:本节操作可能需要使用具有root权限的用户。
创建zookeeper存放数据的目录和日志输出文件,本文创建目录如下:
mkdir -p /data/zookeeper/data #数据存储目录 mkdir -p /data/zookeeper/log #日志输出文件
保证这些目录所属用户和用户组为zookeeper,执行命令:
chown -R zookeeper:zookeeper /data/zookeeper
3.2.3.?编辑配置文件
在/data/zookeeper/data目录下创建myid文件,写入内容为1,如下图:
![]()
编辑zookeeper配置文件,即之前创建的zoo.cfg,配置内容下:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log clientPort=2181 server.1=ip1:2888:3888 #ip1为myid文件内容为1的机器的ip地址 # server.2=ip2:2888:3888 #ip2为myid文件内容为2的机器的ip地址 # server.3=ip3:2888:3888 #ip3为myid文件内容为3的机器的ip地址
在conf目录下新建java.env文件,用于配置zookeeper使用内存大小,文件内容如下:
export JVMFLAGS="-Xms4096m -Xmx4096m $JVMFLAGS" #内存大小设置为4G3.2.4.?配置环境变量
为了便于使用zookeeper/bin目录下的命令,需要配置和编辑两个环境变量:ZOOKEEPER_HOME和PATH,修改/etc/profile文件,增加如下内容:
export ZOOKEEPER_HOME=/home/zookeeper/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin上述操作需要root权限才能修改,修改完成之后需要执行下面的命令才能生效。
source /etc/profile生效之后可以在任何地方直接执行zookeeper/bin目录下的命令。
3.3.?集群配置
3.3.1.?创建目录
在其他机器上按照3.2.2创建zookeeper数据和日志目录。
在zookeeper数据目录下创建myid文件,内容分别为2,3,4...
3.3.2.?拷贝安装
将zookeeper的安装目录远程拷贝至其他机器,并创建对应的软链接。
scp -rp zookeeper-3.4.11/ zookeeper@ip2:/home/zookeeper/ scp -rp zookeeper-3.4.11/ zookeeper@ip3:/home/zookeeper/3.3.3.?修改配置
修改3台机器的配置文件内容如下即可:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log clientPort=2181 server.1=ip1:2888:3888 #ip1为myid文件内容为1的机器的ip地址 server.2=ip2:2888:3888 #ip2为myid文件内容为2的机器的ip地址 server.3=ip3:2888:3888 #ip3为myid文件内容为3的机器的ip地址
3.3.4.?配置环境变量
其他机器配置环境变量,方便使用zookeeper的命令,参考3.2.4节。
3.4.?启动和停止
配置好环境变量之后,可以在任何目录下执行如下的命令。
3.4.1.?命令提示
执行zkServer.sh命令,控制台给出提示信息,如下图:

3.4.2.?启动
执行命令:zkServer.sh start
3.4.3.?停止
执行命令:zkServer.sh stop
4.?Kafka安装和配置
本文档采用Kafka安装包为kafka_2.11-1.1.0.tgz,所有命令均由kafka用户操作执行。
注意:配置操作请严格按照先单机配置,然后再进行集群配置。
4.1.?解压安装
执行命令,完成安装包的解压:tar -zxvf kafka_2.11-1.1.0.tgz,解压完成后在当前目录生成kafka_2.11-1.1.0目录,针对该目录创建软连接,方便以后软件升级,执行命令:ln -s kafka_2.11-1.1.0 kafka,创建完成之后,当前目录结构如下图:

4.2.?单机配置
4.2.1.?创建目录
注意:本节操作可能需要使用具有root权限的用户。
Kafka将数据以日志文件的形式存储在磁盘中,日志文件存放目录需要创建。本文创建目录如下:
mkdir -p /data/kafka/logs #创建目录 chown -R kafka:kafka /data/kafka #修改文件夹所属用户和用户组
4.2.2.?编辑配置文件
首先,请备份配置文件,执行命令:cp server.properties server.properties.bak。
需要修改的内容如下:
broker.id=1 listeners=PLAINTEXT://ip1:9092 #ip1表示当前机器ip,请自行替换 log.dirs=/data/kafka/logs zookeeper.connect=ip1:2181,ip2:2181,ip2:2181 #ip1,ip2,ip3分别表示集群机器ip,请自行替换
编辑脚本kafka-server-start.sh,设置启动内存,增加内容:
export KAFKA_HEAP_OPTS="-Xms4G -Xmx4G" #启动内存设置为4G
4.2.3.?配置环境变量
为了便于使用kafka/bin目录下的命令,需要配置和编辑两个环境变量:KAFKA_HOME和PATH,修改/etc/profile文件,增加如下内容:
export KAFKA_HOME=/home/kafka/kafka export PATH=$PATH:$KAFKA_HOME/bin上述操作需要root权限才能修改,修改完成之后需要执行下面的命令才能生效。
source /etc/profile生效之后可以在任何地方直接执行kafka/bin目录下的命令。
4.3.?集群配置
4.3.1.?创建目录
在其他机器上按照4.2.1创建kafka的日志目录。
4.3.2.?拷贝安装
将kafka的安装目录远程拷贝至其他机器,并创建对应的软链接。
scp -r kafka_2.11-1.1.0/ kafka@ip2:/home/kafka scp -r kafka_2.11-1.1.0/ kafka@ip3:/home/kafka4.3.3.?修改配置
修改其他两台机器上kafka配置文件中broker.id的值为2,3;listeners参数的值修改为实际机器的ip地址。
4.3.4.?配置环境变量
其他机器配置环境变量,方便使用kafka的命令,参考4.2.3节。
4.4.?启动和停止
4.4.1.?启动
执行命令:kafka-server-start.sh /home/kafka/kafka/config/server.properties;
后台启动:kafka-server-start.sh -daemon /home/kafka/kafka/config/server.properties;
4.4.2.?停止
执行命令:kafka-server-stop.sh
4.4.3.?测试
请参考《kafka集群测试和简单使用》。
4.5.?队列监控
队列中消息是否有堆积?这是我们最关心的事情,下面介绍如何监控消息堆积。
首先找到该队列的消费者分组id,执行如下命令:
$KAFKA_HOME/bin/kafka-consumer-groups.sh --bootstrap-server ip1:9092 --list
结果将显示所有消费者分组id,找到该队列的消费分组id,假如为:test。接下来,可以根据消费分组id查看该分组下所有Topic、Partition的消费偏移量和消息堆积量。执行如下命令:
$KAFKA_HOME/bin/kafka-consumer-groups.sh --bootstrap-server ip1:9092 --group test --describe
显示结果如下图所示:

LOG-END-OFFSET表示对应的Topic对应的Partition的总消息数量,CURRENT-OFFSET表示当前消费分组已经读取消费的消息量,LAG表示剩余的消息量,即消息堆积量。
LAG = LOG-END-OFFSET - CURRENT-OFFSET
如果发现LAG大于0,表示对应的Topic中指定的Partition存在消息堆积,可以适当增加消费者来进行处理。
5.?Filebeat安装和配置
Filebeat主要用来实时采集最新的日志信息,在日志平台中的角色为——采集器,类似一个代理组件。本文档采用filebeat安装包为filebeat-6.1.1-linux-x86_64.tar.gz,所有命令均由elk用户操作执行。
5.1.?解压安装
执行命令,完成安装包的解压:tar -zxvf filebeat-6.1.1-linux-x86_64.tar.gz,解压完成后在当前目录生成filebeat-6.1.1-linux-x86_64目录,针对该目录创建软连接,方便以后软件升级,执行命令:ln -s filebeat-6.1.1-linux-x86_64 filebeat,创建完成之后,当前目录结构如下图:

5.2.?编辑配置文件
首先,请先备份配置文件,配置文件位于filebeat根目录,执行命令:cp filebeat.yml filebeat.yml.bak。
清空原配置文件,执行命令:true > filebeat.yml。再在filebeat.yml文件输入如下内容:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /data/test-log/pay/system.log
tags: [“pay”, “system”]
multiline.pattern: ^(INFO|TRACE|DEBUG|WARN|ERROR|FATAL)\s
multiline.negate: true
multiline.match: after
#tail_files: true
output.console:
enabled: true
pretty: true
output.kafka:
enabled: false
hosts: ["ip1:9092","ip2:9092","ip3:9092"]
topic: system-log
required_acks: 1
compression: gzip
max_message_bytes: 1000000上述配置内容中,红色字体标明的属性值需要根据实际情况进行调整。配置文件中有两个输出配置,同时只能使用一个,可以通过enabled属性进行控制。建议开启output.console,直接在控制台输出采集到的日志信息。
5.3.?启动和停止
本节的所有命令均是在filebeat安装根目录下执行。
5.3.1.?命令提示
执行./filebeat --help,显示如下:
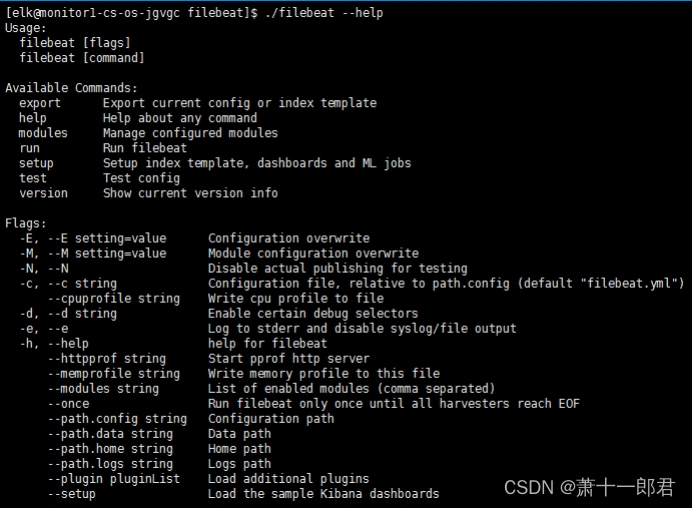
5.3.2.?启动
启动执行如下命令:
./filebeat -c filebeat.yml
上述是前台启动,后台启动在上述命令之后加上 & 即可:
./filebeat -c filebeat.yml &
5.3.3.?停止
如果是前台启动filebeat,则按Ctrl+C即可停止;如果是后台启动,则先使用PS命令查找filebeat进程号,然后使用kill杀掉即可。
6.?LogStash安装和配置
FileBeat只能单纯的将日志信息采集之后发送到Kafka集群,无法对日志信息进行解析。LogStash的Filter组件具有数据处理功能,能够对日志信息进行抽取转换,实现日志的标准化。本文档采用logstash安装包为logstash-6.1.1.tar.gz。
6.1.?解压安装
LogStash的安装比较简单,只需要解码压缩包即可。执行命令,完成安装包的解压:tar -zxvf logstash-6.1.1.tar.gz,解压完成后在当前目录生成logstash-6.1.1目录,针对该目录创建软连接,方便以后软件升级,执行命令:ln -s logstash-6.1.1 logstash,创建完成之后,当前目录结构如下图:

6.2.?编辑配置文件
第6节中,FileBeat从system.log文件读取日志信息发送到了Kafka集群,本节主要对LogStash从Kafka读取信息进行配置。
为了方便对日志的解析,需要自定义Grok表达式。在logstash根目录下创建目录patterns,并创建custom文件,写入自定义的Grok表达式。具体操作如下:
mkdir patterns;
cd patterns;vim custom,输入自定义表达式:
ALL ([\s\S]*)
CHDATE \d{4}\-\d{2}\-\d{2}
CHDATETIME %{CHDATE} %{TIME}在$LOGSTASH_HOME/config目录下创建配置文件hx-pipeline.conf,内容如下:
input {
kafka {
group_id => "logstash-hx"
client_id => "c2"
bootstrap_servers => "ip1:9092,ip2:9092,ip3:9092"
topics => ["system-log"]
auto_offset_reset => "latest"
consumer_threads => 3
type => "all-logs"
codec => json
}
}
# The filter part of this file is commented out to indicate that it is optional.
filter {
if "system" in [tags] {
grok {
patterns_dir => ["$LOGSTASH_HOME/patterns"]
match => {"message" => "%{LOGLEVEL:loglevel} \[%{DATA:handler}\] %{CHDATETIME:logdatetime} %{ALL:content}"}
add_field => ["host", "%{[beat][hostname]}"]
remove_field => ["message","beat","prospector","offset","space"]
}
date {
match => ["logdatetime", "yyyy-MM-dd HH:mm:ss"]
timezone => "+00:00"
target => "@timestamp"
remove_field => ["logdatetime"]
}
}
}
output {
stdout { codec => rubydebug }
}
output {
elasticsearch {
hosts => ["host:9200"]
index => "hx-log-%{+YYYY.MM.dd}"
document_type => "%{type}"
}
}该配置文件中使用pattern_dir指定了自定义Grok表达的目录,从日志信息中解析出日志级别信息,用变量loglevel表示,输出容器用变量handler表示,日志输出时间logdatetime,日志内容content,并将logdatetime作为@timestamp。
红色字体部分需要根据实际情况进行调整。
6.3.?启动和停止
本节的所有命令均是在logstash安装根目录下执行。
6.3.1.?命令提示
执行如下命令,即可获得命令使用指南:
./bin/logstash --help
其中-f可以指定配置文件,--config.test_and_exit验证配置文件,--config.reload.automatic启动logstash后,默认每隔3s自动加载配置文件。
6.3.2.?启动
根据上述命令使用指南,启动进程之前要验证配置文件的可用性:
./bin/logstash -f config/hx-pipeline.conf --config.test_and_exit
如果通过校验,则执行如下命令启动logstash进程:
./bin/logstash -f config/hx-pipeline.conf --config.reload.automatic
如果需要后台启动,则参照FileBeat的启动方式,在启动命令后面加上‘&’即可。
6.3.3.?停止
如果是前台启动logstash,则按Ctrl+C即可停止;如果是后台启动,则先使用PS命令查找logstash进程号,然后使用kill杀掉即可。
7.?ES安装和配置
ElasticSearch简称ES,分布式搜索系统,负责对数据进行索引存储,并提供搜索接口。本文主要使用ES对服务日志进行存储、索引并提供检索功能。
7.1.?前置要求
ElasticSearch简称ES,其安装有一定的必备条件,否则安装完成之后服务无法启动。
7.1.1.?创建用户
ES不能以root用户启动,所以我们必须创建启动用户,在本文档第2节已经创建用户elk,这里ES的安装就使用elk用户来完成。
7.1.2.?修改系统配置
ES的启动需要修改两项系统配置信息,都需要以root用户才能进行修改。
7.1.2.1.?修改最大文件限制数
首先查看当前系统允许的最大文件限制数,执行命令:ulimit -n。将最大文件限制数修改为65536,修改/etc/security/limits.conf,在文件尾部增加如下内容:
* soft nofile 65536 * hard nofile 65536
保存文件之后,退出系统重新登录之后查看是否修改成功。
7.1.2.2.?修改内存映射区域的最大数量
首先查看当前系统内存映射区域允许的最大数量,执行命令:sysctl -a | grep vm.max,结果如下:
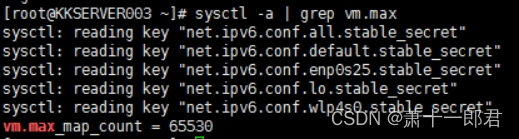
将该值设置为262144,编辑文件/etc/sysctl.conf,添加下面的配置:
vm.max_map_count=262144,保存文件之后执行命令:sysctl -p使配置生效。
7.2.?解压安装
ElasticSearch的安装比较简单,只需要解码压缩包即可。执行命令,完成安装包的解压:tar -zxvf elasticsearch-6.1.1.tar.gz,解压完成后在当前目录生成elasticsearch-6.1.1目录,针对该目录创建软连接,方便以后软件升级,执行命令:ln -s elasticsearch-6.1.1 es,创建完成之后,当前目录结构如下图:

7.3.?单机配置
7.3.1.?创建目录
在elk当前home目录下创建es的日志存储目录和数据存储目录。
mkdir -p var/es/data mkdir -p var/es/logs
7.3.2.?编辑配置文件
配置文件位于$ES_HOME/config目录中,该目录中有三个文件,分别是:
elasticsearch.yml:es应用配置文件;
jvm.options:es进程jvm配置文件;
log4j2.properties:es程序日志配置文件;
本节主要对elasticsearch.yml进行编辑,首先应该备份该文件,执行命令:
cp elasticsearch.yml elasticsearch.yml.bak
编辑文件,修改内容如下:
cluster.name: mycluster
node.name: node-1
node.attr.rack: r1
path.data: /home/elk/var/es/data
path.logs: /home/elk/var/es/logs
bootstrap.memory_lock: false
network.host: ip1
http.port: 9200
discovery.zen.ping.unicast.hosts: ["ip1"] #集群配置时待修改
discovery.zen.minimum_master_nodes: 1 #集群配置时待修改将上述配置中的ip1修改为机器实际的ip地址。
7.4.?集群配置
ES的集群配置是在上节单机配置的基础上进行的,即首先已完成单机配置,并可以正常启动ES单机实例。现在我们要在ip2的机器上再部署一个ES实例,与ip1的实例组成ES集群。
7.4.1.?拷贝安装目录
将ip1的ES解压目录拷贝到ip2机器上对应的位置,在ip2上拷贝目标目录下执行命令:
scp -r elk@ip1:/path/to/elasticsearch-6.1.1?.
7.4.2.?创建目录
参考8.3.1节,在ip2机器上创建对应的目录存放es的数据和日志信息。
7.4.3.?修改配置文件
集群配置与单机配置有所不同。
首先,编辑ip2上es的配置信息,最终内容如下:
cluster.name: mycluster
node.name: node-2
node.attr.rack: r2
path.data: /home/elk/var/es/data
path.logs: /home/elk/var/es/logs
bootstrap.memory_lock: false
network.host: ip2
http.port: 9200
discovery.zen.ping.unicast.hosts: ["ip1", “ip2”]
discovery.zen.minimum_master_nodes: 2注意,上述两个加粗的配置项,修改ip1上的es配置中的这两个属性值,使ip1和ip2的值相同。
7.4.4.?注意事项
(1)机器ip2一定要修改系统配置,否则es无法启动,参考8.1.2节。
(2)集群中的节点需要相互通信,通信端口默认为9300,一定要在防火墙中配置9300端口通过,否则集群无法形成。
(3)启动用户不能为root,请使用之前创建的用户,本文为elk。
7.5.?启动和停止
7.5.1.?命令提示
在ES的安装根目录下,执行命令:./bin/elasticsearch -h,显示结果如下:
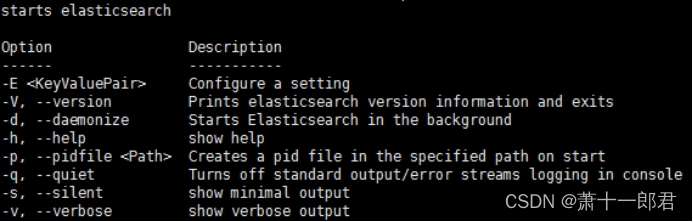
7.5.2.?启动
使用elk用户启动es服务。Elasticsearch可以前台启动也可以后台启动。
前台启动命令:./bin/elasticsearch,默认不带任何参数则进行前台启动,所有日志都输出到控制台,方便调试;
后台启动命令:./bin/elasticsearch -d,参数-d表示后台启动,生产环境建议使用。
7.5.3.?停止
如果是前台启动elasticsearch,则按Ctrl+C即可停止;如果是后台启动,则先使用PS命令查找elasticsearch进程号,然后使用kill杀掉即可。
8.?Kibana安装和配置
ES对外提供搜索接口,但是对于通常使用的用户不友好,Kibana一套简单的前端搜索系统,直接对接ES集群,能够为用户提供友好的日志搜索界面。
8.1.?解压安装
Kibana的安装比较简单,只需要解码压缩包即可。执行命令,完成安装包的解压:tar -zxvf kibana-6.1.1-linux-x86_64.tar.gz,解压完成后在当前目录生成kibana-6.1.1-linux-x86_64目录,针对该目录创建软连接,方便以后软件升级,执行命令:ln -s kibana-6.1.1-linux-x86_64 kibana,创建完成之后,当前目录结构如下图:

8.2.?系统配置
8.2.1.?创建目录
在elk当前home目录下创建kibana的日志存储目录和数据存储目录。
mkdir -p var/kibana/data mkdir -p var/kibana/logs
8.2.2.?编辑配置
Kibana的配置文件为:$KIBANA_HOME/config/kibana.yml。
首先备份该文件:cd $KIBANA_HOME/config && cp kibana.yml kibana.yml.bak
编辑,vim kibana.yml,将配置信息修改为:
server.port: 5601
server.host: "yourIP"
elasticsearch.url: "http://ip1:9200, http://ip2:9200,"
logging.dest: "/home/elk/var/kibana/logs/kibana.log"
path.data: "/home/elk/var/kibana/data"
logging.useUTC: false8.3.?启动和停止
8.3.1.?启动
在kibana的根目录下编写启动脚本start-kibana.sh,内容如下:
nohup /home/elk/kibana/bin/kibana &
给脚本赋予可执行权限:chmod +x start-kibana.sh。
执行脚本./start-kibana.sh即可启动kibana服务,根据上述配置文件,kibana的访问地址为:http://yourIP:5601
8.3.2.?停止
使用PS命令查找kibana进程号,然后使用kill杀掉该进程。
8.4.?简单使用
在地址栏输入:http://yourIP:5601,进入kibana系统。

8.4.1.?匹配索引
在ES中,一个索引代表一个数据库,ES的搜索默认是跨库的。要展示数据,必须先指定要展示那些数据库的数据,即指定索引。这里可以采用正则表达式来匹配。
由于我们的索引命令规范是:hx-log-YYYY.MM.DD,所以匹配模式设置为:hx-log-*。
8.4.2.?日志搜索
8.4.2.1.?时间区间选择
Discovery页面右上角可以自由选择搜索时间区间,可以项非常丰富。点击右上角显示如下图:

8.4.2.2.?关键字搜索
时间是搜索的辅助条件,真正搜索到想要的日志信息,需要通过关键字搜索。在搜索框中输入关键字,系统默认匹配日志的所有字段。如果想要指定字段搜索,可以采用field:keyword的形式输入,比如上图中,搜索框输入loglevel:ERROR,表示日志记录的loglevel这个字段,如果字段值与“ERROR”匹配,则被搜索命中,命中关键字以绿色底白色字形式展示。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 极高创新性!直接写!BiTCN-Attention基于双向时间卷积融合多头自注意力机制的多变量回归预测程序,独家原创!直接运行!
- 深入探索Qt 6.3:全面了解新特性及应用技巧
- C++数据类型以及函数设计学习记录
- 关闭Windows自动更新的6种方法
- Flutter基建 - 12种隐式动画小组件全解析
- 图像处理-像素位置的一阶导数和二阶导数
- Java服务网关的实现与应用:Spring Cloud Gateway、Zuul和Kong比较
- 2023量子科技十大人物(团队) | 光子盒年度系列
- 毕业设计日志——在Pycharm中安装Tensorflow
- 哭了,幼师姐妹一定都要刷到啊