【计算机组成原理】总复习笔记(上)
特别声明:
本文仅供参考,本文部分内容来自AI总结、网络搜集与个人实践。如果任何信息存在错误,欢迎读者批评指正。本文仅用于学习交流,不用作任何商业用途。
文章目录
- 第 1 章 计算机系统概述
- 第 2 章 总线
- 第 3 章 存储器
- 3.1 存储器类型
- 3.2 RAM 和 ROM 特性
- 3.3 闪存特性
- 3.4 存储器芯片地址与数据引脚
- 3.5 存储器刷新
- 3.6 存储器交叉编址
- 3.7 存储器突发传送
- 3.8 存储器设计
- 3.9 存储器地址计算
- 3.10 存储器字节编址
- 3.11 存储器地址寄存器位数
- 3.12 存储器设计与芯片数量
- 3.13 DRAM芯片行列设计
- 3.14 存储器总线位数与容量
- 3.15 磁盘读取时间
- 3.16 RAID 可靠性提升措施
- 3.17 磁盘存取时间计算
- 3.18 磁盘存储器描述
- 3.19 Cache 命中率计算
- 3.20 Cache 映射方式计算
- 3.21 Cache 映射和替换策略
- 3.22 指令 Cache 与数据 Cache 分离目的
- 3.23 数据 Cache 缺失率计算
- 3.24 数组访问局部性描述
- 3.25 Cache 行位数计算
- 3.26 Cache 比较器个数和位数计算
- 3.27 计算机存储器访问
- 3.28 存储器层次结构与性能
- 3.29 页式虚拟存储管理
- 3.30 直写和回写策略
- 3.31 存储器访问命中率
- 3.32 虚拟地址转换
- 3.33 计算机指令执行过程
- 3.34 直接映射方式下的 Cache
- 3.35 缺页处理与异常
- 3.36 TLB 和 Cache 特性
- 3.37 虚拟地址转换与存储管理
- 3.38 Cache结构与页式虚拟存储管理
- 3.39 存储器层次结构优化
- 3.40 存储器技术的未来趋势
- 第 4 章 输入/输出系统
- 1. 显示存储器和带宽计算
- 2. I/O 总线的数据传输
- 3. I/O 接口
- 4. I/O 指令的数据传送
- 5. I/O 接口
- 6. 外部中断
- 7. 单级中断系统
- 8. 多级中断系统
- 9. 设备 I/O 时间计算
- 10. 外部中断的处理
- 11. 中断 I/O 和 DMA 方式比较
- 12. 中断响应时间和 CPU 利用率
- 13. 中断 I/O 的信息交换
- 14. DMA 方式的特点
- 15. CPU 时间占用百分比的计算
- 16. DMA 方式的 CPU 利用率
- 17. DMA 方式和外部 I/O 中断
- 18. 外部中断事件
- 19. 外部中断的特点
- 20. 周期挪用 DMA 方式
- 21. 多重中断系统
- 22. 中断 I/O 方式
- 23. CPU 时间占用百分比的计算
- 24. 计算机性能参数
- 25. 外设的异步串行通信
- 26. I/O 方式的时间占用百分比计算
- 27. 磁盘驱动器的结构和性能参数
第 1 章 计算机系统概述
1.1 冯·诺依曼计算机结构
标准定义: 冯·诺依曼计算机结构是一种计算机体系结构,其中指令和数据以二进制形式存放在存储器中,CPU通过指令周期的不同阶段来区分指令和数据。
通俗解释: 冯·诺依曼计算机就像一家工厂,工厂里有一本操作手册(指令),还有原材料和成品(数据)都放在一个大仓库(存储器)里。工厂的管理者(CPU)按照操作手册的步骤,从仓库中取出原材料,进行加工,最后把成品放回仓库。
指令周期 (Instruction Cycle)
指令周期是计算机执行一条指令所经历的完整过程。它通常包括取指(Fetch)、译码(Decode)、执行(Execute)、访存(Memory Access)和写回(Write-back)等阶段。在指令周期内,CPU从存储器中获取指令,并在各个阶段执行特定的操作,包括获取数据、对数据进行处理等。
在这种情况下,CPU可以根据指令周期的不同阶段来区分当前操作是指令还是数据。典型地,在取指阶段CPU从存储器中取出下一条指令;在执行阶段CPU可能需要从存储器中取出数据来执行指令操作。
控制单元 (Control Unit)
控制单元是计算机的一个重要部件,负责指挥和协调计算机内部各部件的操作。它主要执行指令周期中的指令解码(Decode)和执行(Execute)等操作。控制单元解释指令,确定指令操作类型,并向其他部件发出相应的控制信号,以确保指令能够正确执行。控制单元也负责协调各个执行单元,包括算术逻辑单元(ALU)和寄存器等,确保指令按照正确的顺序和时间执行。
存储器单元 (Memory Unit)
存储器单元是计算机中用于存储数据和指令的组件。它分为主存储器(RAM)和辅助存储器(如硬盘驱动器)等。主存储器用于临时存储程序和数据,而辅助存储器则用于长期存储数据和程序。存储器单元被CPU用来读取和写入数据、指令等信息,以及暂时保存中间计算结果等。
1.2 高级语言与机器级目标代码
标准定义: 高级语言源程序需要经过编译程序转换为机器级目标代码,而汇编语言源程序则经过汇编程序翻译为机器语言程序。
通俗解释: 高级语言就像人们使用的日常语言,而机器级目标代码则是计算机能够理解的语言。编译程序就像翻译官,负责把人们用高级语言写的文章翻译成计算机能够执行的机器语言。
这道题涉及到将高级语言源程序转换为机器级目标代码的过程。以下是相关专业术语的解释:
编译程序 (Compiler)
编译程序是将高级语言源代码一次性全部翻译成目标代码的软件工具。它将整个高级语言程序源代码转换为等效的机器语言目标代码。编译程序首先进行词法分析、语法分析、语义分析等操作,然后生成相应的目标代码。该目标代码可以保存在文件中,稍后可以被执行,而不需要再次翻译源代码。
汇编程序 (Assembler)
汇编程序是一种将汇编语言源程序翻译成机器语言程序的翻译程序。与编译程序类似,汇编程序将汇编语言代码转换为机器级目标代码。不同之处在于,汇编程序针对的是汇编语言而不是高级语言。它将汇编语言中的符号指令翻译为对应的机器码,并生成可执行的机器语言程序。
链接程序 (Linker)
链接程序用于将多个目标代码文件或库文件中的模块合并成一个单独的可执行文件。它将各个模块中引用的符号(如函数或变量)进行连接,解决符号引用关系,从而创建一个完整的可执行程序。这个过程包括地址解析、符号解析、重定位等步骤。
解释程序 (Interpreter)
解释程序是将源程序的一条语句翻译成对应的机器目标代码,并立即执行的软件。它不会生成目标代码文件,而是逐行读取源代码并解释执行。解释程序翻译一条语句,执行一条语句,这与编译程序将整个程序一次性翻译成目标代码的方式不同。
在题目中,正确答案是 C,即编译程序,因为编译程序是将高级语言源代码一次性全部翻译成目标代码的软件。
1.3 计算机硬件执行的程序类型
标准定义: 计算机硬件能够直接执行的是机器语言程序,而汇编语言程序需要经过汇编才能被执行。
通俗解释: 计算机就像一个聪明的工人,他能够理解的语言是机器语言,而汇编语言就像是工人们用来交流的简便语言,需要经过一个翻译的过程。
-
机器语言程序(I):
- 可以直接被计算机硬件执行。
- 机器语言是计算机能够理解和执行的二进制编码。
-
汇编语言程序(II):
- 需要经过汇编过程将汇编代码转换为机器语言。
- 汇编语言是一种人类可读性更强的低级编程语言。
-
硬件描述语言程序(III):
- 不是直接被计算机硬件执行的语言。
- 用于描述硬件电路结构,需要通过合成工具转换为实际的电路。
因此,计算机硬件能够直接执行的是机器语言程序(I),答案为A。
1.4 冯·诺依曼计算机基本思想
标准定义: 冯·诺依曼计算机基本思想包括程序的功能通过中央处理器执行指令实现,指令和数据都用二进制数表示,形式上无差别,指令按地址访问,数据在指令中直接给出,程序执行前,指令和数据需预先存放在存储器中。
通俗解释: 冯·诺依曼计算机就像一个有条理的厨房,菜谱(指令)告诉厨师(CPU)如何烹饪食物,食材和成品(数据)都是用相同的方式存放在冰箱(存储器)里。在做菜之前,所有的食材和菜谱都需要提前准备好。
-
冯·诺依曼计算机基本思想:
- 冯·诺依曼结构计算机包括输入设备、输出设备、存储器、运算器和控制器。
- 功能通过中央处理器(运算器和控制器)执行指令来实现。
-
指令和数据表示:
- 二进制表示:指令和数据都以二进制数表示,形式上无差别。
- 存储器统一:指令和数据以同等地位存放于存储器内。
-
指令访问与数据存储:
- 指令按地址访问:程序通过中央处理器执行指令,指令通过地址访问。
- 数据存储:数据以二进制形式存放在存储器中,除立即寻址外,数据均存放在存储器内。
-
程序执行前的存储:
- 预先存放:在程序执行前,指令和数据需预先存放在存储器中。
1.5 高级语言程序的转换过程
标准定义: 将高级语言源程序转换为可执行目标文件的过程包括预处理、编译、汇编和链接。
通俗解释: 就好像烹饪一道美味的菜一样,高级语言源程序就像是食谱,而转换过程就是将这份食谱翻译成厨师能够理解的步骤。预处理就像准备食材,编译就像烹饪步骤,汇编就像将食材摆放在一起,而链接则是将每个步骤连接成最终的美味菜品。
-
SRAM(静态随机存储器):
- 不需要周期性刷新。
- 使用触发器作为存储单元,保持信息不变。
-
SDRAM(同步动态随机存储器):
- 需要周期性刷新。
- 使用电容存储,必须隔一段时间刷新一次,否则信息会丢失。
-
ROM(只读存储器):
- 不需要周期性刷新。
- 通常用于存储固定数据,只读。
-
Flash 存储器:
- 不需要周期性刷新。
- 使用非易失性存储技术,适用于闪存等应用。
1.6 提高程序执行效率的措施
标准定义: 提高程序执行效率的措施包括提高CPU时钟频率、优化数据通路结构和对程序进行编译优化。
通俗解释: 就好像提高工厂生产效率一样,提高CPU时钟频率就是让工人工作的速度更快,优化数据通路结构就是改进生产线,而对程序进行编译优化就是优化生产过程,让产品更快地生产出来。
-
提高 CPU 时钟频率(主频):
- 解释: 提高 CPU 时钟频率可以缩短每个时钟周期的时间,使得每个执行步骤所用的时间更短,从而加快程序的执行速度。这是通过提高硬件速度来缩短程序执行时间的方法。
-
优化数据通路结构:
- 解释: 数据通路负责实现 CPU 内部的运算器、寄存器,以及寄存器之间的数据交换。通过优化数据通路结构,可以提高计算机系统的吞吐量,加快程序的执行速度。
-
对程序进行编译优化:
- 解释: 编译优化是在将高级语言程序转化成机器指令序列时对程序进行优化。通过得到更优的指令序列,可以使程序执行时间更短。
1.7 浮点数操作速度指标
标准定义: 浮点数操作速度通常用MFLOPS(每秒执行多少百万条浮点数运算)来描述。
通俗解释: 就像一个数学天才能够在短时间内解决大量数学问题一样,MFLOPS描述了计算机在一秒内能够完成多少复杂的浮点数运算,是衡量计算机处理数学问题速度的标准。
-
MIPS(百万条指令每秒):
- 解释: 衡量每秒执行多少百万条指令,适用于衡量标量机的性能。
-
CPI(时钟周期数):
- 解释: 平均每条指令的时钟周期数。
-
IPC(每时钟周期执行的指令数):
- 解释: IPC是CPI的倒数,即每个时钟周期执行的指令数。
-
MFLOPS(百万浮点数运算每秒):
- 解释: 衡量每秒执行多少百万条浮点数运算,用于描述浮点数运算速度,适用于衡量向量机的性能。
1.8 计算机速度提升对程序执行时间的影响
标准定义: 提高计算机速度,特别是提高CPU时钟频率,可以有效减少程序执行时间。
通俗解释: 就好像提高工厂机器运转速度一样,提高计算机速度就是让计算机内部的处理器工作得更快,从而加速程序的执行,就像工厂生产产品的速度提高一样。
-
CPU 速度提高 50%后的新运行时间计算:
- 新 CPU 时间:原 CPU 时间 / 1.5(速度提高50%)
- 新 I/O 时间:不变
-
计算新的总运行时间:
- 新总运行时间 = 新 CPU 时间 + 新 I/O 时间
-
计算过程:
- 新 CPU 时间 = 90 / 1.5 = 60s
- 新总运行时间 = 60 + 10 = 70s
1.9 MIPS数的计算
标准定义: MIPS(每秒执行多少百万条指令)是衡量计算机性能的指标,可以通过计算机主频和CPI(每条指令的时钟周期数)来得到。
通俗解释: 就像衡量车速一样,MIPS表示计算机每秒能够执行多少百万条指令,主频就像车速一样,而CPI则是每条指令所花费的时间,两者乘积即可得到MIPS数。
-
CPI(Cycles Per Instruction):
- 解释: 每条指令执行所需的平均时钟周期数。对于基准程序,CPI可以通过加权平均每种指令的CPI得到,即CPI = Σ(每类指令的占比 × 指令的CPI)。
-
MIPS(Million Instructions Per Second):
- 解释: 每秒执行的百万条指令数。计算公式为 MIPS = 主频 / CPI。主频指的是计算机的时钟频率,CPI是每条指令的平均时钟周期数。
在这个题目中,计算机的MIPS数通过计算CPI和主频得到,即MIPS = 主频 / CPI。
1.10 程序执行时间的影响因素
标准定义: 程序执行时间受CPU时钟频率、指令条数和CPI的影响。
通俗解释: 就像制定旅行计划一样,程序执行时间受到计算机内部时钟频率(计划的速度)、指令条数(要经过的地点数量)和CPI(每到一个地点所花费的时间)的综合影响。优化这些因素可以让计算机更快地完成任务,就像合理安排旅行计划一样。
-
指令数减少到原来的70%:
- 解释: 编译优化后,程序 P 的执行所需的指令数减少到原来的70%,即新的指令数为0.7x。
-
CPI增加到原来的1.2倍:
- 解释: 编译优化后,每条指令的平均时钟周期数增加到原来的1.2倍,即新的CPI为24f/x。
-
执行时间计算:
- 原执行时间: 原程序 P 在机器 M 上的执行时间是20s。
- 新执行时间: (新指令数 × 新CPI) / f = (0.7x × 24 × f / x) / f = 24 × 0.7 = 16.8s。
1.11 机器字长与部件位数
标准定义: 机器字长是指CPU内部用于整数运算的数据通路的宽度。
通俗解释: 就像一条传送带的宽度一样,机器字长决定了CPU内部能够同时处理的数据位数。如果机器字长是32位,就好像传送带宽度是32英寸,CPU内部的数据通路也能够同时处理32位的数据。
-
CPI(Cycles Per Instruction):
- 解释: 每条指令执行所需的平均时钟周期数。在这个问题中,M1 上的平均CPI为2,M2 上的平均CPI为1。
-
主频:
- 解释: 计算机的时钟频率,M1 的主频为1.5GHz,M2 的主频为1.2GHz。
-
运行时间计算:
- M1 上的运行时间: 指令数 × CPI / 主频 = 指令数 × 2 / 1.5
- M2 上的运行时间: 指令数 × CPI / 主频 = 指令数 × 1 / 1.2
1.12 超级计算机性能指标
标准定义: 超级计算机性能通常以PFLOPS(每秒执行多少千万亿次浮点运算)为衡量标准。
通俗解释: 就像衡量一辆车的速度一样,PFLOPS表示超级计算机每秒能够执行多少千万亿次浮点运算,是评估其处理能力的标准。一台性能强大的超级计算机就像一辆飞驰的超级跑车一样。
-
机器字长(Word Length):
- 解释: 指 CPU 内部用于整数运算的数据通路的宽度。它等于 CPU 内部用于整数运算的运算器位数和通用寄存器宽度。
-
ALU(Arithmetic Logic Unit):
- 解释: 算术逻辑单元,用于执行算术和逻辑运算。其位数可能与机器字长相同,也可能不同。
-
指令寄存器:
- 解释: 通常用于存储正在执行或即将执行的指令,其位数不一定与机器字长相同。
-
通用寄存器:
- 解释: 用于存储临时数据的寄存器,其位数可能与机器字长相同,也可能不同。
-
浮点寄存器:
- 解释: 用于存储浮点数的寄存器,其位数可能与机器字长相同,也可能不同。
1.13 程序性能分析与优化
标准定义: 通过对程序进行编译优化,可以提高程序执行效率,减少执行时间。
通俗解释: 就像提升学习效率一样,通过对程序进行编译优化就是对代码进行一些调整,使得计算机能够更快地理解和执行这段代码,就像学生通过学习方法的优化能够更快地掌握知识一样。
- PFLOPS(PetaFLOPS):
- 解释: 衡量超级计算机性能的单位,每秒钟的浮点运算次数。1 PFLOPS 等于每秒 10^15 次浮点运算。
1.14 不同计算机上程序运行时间比较
标准定义: 不同计算机主频和体系结构对程序执行时间产生影响,可以通过比较平均CPI和主频来评估不同计算机上程序的运行性能。
通俗解释: 就像不同车辆在不同道路上行驶一样,不同计算机在不同的任务下有着不同的运行速度。通过比较计算机的主频和每条指令所需的平均时钟周期数,我们可以了解到不同计算机的性能差异,就像比较不同车辆在不同道路上的行驶速度一样。
-
主频:
- 解释: 计算机的时钟频率,本题中主频为1GHz,即每秒1×10^9个时钟周期。
-
CPI(Cycles Per Instruction):
- 解释: 每条指令执行所需的平均时钟周期数。本题中,80%的指令执行平均需要1个时钟周期,20%的指令执行平均需要10个时钟周期。因此,CPI = 80% × 1 + 20% × 10 = 2.8。
-
CPU执行时间:
- 解释: 指程序在 CPU 上运行所需的时间。本题中,程序 P 共执行了10000条指令,平均每条指令需要2.8个时钟周期,因此 CPU 执行时间 = (10000 × 2.8) / 10^9 = 28 × 10^-6秒 = 28μs。
第 2 章 总线
2.1 总线带宽计算
-
定义: 总线带宽是指单位时间内总线上传输数据的位数,通常用每秒传送信息的字节数来衡量,单位为 B/s。
-
比喻: 总线带宽就像是一条水管,它表示这条水管每秒能够输送多少水(数据)。
-
总线周期:
- 解释: 在计算机系统中,总线周期是总线完成一个数据传输周期的时间。本题中,一个总线周期占用2个时钟周期。
-
时钟周期:
- 解释: 在计算机中,时钟周期是由计算机的时钟频率决定的,表示一个时钟脉冲的时间长度。本题中,总线时钟频率为10MHz,即每秒钟有10^7个时钟周期。
-
总线带宽:
- 解释: 单位时间内总线上传输数据的位数,通常用每秒传送信息的字节数来衡量。单位为 B/s。在本题中,通过总线传输的数据为4字节,因此总线带宽为[ \frac{4 \text{字节}}{2 \times \frac{1}{\text{总线时钟频率}}} ],计算结果为20MB/s。
2.2 总线标准
-
定义: 总线标准是连接计算机内部各部件的规范,常见的有PCI、EISA、ISA、PCI-Express等。
-
比喻: 总线标准就像是计算机内各个设备使用的插头,不同的设备需要匹配相应的插头才能连接。
-
PCI(Peripheral Component Interconnect):
- 解释: PCI 是一种用于连接计算机内部扩展设备的标准总线。它定义了插槽和卡的物理和电气特性,允许多种设备,如显卡、网卡和存储控制器等,连接到计算机主板。
-
CRT:
- 解释: CRT 是阴极射线管(Cathode Ray Tube)的缩写,是一种传统的显示器技术,使用电子束在荧光屏上生成图像。
-
USB(Universal Serial Bus):
- 解释: USB 是一种通用的外部设备连接标准,用于连接计算机与各种外部设备,如打印机、键盘、鼠标和移动存储设备等。
-
EISA(Extended Industry Standard Architecture):
- 解释: EISA 是一种用于连接计算机内部扩展设备的总线标准。它是 ISA 的扩展版本,提供了更高的性能和更多的插槽,适用于需要更多带宽和更大系统容量的应用。
-
ISA(Industry Standard Architecture):
- 解释: ISA 是一种早期的计算机总线标准,用于连接计算机内部的扩展设备,如插卡。ISA 总线已被后来的标准所取代,但在历史上扮演了重要角色。
-
CPI(Cycles Per Instruction):
- 解释: CPI 是衡量计算机指令执行效率的指标,表示每条指令执行所需的平均时钟周期数。
-
VESA(Video Electronics Standards Association):
- 解释: VESA 是一个组织,致力于推动和制定视频电子标准。在计算机领域,VESA 规范通常涉及显示器和图形标准,确保兼容性和互操作性。
-
SCSI(Small Computer System Interface):
- 解释: SCSI 是一种用于连接计算机和外部设备(如硬盘、打印机)的接口标准,提供了高性能和可靠性。
-
RAM(Random Access Memory):
- 解释: RAM 是一种计算机内存类型,用于临时存储正在使用的数据和程序。RAM 允许快速读写,但是在断电时会丢失存储的信息。
-
MIPS(Million Instructions Per Second):
- 解释: MIPS 是衡量计算机性能的指标,表示每秒执行的百万条指令数。
2.3 数据线上的信息传输
-
传输信息: 在系统总线的数据线上可能传输指令、操作数、中断类型号。
-
比喻: 数据线就像是计算机内部的高速道路,通过这条道路可以传输不同类型的信息。
-
指令:
- 解释: 在计算机系统中,指令是由控制单元传递到执行单元,以执行特定操作的信息。在总线上,指令是通过数据线传输的。
-
操作数:
- 解释: 操作数是指计算机指令中的数据,用于执行算术或逻辑操作。在总线上,操作数也是通过数据线传输的。
-
握手(应答)信号:
- 解释: 握手信号通常是指在通信过程中的确认信号,用于确保数据的正确传输。在系统总线的数据线上,握手信号不是直接的数据传输,而是控制信号,用于确认接收或发送数据的状态。
-
中断类型号:
- 解释: 中断类型号是在发生中断时识别中断的类型的信息。它通常作为数据传输到数据总线上,以通知中断处理程序有关中断的详细信息。
2.4 同步总线的数据传输
-
特性: 同步总线采用同一个时钟信号进行通信,但一次总线事务不一定在一个时钟周期内完成。
-
比喻: 同步总线的通信方式就像是在一个音乐会上,乐队成员统一在同一个指挥的节奏下演奏,但不是每个乐器都在每个拍子响应。
-
同步总线:
- 解释: 同步总线是在系统中通过时钟信号同步各个部件的总线。它使用统一的时钟信号来协调数据的传输,确保各个部件的操作是同步的。
-
时钟频率:
- 解释: 时钟频率是指在单位时间内时钟信号的振荡次数。对于同步总线,时钟频率决定了数据传输的速度。
-
宽度为 32 位:
- 解释: 总线的宽度表示每个时钟周期传输的位数。在这里,总线宽度为 32 位,即每个时钟周期可以传输 32 位的数据。
-
地址/数据线复用:
- 解释: 地址/数据线复用表示在总线上,同一根线既可以传输地址信息,也可以传输数据信息。这种技术能够减少总线的数量,提高系统的效率。
-
猝发传输方式:
- 解释: 突发传输方式是指在进行数据传输时,可以连续传送一系列相邻地址的数据,而不需要每次都进行独立的地址传输。
根据题目的信息,总线的时钟频率为 100MHz,宽度为 32 位,地址/数据线复用,每传输一个地址或数据占用一个时钟周期。因此,传送 128 位数据所需的时间为 40ns(4个时钟周期),加上传送地址的时间 10ns,总共为 50ns。
2.5 USB总线特性
-
特性: USB支持即插即用、热拔插,连接多个外设,是一种串行通信总线。
-
比喻: USB就像是计算机的多功能插线板,可以方便地连接各种外设,而且支持即插即用。
-
USB(通用串行总线):
- 解释: USB 是一种用于连接计算机和外部设备的串行总线标准。它具有即插即用、热插拔、可级联连接多个外设的特点。
-
即插即用和热拔插:
- 解释: 即插即用是指插入设备后系统无需重新启动即可自动识别并配置设备。热插拔是指在系统运行时可以插入或拔出设备而不影响系统的正常工作。
-
通过级联方式连接多台外设:
- 解释: USB 支持通过级联方式连接多个外部设备,形成菊花链状的连接结构。这使得用户可以方便地连接多个设备而无需扩展插槽。
-
通信总线,连接不同外设:
- 解释: USB 是一种通信总线,可以连接各种不同类型的外部设备,包括打印机、键盘、鼠标、摄像头等。
-
同时可传输 2 位数据,数据传输率高:
- 解释: 此选项描述错误。USB 是串行总线,每个时钟周期传输一位数据,而不是同时传输两位。USB 2.0 的最高传输速率是 480Mb/s。
2.6 设备互连接口标准
-
连接口标准: 常见的设备互连接口标准有PCI、USB、AGP、PCI-Express等。
-
比喻: 设备互连接口标准就像是计算机的多个门,每个门对应一种连接方式,不同设备通过相应的门进入计算机。
-
PCI(Peripheral Component Interconnect):
- 解释: PCI 是一种用于计算机内部设备(如网卡、声卡等)和主板之间连接的标准接口。它是一种通用的、并行的接口标准。
-
USB(Universal Serial Bus):
- 解释: USB 是一种用于连接计算机与外部设备之间的串行总线标准。它支持即插即用、热插拔,并连接各种不同类型的外部设备,例如打印机、键盘、鼠标等。
-
AGP(Accelerated Graphics Port):
- 解释: AGP 是一种专门用于连接图形卡(显卡)与主板之间的接口标准,用于提高图形数据传输的速度。
-
PCI-Express(Peripheral Component Interconnect Express):
- 解释: PCI-Express 是 PCI 标准的一种演进,用于高速数据传输,常用于连接图形卡、硬盘、网络卡等。
2.7 总线频率和带宽计算
-
计算方法: 总线带宽 = 数据位数 × 时钟频率 × 2(考虑上升沿和下降沿)。
-
比喻: 总线频率和带宽的计算就像是计算车道上车辆通过的速度,取决于每辆车的宽度和通过的频率。
总线带宽: -
解释: 总线带宽是指总线在单位时间内传输的数据位数,通常以比特率或字节率表示。在这个上下文中,是指在每秒内通过总线传输的数据量。
-
计算: 数据线有32根,每个时钟周期传送两次数据,总线时钟频率为66MHz。因此,总线每秒传送的最大数据量为:32根数据线 * 2次/周期 * 4字节/次 * 66M周期/秒 = 528MB/s。
2.8 总线事务方式
- 突发传输: 一次总线事务中,主设备给出一个首地址,从设备可以连续读取或写入多个数据。
- 比喻: 突发传输就像是在超市购物一样,一次办理事务,可以顺序选购多个商品。
并行传输(Parallel Transfer):
并行传输是一种数据传输方式,其中多个数据位同时在设备之间进行传输。在并行传输中,每个时钟周期都可以传输多个比特的数据,相较于串行传输,它在同一时刻能够传输更多的信息。并行传输常用于内部总线或设备之间的高速数据传输,例如在计算机系统中,内存和处理器之间的数据通常采用并行传输。
串行传输(Serial Transfer):
串行传输是一种数据传输方式,其中数据的二进制代码按照时间顺序逐位传输,每个时钟周期传输一个比特。相对于并行传输,串行传输减少了线缆数量和复杂性,但在同一时刻传输的信息量较少。串行传输常用于长距离通信、外部设备连接和高速通信领域。
突发传输(Burst Transfer):
突发传输是一种总线事务方式,其中主设备只需提供一个首地址,从设备就能顺序读取或写入从该首地址开始的若干连续单元的数据。这种方式能够有效地利用总线的带宽,减少地址传输的开销,提高数据传输效率。突发传输常用于缓存和内存之间的数据传输,有助于提高系统的性能。
同步传输(Synchronous Transfer):
同步传输是指在数据传输过程中,传输过程由统一的时钟信号控制,以确保发送和接收之间的同步。同步传输可以通过在数据线上使用同步时钟信号来协调发送和接收端的数据传输,确保它们在相同的时间间隔内进行。这有助于提高数据传输的稳定性和可靠性。在串行通信中,同步传输是一种常见的方式。
2.9 总线定时
- 异步通信: 异步通信中,全互锁协议较慢,非互锁协议可靠性较差。
- 比喻: 异步通信就像是在沟通时,有些人可能需要等待对方回应,而有些人则不等对方回应直接进行下一步操作。
总线定时:
总线定时是指在计算机系统中,设备之间的数据传输需要在一定的时间序列中进行,以确保数据的可靠传输。在计算机中,总线定时涉及到异步通信、同步通信、互锁协议等概念。以下是对相关专业名词的简要解释:
-
异步通信方式(Asynchronous Communication):异步通信是一种不使用时钟信号进行同步的通信方式。通信的开始和结束由特定的起始位和停止位标识,而数据的传输速率不受全局时钟的控制。
-
同步通信方式(Synchronous Communication):同步通信是一种使用统一时钟信号进行同步的通信方式。通信的发送和接收都依赖于一个全局的时钟信号,确保设备之间在同一时钟周期内进行数据传输。
-
互锁协议(Handshaking Protocol):互锁协议是一种确保通信双方同步进行的协议。在通信的不同阶段,设备之间通过握手信号进行交互,以确保数据的正确传输。在异步通信中,全互锁协议要求通信的发送和接收在一定的顺序和时序中进行,而非互锁协议的可靠性较差,因为没有严格的互锁要求。
-
半同步通信方式:半同步通信方式结合了异步和同步通信的特点。通信的开始和结束由异步的起始位和停止位标识,但数据的传输速率受到同步时钟的控制。在半同步通信中,握手信号的采样由同步时钟控制。
总线定时的选择对于计算机系统的性能和可靠性都具有重要影响,因此在设计和配置计算机系统时需要谨慎考虑。
2.10 总线设计原则
-
原则: 并行总线和串行总线、信号线复用、突发传输和分离事务通信方式。
-
比喻: 总线设计原则就像是建筑设计的原则,考虑到不同的需求和材料,选择合适的设计方案。
总线设计: -
并行总线:并行总线是指同时传送多位数据的总线。每根线上可以传送一个二进制位,通常用于在短距离内高速传输大量数据。虽然在某些情况下速度更快,但在高时钟频率下可能面临相互干扰等问题。
-
串行总线:串行总线是指逐位传送数据的总线,每次传送一个二进制位。串行总线由于导线较少,对线间干扰的控制较容易,因此在高时钟频率下能够提供较高的传输速率。
-
信号线复用技术:信号线复用是指一种技术,通过在不同的时间传输不同的信息,可以使用较少的线路传输更多的信息,以节省空间和成本。
-
突发传输方式:突发传输是在一个总线周期内,可以传输多个存储地址连续的数据,一次传输一个地址和一批地址连续的数据,有助于提高总线数据传输率。
-
分离事务通信方式:分离事务通信是一种总线复用的方式,通过将不同的通信事务分离,可以提高总线的利用率。这种方式可通过有效地利用总线上的时间片来传输多个事务。
在总线设计中,选择适当的传输方式和技术取决于系统的需求和设计目标。
2.11 多总线结构
-
连接原则: 靠近CPU的总线速度较快,存储器总线支持突发传送方式。
-
比喻: 多总线结构就像是城市交通规划,为了提高效率,靠近城市中心的道路需要更宽,而高速公路需要支持连续高速流通。
多总线结构: -
靠近 CPU 的总线速度较快:在计算机体系结构中,为了提高性能,通常将速度较快的总线连接到中央处理器(CPU)。这样可以确保高速设备与 CPU 之间的数据传输更加迅速。
-
存储器总线可支持突发传送方式:存储器总线支持一种传输方式,即突发传送。这种方式允许在单个事务中连续传送多个数据单元,从而提高了存储器读写的效率。
-
总线之间须通过桥接器相连:在计算机系统中,不同种类或速度的总线之间通常需要通过桥接器进行连接。桥接器是一种设备,充当不同总线之间的接口,使它们可以协同工作。
-
PCI-Express×16 采用串行传输方式:PCI-Express×16 是一种高速的串行总线标准,其中的“×16”表示支持16个通道。PCIe 使用串行传输,即一次只传输一个位的数据,但通过使用多个通道和高频率,它能够提供很高的数据传输速率。
2.12 总线传输率提升
-
因素: 总线宽度和工作频率对传输率的影响,突发传输和地址/数据线复用的提升效果。
-
比喻: 总线传输率提升就像是提高水管输水速度,可以通过增加管道直径和提高水压来实现。
同步总线数据传输率提升相关专业名词解释: -
总线宽度(I):总线宽度是指在同一时刻可以传输的数据位数。增加总线宽度可以一次传输更多的数据,从而提高数据传输率。
-
总线工作频率(II):总线工作频率是指在单位时间内总线进行数据传输的次数。提高总线工作频率意味着在相同时间内可以进行更多的数据传输,因此有助于提高数据传输率。
-
支持突发传输(III):突发传输是一种在一个总线周期内传输多个存储地址连续的数据的方式。通过支持突发传输,可以在较短的时间内传输更多的数据,提高总线的数据传输效率。
-
地址/数据线复用(IV):地址/数据线复用是指在总线上同时使用一组线来传输地址和数据。这样可以减少总线线数,但并不直接提高传输率。它主要有助于降低系统成本和复杂度。
2.13 存储器总线带宽计算
- 计算方法: 存储器总线总带宽 = 通道数 × 数据宽度 × 工作频率。
- 比喻: 存储器总线带宽计算就像是计算水管的总输水量,取决于水管的数量、直径和水流速度。
-
3 通道存储器总线:计算机中的存储器总线通常分为多个通道,表示可以同时进行多个数据传输通路。3 通道存储器总线指的是具有三个独立通道的存储器总线,有助于提高内存访问性能。
-
DDR3-1333:DDR3(Double Data Rate 3)是第三代双倍数据速率同步动态随机存取存储器的标准。1333 表示内存的工作频率为 1333 兆赫兹,即每秒钟进行 1333 次数据传输。
-
总线宽度为 64 位:指存储器总线在每个时钟周期内传输的数据位数。64 位总线宽度表示每个时钟周期内可以传输 64 位的数据。
-
存储器总线的总带宽:表示在单位时间内通过存储器总线传输的数据量。计算方式是通道数 × 每通道位宽 / 8(转换为字节)× 存储器频率。在这个例子中,总带宽为 3 × 64 / 8 × 1333 MB/s,即 32GB/s。
这些专业名词涉及计算机硬件中与存储器访问和传输速率相关的方面。
2.14 QPI总线带宽计算
- 特性: QPI总线是点对点全双工同步串行总线,每个方向可同时传输20位信息。
- 比喻: QPI总线的特性就像是一对对讲机,可以同时收发信息。
-
QPI 总线:QuickPath Interconnect(QPI)总线是由英特尔推出的一种点对点全双工同步串行总线,用于连接处理器、内存和其他相关芯片。它是一种高速、低延迟的总线架构,通常用于服务器和高性能计算系统。
-
点对点:在总线上,点对点表示连接的两个节点之间直接进行通信,而不是通过共享的总线。QPI 是点对点连接,允许更直接、高效的数据传输。
-
全双工:在全双工通信中,设备可以同时发送和接收信息,而不需要切换模式。QPI 总线支持全双工通信,这意味着连接的设备可以同时进行双向数据传输。
-
同步串行总线:同步串行总线是一种通过在发送和接收设备之间协调时钟信号来同步数据传输的总线。QPI 是同步串行总线,其数据传输在时钟信号的同步下进行。
-
总线带宽:总线带宽是指在单位时间内通过总线传输的数据量。它通常以字节每秒(B/s)或吉比字节每秒(GB/s)为单位。在这个例子中,总线带宽是通过 QPI 总线传输的数据量,计算方式为每秒传送次数乘以每次传送的位数,再除以 8 转换为字节。
以上是 QPI 总线相关术语的解释,涉及计算机体系结构中处理器之间通信的高速总线。
2.15 总线概念辨析
- 定义和作用: 总线是在两个或多个设备之间进行通信的传输介质。
- 比喻: 总线就像是城市的交通
- 通信介质: 总线是在两个或多个设备之间进行通信的传输介质。
- 比喻: 总线就像是城市的交通网络,连接着各个部分,使得信息能够自由流动。
关于总线的相关专业名词解释:
-
总线(Bus):在计算机体系结构中,总线是连接计算机内部各个组件(如CPU、内存、I/O设备等)进行数据传输和通信的物理通道或逻辑通道。
-
同步总线:同步总线是一种通过共享时钟信号进行数据传输的总线。与时钟同步,但不一定每个总线事务在一个时钟周期内完成。
-
时钟频率:时钟频率是指在同步总线中时钟信号的速率,通常以赫兹(Hz)为单位,表示每秒钟的时钟周期数。
-
工作频率:工作频率是指总线或设备在实际操作中的工作速率。在同步总线中,工作频率可能与时钟频率相同,也可能不同。
-
异步总线:异步总线是一种通过握手信号进行数据传输的总线。通信的双方通过握手信号来同步数据的传输,每次握手过程完成一次数据交换。
-
握手信号:握手信号是在异步总线中用于同步通信的信号。它表示通信的开始、结束或其他状态,确保数据的正确传输。
-
突发传送:突发传送是指在一个总线周期内连续传输多个数据,提高数据传输的效率。在这种情况下,地址和数据之间的传输是连续的。
以上是关于总线的相关专业名词解释,涵盖了同步总线、异步总线、时钟频率、握手信号等与总线通信相关的术语。
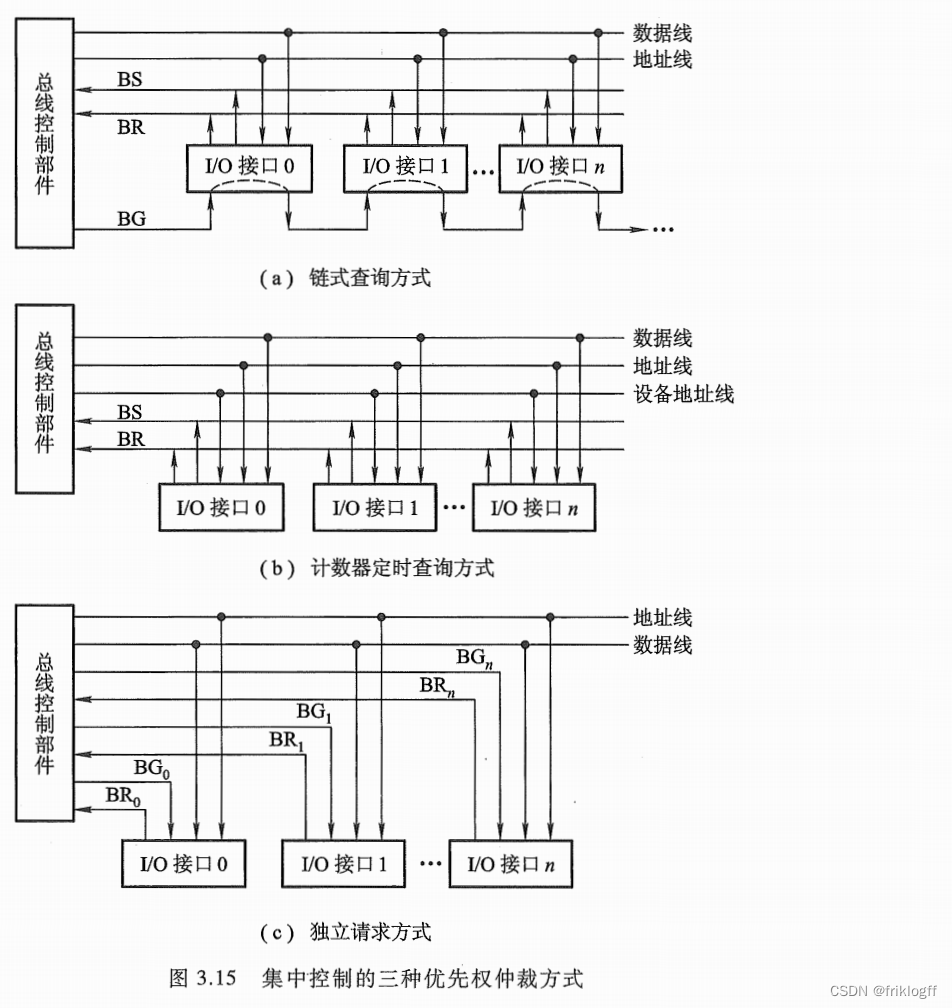
常见的集中控制优先权仲裁方式有以下三种。
(1) 链式查询
链式查询方式如图 3.15(a) 所示。图中控制总线中有 根线用千总线控制 (BS 总线忙、 BR 总线请求、 BG 总线同意),其中总线同意信号 BG 是串行地从一个 I/0 接口送到下一个 I/0 接口。如果 BG 到达的接口有总线请求, BG 信号就不再往下传,意味着该接口获得了总线使用权,并建立总线忙 BS 信号,表示它占用了总线。可见在链式查询中,离总线控制部件最近的设备具有最高的优先级。这种方式的特点是:只需很少几根线就能按一定优先次序实现总线控制,并且很容易扩充设备,但对电路故障很敏感,且优先级别低的设备可能很难获得请求。
(2) 计数器定时查询
计数器定时查询方式如图 3.15 (b) 所示。与图 3.15 (a) 相比,多了一组设备地址线,少了一
根总线同意线 BG 。总线控制部件接到由 BR 送来的总线请求信号后,在总线未被使用 (BS= 0) 的情况下,总线控制部件中的计数器开始计数,并通过设备地址线,向各设备发出一组地址信号。当某个请求占用总线的设备地址与计数值一致时,便获得总线使用权,此时终止计数查询。这种方式的特点是:计数可以从 “0“ 开始,此时一旦设备的优先次序被固定,设备的优先级就按0, 1, …, 的顺序降序排列,而且固定不变;计数也可以从上一次计数的终止点开始,即是一种循环方法,此时设备使用总线的优先级相等;计数器的初始值还可由程序设置,故优先次序可以改变。这种方式对电路故障不如链式查询方式敏感,但增加了控制线(设备地址)数,控制也较复杂。
(3) 独立请求方式
独立请求方式如图 3.15( c) 所示。由图中可见,每一台设备均有一对总线请求线 BR; 和总线同意线 BGi 。当设备要求使用总线时,便发出该设备的请求信号。总线控制部件中有一排队电路,可根据优先次序确定响应哪一台设备的请求。这种方式的特点是:响应速度快,优先次序控制灵活(通过程序改变),但控制线数量多,总线控制更复杂。链式查询中仅用两根线确定总线使用权属千哪个设备,在计数器查询中大致用 log2n 根线,其中 是允许接纳的最大设备数,而独立请求方式需采用 2n 根线。
第 3 章 存储器
3.1 存储器类型
3.1.1 随机存取方式
标准定义: 存储器访问方式,允许直接访问任意位置的存储单元。
通俗解释: 就像翻开一本书,可以直接阅读任意一页,无需按顺序一页一页翻阅。
-
EPROM(可擦除可编程只读存储器):EPROM是一种只读存储器,存储的数据在写入后可以被擦除和重新编程。它采用随机存取方式,允许CPU随机读取或写入其中的数据。
-
CD-ROM(只读光盘):CD-ROM是一种只读存储器,数据通常由光学方式读取。与随机存取不同,CD-ROM采用串行存取方式,数据按照光盘上的物理顺序顺序读取。
-
DRAM(动态随机存取存储器):DRAM是一种随机存取存储器,用于临时存储正在使用的数据和程序。它需要定期刷新以保持存储的数据,采用随机存取方式。
-
SRAM(静态随机存取存储器):SRAM也是一种随机存取存储器,与DRAM不同,它的存储单元不需要刷新操作。SRAM提供更快的访问速度,但通常比DRAM更昂贵。
在给定的选项中,CD-ROM 是不采用随机存取方式的存储器。
3.1.2 存储器类型解释
-
EPROM(可擦除可编程只读存储器):
- 标准定义: 非易失性存储器,需要特殊操作才能擦除和重新编程。
- 通俗解释: 类似于一次写入的电子板书,如果需要修改,必须使用特殊工具。
-
CD-ROM(只读光盘存储器):
- 标准定义: 只读存储介质,常用于光盘存储。
- 通俗解释: 就像一张不能改写的光盘,只能读取里面的信息,无法在上面写入新的内容。
-
DRAM(动态随机存取存储器):
- 标准定义: 易失性存储器,使用电容存储数据,需要定期刷新。
- 通俗解释: 类似于水桶,需要不断加水(刷新)来保持水的存在(数据)。
-
SRAM(静态随机存取存储器):
- 标准定义: 易失性存储器,不需要刷新,但相对较昂贵。
- 通俗解释: 像一个打开的书,无需不断翻页(刷新),但成本较高。
3.2 RAM 和 ROM 特性
3.2.1 RAM:易失性存储器,采用随机存取方式
标准定义: 随机存取存储器,是一种易失性存储器,允许随机访问存储单元。数据不断电时会丢失。
通俗解释: 就像一张白板,可以随意写上内容,但关掉电源后,内容会消失。
3.2.2 ROM:非易失性存储器,可用于 Cache,不需要刷新
标准定义: 只读存储器,是一种非易失性存储器,通常用于存储固定数据。可用于Cache,不需要刷新操作。
通俗解释: 类似于一本印刷好的书,内容固定,可以反复阅读而不会改变。
-
RAM(随机存取存储器):一种计算机主存储器,可实现对存储单元的随机读写。RAM是易失性存储器,其内容在断电时会丢失。主要分为动态RAM(DRAM)和静态RAM(SRAM),前者需要刷新以保持数据,而后者则不需要。
-
ROM(只读存储器):一种存储固定数据或程序的计算机存储器,其内容在正常操作中只能被读取,不能被随机写入。ROM是非易失性存储器,保持存储内容即使在断电的情况下。
-
Cache(缓存):一种高速临时存储器,用于存储计算机处理器经常访问或可能需要的数据,以提高数据访问速度。Cache通常分为多级,包括一级缓存(L1 Cache)和二级缓存(L2 Cache)。SRAM常用于制造Cache,因为它提供了更快的读写速度。
-
DRAM(动态随机存取存储器):一种随机存取存储器类型,它使用电容来存储每个位的数据。DRAM需要定期刷新,以防止电容电荷消失,这使得它相对于SRAM来说更经济,但速度较慢。
-
SRAM(静态随机存取存储器):一种随机存取存储器类型,它使用触发器电路来存储每个位的数据。相对于DRAM,SRAM速度更快,但成本更高,通常用于高速缓存和其他需要快速访问的应用。
3.3 闪存特性
3.3.1 可读可写,速度较慢
标准定义: 一种可读可写的非易失性存储器,相比RAM速度较慢。
通俗解释: 像一块橡皮擦,可以写上内容,但擦除和写入速度相对较慢。
3.3.2 采用随机访问方式
标准定义: 闪存采用随机访问方式,允许直接访问任意存储位置。
通俗解释: 类似于书页,可以直接翻到需要的部分,而不必一页一页过。
3.3.3 非易失性存储器
标准定义: 与RAM不同,闪存是一种非易失性存储器,数据在断电时仍然保持。
通俗解释: 像一块磁性板,数据不会因为断电而消失。
闪存(Flash Memory)
闪存是一种半导体存储器,属于非易失性存储器(NVM)。它以其高速度、低能耗和耐用性而受到广泛应用。闪存被广泛用于各种电子设备,包括移动设备、相机、USB闪存驱动器、固态硬盘(SSD)等。
特点和属性:
-
可读写性:与只读存储器(ROM)不同,闪存是可读写的,允许对存储的数据进行修改和更新。
-
构成:存储元件通常由金属-氧化物-半导体场效应晶体管(Metal-Oxide-Semiconductor Field-Effect Transistor,MOSFET)组成。数据以电荷的形式存储在浮动栅上。
-
非易失性:闪存是一种非易失性存储器,即使在断电的情况下,存储的数据也能被保留。
-
写入擦除机制:写入操作需要先将存储单元擦除,然后再进行写入。这个擦除-写入机制影响了写入速度,使得写入速度通常较读取速度慢。
-
随机访问:可以通过随机访问方式读取和写入数据,这使得闪存在替代传统磁盘驱动器时成为可能。
应用:
-
移动设备:用于存储操作系统、应用程序和用户数据。
-
固态硬盘(SSD):替代传统机械硬盘,提供更快的读写速度和更高的耐用性。
-
相机和摄像机:用于存储照片和视频。
-
USB闪存驱动器:便携式存储设备,可插入计算机或其他设备以传输和存储数据。
-
嵌入式系统:在嵌入式计算设备中用于存储固件和操作系统。
非易失性存储器(Non-Volatile Memory)
非易失性存储器,简称NVM,是一种在断电后能够保持存储信息的存储技术。与易失性存储器(如RAM)不同,非易失性存储器不需要持续的电源供应来保持存储的数据。这种存储器通常用于长期存储和检索数据,例如闪存、硬盘驱动器和只读存储器(ROM)。
NVM 在计算机系统中扮演重要角色,因为它可以长时间保存存储的数据而无需电源。这对于存储引导程序、操作系统、应用程序和其他关键信息至关重要。其中一些技术包括:
-
闪存(Flash Memory):作为一种非易失性存储器,闪存常用于移动设备、固态硬盘(SSD)和其他需要持久存储的场景。它的特点包括可擦写和可编程的特性。
-
EEPROM(Electrically Erasable Programmable Read-Only Memory):EEPROM是一种可通过电擦除的ROM,可在电路板上进行重新编程。这种存储器常用于存储设备参数、BIOS设置等。
-
硬盘驱动器(Hard Disk Drive,HDD):HDD使用磁盘表面上的磁性涂层存储数据。即使断电,数据仍然保留在盘片上。
-
固态硬盘(Solid State Drive,SSD):SSD使用闪存或其他非易失性存储器技术,提供了与传统硬盘驱动器相似的功能,但速度更快且更耐用。
非易失性存储器在计算机体系结构、嵌入式系统和各种电子设备中发挥着关键作用。
3.4 存储器芯片地址与数据引脚
3.4.1 地址引脚数:log2(4M) = 22
标准定义: 存储器芯片的地址引脚数计算公式为log2(存储容量),对于4兆比特的存储器,地址引脚数为22。
通俗解释: 就像一个房间有多少个门,能决定进入房间的位置。
3.4.2 数据引脚数:8
标准定义: 存储器芯片的数据引脚数为8,表示每次可以传输8位数据。
通俗解释: 像一次能搬运的货物数量,每次可以传输8个单位的数据。
地址引脚和数据引脚
在计算机存储器的设计中,地址引脚和数据引脚是两个关键的概念,它们用于连接计算机系统的主板(或其他处理器)与存储器设备,以实现对存储器中数据的读写操作。
1. 地址引脚:
- 定义: 地址引脚是用于传递访问存储器时所需地址信息的电脑接口或插头上的引脚。
- 作用: 当计算机需要读取或写入存储器中的数据时,通过地址引脚传递目标存储单元的地址,使得系统能够准确地定位到所需的存储单元。
- 示例: 如果一个存储芯片有 n 个地址引脚,它可以寻址 2^n 个存储单元。
2. 数据引脚:
- 定义: 数据引脚是用于传输实际数据(比特位)的电脑接口或插头上的引脚。
- 作用: 数据引脚负责在计算机和存储器之间传递二进制数据,实现数据的读取和写入操作。
- 示例: 如果一个存储芯片有 m 个数据引脚,每次传输的数据位数为 m 位,可以通过这些引脚同时传输 m 位的数据。
相关概念:
- 地址线和数据线复用: 在一些存储器设计中,为了减少引脚数量,地址线和数据线可能会进行复用。这意味着同一根引脚在不同的时刻既可能用于传递地址信息,又可能用于传递数据信息。
- 动态随机存取存储器(DRAM): 是一种常见的存储器类型,其内部由电容构成,数据存储在电容中。DRAM的地址引脚和数据引脚的数量取决于具体的芯片设计。
解析题目中的情况:
对于题目中提到的 4M×8 位的 DRAM 芯片,其中 4M 表示存储容量为 4 兆位,8 位表示每个存储单元的位数。根据此信息,可以计算地址引脚和数据引脚的总数。在此例中,地址引脚数目为 log2(4M),而数据引脚数为 8。然后,考虑到 DRAM 采用地址复用技术,因此地址引脚数量实际上是数据引脚数量的一半。因此,总引脚数为地址引脚数加上数据引脚数,即 log2(4M)/2 + 8,根据计算结果,这个总数为 19,因此答案为 A。
动态随机存取存储器(DRAM)
动态随机存取存储器(Dynamic Random Access Memory,DRAM) 是一种计算机主存储器的类型,用于临时存储计算机运行时所需的数据和指令。以下是有关DRAM的专业名词解释:
-
动态性: DRAM之所以称为"动态",是因为它使用电容存储数据,而电容中的电荷会逐渐泄漏。因此,为了保持数据,DRAM需要定期进行刷新(刷新周期),在刷新过程中重新写入数据。
-
随机存取: DRAM允许计算机以随机的方式访问存储单元,而不需要按照顺序或地址顺序进行访问。这使得它成为主要内存(RAM)的理想选择,因为它可以快速随机读取或写入数据。
-
存储单元: DRAM存储信息的基本单元是存储单元,通常由一个电容和一个晶体管组成。电容负责存储电荷,晶体管则充当开关,用于读取和写入电荷。
-
刷新周期: 由于电容泄漏的特性,DRAM需要定期进行刷新操作以防止数据丢失。刷新周期是指DRAM芯片执行刷新操作的时间间隔,通常以毫秒为单位。
-
地址复用: DRAM采用地址复用技术,其中同一组地址线在不同时间传递不同的地址信息。这减少了所需的引脚数量,提高了存储器的效率。
-
位和字: DRAM以位(bit)为单位进行寻址和存储,而多个位组合形成字节。例如,一个8位的DRAM表示每个存储单元存储8个二进制位,组成一个字节。
-
存储容量: DRAM的存储容量通常以位或字节为单位进行度量,例如4M×8表示4兆位的DRAM,每个存储单元存储8位,总数据位数为32兆位。
总体而言,DRAM是一种常见的主存储器技术,尽管其需要定期刷新和相对较慢的速度,但由于其高密度和相对低成本,它被广泛用于个人电脑和其他计算设备中。
3.5 存储器刷新
3.5.1 SDRAM 需要周期性刷新
标准定义: SDRAM(同步动态随机存取存储器)需要周期性刷新以保持存储的数据有效。
通俗解释: 就像植物需要定期浇水一样,SDRAM需要定期刷新以保持数据的保存。
SRAM、SDRAM、ROM 和 Flash 的专业名词解释:
-
SRAM(Static Random Access Memory): SRAM是一种静态随机存取存储器。与动态存储器(如DRAM)不同,SRAM的存储单元使用触发器电路来存储每个位,而不需要定期刷新。这使得SRAM访问速度相对较快,但它通常比DRAM更昂贵,且密度较低。
-
SDRAM(Synchronous Dynamic Random Access Memory): SDRAM同样是一种动态随机存取存储器,但它与系统时钟同步运行。它的同步性允许更高效的数据传输,并且与现代计算机系统更好地协同工作。SDRAM通常用作主内存,提供了较高的存储密度和性能。
-
ROM(Read-Only Memory): ROM是一种只读存储器,其中存储的数据在常规操作中不可更改。ROM通常用于存储固件、启动代码和其他需要保持不变的信息。与RAM不同,ROM通常是非易失性的,即使在断电情况下也能保持存储的数据。
-
Flash Memory: Flash存储器是一种非易失性存储器,类似于ROM,但它通常可以进行可擦写和可编程操作。Flash存储器被广泛用于各种设备,包括USB驱动器、固态硬盘(SSD)和移动设备。Flash存储器的主要特点是能够进行多次擦写和编程,使其适用于需要频繁更新的应用。
综上所述,每种存储器类型都有其独特的特性和应用场景。 SRAM和SDRAM用于主内存,提供快速的读写访问。 ROM用于存储不变的数据,而Flash存储器结合了可擦写和非易失性的特性,适用于需要灵活性和可编程性的应用。
3.6 存储器交叉编址
3.6.1 四体交叉编址规则
标准定义: 存储器地址分配规则,通过四个体(bank)交叉编址以提高访问效率。
通俗解释: 就像将书籍分布在四个书架上,以加速查找和阅读的效率。
3.6.2 可能发生访存冲突的判断
标准定义: 在四体交叉编址中,需要判断是否可能发生访存冲突,以确保数据的正确读写。
通俗解释: 类似于在四个货架上寻找物品时,需要确认是否可能发生碰撞,以防止混淆物品位置。
-
四体交叉编址存储器: 这是一种存储器的组织方式,其中存储器的地址空间被划分为四个模块,通常用于提高存储器的访问速度。在这种架构下,相邻的四个存储单元分别属于四个模块,通过循环方式对这四个模块进行交叉编址。
-
访存冲突: 在多体交叉编址存储器中,如果两个或多个地址映射到相同的模块,并且这些地址在相邻的存储周期内被访问,就可能导致访存冲突。访存冲突可能导致存储器的访问效率下降。
-
存储模块: 存储器被划分为多个模块,每个模块具有一定的地址范围。在四体交叉编址存储器中,有四个存储模块,每个模块负责处理地址空间的四分之一。
-
模块序号: 每个访存地址对应的存储模块的编号。根据地址对模块数取余的方式计算模块序号。
-
地址交叉模块数: 存储器被划分的模块数量,这里是四个。用于计算模块序号的取余操作。
在给定的问题中,通过四体交叉编址存储器的模块划分和模块序号计算规则,判断可能发生访存冲突的地址对。
3.7 存储器突发传送
3.7.1 64位总线,8个8192×8192×8位的DRAM芯片
标准定义: 存储器突发传送通过64位总线,同时访问8个8192×8192×8位的DRAM芯片,提高数据传输效率。
通俗解释: 好比一次性搬运多个货物,通过宽敞的通道(64位总线)同时访问多个存储单元。
3.7.2 行缓冲区的作用
标准定义: 行缓冲区用于暂存存储器中的一行数据,以加速存储器突发传送过程。
通俗解释: 就像在搬运货物时,先将一整排货物暂时放在一个区域,以提高搬运效率。
-
主存按字节编址: 这表示计算机的主存储器中的每个字节都被分配一个唯一的地址。主存的寻址是按字节为单位进行的。
-
DRAM(Dynamic Random-Access Memory): DRAM 是一种动态随机存取存储器,用于临时存储数据和机器码。在题目中,指的是存储器中的芯片采用 DRAM 架构。
-
交叉编址方式: 这是一种存储器组织方式,将主存划分为多个模块,然后按照某种规律对这些模块进行交叉编址,以提高访问速度。
-
存储器总线: 连接计算机主存储器和其他组件的总线,用于在计算机各部件之间传输数据。
-
宽度为 32 位的存储器总线: 存储器总线的宽度表示在一次操作中可以传输的位数。这里是指每次可以传输 32 位数据。
-
存储周期数: 读取或写入一个数据所需的存储周期的数量。存储周期数取决于存储器的组织结构和数据的大小。
-
double 型变量: 在C语言中,double 是一种双精度浮点数类型,通常占用 64 位(8 字节)的存储空间。
在给定的问题中,主要考察了主存的组织方式(交叉编址)、存储器总线的宽度、DRAM 的存储结构,以及读取 double 型变量所需的存储周期数的计算。
3.8 存储器设计
3.8.1 ROM和RAM的数量计算
标准定义: 存储器设计时需要计算所需的ROM和RAM数量,以满足系统需求。
通俗解释: 类似于规划图书馆,确定需要多少书籍(ROM)和笔记本(RAM)以适应读者需求。
3.8.2 主存地址寄存器(MAR)的位数计算
标准定义: 主存地址寄存器(MAR)的位数需根据存储器的地址引脚数计算,以确保正确寻址。
通俗解释: 就像门牌号需要足够的位数以确保能够准确找到每个房间,MAR的位数也需要足够以准确访问存储器。
-
突发传送方式(Burst Transfer): 这是一种存储器访问方式,其中在请求一个地址后,接下来的若干个数据项也被连续传输。这有助于提高内存访问的效率,减少访问延迟。
-
存储器总线宽度: 存储器总线宽度是指在一次存储器访问中可以同时传输的位数。64位的存储器总线宽度表示每次可以传输64位数据。
-
多模块交叉编址方式: 这是一种存储器的组织方式,通过多个存储模块以某种规律进行交叉编址,以提高整体存储器系统的访问速度。
-
地址引脚: 每个存储芯片的地址引脚数表示该芯片可以寻址的地址数量,通常用来计算地址线的位数。
-
行缓冲区(Row Buffer): 这是DRAM芯片内部的一部分,用于存储最近访问的行的数据。它的存在可以加速对同一行数据的连续访问。
在给定的问题中,对内存条的叙述进行了多方面的考察,包括存储器容量、交叉编址方式、地址引脚数、以及芯片内部的行缓冲区。最后一项是指向选项的修正,指出芯片内的行缓冲区长度为一行的大小。
3.9 存储器地址计算
3.9.1 地址范围的划分
标准定义: 存储器地址的范围需要划分,以便有效地管理数据。
通俗解释: 就像将城市划分为不同的区域,以方便管理和寻找地址。
3.9.2 存储器容量的计算
标准定义: 计算存储器的容量时需要考虑地址位数,以确保足够的存储空间。
通俗解释: 像计算一个房子有多少个房间,考虑地址位数以确保足够的空间来存放物品。
-
ROM(Read-Only Memory): ROM是只读存储器,其内容在正常条件下不能被修改或写入。在计算机系统中,ROM通常用于存储固件、启动程序等不需要频繁修改的数据。
-
RAM(Random Access Memory): RAM是随机存取存储器,允许随机读写存储单元的数据。与ROM不同,RAM是易失性存储器,意味着其内容在断电时会丢失。
-
字节编址: 存储器的字节编址方式是指每个存储单元都有一个唯一的地址,这个地址按照字节为单位递增。
-
2K×8位的 ROM 芯片: 这表示ROM芯片的容量为2K字节,每个字节有8位。类似地,4K×4位的RAM芯片表示RAM芯片的容量为4K字节,每个字节有4位。
-
字扩展: 字扩展是指在设计存储器时,将存储器的地址线扩展到更高的位数,以适应更大容量的存储器。这里指的是将2K×8位的ROM芯片通过字扩展适应4KB的ROM区。
-
位同时扩展: 位同时扩展是指在设计存储器时,将存储器的数据线扩展到更多的位数,以适应更大的数据容量。这里指的是将4K×4位的RAM芯片通过位同时扩展适应60KB的RAM区。
在给定的问题中,解释了ROM、RAM的基本概念,字节编址方式以及字扩展和位同时扩展的概念。最后,根据题意计算了所需的ROM芯片数和RAM芯片数。
3.10 存储器字节编址
3.10.1 不同位数的芯片组合
标准定义: 在存储器字节编址中,需要考虑不同位数的芯片如何组合,以满足系统需求。
通俗解释: 就像在拼图时,需要考虑不同形状的拼图如何组合在一起。
3.10.2 地址计算规则
标准定义: 制定存储器字节编址的地址计算规则,确保准确访问数据。
通俗解释: 类似于通过地图上的规则来计算两个地点之间的距离,确保能够准确找到需要的数据。
-
地址 0B1FH: 这是一个十六进制地址,表示存储器中的一个特定地址。在这个问题中,该地址被用来确定存储器中某个数据所在的位置。
-
2K×4位的芯片: 这表示每个芯片的容量为2K字节,每个字节有4位。这种记法通常表示存储器的行和列的大小。
-
8K×8位的存储器: 这表示整个存储器的容量为8K字节,每个字节有8位。这种记法通常表示存储器的总体大小和每个地址存储的数据位数。
-
最小地址: 这是指在一个特定行中,由若干芯片组成的存储器中,该行中芯片的最小地址。在这里,问题涉及将多个2K×4位的芯片组成8K×8位的存储器。
在给定的问题中,解释了十六进制地址的表示,2K×4位的芯片和8K×8位的存储器的概念。然后,通过计算确定了地址0B1FH所在芯片的最小地址。
3.11 存储器地址寄存器位数
3.11.1 主存大小与地址寄存器位数的关系
标准定义: 计算主存大小与地址寄存器位数之间的关系,以满足系统的寻址需求。
通俗解释: 就像确保有足够多的门牌号以容纳整个城市的房子,地址寄存器位数要足够大以正确定位主存中的数据。
-
主存储器(RAM): 主存储器是计算机中用于存储数据和程序的内存部分。在这个问题中,采用了4M×8位的RAM芯片组成主存储器。
-
按字节编址: 这表示计算机主存储器中的每个地址都对应一个字节。字节是计算机中最小的可寻址存储单元。
-
主存地址空间: 这是指计算机中主存储器所有可能地址的范围。在这个问题中,主存地址空间大小为64MB。
-
存储器地址寄存器(MAR): 存储器地址寄存器是一个用于存储将要访问的存储器地址的寄存器。在这里,问题涉及到计算MAR的位数,以确定其寻址范围。
-
位数: 在计算机中,"位"通常表示二进制位数,用于表示地址或数据的长度。MAR的位数表示它能够寻址的不同地址数量。
在这个问题中,MAR的位数至少需要26位,以确保它能够寻址64MB的主存地址空间。这涉及到了计算机内存的寻址范围和地址位数的关系。
3.12 存储器设计与芯片数量
3.12.1 64KB容量的存储器设计
标准定义: 设计满足64KB容量需求的存储器,并确定所需的芯片数量。
通俗解释: 类似于规划一个64KB容量的书库,确定需要多少书架(芯片)以存放所有的书籍。
3.12.2 SRAM芯片数量的计算
标准定义: 计算构建SRAM存储器所需的芯片数量,以满足系统性能和容量的要求。
通俗解释: 像计算建造一个带有高级功能的学习区,确定需要多少书桌(SRAM芯片)以满足学生的需求。
-
SRAM(Static Random-Access Memory): SRAM是一种静态随机存取存储器,它能够在不断电的情况下保持存储的数据。与DRAM(动态随机存取存储器)相比,SRAM不需要刷新操作,但相对来说更昂贵。
-
按字节编址: 这表示计算机主存储器中的每个地址都对应一个字节。字节是计算机中最小的可寻址存储单元。
-
ROM(Read-Only Memory): ROM是只读存储器,其中存储的数据在正常操作中不能被修改或写入。在这个问题中,地址范围为4000H到5FFFH的区域被分配给ROM。
-
RAM(Random-Access Memory): RAM是一种随机存取存储器,其中的数据可以随时读取和写入。在这个问题中,除了ROM区域外的其余区域被分配给RAM。
-
地址范围: 这表示在计算机存储器中,可以用来唯一标识不同存储单元的地址的范围。
在这个问题中,通过计算ROM和RAM的容量需求,确定了所需的8K×4位的SRAM芯片数量为14。这涉及到计算存储器区域的容量和选择适当大小的存储器芯片。
3.13 DRAM芯片行列设计
3.13.1 最小地址引脚数的选择
标准定义: 在设计DRAM芯片的行列时,选择最小的地址引脚数以降低复杂性。
通俗解释: 就像在设计一个花园,选择最简单的路径以使游客更容易找到目的地。
3.13.2 减小刷新开销的策略
标准定义: 制定减小刷新开销的策略,提高DRAM性能。
通俗解释: 像设计一个自动浇水系统,以减少人工浇水的次数,提高效率。
-
DRAM(Dynamic Random-Access Memory): DRAM是一种动态随机存取存储器,与静态RAM(SRAM)相比,它需要定期刷新以保持存储的数据,因为存储的数据会逐渐消失。DRAM通常用于主存储器。
-
存储阵列: 存储阵列是DRAM芯片中用于存储数据的结构。它通常由行和列组成,以形成一个二维的存储单元数组。
-
行数(r)和列数(c): 在DRAM芯片的存储阵列中,行数和列数表示存储单元的布局。行和列的选择与地址线有关,行和列的交点处存储着一个数据位。在这个问题中,r表示行数,c表示列数。
-
刷新开销: DRAM中的数据存储在电容中,由于电容的自放电特性,需要定期刷新以维持存储的数据。刷新开销是指为了防止数据丢失而进行的刷新操作所带来的性能开销。
在这个问题中,为了最小化地址引脚数并减小刷新开销,选择行和列的值,其中行列差值较小,行数较少,以达到优化地址引脚和减小刷新开销的目的。选项C (32行,64列) 是最符合这些条件的选择。
3.14 存储器总线位数与容量
3.14.1 地址线和数据线的关系
标准定义: 确定存储器总线的位数,确保地址线和数据线之间的兼容性。
通俗解释: 就像确保交通道路足够宽以容纳不同类型的车辆,存储器总线位数要足够宽以传输地址和数据。
3.14.2 RAM芯片数量的计算
标准定义: 计算构建RAM存储器所需的芯片数量,以满足系统容量需求。
通俗解释: 类似于确定一个足够大的停车场,计算需要多少停车位(RAM芯片)以容纳所有车辆。
-
字编址: 字编址是指计算机按字节为单位进行寻址。在这种模式下,每个地址引用一个字节的数据。
-
字长: 字长表示计算机一次能够处理的二进制位数。在这个问题中,字长为32位,即一次可以处理32位的二进制数据。
-
RAM(Random-Access Memory): RAM是一种随机访问存储器,它允许在存储器中直接访问任意位置的数据。RAM通常用于主存储器。
-
RAM芯片容量: RAM芯片容量表示每个RAM芯片能够存储的数据量。在这个问题中,RAM芯片容量为512K×8位,表示每个RAM芯片能够存储512K字节(或4M位)的数据。
根据问题中的地址范围和RAM区的大小,计算出RAM区的总容量。然后,将RAM区的总容量除以每个RAM芯片的容量,得到需要的RAM芯片数量。在这个问题中,需要的512K×8位的RAM芯片数量为32。
3.15 磁盘读取时间
3.15.1 转速、寻道时间、传输速率的影响
标准定义: 分析磁盘读取时间受转速、寻道时间和传输速率等因素的影响。
通俗解释: 像计算到达目的地所需的时间,考虑车辆速度、道路选择以及交通状况等因素。
3.15.2 读取扇区平均时间的计算
标准定义: 通过计算平均读取扇区的时间,评估磁盘性能。
通俗解释: 就像计算一个邮递员平均递送一封信所需的时间,考虑信的数量和投递的距离。
-
磁盘转速: 磁盘转速是指磁盘每分钟旋转的圈数。在这个问题中,磁盘的转速为10000转/分。
-
平均寻道时间: 平均寻道时间是指磁头从磁盘的一个磁道移动到另一个磁道所需的平均时间。在这个问题中,平均寻道时间为6ms。
-
磁盘传输速率: 磁盘传输速率表示从磁盘读取或写入数据的速度。在这个问题中,磁盘传输速率是20MB/s。
-
磁盘控制器延迟: 磁盘控制器延迟是指磁盘控制器处理读取或写入请求所需的时间。在这个问题中,磁盘控制器延迟为0.2ms。
-
扇区: 磁盘存储被划分为小的数据块,每个数据块称为一个扇区。在这个问题中,读取一个4KB的扇区。
基于这些参数,计算平均读取一个4KB扇区的时间,包括寻道时间、旋转延迟、传输时间和控制器延迟。在这个问题中,计算的结果是9.4ms。
3.16 RAID 可靠性提升措施
3.16.1 磁盘镜像
标准定义: 实施磁盘镜像作为提高RAID系统可靠性的一项措施。
通俗解释: 类似于备份重要文件,磁盘镜像是对数据的实时备份,以提高系统可靠性。
3.16.2 条带化
标准定义: 采用条带化技术,提高RAID系统的读写速度。
通俗解释: 就像将书籍分割成条带放置,以同时阅读多本书,提高读写效率。
3.16.3 奇偶校验
标准定义: 应用奇偶校验算法,提供RAID系统的数据冗余和错误检测。
通俗解释: 像用一个备用的拼图块,可以用来纠正其他拼图块中的错误,确保完整的图案。
3.16.4 增加 Cache 机制
标准定义: 引入缓存机制,加速对RAID系统的访问速度。
通俗解释: 类似于提前将需要的书籍放在桌子上,以加快阅读速度。
-
RAID (Redundant Array of Independent Disks): RAID是一种磁盘阵列技术,通过将多个硬盘组合起来,提供更高的性能、容错能力或两者兼而有之。RAID系统可以分为多个级别,如RAID 0、RAID 1、RAID 5等,每种级别都有不同的数据存储和冗余方式。
-
磁盘镜像: RAID 1采用磁盘镜像技术,将数据同时写入两个磁盘,实现数据的冗余备份。如果一个磁盘失效,系统仍然可以通过另一个镜像磁盘提供数据。
-
条带化: RAID 0采用条带化技术,将数据分割成小块,然后分别写入不同的硬盘。这样可以提高数据的读写速度,但没有冗余备份,因此一颗硬盘故障将导致数据丢失。
-
奇偶校验: RAID 3、RAID 4和RAID 5采用奇偶校验技术。这种技术通过在数据块中添加奇偶校验位,使得在某一块磁盘故障时,可以通过其他磁盘上的数据和奇偶校验位来还原数据,从而实现冗余备份。
-
增加Cache机制: 在RAID系统中,增加缓存机制可以提高读写性能。缓存可以用来暂时存储读取或写入的数据,从而加快系统的响应速度。然而,需要注意的是,增加缓存也带来了一定的数据丢失风险,因此通常需要采用电池支持的缓存以防止电源故障时数据的丢失。
3.17 磁盘存取时间计算
3.17.1 存取时间 = 寻道时间 + 延迟时间 + 传输时间
标准定义: 计算磁盘存取时间,考虑寻道时间、延迟时间和传输时间等因素。
通俗解释: 就像计算去商店买东西所需的时间,考虑到找到商品的时间、排队的时间以及支付的时间。
-
平均寻道时间: 磁盘存储器的平均寻道时间是指磁头从当前磁道移动到目标磁道的平均时间。这个时间包括寻道时间和定位时间,寻道时间是将磁头移动到目标磁道上的时间,而定位时间是使磁头精确定位到目标磁道上的时间。
-
扇区: 磁盘上的一个扇区是存储数据的最小单位,通常为512字节或4KB。扇区是磁盘进行数据读写的基本单元,磁盘上的每个磁道被划分为多个扇区,磁头在读写时定位到目标磁道后,通过旋转磁盘来访问特定的扇区。
-
磁盘转速: 磁盘转速是指硬盘磁盘旋转一周的时间,通常以每分钟的转数表示。转速的快慢直接影响到磁盘的读写速度,一般以每分钟转数(RPM,Revolutions Per Minute)来描述。
-
平均存取时间: 磁盘的平均存取时间是指从发出访问请求到获取数据所需的平均时间,它包括了寻道时间、旋转延迟时间和数据传输时间。这是一个评估磁盘性能的重要指标。
在这个问题中,计算平均存取时间时考虑了平均寻道时间、旋转延迟时间和数据传输时间,通过这些时间的累加得到了访问一个扇区的平均存取时间。
3.18 磁盘存储器描述
3.18.1 磁盘的格式化容量比非格式化容量小
标准定义: 解释磁盘格式化容量较非格式化容量小的原因。
通俗解释: 类似于购物袋的容量,实际可以装的东西比袋子的大小要小,因为袋子的一部分空间用于标签和整齐摆放物品。
3.18.2 扇区中包含数据、地址和校验等信息
标准定义: 描述磁盘扇区的结构,包括存储数据、地址和校验等信息。
通俗解释: 就像书的一页,扇区中包含了数据内容(文字)、地址(页码)以及校验(纠错手段)等信息。
3.18.3 磁盘存储器的最小读写单位为一个扇区
标准定义: 确定磁盘存储器的最小读写单位,并考虑其影响。
通俗解释: 像一次只能搬运一个箱子,磁盘的最小读写单位是一个扇区,只能读写这个扇区的内容。
3.18.4 磁盘存储器由磁盘控制器、磁盘驱动器和盘片组成
标准定义: 分析磁盘存储器的组成结构,包括磁盘控制器、磁盘驱动器和盘片等组件。
通俗解释: 就像一个图书馆,有管理图书的管理员(磁盘控制器)、存放书籍的书架(磁盘驱动器)以及书架上的具体书籍(盘片)。
-
磁盘的格式化容量和非格式化容量:
- 磁盘的非格式化容量(Unformatted Capacity): 这是指磁盘上的总存储容量,包括所有的磁道和扇区。在此阶段,磁盘还没有进行格式化,没有划分成文件系统可用的逻辑结构。
- 磁盘的格式化容量(Formatted Capacity): 当磁盘被格式化后,一部分容量会被用于存储文件系统的元数据、文件分配表等信息,这部分容量不可用于存储用户数据。因此,磁盘的格式化容量通常小于非格式化容量。
-
扇区中包含的信息:
- 一个磁盘扇区是磁盘存储中的最小单位,通常包含了一定数量的字节数据。每个扇区中的信息通常包括用户数据、扇区地址(用于磁盘寻址)、校验信息(如校验和或纠错码)等。
-
磁盘存储器的最小读写单位:
- 磁盘存储器的最小读写单位是一个扇区。即便是对小于扇区大小的数据进行读写操作,也需要读写整个扇区。
-
磁盘存储器的组成:
- 磁盘控制器(Disk Controller): 控制磁盘的读写操作,负责与计算机系统的其他部分进行通信。
- 磁盘驱动器(Disk Drive): 物理存储介质,如硬盘驱动器或软盘驱动器,用于存储数据。
- 盘片(Platter): 磁盘驱动器中的一个圆形盘片,通常有多个盘片叠在一起,每个盘片的两个表面都被用于存储数据。
选项C中的错误在于,磁盘存储器的最小读写单位是一个扇区,而不是一个字节。
3.19 Cache 命中率计算
3.19.1 命中率 = Cache 命中次数 / 总访问次数
标准定义: 计算Cache命中率,评估Cache性能。
通俗解释: 就像商店里的货架,计算有多少次顾客能在这里找到所需商品,从而评估货架的效率。
专业名词解释:
-
Cache(高速缓存):
- Cache 是一种高速缓存存储器,位于计算机的存储层次结构中,介于主存储器(RAM)和中央处理器(CPU)之间。其目的是提供比主存更快的访问速度,减少CPU对主存的访问时间。
-
Cache命中率:
- Cache命中率是指在访问Cache时,所成功读取或写入Cache的次数与总的访问次数之比。这是一个重要的性能指标,高命中率通常表示Cache的设计和使用是有效的,能够减少对慢速主存的访问次数,提高整体计算机性能。
-
Cache未命中:
- 当CPU请求数据或指令时,如果在Cache中找到了所需的数据,就称为Cache命中;相反,如果没有找到,就称为Cache未命中。未命中会导致需要从主存中获取数据,这会产生额外的访问时间。
在这个题目中,Cache的命中率计算公式为:
[ \text{命中率} = \frac{\text{Cache命中次数}}{\text{总访问次数}} ]
题目中提到访问Cache未命中50次,因此命中次数是总访问次数减去未命中次数,即 (1000 - 50 = 950)。带入公式计算:
[ \text{命中率} = \frac{950}{1000} \times 100% = 95% ]
所以,答案是D. 95%。
3.20 Cache 映射方式计算
3.20.1 二路组相联映射
标准定义: 分析二路组相联映射方式,计算主存单元地址与Cache组号的关系。
通俗解释: 就像在图书馆中确定书籍的放置位置,通过计算来确定每本书应该放在哪个书架上。
专业名词解释:
-
组相联映射:
- 组相联映射是Cache映射方式之一,它将主存块划分为若干组,每组包含多个Cache行。当一个主存块需要被加载到Cache时,它可以映射到该组的任何一个行中。这种方式的设计可以减少直接映射方式下的冲突。
-
Cache组:
- Cache组是Cache的逻辑单元,由多个Cache行组成。在组相联映射中,一个组包含多个Cache行,每个行用于存储一个主存块。组的数量决定了Cache的组相联度。
-
Cache行:
- Cache行是Cache的基本存储单元,用于存储主存中的一块数据。在组相联映射中,一个Cache行对应一个主存块。每个Cache行都有一个标记(Tag)用于标识存储的主存块。
在这个题目中,Cache共有16块,采用二路组相联映射,即8组。主存块大小为32B,主存单元地址129(二进制为10000001)需要映射到Cache的哪一组?
主存单元地址的后5位是块内地址,块内地址的前3位确定组号。所以,(10000001_2) 的前3位是 (100_2),转换成十进制是4。因此,主存块129号应装入Cache的第4组。所以,答案是C. 4。
3.21 Cache 映射和替换策略
3.21.1 二路组相联映射
解释二路组相联映射,考虑LRU替换策略。
在计算机组成原理中,以下是相关专业术语的解释:
-
Cache(缓存): 高速缓存存储器,用于临时存储计算机处理器频繁访问的数据和指令,以提高数据访问速度。
-
LRU(Least Recently Used,最近最少使用): LRU 是一种缓存替换算法,根据最近的访问模式淘汰最长时间未被使用的缓存块。
-
组相联映射: 一种缓存映射方式,其中主存地址的一部分映射到缓存的多个组中,每个组包含多个缓存行。这有助于减少冲突,提高缓存的效率。
-
主存(主存储器): 计算机中用于存储数据和指令的内存,是处理器直接访问的主要存储区域。
-
字节编址: 计算机内存按字节进行寻址,每个地址单元都对应一个字节。
-
块(Cache 块): 在缓存中存储的数据块,通常与主存的一个块相对应。
-
替换策略: 决定在缓存未命中时选择哪个缓存块进行替换的规则。LRU 是其中一种常见的替换策略。
以上是一些与题目相关的专业术语的解释。如果您有其他需要解释的术语,请告诉我。
3.22 指令 Cache 与数据 Cache 分离目的
3.22.1 减少指令流水线资源冲突
说明分离指令Cache和数据Cache的目的,减少指令流水线资源冲突。
指令 Cache 和数据 Cache 分离:这是计算机系统中一种组织缓存结构的方式,其中指令缓存(Instruction Cache)和数据缓存(Data Cache)是两个独立的缓存部分。每个部分专门用于存储对应类型的信息,以提高存储器访问的效率。
-
指令 Cache(I-Cache):用于存储计算机程序的指令。当中央处理器需要执行一条指令时,会首先查找指令 Cache,如果命中(在 Cache 中找到了相应的指令),则直接从 Cache 中获取指令执行,否则需要从主存中加载到 Cache 中再执行。
-
数据 Cache(D-Cache):用于存储计算机程序中的数据。当中央处理器需要读取或写入数据时,会首先查找数据 Cache,如果命中,则直接在 Cache 中进行数据的读取或写入,否则需要从主存中加载到 Cache 中再进行操作。
分离指令 Cache 和数据 Cache 的设计有助于避免指令和数据的访问冲突,提高了缓存的命中率,从而提高了整体的计算机性能。这种分离的设计通常是为了减少在同时访问指令和数据时可能发生的缓存竞争,提高指令和数据的并行性,从而更有效地利用计算资源。
指令流水线(Instruction Pipeline):
指令流水线是一种计算机指令执行的优化技术,通过将指令执行的不同阶段划分为多个流水线阶段,使得多个指令可以同时在不同阶段执行,从而提高处理器的吞吐量。每个流水线阶段执行特定的任务,如取指、译码、执行、访存和写回。当一条指令执行完成某个阶段后,它就进入下一个阶段,同时下一条指令开始执行当前阶段,形成了指令在流水线中的并行执行。
流水线技术的优势在于能够充分利用处理器资源,提高指令的执行速度。不同的流水线阶段可以并行执行,使得多条指令能够在同一时间段内完成不同的阶段,从而达到更高的效率。然而,流水线也面临着一些问题,如流水线暂停、数据相关性、分支预测等,需要采取相应的措施进行解决。
3.23 数据 Cache 缺失率计算
3.23.1 计算数据 Cache 缺失率
通过计算数据Cache的缺失率,评估系统对数据的访问效率。
直接映射方式(Direct Mapping): 直接映射是一种缓存映射技术,其中主存中的每个块都只能映射到缓存中的特定位置。具体来说,在直接映射中,主存的每个块只能映射到缓存的一个特定块,这个映射关系是通过使用主存地址的某些位来直接确定的。这就意味着,如果两个主存块的这些位相同,它们就会映射到缓存中的相同位置。
LRU 替换策略(Least Recently Used): LRU 是一种缓存替换策略,用于确定在缓存中选择哪个块被替换出去,以便为新块腾出空间。在LRU策略中,被认为是最近最少使用的块将被替换。具体来说,当一个块被访问时,它就被标记为最近使用的块。当需要替换一个块时,选择缓存中最久未被使用的块进行替换。
缓存缺失率(Cache Miss Rate): 缓存缺失率是一个用于衡量缓存性能的指标,表示在一系列访问中,缓存无法满足的访问数量占总访问数量的比例。缓存缺失率越低,缓存的性能越好,因为这意味着更多的访问被成功地满足于缓存而不需要从主存中加载数据。
块(Block): 在缓存和主存之间传输的数据的最小单位。也称为缓存块或主存块。块的大小通常是2的幂次方,例如,16字节、32字节等。块的大小决定了在缓存中和主存之间传输的数据量,较大的块可以提高访存命中率,减少缓存缺失率。
这段C语言程序通过循环遍历数组a,每次将数组元素a[k]的值增加32。根据程序执行过程中的访存操作,采用直接映射方式的数据Cache,数据区大小为1KB,块大小为16B,且初始时Cache为空,分析可得:
- 该程序中访问a[k]需要两次内存访问:一次读取a[k]的值,一次写回新的值。
- 数组a中每个元素为int型,占4B。
首先,计算数组a的元素个数,即主存区大小与元素大小的商:1KB / 4B = 256个元素。
然后,考虑每个块的大小为16B,那么每个块可容纳4个元素(16B / 4B = 4)。
由此可知,数组a共有256个元素,每个块可容纳4个元素,因此需要64个块(256元素 / 4元素/块 = 64块)。
在程序执行的过程中,首次访问a[k]时,发生了缺失,导致对应的块(4个元素)加载到Cache中。接下来的7次访问都是在已经加载到Cache中的这个块内进行,因此都命中了Cache。
因此,该程序段执行过程中访问数组a的Cache缺失率约为(1次缺失 / 8次访问) * 100% = 12.5%。答案选项为C。
3.24 数组访问局部性描述
3.24.1 时间局部性和空间局部性
描述数组访问的时间局部性和空间局部性,优化存储器访问效率。
时间局部性(Temporal Locality)
时间局部性是指在程序执行过程中,一旦某个存储单元被访问,它在不久的将来可能再次被访问的倾向。这种局部性体现为程序对某些数据或指令的重复使用,充分利用了计算机系统中的高速缓存(Cache)以及寄存器等存储层次结构,从而提高程序执行效率。
在计算机系统中,由于程序的执行通常表现出循环结构、顺序执行等规律,某个存储单元在一段时间内可能会被多次访问,因此在这段时间内,该存储单元的数据被保留在高速缓存中,减少了访问主存储器的需求,提高了程序执行速度。
空间局部性(Spatial Locality)
空间局部性是指在程序执行过程中,一旦某个存储单元被访问,附近的存储单元也很快会被访问的倾向。这种局部性体现为程序在一段时间内对相邻内存地址的访问,通常表现为对数组、数据结构等连续内存区域的访问模式。
与时间局部性类似,空间局部性的存在也是为了充分利用高速缓存和其他存储层次结构,减少对主存储器的访问。通过预读取、缓存预取等技术,系统可以在发现某个存储单元被访问后,提前将其附近的数据加载到高速缓存中,以满足后续可能的访问需求,提高程序的整体性能。
3.25 Cache 行位数计算
3.25.1 直接映射方式和回写策略
计算直接映射方式下Cache的行位数,考虑回写策略对性能的影响。
-
直接映射方式: 是一种Cache映射策略,其中每个主存块只能映射到Cache的一个特定行。即,主存中的每个块只能放在Cache的一个位置上。这可以通过使用块地址的一部分来选择Cache行来实现。
-
回写策略(Write Back): 是一种缓存写入策略,其中只有在Cache行被替换时,才将其内容写回主存。在发生写入时,数据首先被写入Cache,而不是立即写回主存。这样,只有在Cache行被替换时,才需要写回主存。
-
Cache行的位数: 指的是Cache中每一行的总位数,包括数据位、标记位、脏位(Dirty Bit)、有效位(Valid Bit)等。在这个上下文中,主要包括了数据位、标记位、脏位和有效位,总共275位。
-
物理地址: 在计算机中,是指对计算机中的内存和外设的寻址。在这里,特指主存地址,它通常由标记(Tag)、组号(Index)、块内地址(Offset)等部分组成,用于Cache的映射和标识。
这些名词解释涵盖了与Cache映射方式、写策略和Cache行结构等相关的计算机体系结构概念。
3.26 Cache 比较器个数和位数计算
3.26.1 组相联映射方式的 Cache
计算组相联映射方式下Cache的比较器个数和位数,以满足系统需求。
组相联映射
组相联映射是一种缓存映射方式,其中主存的地址被分成多个组,每个组中有多个缓存行。每个组中的多个缓存行共享一个组标记,而每个缓存行包含标记、组索引和块偏移。
-
组相联映射结构: 在这种结构中,主存地址被分成组和块,每个组中有多个缓存行。缓存行与主存块的大小相同。
-
组相联映射的组数: 由缓存的组相联度决定,如果有8路组相联,则有8个缓存行共享一个组标记。
-
比较器: 用于在访问时检查缓存中的标记是否与要访问的主存块的标记匹配。在给定的组内,需要比较每个缓存行的标记。
-
例子: 若Cache采用8路组相联映射,每个组中有8个缓存行,则需要8个比较器来并行比较8个缓存行的标记。
组相联映射结构的优点是相对于直接映射,有更好的灵活性和更高的命中率,但相应地,实现它需要更多的硬件开销。
3.27 计算机存储器访问
3.27.1 虚拟存储概念
阐述虚拟存储的概念,介绍如何通过虚拟存储提高系统的性能和灵活性。
3.27.2 TLB(快表)和 Cache 的作用
说明TLB和Cache在计算机存储器访问中的作用,以提高访存效率。
3.27.3 访存过程中的缺页和缺失处理
详细描述计算机存储器访问过程中可能出现的缺页和缺失处理机制,确保数据的正确获取。
计算机时钟周期和总线带宽
CPU 和总线的时钟周期
-
CPU 时钟周期: 是指 CPU 执行一条指令所需的时间,它是主频的倒数,即 1/主频。在这里,主频是指 CPU 的时钟频率,主频为 800MHz,所以 CPU 时钟周期为 1/800MHz = 1.25ns。
-
总线时钟周期: 是指总线进行一次时钟振荡所需的时间,也是总线频率的倒数。在这里,总线频率为 200MHz,所以总线时钟周期为 1/200MHz = 5ns。
总线带宽
- 总线带宽: 是指在单位时间内通过总线传输的数据量。对于一个 32 位总线,每个时钟周期传输 32 位的数据,因此带宽为 32 位 × 时钟频率。在这里,总线宽度为 32 位,时钟频率为 200MHz,所以总线带宽为 32位 × 200MHz = 800MB/s 或者 4B/5ns = 800MB/s。
Cache 缺失时的读取总线事务
-
Cache 块大小: 指的是缓存中每个块的大小,通常以字节为单位。在这里,Cache 块大小为 32B。
-
读突发传送总线事务: 当缓存发生缺失时,需要从主存中读取一个块到缓存中。这个过程称为读突发传送总线事务。
存储器总线读事务时间
- 读事务时间: 包括发送地址和命令、存储器准备数据、传送数据等过程。在这里,每个读事务的时间为地址传送时间、第一个体读数据时间以及数据传送时间的总和。
CPU 执行时间
-
指令执行时间: 是指 CPU 执行一条指令所需的时间,它可以分为 Cache 命中时的执行时间和缺失时的平均额外开销。
-
平均额外开销: 指的是每条指令由于缓存缺失而导致的额外开销的平均值,包括缓存访问次数、缺失率以及读取总线事务时间的综合考虑。
这些专业名词的解释涵盖了计算机体系结构中的时钟周期、总线带宽、Cache 缺失、存储器总线事务等关键概念。
Cache 容量
Cache 容量是指缓存存储器能够容纳的数据量或指令量的大小。在计算机中,Cache 是用来存储最常访问的数据和指令,以提高对这些数据和指令的访问速度。
-
计算公式: Cache 容量的计算通常取决于缓存的行数、每行的大小(字节数)以及路数(相联度)。
-
直接映射方式中的容量计算: 对于直接映射方式,每个行对应一个主存块,计算公式为 Cache 容量 = 行数 × 行大小。行大小包括数据部分、标记部分、有效位等。
-
相联映射方式中的容量计算: 对于相联映射方式,容量计算需要考虑每个组的行数、每行的大小以及组数。公式为 Cache 容量 = 行数 × 行大小 × 组数。
Cache 行号计算
在相联映射方式中,计算特定主存地址对应的 Cache 行号涉及到地址的拆解和映射规则的应用。一般的计算公式为:Cache 行号 = [(首地址 + 块内偏移) / (每组行数)] % 组数。这公式中包括主存首地址、块内偏移、每组行数以及组数等因素。
命中率
Cache 命中率是指在程序执行中,所访问的数据或指令在 Cache 中已经存在的比率。计算公式为 命中率 = (总访问次数 - 不命中次数) / 总访问次数。对于不同的访存方式(行优先遍历、列优先遍历),命中率会有显著的差异,影响程序执行效率。
在上述问题中,Cache 容量的计算、Cache 行号的确定以及程序 A 和 B 的命中率分析都涉及到这些概念的运用。
3.28 存储器层次结构与性能
3.28.1 存储器层次结构概述
概括存储器层次结构,包括主存、Cache和辅助存储器等,以提高系统整体性能。
3.28.2 Cache 命中时的 CPI 计算
计算Cache命中时的CPI(每指令周期数),评估Cache对指令执行效率的提升。
3.28.3 存储器总线带宽计算
计算存储器总线的带宽,确保数据传输的效率和速度。
3.28.4 存储器总线突发传送
分析存储器总线的突发传送机制,优化数据的连续传输。
- 时钟周期和总线带宽
-
CPU 时钟周期: CPU 完成一次时钟振荡所需的时间,通常是主频的倒数。在这里,CPU 主频为 800MHz,因此 CPU 时钟周期为 1/800MHz = 1.25ns。
-
总线时钟周期: 总线进行一次时钟振荡所需的时间,是总线频率的倒数。总线频率为 200MHz,因此总线时钟周期为 1/200MHz = 5ns。
-
总线带宽: 指单位时间内通过总线传输的数据量。对于一个 32 位总线,每个时钟周期传输 32 位的数据,带宽为 32位 × 时钟频率。在这里,总线宽度为 32 位,时钟频率为 200MHz,带宽为 32位 × 200MHz = 800MB/s 或 4B/5ns = 800MB/s。
- Cache 缺失和读取总线事务
-
Cache 块大小: 指缓存中每个块的大小,通常以字节为单位。在这里,Cache 块大小为 32B。
-
读突发传送总线事务: 当缓存发生缺失时,需要从主存中读取一个块到缓存中。这个过程称为读突发传送总线事务。
- 存储器总线读事务时间
- 读事务时间: 包括发送地址和命令、存储器准备数据、传送数据等过程。在这里,每个读事务的时间为地址传送时间、第一个体读数据时间以及数据传送时间的总和,计算为 5ns + 40ns + 8×5ns = 85ns。
- CPU 执行时间
-
指令执行时间: CPU 执行一条指令所需的时间。它包括 Cache 命中时的指令执行时间和缺失时的平均额外开销。
-
平均额外开销: 缓存缺失导致的平均额外开销,考虑了平均访存次数、Cache 缺失率和一次读取总线事务时间。在这里,一条指令的平均 CPU 执行时间为 10.1ns,BP 的总 CPU 执行时间为 1010ns。
这些名词解释涵盖了计算机体系结构中的时钟周期、总线带宽、Cache 缺失、读取总线事务以及 CPU 执行时间等关键概念。
3.29 页式虚拟存储管理
3.29.1 页式存储基本概念
介绍页式存储的基本概念,包括虚拟页、物理页和页表等。
3.29.2 TLB 的全相联映射
详细说明TLB的全相联映射方式,以提高地址映射效率。
3.29.3 Cache 数据区与页表项大小计算
计算Cache数据区和页表项的大小,确保它们的匹配和协同工作。
3.29.4 虚拟地址到物理地址变换过程
描述虚拟地址到物理地址的变换过程,揭示页式虚拟存储的工作原理。
- 页式虚拟存储管理方式
-
页大小: 每一页的大小,以字节为单位。在这里,页大小为 8KB。
-
虚拟地址和物理地址: 虚拟地址是程序中使用的地址,物理地址是在主存中的实际地址。在这里,虚拟地址为 32 位,物理地址为 24 位。
-
TLB(Translation Lookaside Buffer): 页表项的高速缓存,用于加速虚拟地址到物理地址的转换。
-
全相联映射: TLB 中每个条目都可以映射到任何虚拟页,提供更大的灵活性。
-
Cache 数据区大小和组相联: Cache 存储数据的区域大小,以及组相联映射方式。在这里,Cache 数据区大小为 64KB,采用二路组相联方式。
-
主存块大小: 主存中数据块的大小。在这里,主存块大小为 64B。
- 存储访问过程示意图
-
字段 A~G 的位数: A 和 B 表示虚拟地址的位数,C 表示物理地址的位数,D 表示页内偏移地址的位数,E 和 F 表示 Cache 相关的位数,G 表示主存块的位数。在这里,A = B = 19,C = 11,D = 13,E = F = 9,G = 6。
-
TLB 标记字段 B: 存放虚拟页号,表示 TLB 项对应哪个虚拟页的页表项。
- Cache 映射和块号装入
-
Cache 组号: Cache 中每个组的编号,用于确定映射到哪个组。在这里,块号 4099 映射到 Cache 组号为 3。
-
字段 H 内容: Cache 中的一个字段,与组号相关。在这里,块号 4099 对应的 H 字段内容为 0 0000 1000B。
- Cache 缺失和缺页处理
-
Cache 缺失: 当访问的数据不在 Cache 中时,发生 Cache 缺失。处理缓存缺失通常比处理缺页的开销小。
-
缺页处理: 当访问的数据不在主存中时,需要从外部存储(通常是硬盘)中装入缺失的页。这个过程的开销较大,因为需要磁盘 I/O 操作。
-
直写策略和回写策略: 直写策略是指每次数据被修改时都立即写回主存,而回写策略是指只有在被替换出 Cache 时才将修改的数据写回主存。在这里,Cache 可以采用直写策略,而在修改页面内容时总是采用回写策略,因为磁盘写操作相比主存写操作较慢。
这些名词解释涵盖了页式虚拟存储管理、TLB、Cache 映射、块号装入、Cache 缺失和缺页处理等计算机体系结构中的重要概念。
3.30 直写和回写策略
3.30.1 Cache 写策略概述
概括Cache的写策略,包括直写和回写,以及它们的优缺点。
3.30.2 直写与回写策略区别
比较直写和回写策略的区别,帮助选择适合系统的写策略。
3.30.3 为何修改页面内容时采用回写策略
解释在修改页面内容时为什么选择回写策略,分析其优势和应用场景。
- Cache 行中标记、LRU 位、修改位
-
标记 (Tag): 用于标识主存块在Cache中的唯一性,通过与主存地址的高位进行比较来确定是否命中。
-
LRU 位: Least Recently Used,表示最近最少使用的位,用于实现LRU替换算法。每行的LRU位用于记录这一行上次被访问的时间,以确定在替换时哪一行是最近最少使用的。
-
修改位: 也称为脏位(Dirty Bit),用于标识Cache中的数据是否被修改过。直写策略中,修改的数据会立即写回主存,因此一般不需要此位。
- 访问数组 s 的数据 Cache 缺失次数
-
主存块大小: 主存中数据块的大小,这里为64B。
-
Cache 组数: Cache中的组数,根据8路组相联映射,计算方法为32KB/(64B×8) = 64。
-
LRU替换算法: Least Recently Used替换算法,用于在Cache行中选择最近最少使用的行进行替换。
- 从 Cache 中访问指令的过程
-
主存地址划分: 根据主存地址的不同部分(标记、组号、块内地址)划分主存地址。
-
组索引: 根据主存地址计算得到的Cache组索引,用于定位到相应的Cache组。
-
有效位: Cache行的有效位,标识该行是否存储了有效的数据。
-
LRU替换过程: 在Cache中选择最近最少使用的行进行替换,通常是通过LRU位的更新实现。
这些名词解释涵盖了与Cache行结构、LRU替换算法和Cache缺失等相关的计算机体系结构概念。
3.31 存储器访问命中率
3.31.1 存储器访问命中率计算
通过计算存储器访问命中率,评估系统对数据的访问效率。
3.31.2 Cache、TLB 和 Page 命中情况分析
分析Cache、TLB和Page在存储器访问中的命中情况,揭示不同组件对性能的影响。
3.31.3 命中率对系统性能的影响
探讨存储器访问命中率对系统性能的影响,为系统优化提供指导。
-
TLB(Translation Lookaside Buffer): 是一种缓存,用于存储虚拟地址到物理地址的转换映射。TLB加速了虚拟内存地址到物理内存地址的转换过程,减少了访问主存的时间。当CPU访问一个虚拟地址时,TLB首先被查询,如果虚拟页号在TLB中,就命中TLB,直接得到相应的物理页框号。否则,会发生TLB未命中。
-
Cache未命中(Cache Miss): 在Cache中进行存储器访问时,如果需要的数据或指令未在Cache中找到,就发生了Cache未命中。这时,系统需要从主存中加载相应的数据块或指令块到Cache中,以便CPU能够继续执行。
-
Page未命中(Page Fault): 在虚拟内存系统中,如果CPU试图访问一个尚未调入主存的虚拟页面,就会发生Page未命中。这时,操作系统会将相应的页面从磁盘加载到主存,以满足CPU的访存请求。
在给定的选项中,选项D中提到的TLB命中、Cache命中、Page未命中的情况不可能发生,因为当Page未命中时,TLB命中是不可能的,因为虚拟页号不在TLB中。
3.32 虚拟地址转换
3.32.1 TLB 标记字段的含义
解释TLB标记字段的含义,阐述它在虚拟地址转换中的作用。
3.32.2 TLB 和 Cache 访问过程
详细描述TLB和Cache的访问过程,揭示它们在虚拟地址转换中的协同工作。
3.32.3 虚拟地址转换结果分析
分析虚拟地址转换的结果,确保系统能够正确访问相应的物理地址。
-
页式存储管理(Paging): 是一种虚拟存储器管理技术,将主存和虚拟存储器划分为固定大小的页面(Page),通常是4KB或其他大小的幂。这样的划分使得程序的地址空间也被划分为相同大小的页面。页式存储管理允许将不同程序的页面分散存储在主存中,而不需要连续的物理地址。
-
TLB(Translation Lookaside Buffer): 是一种缓存,用于存储虚拟地址到物理地址的转换映射。TLB加速了虚拟内存地址到物理内存地址的转换过程,减少了访问主存的时间。当CPU访问一个虚拟地址时,TLB首先被查询,如果虚拟页号在TLB中,就命中TLB,直接得到相应的物理页框号。
在此问题中,通过TLB的全相联映射,根据虚拟地址的页号03FFFH查找对应的TLB表项,得到页框号0153H,将其与虚拟地址的页内偏移地址拼接,得到物理地址0153180H。
3.33 计算机指令执行过程
3.33.1 指令执行过程中的访存
揭示计算机指令执行过程中的访存过程,强调存储器对指令执行的重要性。
3.33.2 Cache 访问次数估算
估算Cache的访问次数,为系统性能分析提供基础数据。
3.33.3 TLB 命中与 Cache 命中分析
分析TLB和Cache的命中情况,深入了解它们对指令执行效率的贡献。
解释专业名词:
-
页式虚拟存储管理方式: 一种计算机内存管理的方式,将主存和辅助存储器划分为固定大小的页面(通常为4KB或8KB),将程序和数据划分为相同大小的页。虚拟存储空间也被划分为相同大小的页面。当程序执行时,只有当前需要的页才会调入主存,其余的页则保留在辅助存储器。这样可以允许程序的大小超过物理内存的大小。
-
TLB(Translation Lookaside Buffer,快表): 一种硬件缓存,用于存储虚拟地址到物理地址的转换信息,加速地址翻译的过程。TLB通常是一个小而快速的高速缓存,存储了最近访问的页表项,减少了从主存获取转换信息的时间。
-
Cache(高速缓存): 一种存储器层次结构中的高速缓存,用于暂时存储最常用的数据和指令,以提高CPU对存储器的访问速度。Cache存储了最近使用的数据,如果CPU需要的数据在Cache中找到(命中),则可以更快地获取;否则,需要从主存或其他更慢的存储器层次中获取(缺失)。
-
直写方式(Write Through): 一种缓存写入策略,即在数据写入缓存的同时也立即写入主存。这确保了主存和缓存中的数据一致,但写入开销较大。
-
存储单元地址(Memory Address): 用于唯一标识计算机存储中的一个单元的地址。在上下文中,xaddr表示变量x对应的存储单元的地址。
-
取数、运算和写回过程: 执行指令时的三个基本步骤。取数阶段涉及从存储器中读取数据,运算阶段进行算术或逻辑运算,写回阶段将结果写回存储器。
希望以上解释能够帮助您理解相关的计算机体系结构和操作系统概念。
3.34 直接映射方式下的 Cache
3.34.1 Cache 相关概念解释
解释直接映射方式下Cache的相关概念,包括行标记、索引和块等。
3.34.2 直接映射方式地址结构
详细说明直接映射方式下Cache的地址结构,包括标记、索引和块偏移等字段的位置和作用。
3.34.3 Cache 容量计算
计算直接映射方式下Cache的容量,确保它满足系统对存储容量的需求。
3.34.4 Cache 行标记项结构
描述直接映射方式下Cache行标记项的结构,揭示标记的作用和存储结构。
解释专业名词:
-
直接映射方式: 一种缓存映射方式,其中每个主存块只能映射到缓存的一个特定行。这意味着特定的主存块只能存储在缓存的一个位置,没有其他替代位置。
-
主存块: 主存中的一个固定大小的数据块,通常是缓存中相应数据的拷贝。主存块的大小由计算机体系结构决定。
-
字: 在计算机中,一个字是一组位,通常是32位或64位,表示一个整数或其他数据类型的大小。在这里,字的大小是32位。
-
回写方式: 一种缓存写入策略,即只有在缓存中的数据被修改后才会写回主存。这可以减少对主存的写操作次数,提高性能。
-
Cache 行: 缓存中的一个存储单元,通常对应于主存中的一个块。每个 Cache 行包含一部分主存块的数据以及用于标记和控制的额外信息。
-
Cache 容量: 缓存能够存储的总数据量。在这里,它指的是能够存放4K字数据的Cache的总容量。
-
标记位: 在缓存行的标记阵列中,标记位用于存储主存块的标识信息,以确定是否缓存了请求的数据。
-
有效位: 在缓存行的标记阵列中,有效位用于指示缓存行中的数据是否有效。如果有效位为1,表示缓存行中的数据是有效的。
-
一致性维护位(脏位): 在缓存中,一致性维护位用于标记缓存行中的数据是否被修改。当采用回写方式时,脏位用于指示缓存中的数据是否需要写回主存。
-
替换算法控制位: 在缓存中,替换算法控制位用于记录采用何种替换算法。在这里,题目未提及替换算法的相关信息,因此不进一步讨论。
根据以上专业名词的解释,可以更好地理解计算机体系结构和缓存管理的相关概念。
3.35 缺页处理与异常
3.35.1 缺页处理异常产生原因
阐述缺页处理异常产生的原因,包括虚拟页未在主存中的情况。
3.35.2 缺页处理流程概述
概括缺页处理的流程,包括从辅助存储器中加载缺失的页到主存。
3.35.3 缺页处理程序的执行过程
详细描述缺页处理程序的执行过程,确保有效地处理缺页异常并维护正确的数据状态。
当涉及请求分页系统中的缺页处理时,以下专业术语可以解释这些叙述:
-
缺页:缺页指的是在程序执行期间,CPU检测到所需的页面不在主存中的一种异常情况。这意味着需要的页面不在当前的内存中,导致缺页中断。
-
缺页处理程序:由操作系统提供的一段代码,负责处理缺页中断。其功能是根据缺页中断提供的地址信息,将所需的页面从外部存储(如硬盘)加载到内存中。
-
缺页中断:当CPU检测到所需的页面不在内存中时,会产生缺页中断,这是一种CPU检测到的异常情况。CPU会暂时停止执行程序,并请求操作系统的帮助来解决缺页问题。
-
地址转换异常:缺页是一种地址转换异常,当CPU试图访问一个在主存中不存在的页面时发生。
叙述中描述的选项D中所述是错误的,因为缺页处理完成后,CPU不会直接回到发生缺页的指令的下一条指令执行,而是会重新执行导致缺页的指令。CPU需要重新执行这个指令,因为在缺页发生时,所需的页面可能已经被加载到内存中了。
3.36 TLB 和 Cache 特性
3.36.1 TLB 和 Cache 的命中率与局部性关系
分析TLB和Cache的命中率与局部性之间的关系,考虑局部性对地址映射的影响。
3.36.2 缺失时的访存过程分析
在TLB或Cache发生缺失时,分析系统执行的额外访存过程,了解缺失处理的机制。
3.36.3 缺失处理硬件实现的可行性
评估缺失处理硬件实现的可行性,考虑成本和性能等因素。
-
TLB(Translation Lookaside Buffer):TLB是一种硬件缓存,用于存储最近或最常用的虚拟地址到物理地址的转换信息。它加速了虚拟地址到物理地址的转换过程,缓存了部分页表项,减少了对页表的频繁访问,提高了地址转换的速度。
-
Cache:Cache是高速缓存,存储了主存中最常用的数据和指令的副本。它位于CPU和主存之间,具有更快的访问速度,可以缓解主存访问速度较慢和CPU速度较快之间的矛盾,提高系统整体性能。
-
DRAM(Dynamic Random Access Memory):DRAM是一种动态随机存取存储器,用于主存储器。它的内存单元由电容和电阻构成,需要定期刷新来保持存储的数据。相对于SRAM,DRAM的访问速度较慢,但具有较高的存储密度和低成本。
-
SRAM(Static Random Access Memory):SRAM是一种静态随机存取存储器,常用于Cache和一些高速缓存中。它由触发器构成,不需要定期刷新,速度较快但成本较高,通常用于需要更快访问速度和更低功耗的情况。
3.37 虚拟地址转换与存储管理
3.37.1 分页虚拟存储管理方式
3.37.1.1 虚拟地址与物理地址的转换
3.37.1.2 页大小对地址位数的影响
解释分页虚拟存储管理方式,分析虚拟地址与物理地址的转换以及页大小对地址位数的影响。
3.37.2 页表的作用与组织
3.37.2.1 虚拟页号、实页号、存在位的解释
说明页表的作用,解释虚拟页号、实页号和存在位等字段的含义。
3.37.3 CPU访问虚拟地址的过程
3.37.3.1 页表的查询和TLB的映射
3.37.3.2 虚拟地址到物理地址的映射
描述CPU访问虚拟地址的过程,包括页表的查询、TLB的映射和虚拟地址到物理地址的映射。
在计算机虚拟存储管理中,以下是相关术语的解释:
-
分页虚拟存储管理方式:一种内存管理技术,将进程内存分割成大小固定的页面(页框),并将进程的虚拟地址空间也分割成同样大小的虚拟页面。当一个进程需要访问某个虚拟页面时,系统会将其映射到主存(物理内存)的一个物理页面(页框)上。
-
页大小:指内存中一页的容量。它决定了内存中单个页面的字节数。在这个例子中,页大小为 4KB(2^12 bytes)。
-
虚拟地址空间大小:表示操作系统为每个进程提供的虚拟地址的总数。在这个例子中,虚拟地址空间大小为 4GB(2^32 bytes)。
-
虚拟地址:由操作系统分配给进程的地址空间中的地址。通常,它是从 0 开始到虚拟地址空间大小的一个值。
-
页表:用于虚拟地址和物理地址之间的映射的数据结构。页表中的条目指示了虚拟页面和实际页面之间的关联关系。
-
虚拟地址转换:将进程中的虚拟地址转换为对应的物理地址的过程。这个过程涉及到页表的查询,找到虚拟页面对应的物理页面。
在这个问题中,根据给定的页表内容,通过虚拟地址转换,虚拟地址 0008 2840H 对应的虚页号为 00082H,通过查找页表可以得知对应的实页号(页框号)为 018H。将页框号和页内地址拼接得到实际的主存地址 01 8840H。
3.38 Cache结构与页式虚拟存储管理
3.38.1 Cache直接映射方式
3.38.1.1 Cache行号、标记、有效位等字段的位置和含义
3.38.1.2 虚拟地址到物理地址的映射
3.38.1.3 Cache命中和未命中的判断
详细说明Cache直接映射方式的结构,包括行号、标记、有效位等字段的位置和含义,虚拟地址到物理地址的映射过程,以及Cache命中和未命中的判断条件。
3.38.2 Cache和页式虚拟存储的协同工作
3.38.2.1 Cache和页式虚拟存储如何协同工作
3.38.2.1 页面置换算法的选择
3.38.2.2 Cache中的数据与物理内存的同步
详细阐述Cache和页式虚拟存储如何协同工作,包括选择页面置换算法、确保Cache中的数据与物理内存的同步等关键方面。
3.38.3 缓存一致性的保持
3.38.3.1 MESI协议的基本原理
3.38.3.2 缓存一致性维护的挑战
解释如何通过MESI协议等方式来保持缓存一致性,同时分析维护缓存一致性所面临的挑战。
3.39 存储器层次结构优化
3.39.1 层次结构中的数据传递流程
3.39.1.1 数据在主存、Cache和寄存器之间的传递
3.39.1.2 数据传递的时序和同步控制
详细描述存储器层次结构中数据传递的流程,包括数据在主存、Cache和寄存器之间的传递,以及数据传递的时序和同步控制。
3.39.2 存储器层次结构的优化策略
3.39.2.1 数据预取的机制
3.39.2.2 替换算法的选择
探讨存储器层次结构的优化策略,包括数据预取的机制和替换算法的选择,以提高系统性能。
3.39.3 存储器总线冲突的解决
3.39.3.1 总线的分离与并行传输
3.39.3.2 冲突检测与调度策略
解决存储器总线冲突的方法,包括总线的分离与并行传输,以及冲突检测与调度策略的优化。
3.39.4 MMU的作用与TLB的映射方式
MMU的作用: 存储管理单元(Memory Management Unit,MMU)是计算机体系结构中的一个重要组成部分,负责虚拟地址到物理地址的映射。它实现了虚拟内存的概念,允许程序使用比实际物理内存更大的地址空间。
TLB的映射方式: TLB(Translation Lookaside Buffer)是一种高速缓存,用于加速虚拟地址到物理地址的转换。TLB存储了虚拟页号到物理页框号的映射关系。
3.39.4.1 TLB全相联映射的解释
在TLB的全相联映射中,任何虚拟地址都可以映射到TLB的任一缓存行,而不受固定的位置限制。这种映射方式的优点是能够更灵活地处理不同的虚拟地址,但缺点是可能会引起替换冲突,因为任何虚拟地址都可以映射到任一TLB位置。
3.39.5 Cache的映射方式与替换策略
3.39.5.1 二路组相联映射与LRU替换策略
二路组相联映射: 在二路组相联映射中,Cache被划分为若干组,每组包含两个缓存行。一个给定的块可以映射到两个不同的组中的任一组。
LRU替换策略: LRU(Least Recently Used)是一种缓存替换策略,它选择最近最少使用的缓存块进行替换。这意味着被访问时间最久远的缓存块将被替换。
3.39.5.2 虚拟地址的物理地址转换过程
虚拟地址的物理地址转换过程涉及MMU和TLB的协同工作。简要步骤如下:
-
当程序访问虚拟地址时,MMU首先检查TLB中是否有虚拟地址到物理地址的映射。
-
如果TLB中有映射,则直接使用TLB提供的物理地址。
-
如果TLB中没有映射,则MMU将虚拟地址的页号与页表进行匹配,找到相应的物理页框号。
-
如果使用了TLB,将新的映射添加到TLB中,或者如果TLB已满,则根据替换策略替换TLB中的某个条目。
-
最终,得到物理地址,程序可以访问相应的数据。
下面是有关相关术语的解释: -
页式虚拟存储管理(Paged Virtual Memory Management):这种管理方式将虚拟地址空间和物理地址空间划分为固定大小的页面或框架。通过页表的映射关系,将虚拟地址映射到物理地址。
-
TLB(Translation Lookaside Buffer):TLB是一种高速缓存,用于存储最近或最常用的虚拟地址到物理地址的转换信息。它加速了虚拟地址到物理地址的转换过程,缓存了部分页表项,减少了对页表的频繁访问,提高了地址转换的速度。
-
Cache:Cache是一个高速缓存存储器,用于存储最常用的数据和指令的副本。它位于CPU和主存之间,提供了更快速的数据访问速度。
-
直接映射(Direct Mapping):是Cache中一种常见的映射方式,它将主存中的每个块映射到Cache的唯一一行。这意味着主存中的一个块只能映射到Cache中的一个特定位置。
-
LRU替换算法(Least Recently Used Replacement Algorithm):LRU是Cache中一种替换算法,它会替换最长时间未被使用的Cache行。该算法保留最近最少使用的数据,以提高Cache命中率。
-
回写策略(Write Back Policy):这是Cache中一种数据更新策略,即在数据被替换出Cache之前,只有在数据被修改后才会写回主存,而不是立即写回主存。
3.40 存储器技术的未来趋势
3.40.1 新型存储介质的研究
3.40.1.1 基于非易失性存储介质的创新
3.40.1.2 存储密度和读写速度的平衡
研究新型存储介质的发展趋势,包括基于非易失性存储介质的创新和存储密度与读写速度的平衡。
3.40.2 存储器架构的演进
3.40.2.1 多通道、多层次存储器架构
3.40.2.2 集成存储与计算的趋势
探讨存储器架构的未来演进,涉及多通道、多层次存储器架构和集成存储与计算的趋势。
3.40.3 存储器安全性的挑战与解决
3.40.3.1 物理攻击与侧信道攻击
3.40.3.2 加密与隔离技术的应用
分析存储器安全性面临的挑战,包括物理攻击与侧信道攻击,并探讨加密与隔离技术的应用。
3.40.4 TLB的二路组相联方式
TLB标记和组号的分配: 在TLB的二路组相联方式中,虚拟地址被分为标记(tag)、组号和偏移量。标记用于在TLB中唯一标识一个虚拟地址的映射,组号用于选择TLB中的组,而偏移量则指示在组内的具体位置。
3.40.5TLB的替换策略
TLB中的替换过程与LRU算法: 当TLB中没有命中所需的映射时,需要进行替换。使用LRU算法时,选择最近最少使用的TLB条目进行替换。这确保了相对较少使用的映射被替换,提高了TLB的命中率。
3.40.6虚拟地址的TLB命中与替换
虚拟地址的TLB命中: 当程序访问的虚拟地址在TLB中找到了映射时,即为TLB命中。这时,MMU可以直接使用TLB提供的物理地址,无需查找页表。
虚拟地址的TLB替换: 当TLB中没有找到虚拟地址的映射时,需要进行TLB替换。替换策略决定了选择哪个TLB条目进行替换,通常采用LRU算法来保证替换最少使用的条目。替换完成后,新的映射关系将被添加到TLB中,以提高将来的访问效率。
-
分页存储管理方式(Paged Memory Management):这是一种虚拟存储管理方法,将虚拟地址和物理地址空间划分为固定大小的页面或框架。通过使用页表,将虚拟地址映射到物理地址,以便实现内存管理和地址转换。
-
TLB(Translation Lookaside Buffer):TLB是一种高速缓存,用于存储最近或最常用的虚拟地址到物理地址的转换信息。它加速了虚拟地址到物理地址的转换过程,减少了对页表的频繁访问,从而提高了内存访问速度。
-
二路组相联(Two-way Set-Associative):这是一种缓存映射技术,指定了Cache中每个组具有两个缓存行的容量。它允许一个主存块映射到两个缓存行中的任何一个,通过这种方式提高了Cache的命中率。
-
LRU替换策略(Least Recently Used Replacement Policy):LRU是一种缓存替换策略,用于在缓存满时选择被替换的缓存行。它基于最近被使用的原则,替换最久未被使用的缓存行,以便腾出空间用于新数据。
-
虚拟地址(Virtual Address):指程序中使用的地址,通常是程序员编写的代码中使用的地址。虚拟地址需要经过地址转换才能映射到物理内存中的实际地址。
-
页大小(Page Size):指分页存储管理中一个页的大小,表示虚拟地址空间和物理地址空间划分的单元大小。页大小决定了程序在存储器中的存储方式以及页表的大小。
这些术语涉及了计算机内存管理和存储系统中常见的关键概念,包括虚拟存储、缓存技术和地址转换。
第 4 章 输入/输出系统
1. 显示存储器和带宽计算
- 显示分辨率、颜色深度、帧频的关系
- 刷新屏幕所需带宽的计算
- 显存总带宽的分配与计算
-
DRAM芯片: Dynamic Random Access Memory芯片,一种用于计算机系统中的内存存储器。DRAM以电容存储数据,需要定期刷新来保持存储的信息。
-
分辨率: 显示器上的像素数目,通常以水平像素数 × 垂直像素数表示,用于描述屏幕的清晰度和图像的细节。
-
颜色深度: 描述图像中每个像素可以表示的颜色数目,通常以位数表示。24位颜色深度表示每个像素有2^24种不同的颜色选择。
-
帧频: 指每秒钟显示的图像帧数,通常以赫兹(Hz)为单位。帧频越高,图像在屏幕上的流畅度越好。
-
显存总带宽: 用于描述显卡或显示存储器传输数据的速率,通常以每秒传输的位数(或字节数)来衡量。显存总带宽决定了图像数据从显存到显示器的传输速度。
-
刷新屏幕: 将显存中的图像数据传输到显示器以更新屏幕上显示的图像,通常以一定的帧率进行。
-
Mb/s: 每秒兆位(Megabit per second),是一种网络或数据传输速率的单位,表示每秒传输的位数。
请注意,这些专业名词在计算机和显示技术领域是常见的概念。
2. I/O 总线的数据传输
- 数据线、控制线、地址线的作用
- I/O 接口中的命令字、状态字、中断类型号在数据线上传输的情况
在这个问题中,涉及到I/O(Input/Output)总线的数据线传输的信息。以下是相关专业名词的解释:
-
I/O 总线: 用于连接计算机的中央处理器(CPU)和外部设备,用于进行输入和输出操作的通信通道。
-
数据线: I/O 总线的一部分,用于在计算机和外部设备之间传输数据的电子信号线。数据线负责实际的数据传输。
-
I/O 接口: 用于连接计算机系统和外部设备的硬件或电子接口,允许数据在计算机和外设之间进行传输。
-
命令字(Command Word): I/O 接口中的一种控制信号,用于指示外设执行特定的操作或命令。
-
状态字(Status Word): I/O 接口中的一种信号,用于反映外设的状态,例如操作是否完成或是否发生了错误。
-
中断类型号: 用于表示中断的类型或来源,帮助计算机系统确定如何处理特定的中断事件。
在这个问题中,正确答案为D,因为I/O总线的数据线上传输的信息包括I/O接口中的命令字、状态字以及中断类型号。这些信息通过数据线进行传输,以实现计算机与外部设备之间的有效通信。
3. I/O 接口
- 状态端口和控制端口的合用
- I/O 端口的定义
- 独立编址方式和统一编址方式的区别
-
状态端口和控制端口: I/O 接口中的两个寄存器,分别用于传输外设的状态信息和控制信息。它们可以合用同一个寄存器,也可以分别独立使用,具体取决于系统设计。
-
I/O 端口: I/O 接口中,CPU 可以访问的寄存器,用于进行输入和输出操作。通过对 I/O 端口的读写,CPU 可以与外部设备进行通信,执行特定的命令或获取设备状态信息。
-
独立编址方式: I/O 接口的一种设计方式,其中 I/O 端口的地址空间和主存地址空间是分开的,彼此不重叠。这意味着使用不同的地址线对主存和 I/O 端口进行寻址。
-
统一编址方式: I/O 接口的一种设计方式,其中 I/O 端口的地址空间可能与主存地址空间相同。在这种方式下,相同的地址线用于对主存和 I/O 端口进行寻址,可以通过访存指令来访问 I/O 端口。
这些专业名词涉及到计算机系统中输入/输出操作和接口设计的相关概念,包括寄存器的用途、地址空间的分配方式以及 CPU 与外部设备之间的通信机制。
4. I/O 指令的数据传送
- I/O 指令是如何进行数据传送的
- 数据传送发生的位置,如通用寄存器和 I/O 端口之间
-
I/O 指令: 由 CPU 发出,用于执行输入和输出操作的指令。这些指令包括对 I/O 端口进行读写操作,实现计算机与外部设备之间的数据传送。
-
I/O 端口: I/O 接口中的寄存器,用于缓冲信息的传输。CPU 通过 I/O 指令与这些端口进行交互,进行数据的读取或写入,实现与外部设备的通信。
-
通用寄存器: CPU 中的寄存器,用于存储临时数据和运算结果。在 I/O 操作中,通用寄存器可用于暂时存储或处理与外部设备交换的数据。
这些专业名词涉及到计算机指令、I/O 操作和寄存器的相关概念。
5. I/O 接口
- 磁盘驱动器、打印机适配器、网络控制器、可编程中断控制器的分类
- I/O 接口的功能和作用
-
I/O 接口(或 I/O 控制器): 负责连接计算机系统和外部设备,管理输入和输出操作的硬件或电子接口。其主要功能是接收主机发送的 I/O 控制信号,并实现主机和外部设备之间的信息交换。
-
磁盘驱动器: 硬件设备,用于读取和写入数据到磁盘。磁盘驱动器通常包括磁头、磁盘和相关的读写电路等组成部分。
-
打印机适配器: I/O 控制器,用于连接计算机和打印机,负责管理打印机的输入和输出操作。打印机适配器充当计算机和打印机之间的桥梁,使它们能够协同工作。
-
网络控制器: I/O 控制器,用于连接计算机到网络,处理网络通信的输入和输出。网络控制器负责管理数据在计算机与网络之间的传输,实现计算机与其他设备的通信。
-
可编程中断控制器: I/O 控制器,负责管理和分发中断信号,帮助处理系统中断。中断是一种机制,允许外部设备通知 CPU 发生了某个事件,可编程中断控制器帮助系统有效地处理这些中断。
这些专业名词涉及到计算机体系结构、输入/输出操作和外部设备连接的相关概念。
6. 外部中断
- 引起外部中断的事件
- 中断服务程序的执行顺序
-
外部中断: 指 CPU 执行指令以外的事件产生的中断,通常是来自 CPU 与内存以外的中断,例如来自输入设备、定时器等外部事件引起的中断。
-
键盘输入: 涉及输入设备的一种外部事件,每次键盘输入都可能引起 CPU 执行中断以读取输入数据。
-
除数为 0: 属于异常情况,即在运算过程中发生的错误。异常通常发生在 CPU 内部,而不是来自外部设备。
-
浮点运算下溢: 当浮点运算的结果小于浮点数的最小表示范围时发生下溢。通常不会引起中断,而是按照机器零或其他处理方式进行。
-
访存缺页: 发生在 CPU 执行指令时,当试图访问内存中不存在的页时可能引起的中断。这也不属于外部中断。
这些专业名词涉及到计算机中断处理、异常情况和外部设备事件的相关概念。
7. 单级中断系统
- 单级中断系统的执行顺序
- 中断服务程序内的操作
-
单级中断系统: 中断系统中只允许一次中断的发生,不允许中断嵌套。
-
保护现场: 在中断服务程序执行前,需要保存 CPU 寄存器的当前状态,以便在中断服务程序执行完毕后能够正确恢复。
-
开中断: 在中断服务程序执行完毕后,需要开启中断,允许系统响应其他中断事件。
-
保存断点: 在中断服务程序执行前,需要保存当前程序的断点位置,以便在中断返回时能够正确回到原来的执行位置。
-
中断事件处理: 中断服务程序执行的主要阶段,处理具体的中断事件,可能包括识别中断源、执行相应的操作等。
-
恢复现场: 在中断服务程序执行完毕后,需要恢复之前保存的 CPU 寄存器状态,以便恢复中断前的程序执行状态。
-
中断返回: 在中断服务程序执行完毕后,通过中断返回指令返回到原程序的断点位置。
这些专业名词涉及到中断处理、中断服务程序和单级中断系统的相关概念。
8. 多级中断系统
- 中断屏蔽字的含义和设置
- 中断优先级的判断和设置
-
中断优先级: 指示在多个中断请求同时到达时,计算机系统按照一定规则选择要处理的中断的顺序。较高优先级的中断通常被优先处理。
-
中断屏蔽字: 用于控制中断处理优先级的机制,通过设置中断屏蔽字的不同位,可以屏蔽或允许不同优先级的中断。屏蔽字的设置决定了哪些中断可以被响应,哪些中断会被屏蔽。
这些专业名词涉及到计算机中断系统的管理和中断优先级的概念。
9. 设备 I/O 时间计算
- CPU 用于设备的 I/O 时间占整个 CPU 时间的百分比的计算
-
主频: 指计算机处理器的时钟频率,以赫兹(Hz)为单位,表示处理器每秒的时钟周期数。
-
定时查询方式: 一种设备 I/O 控制方式,通过定时查询的方式周期性地检查设备状态,以决定是否执行数据传输。
-
时钟周期: 在计算机中,时钟周期是处理器执行一条基本指令所需的时间,主频的倒数。
10. 外部中断的处理
- 中断隐指令的操作
- 中断服务程序的执行步骤
-
外部中断: 指 CPU 执行指令以外的事件产生的中断,通常是来自 CPU 与内存以外的中断,例如来自输入设备、定时器等外部事件引起的中断。
-
中断隐指令: 是指在处理中断时,系统自动执行的一些操作,通常包括关中断、保存断点、形成中断服务程序入口地址并送 PC 等。
-
关中断: 操作是为了在中断服务程序执行期间阻止其他中断的发生,以确保中断服务程序的完整执行。
-
保存通用寄存器的内容: 在进入中断服务程序后,为了防止中断服务程序的执行对通用寄存器的影响,通常需要将通用寄存器的内容保存起来。
-
形成中断服务程序入口地址并送 PC: 中断隐指令会将程序计数器(PC)设置为中断服务程序的入口地址,从而确保控制权被转移到正确的处理程序。
11. 中断 I/O 和 DMA 方式比较
- 中断 I/O 和 DMA 方式的区别
- 中断 I/O 和 DMA 方式的适用场景
-
中断 I/O 方式: 在这种方式下,每次 I/O 设备输入每个数据时,会向 CPU 发送中断请求,CPU 在中断处理程序中进行处理,然后继续执行其他任务。
-
DMA 方式: 在这种方式下,一个专门的 DMA 控制器负责在 CPU 与 I/O 设备之间直接传输数据,而无需 CPU 的干预。DMA 控制器通过请求总线使用权来进行数据传输。
12. 中断响应时间和 CPU 利用率
- 中断响应时间的计算
- CPU 用于设备 I/O 的时间占整个 CPU 时间的百分比计算
-
中断请求响应时间: 是指当设备发出中断请求时,系统从检测到中断请求到开始执行中断服务程序的时间。
-
中断处理时间: 是指执行中断服务程序所需的时间,包括处理中断请求、保存现场、执行中断服务程序和恢复现场等。
-
中断响应最长延迟时间: 表示系统能够容忍的中断响应的最长等待时间,即在中断请求发出后,系统需要在这个时间内响应并开始处理中断。
13. 中断 I/O 的信息交换
- CPU 和打印控制接口中的 I/O 端口之间交换的信息
-
中断 I/O 方式: 在这种方式下,CPU 通过中断响应的方式来处理外部设备的请求。在打印输出的情况下,打印控制接口与 CPU 之间通过 I/O 端口进行通信。
-
I/O 端口: 是指用于进行输入和输出操作的特定端口,通过它可以与外部设备进行数据交换。
14. DMA 方式的特点
- DMA 传送前的设置
- DMA 控制器请求总线使用权和数据传送的过程
-
多重中断系统: 是指系统能够同时处理多个中断请求,通过中断控制器或中断向量表等机制来管理多个中断源。
-
中断响应: 是指当中断请求发生时,系统采取的响应措施,通常包括保存当前进程状态、执行中断服务程序等。
-
关中断状态: 是指在中断处理期间关闭中断,以防止其他中断的干扰。
-
开中断状态: 是指在中断处理结束后允许中断的状态,以便系统能够响应其他中断。
15. CPU 时间占用百分比的计算
- CPU 用于设备输入/输出的时间占整个 CPU 时间的百分比的计算
-
外部 I/O 中断: 是指来自外部设备的中断请求,通常需要 CPU 响应并执行相应的中断服务程序。
-
中断控制器: 是负责管理和调度多个中断源的硬件设备,根据设定的中断优先级确定哪个中断会被响应。
-
中断隐指令: 是指在处理中断时,系统自动执行的一些操作,通常包括关中断、保存断点、引出中断服务程序等。
-
中断允许状态: 是指 CPU 允许响应中断的状态,通常通过设置开中断状态来表示。
16. DMA 方式的 CPU 利用率
- DMA 方式下 CPU 用于设备输入/输出的时间占整个 CPU 时间的百分比的计算
-
中断方式: 是指设备向 CPU 发送中断请求,CPU 响应中断并执行相应的中断服务程序,以完成设备与 CPU 之间的数据交换。
-
中断开销: 是指每次中断所需的时间,包括中断响应和中断处理的时间。
-
数据缓冲寄存器: 是设备接口中用于存储数据的寄存器,通过中断方式可以将其中的数据传输到 CPU。
-
数据传输率: 表示设备每秒钟能够传输的数据量。
-
CPU 主频: 是指 CPU 每秒钟执行的时钟周期数。
17. DMA 方式和外部 I/O 中断
- DMA 传送结束后的处理由谁完成
- DMA 方式中数据传送的直接控制方式
-
DMA方式: 是指系统中的DMA控制器负责直接控制数据在设备和内存之间的传输,减轻了CPU的负担。
-
设备驱动程序: 是一种软件模块,用于控制特定设备的操作。在DMA方式中,设备驱动程序通常负责设置DMA传输参数。
-
DMA控制器: 是一种硬件设备,用于管理DMA传输。它请求总线使用权,并直接控制数据在内存和设备之间的传输。
-
中断服务程序: 是在DMA传输结束后由CPU执行的程序,用于处理DMA传输完成后的相关工作。
18. 外部中断事件
- 知识点: 外部中断的类型和事件
-
外部中断事件: 是指来自 CPU 执行指令以外的事件引起的中断。这些事件通常与外部设备或系统的状态变化有关。
-
内部异常: 是指由于程序错误或特定条件而引起的异常情况,通常由CPU内部检测和处理。
19. 外部中断的特点
- 知识点: 可屏蔽中断和不可屏蔽中断的特性
-
外部中断: 是指来自CPU外部的中断请求,通常通过中断请求线INTR和不可屏蔽中断线NMI来触发。
-
不可屏蔽中断(NMI): 是一种特殊的外部中断,它的优先级比可屏蔽中断更高,且即使CPU处于关中断状态,也能被响应。
-
可屏蔽中断: 是一种由外部设备引起的中断,可以通过中断屏蔽字来改变其处理优先级。
20. 周期挪用 DMA 方式
- 知识点: 周期挪用 DMA 方式的数据传送
-
DMA方式: 是指系统中的DMA控制器负责直接控制数据在设备和内存之间的传输,减轻了CPU的负担。
-
周期挪用DMA方式: 是DMA的一种工作方式,DMA控制器在每准备好一定量的数据后,发起一次总线请求,然后挪用主存周期,将数据传送到主存。
-
数据块: 是指DMA传送的一段数据,通常由多个字节组成。
-
总线使用权: 是指DMA控制器在传送数据时获取了总线的使用权,阻止了CPU对总线的访问。
21. 多重中断系统
- 知识点: 多重中断系统的响应和检测条件
-
多重中断系统: 是指系统中存在多个中断源,可能同时发生多个中断请求,CPU需要按照优先级和屏蔽字的设置来选择响应的中断。
-
用户态和内核态: 是指CPU的运行状态,用户态是执行用户程序,而内核态是执行操作系统内核代码。
-
中断响应周期: 是指CPU在检测到中断请求后,进行中断响应的整个过程,包括保存断点、选择中断服务程序、执行中断服务程序等步骤。
-
中断允许状态: 是指CPU是否允许中断的发生,通常通过中断屏蔽字的设置来控制。
22. 中断 I/O 方式
- 知识点: 中断 I/O 方式的特点和适用场景
- 中断 I/O 方式: 是一种 I/O 操作方式,其中外设通过发出中断请求通知 CPU 完成数据传输,而不需要 CPU 不断轮询检查外设状态。
23. CPU 时间占用百分比的计算
-
知识点: 计算 CPU 时间占用百分比的公式
-
CPU主频: 指中央处理器(CPU)每秒钟完成的振荡周期数,通常以赫兹(Hz)为单位,表示处理器的运行速度。
-
CPI(Clocks Per Instruction): 表示每条指令执行所需的平均时钟周期数。CPI的值越低,说明平均执行一条指令所需的时钟周期越少,性能越高。
-
中断方式: 一种计算机系统的工作方式,其中外设通过发出中断请求,请求CPU暂停当前执行的任务,转而执行与中断相关的服务程序,处理完中断后再返回原任务。
-
中断服务程序: 用于响应中断请求的一段特殊程序,通常由操作系统提供。当系统发生中断时,CPU会跳转执行相应的中断服务程序来处理中断事件。
-
DMA(Direct Memory Access): 直接内存访问,是一种数据传输方式,允许外设直接与内存进行数据传输,而无需CPU的直接参与。DMA可以提高数据传输的效率,减轻CPU的负担。
-
DMA预处理和后处理: 在DMA传输过程中,涉及到一些预处理和后处理的步骤,用于初始化DMA控制器和完成传输后的清理工作。
-
访存冲突: 当两个或多个设备(如CPU和DMA)试图同时访问同一块内存区域时可能发生的冲突。访存冲突可能导致数据的不一致性或传输错误。
-
数据块传送: 在I/O操作中,指一次性传送的数据单位。DMA通常按照数据块的大小进行传输。
以上解释提供了相关专业名词的基本概念,有助于理解计算机系统中涉及的硬件和数据传输的概念。
24. 计算机性能参数
-
知识点: 计算机性能参数的计算
-
MIPS(Million Instructions Per Second): 衡量计算机性能的单位,表示每秒执行的百万条指令数。计算方法为 CPU 主频除以每条指令平均时钟周期数(CPI)。
-
Cache命中率: 在计算机系统中,指CPU访问的数据或指令是否能够在高速缓存(Cache)中找到的概率。以百分比表示,高命中率表示高效的Cache利用。
-
访存带宽: 指CPU与主存之间数据传输的速率,通常以每秒传输的数据量为单位。高访存带宽有助于满足CPU对内存的高速读写需求。
-
缺页率: 在虚拟存储系统中,表示程序运行过程中发生页面缺失的频率,即CPU访问的页面不在内存中的概率。
-
DMA请求: 直接内存访问(DMA)时,外设向DMA控制器发送的请求,通知DMA控制器执行数据传输操作。DMA请求通常包括对存储器总线的请求。
-
交叉存储模式: 主存存储单元分成若干体,每个体独立工作,交叉存储模式通过轮流使用各个体的存储单元,提高了主存的并发访问性能。
以上解释提供了相关专业名词的基本概念,有助于理解计算机系统中与性能、存储访问等方面相关的概念。
25. 外设的异步串行通信
-
知识点: 异步串行通信方式和串口数据传输
-
异步串行通信: 一种数据传输方式,数据位逐位依次传输,字符之间没有固定的时间间隔,通信双方的时钟不同步。
-
奇校验位: 通信中用于保证数据传输正确性的一种校验方法。使得数据位的总和(包括奇校验位)为奇数,以检测传输过程中的错误。
-
停止位: 在串行通信中,规定数据位之后的位数,用于告知接收端数据位的结束。一般用 1 位或 2 位停止位。
-
中断方式: 计算机系统中一种处理 I/O 事件的方法。当外设需要处理时,通过中断信号通知 CPU,CPU 暂停当前任务转而处理中断服务程序。
-
中断响应时间: CPU 从接收中断请求到开始执行中断服务程序的时间,通常包括中断响应的准备时间。
-
中断服务程序: 一段程序,用于处理特定中断事件。包括对中断源的响应、保存断点和程序状态、执行中断服务的相关操作。
-
时钟周期: 计算机系统中基本的时间单位,表示 CPU 执行一条基本指令所需的时间。与 CPU 主频有关,通常以纳秒(ns)为单位。
以上解释提供了相关专业名词的基本概念,有助于理解计算机系统中与异步串行通信、中断处理等方面相关的概念。
26. I/O 方式的时间占用百分比计算
- 知识点: 计算 I/O 方式的时间占用百分比
1)定时查询 I/O 方式: 一种 I/O 数据传输方式,通过定时轮询设备状态来检查是否有数据传输的需要。CPU 定期查询设备状态,若设备就绪,则执行相应的输入/输出操作。
2)中断 I/O 方式: 一种 I/O 数据传输方式,设备在就绪时通过中断信号通知 CPU 进行数据传输。CPU 响应中断后执行中断服务程序,完成与设备之间的数据交换。
3)DMA 方式: 直接存储器访问(Direct Memory Access,DMA)是一种计算机数据传输方式,允许外设直接与主存储器交换数据,而无需 CPU 参与每一个数据传输周期。
以上解释提供了相关专业名词的基本概念,有助于理解计算机系统中与定时查询 I/O、中断 I/O、DMA 等方面相关的概念。
27. 磁盘驱动器的结构和性能参数
- 知识点: 磁盘驱动器的组成和性能参数计算
1)地址字段:
- 柱面号(磁道号): 表示磁盘上的一个圆柱面,即同一磁道号的磁道位于多个盘片上。
- 磁头号(盘面号): 表示磁盘的读写磁头,用于选择盘片上的磁面。
- 扇区号: 表示磁道上的一个扇区,即磁道被划分为多个等长的数据块。
每个字段的位数由磁盘容量和结构决定,例如,柱面号至少占 [log2(磁道总数)] 位,磁头号至少占 [log2(盘片总数 × 盘面数)] 位,扇区号至少占 [log2(每磁道扇区数)] 位。
2)平均访问时间:
- 寻道时间: 移动磁头到目标磁道的时间。
- 延迟时间: 等待目标扇区旋转到磁头下方的时间。
- 传输时间: 从磁盘读/写数据到数据传送完毕的时间。
平均访问时间是这三者的综合,受到磁盘性能和机械结构的影响。
3)DMA 控制器:
- 总线请求: DMA 控制器通过总线请求通知 CPU,请求使用系统总线。
- 周期挪用 DMA 方式: DMA 控制器通过挪用主存周期实现数据传送。
在磁盘与主机之间的数据传送中,DMA 控制器向 CPU 发送的总线请求次数取决于数据缓冲区的大小,即每次充满缓冲区发生一次请求。在周期挪用 DMA 方式下,DMA 控制器可优先获得总线使用权,确保及时数据传送。
以上解释有助于理解涉及磁盘结构、访问时间和 DMA 控制器的相关概念。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- .NetCore Flurl.Http 升级到4.0后 https 无法建立SSL连接
- MySQL中的自连接
- 2024合成生物学及发酵前沿技术与智能装备论坛暨答谢晚宴
- 图论-并查集
- 05 RESTFul
- SOC系统经典IP介绍以及使用方法说明之dw_i2c
- 使用some 或者 every 方法遇到异常没有return
- Java毕业设计基于Springboot棋牌室管理系统
- CentOS 开启BBR
- 12.27_黑马数据结构与算法笔记Java