CMU15-445-Spring-2023-Project #2 - 前置知识(lec07-010)
Lecture #07_ Hash Tables
Data Structures

Hash Table
哈希表将键映射到值。它提供平均 O (1) 的操作复杂度(最坏情况下为 O (n))和 O (n) 的存储复杂度。
由两部分组成: Hash Function和Hashing Scheme(发生冲突后的处理)
Hash Functions
DBMS 一般只关注散列速度和冲突率,不考虑安全性
SOTA:Facebook XXHash3
Static Hashing Schemes
静态散列方案是一种散列表大小固定的方案。
- Linear Probe Hashing
- 线性探针
- 散列函数将键映射到槽。当发生碰撞时,线性搜索相邻的插槽,直到找到一个打开的插槽。删除时设置一个删除标记而不是真正的删除。
- Robin Hood Hashing
- 线性探针散列的一种扩展,旨在减少每个key与其在散列表中的原本位置之间的最大距离(距离记为dis)。
- 线性探测过程中,若插入的key的dis比当前slot记录的dis大,就将其替换,并将旧key重新向后插入。
- Cuckoo Hashing
- 使用具有不同哈希函数种子的多个哈希表;
- 插入时,检查每个表,挑选有空闲位置的表;
- 如果没有空闲的位置,则将随机一个表中冲突位置的旧元素驱逐出去,然后重新哈希找到新的位置;
Dynamic Hashing Schemes
动态散列方案能够根据需要调整哈希表的大小,而无需重建整个表。
- Chained Hashing
- 链表法
- Extendible Hashing
- Linear Hashing
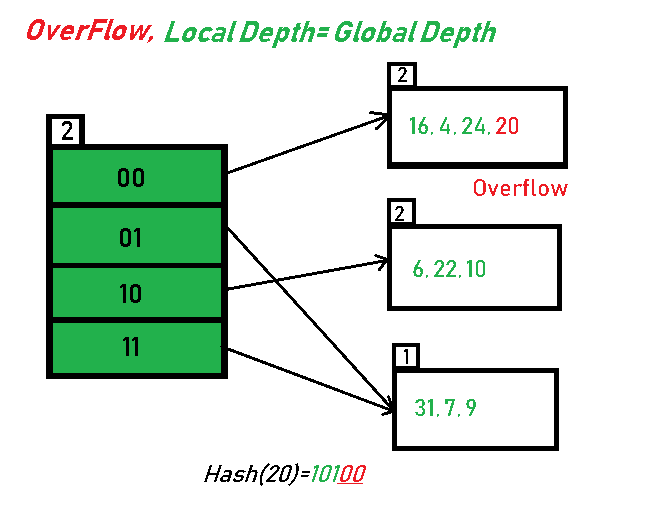
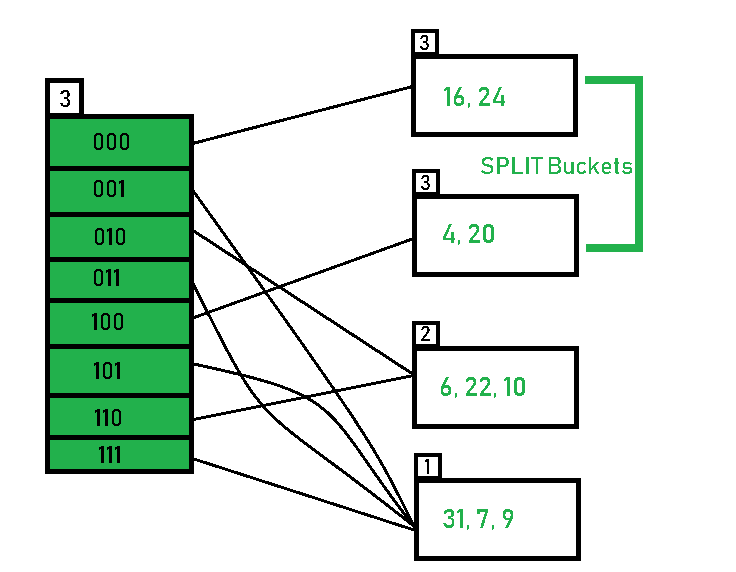
- 这种方案不会在数据桶溢出时立即拆分,而是维护一个拆分指针,跟踪下一个要拆分的数据桶。无论该指针是否指向已溢出的数据桶,数据库管理系统都会进行拆分
Lecture #08_ Tree Indexes
Table Indexes
表索引是表列子集的复制,通过对这些属性的子集进行组织或排序,以实现高效访问。因此,DBMS可以对表索引进行查找,以更快地找到某些图元,而不是执行顺序扫描。DBMS 确保表和索引的内容在逻辑上始终保持同步。
B+Tree
B+Tree 是一种自平衡树形数据结构,它能保持数据排序,并允许在 O(log(n))内进行搜索、顺序访问、插入和删除。
B-Trees 在所有节点中存储键和值,而 B+ 树只在叶子节点中存储值。现代的 B+Tree 实现结合了其他 B-Tree 变体的特征,例如 B link-Tree 中使用的同胞指针。
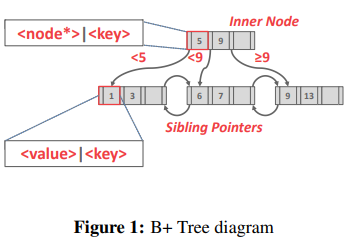
B+Tree 是一棵 M 向搜索树(其中 M 代表一个节点可拥有的最大子节点数),具有以下属性:
- 它是完全平衡的(即每个叶节点的深度相同);
- 除根节点外,每个内部节点至少有一半(M/2 <= 键数 <= M - 1);
- 每个有 k 个键的内部节点都有 k+1 个非空子节点;
对于叶节点,键来自索引所基于的属性。每个节点上的k/v数组几乎都是按键排序的。叶节点值的两种方法是记录 ID 和元组数据。记录 ID 指的是元组位置的指针,通常是主键。拥有元组数据的叶子节点会在每个节点中存储元组的实际内容。
对于内部节点来说,值包含指向其他节点的指针,而键可以被看作是引导桩。 它们引导着树的遍历,但并不代表叶子节点上的键(以及它们的值)。内部节点只拥有叶子节点中的键。
对于重复的key,一种方法是增加记录id作为key的一部分,另一种方法是允许叶节点溢出到包含重复密钥的溢出节点中。
表按照主键指定的排序顺序,以堆栈或索引组织的存储方式存储。 由于有些 DBMS 总是使用聚类索引,因此如果表没有显式主键,它们就会自动将隐藏行 id 作为主键。如果使用聚类索引的属性访问图tuple,DBMS可以直接跳转到页面。
由于直接从非聚类索引中检索tuple的效率很低,因此 DBMS 可以先找出它需要的所有tuple,然后根据它们的页面 id 对它们进行排序。
B+Tree Design Choices
Node Size一般取决于存储介质或者workload。
删除后立即合并叶子节点可能会导致混乱,大量连续的删除和插入操作会导致不断的拆分和合并。可以设置分批合并,即多个合并操作同时进行,从而减少在树上进行昂贵的写入延迟的时间。
支持可变长度的键:
- 不直接存储键,而是存储一个指向键的指针。由于必须为每个键追逐一个指针的效率很低,在生产中使用这种方法的只有嵌入式设备,因为其微小的寄存器和高速缓存可以从这种空间节省中受益;
- 我们可以将每个密钥的大小设置为最大密钥的大小,然后将所有较短的密钥填充,而不是改变密钥的大小。在大多数情况下,这样做会极大地浪费内存;
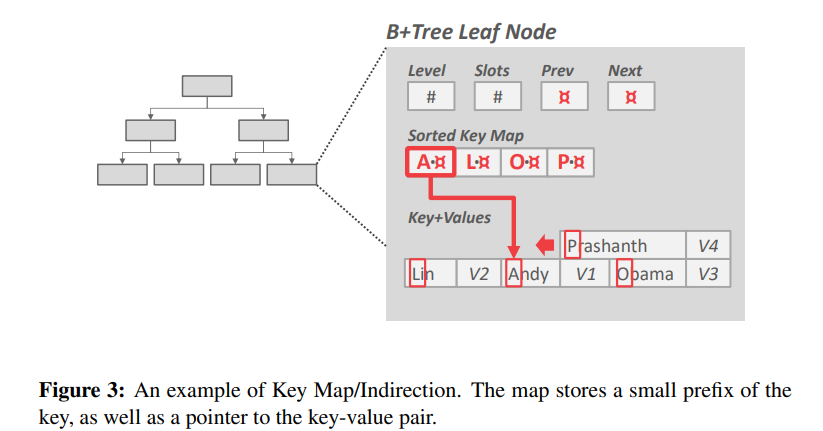
- 最常用的方法是在单独的字典中用k/v索引来代替键。嵌入一个指针数组,该指针映射到节点内的键 + 值列表。
节点内搜索:
- O(n) 线性搜索;
- 更有效的搜索方案是对每个节点进行排序,并使用二分搜索来查找键。每次搜索的复杂度只有 O(ln(n))。不过,由于我们必须维护每个节点的排序,因此插入的成本会更高;
- 利用插值法来找到关键字。这种方法会利用节点存储的元数据(如最大元素、最小元素、平均值等),并利用这些元数据生成关键字的大致位置;
Optimizations
由于 B+Tree 的每个节点都存储在缓冲池中的一个页面中,因此每次加载一个新页面时,都需要从缓冲池中获取该页面。为了完全跳过这一步,可以存储实际的原始指针来代替页面 ID。与手动获取整个树并手动放置指针相比,我们只需在正常遍历索引时存储页面查找产生的指针即可。需要注意的是,我们必须跟踪哪些指针被转换,并在指针指向的页面被unpin和驱逐时,将指针转换回页面 ID。
在 B+Tree 的初始构建过程中,按照常规方法插入每个键会导致不断的拆分操作。由于我们已经给叶子提供了同级指针,所以如果我们构建一个叶子节点的排序链表,然后使用每个叶子节点的第一个键自下而上地建立索引,那么初始插入数据的效率就会高得多。
前缀压缩。
对于非唯一key,只存储一次key。
只存储将查找正确路由到叶子节点所需的最小前缀。
Lecture #09_ Index Concurrency Control
Index Concurrency Control
逻辑正确性:这意味着线程能够读取它应该读取的值,例如,线程应该读回它之前写入的值。
物理正确性:这意味着对象的内部表示是正确的,例如,数据结构中不存在会导致线程读取无效内存位置的指针。
Locks vs. Latches
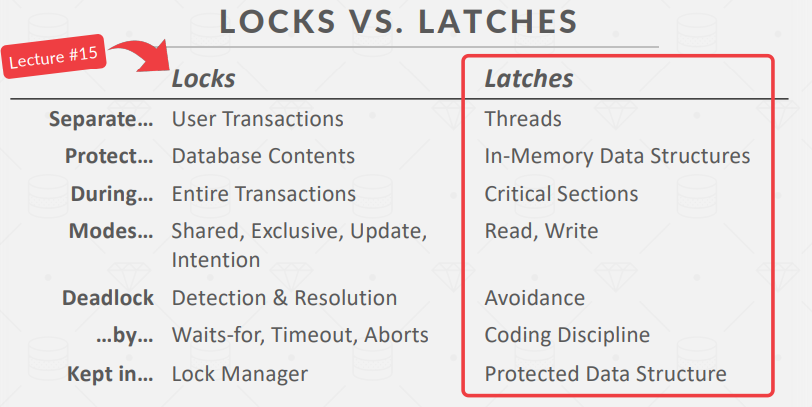
Latch Implementations
实现latch的基本原理是现代 CPU 提供的原子比较和交换(compare-and-swap,CAS)指令。通过该指令,线程可以检查内存位置的内容,查看其是否具有特定值。如果有,CPU 就会将旧值换成新值。否则,内存位置将保持不变。
- Blocking OS Mutex
- Test-and-Set Spin Latch (TAS)
- Reader-Writer Latches



Hash Table Latching
在动态哈希表上相对更复杂。
- page latch:每个页面都有自己的读写锁,保护其全部内容。线程在访问页面前会获得一个读写锁。这降低了并行性,因为每次可能只有一个线程能访问一个页面,但访问页面中的多个插槽对单个线程来说速度很快,因为它只需获取一个锁存器。
- slot latch:每个插槽都有自己的锁存器。这增加了并行性,因为两个线程可以访问同一页面上的不同插槽。但这会增加访问表的存储和计算开销,因为线程必须为访问的每个槽获取一个锁存器,而且每个槽都必须为锁存器存储数据。DBMS 可以使用单模式锁存器(即spin latch)来减少元数据和计算开销,但代价是一定的并行性。
利用CAS也是一种方法。
B+Tree Latching

Basic:

Improved:

B+树代码必须能应对失败的锁存器获取。由于latch的持有时间(相对)较短,如果线程试图获取叶节点上的latch,但该latch不可用,那么它应迅速中止操作(释放持有的任何latch),然后重新开始操作。
Lecture #10_ Sorting & Aggregation Algorithms
Query Plan
数据库系统会将 SQL 编译成查询计划。查询计划是一棵运算符树。
Sorting
DBMS 需要对数据进行排序,因为根据关系模型,表中的tuple没有特定的顺序。排序使用 ORDER BY、GROUP BY、JOIN 和 DISTINCT 操作符。如果需要排序的数据适合内存,那么 DBMS 可以使用标准排序算法(如快排)。如果数据不适合在内存中进行排序,那么 DBMS 就需要使用外部排序,这种排序可以根据需要溢出到磁盘,并且优先选择顺序 I/O,而不是随机 I/O。
如果查询包含一个带 LIMIT 的 ORDER BY,那么 DBMS 只需扫描一次数据就能找到前 N 个元素。这就是 top-n 堆排序。堆排序的理想情况是前 N 个元素都在内存中,这样 DBMS 只需在扫描数据时维护一个内存中的优先队列即可。
外部合并排序是对大到内存无法容纳的数据进行排序的标准算法。这是一种 "分而治之 "的排序算法,它将数据分割然后分别进行排序。
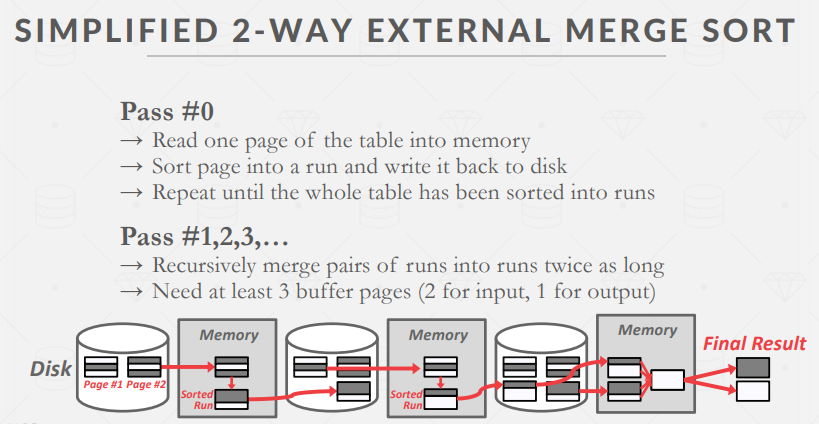
外部合并排序的一种优化方法是在后台预取下一次运行,并在系统处理当前运行时将其存储在第二个缓冲区中。这样可以持续利用磁盘,减少每一步 I/O 请求的等待时间。
对于 DBMS 来说,使用现有的 B+tree 索引辅助排序有时比使用外部合并排序算法更有优势。特别是,如果索引是聚簇索引,DBMS 就可以直接遍历 B+tree 索引。由于索引是聚类的,数据将以正确的顺序存储,因此 I/O 访问将是顺序的。
Aggregations
实现聚合有两种方法:排序和散列。
排序:DBMS 首先根据 GROUP BY 键对图元进行排序。如果所有数据都在缓冲池中(如 quicksort),可以使用内存内排序算法;如果数据大小超出内存,可以使用外部合并排序算法。然后,DBMS 会对排序后的数据执行顺序扫描,以计算聚合。运算符的输出将按键排序。在执行排序聚合时,必须对查询操作进行排序,以最大限度地提高效率。 例如,如果查询需要过滤,最好先执行过滤,然后对过滤后的数据进行排序,以减少需要排序的数据量。
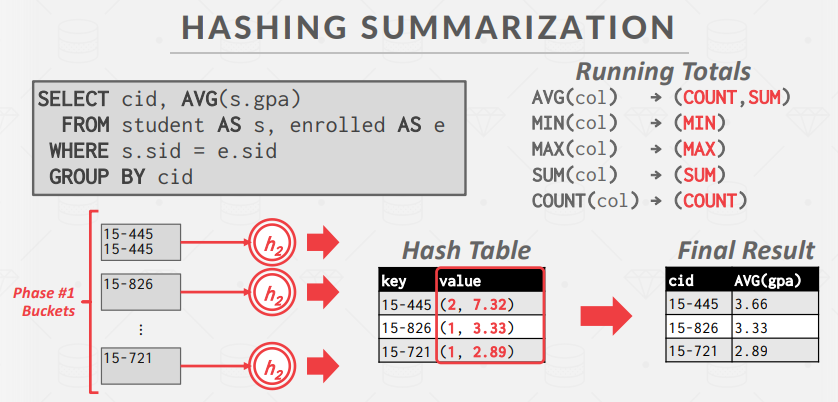
哈希:
- Partition:使用哈希函数 h1,根据目标哈希键将tuple分组到磁盘上的分区。这将把所有匹配的元组放入同一个bucket。假设共有 B 个缓冲区,我们将有 B-1 个输出缓冲区和 1 个输入缓冲区。如果任何分区已满,数据库管理系统就会将其溢出到磁盘。
- ReHash:对于磁盘上的每个分区,将其页面读入内存,并根据第二个哈希函数 h2 建立一个内存哈希表。然后遍历哈希表中的每个桶,将匹配的tuple集中起来计算聚合。假设每个分区都适合内存。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- App各大应用商城的排名被哪些因素影响着?(苹果/谷歌篇
- 力扣(leetcode)第27题移除元素(Python)
- 多租户数据隔离分案
- c++类的静态成员变量和非静态成员变量定义和初始化为什么有区别?
- [嵌入式C][入门篇] 快速掌握基础4 (普通函数,递归函数,函数指针,弱函数)
- 【MATLAB源码-第100期】基于matlab的OFDM系统papr抑制算法对比,clipping,PTS,SLM。
- 结构体基础例题
- 数据预处理:标准化和归一化
- Python之字符串中常用的方法
- 删除注释(C语言)