(11-3-7 )检测以太坊区块链中的非法账户:模型评估
11.3.7 ?模型评估
模型评估(Model Evaluation)是在机器学习和统计建模中的重要步骤,用于评估构建的模型的性能和有效性。它涉及使用不同的指标和技巧来量化模型在处理数据和进行预测时的表现,并帮助确定模型是否足够好以满足特定任务的需求。
(1)对模型进行全面评估,包括在训练集和测试集上的性能评估,并绘制了精确度-召回率曲线,以更全面地了解模型的性能和潜在问题。具体实现代码如下所示。
def model_fit_evaluation2(model_model, params, X_train, y_train, X_val, y_val, algo=None, sampling=None):
start_time = time.time()
rcv = RandomizedSearchCV(model_model, params, cv=10, scoring='roc_auc', n_jobs=-1, verbose=1, random_state=23)
rcv.fit(X_train, y_train)
print('\n')
print('best estimator : ', rcv.best_estimator_)
print('best parameters: ', rcv.best_params_)
print('best score: ', rcv.best_score_)
print('\n')
y_train_pred= (rcv.best_estimator_).predict(X_train)
y_test_prob1=(rcv.best_estimator_).predict_proba(X_test)[:,1]
y_test_pred= (rcv.best_estimator_).predict(X_test)
print("--- %s seconds ---" % (time.time() - start_time))
draw_roc(y_train, y_train_pred)
print("Training set metrics")
print ('AUC for the {} Model {} sampling technique'.format(algo,sampling), metrics.roc_auc_score( y_train, y_train_pred))
model_metrics(rcv,y_train, y_train_pred)
print('*'*50)
print("Test set metrics")
draw_roc(y_test, y_test_pred)
print ('AUC for the {} Model {} sampling technique'.format(algo,sampling), metrics.roc_auc_score(y_test, y_test_pred))
model_metrics(rcv,y_test, y_test_pred)
precision, recall, thresholds = precision_recall_curve(y_test, y_test_prob1)
plt.fill_between(recall, precision, step='post', alpha=0.2,
color='#F59B00')
plt.ylabel("Precision")
plt.xlabel("Recall")
plt.title("Test Precision-Recall curve");
model_fit_evaluation2(model_GB, params_gb, X_train_ro, y_train_ro, X_test, y_test, 'GradientBoosting', 'oversampling')在上述代码中,使用测试数据集 X_test 和 y_test 来评估模型的性能,而不仅仅是训练和验证数据集。具体来说,上述代码的功能包括:
- 使用 RandomizedSearchCV 对指定的机器学习模型(model_model)进行超参数调优。超参数在 params 中定义,并通过交叉验证来选择最佳的超参数组合。
- 输出最佳模型的估计器(best_estimator_)、最佳超参数(best_params_)和最佳得分(best_score_)。
- 使用最佳模型对训练数据集 X_train 进行预测,得到预测结果 y_train_pred。
- 使用最佳模型对测试数据集 X_test 进行预测,得到预测结果 y_test_pred 和类别概率预测 y_test_prob1。
- 绘制训练集和测试集的 ROC 曲线,并计算 AUC(ROC 曲线下面积)以评估模型性能。
- 输出训练集和测试集的性能指标,包括 AUC、准确率、召回率、精确度、F1 分数、混淆矩阵等。
- 绘制测试集的精确度-召回率曲线(Precision-Recall Curve)。
执行后输出使用交叉验证(10折交叉验证)选择最佳超参数的过程以及相应的结果:
Fitting 10 folds for each of 10 candidates, totalling 100 fits
best estimator : ?GradientBoostingClassifier(learning_rate=0.5, n_estimators=50)
best parameters: ?{'n_estimators': 50, 'learning_rate': 0.5}
best score: ?0.9993991240384741
--- 72.88349509239197 seconds ---上面的输出包括了训练集和测试集上的性能指标以及精确度-召回率曲线。总的来说,这个模型在训练集和测试集上都表现出色,但需要注意过拟合的可能性,因为训练集上的性能远远高于测试集。
另外上面的代码执行后还会绘制“精确度-召回率”曲线(Precision-Recall curve),如图11-8所示。这是测试集上模型性能的可视化指标之一,这个曲线用于可视化模型在不同召回率和精确度下的表现,有助于更全面地评估模型的性能。
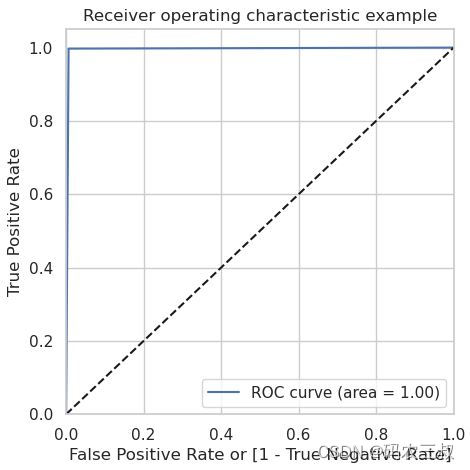
图11-8 ?“精确度-召回率”曲线
(2)在下面的代码中,每一行代码都执行了不同模型的评估,使用不同的采样技术(oversampling或SMOTE)以及不同的超参数进行配置。
model_fit_evaluation2(model_GB, params_gb, X_train_smote, y_train_smote, X_test, y_test, 'GradientBoosting', 'smote')
model_fit_evaluation2(model_LGBM, params_lgbm, X_train_ro, y_train_ro, X_test, y_test, 'LightGradientBoosting', 'Over smapling')
model_fit_evaluation2(model_LGBM, params_lgbm, X_train_smote, y_train_smote, X_test, y_test, 'LightGradientBoosting', 'smote')
model_fit_evaluation2(model_cat, params_cat, X_train_ro, y_train_ro, X_test, y_test, 'Cat Boosting', 'Over sampling')
model_fit_evaluation2(model_cat, params_cat, X_train_smote, y_train_smote, X_test, y_test, 'Cat Boosting', 'SMOTE')上面一共5行代码,具体说明如下:
- 第1行:评估了Gradient Boosting模型,采样技术为SMOTE,输出了模型的性能指标以及Precision-Recall曲线。
- 第2行:评估了Light Gradient Boosting模型,采样技术为Over sampling,输出了模型的性能指标以及Precision-Recall曲线。
- 第3行:评估了Light Gradient Boosting模型,采样技术为SMOTE,输出了模型的性能指标以及Precision-Recall曲线。
- 第4行: 评估了Cat Boosting模型,采样技术为Over sampling,输出了模型的性能指标以及Precision-Recall曲线。
- 第5行:评估了Cat Boosting模型,采样技术为SMOTE,输出了模型的性能指标以及Precision-Recall曲线。
上面的每个评估都采用了相同的评估步骤,包括超参数调优、性能指标计算和绘制Precision-Recall曲线。评估的目的是确定每个模型在不同采样技术下的性能表现,以及它们是否适用于测试数据集。例如第5行代码输出下面的内容结果:
AUC for the Cat Boosting Model SMOTE sampling technique 0.9802106230517987
Accuracy ???: ?0.9827411167512691
Sensitivity : ?0.9758454106280193
Specificity : ?0.9845758354755784
Precision ??: ?0.9439252336448598
Recall ?????: ?0.9758454106280193
F1_score: 0.9596199524940617
[[766 ?12]
?[ ?5 202]]上面输出的是Cat Boosting模型在SMOTE采样技术下的性能评估结果,其中AUC(Area Under the Curve)为0.9802,这是ROC曲线下的面积,用于衡量模型的分类性能。AUC越接近1,模型性能越好。接下来是混淆矩阵中的各项指标:
- 准确度(Accuracy)为0.9827,表示模型正确分类的样本比例为98.27%。
- 敏感度(Sensitivity)为0.9758,也称为真正例率(True Positive Rate),表示模型正确预测正例的比例。
- 特异度(Specificity)为0.9846,也称为真负例率(True Negative Rate),表示模型正确预测负例的比例。
- 精确度(Precision)为0.9439,表示模型在预测为正例的样本中,实际为正例的比例。
- 召回率(Recall)为0.9758,与敏感度相同,表示模型正确预测正例的比例。
- F1分数(F1 Score)为0.9596,综合考虑了精确度和召回率,是一个综合性能指标。
最后,混淆矩阵显示了模型的分类结果。其中,766个样本被正确分类为负例(真负例),202个样本被正确分类为正例(真正例),12个样本被错误分类为正例(假正例),5个样本被错误分类为负例(假负例)。
综合来看,我们的模型在SMOTE采样技术下表现良好,具有较高的准确度、敏感度和特异度,适合应对类别不
另外,上面的5行代码还会为每个评估绘制可视化图,其中包括ROC曲线和Precision-Recall曲线,例如例如第5行代码的绘图如图11-9所示。这些图有助于可视化模型在不同采样技术下的性能表现,以及模型在测试数据集上的性能。这些图有助于更好地理解模型的性能,并进行比较和分析。

图11-9 ?Cat Boosting模型的ROC曲线图
本篇已完结
(11-3-01 )检测以太坊区块链中的非法账户-CSDN博客
(11-3-02)检测以太坊区块链中的非法账户: 数据分析(1)-CSDN博客
(11-3-03)检测以太坊区块链中的非法账户: 数据分析(2)-CSDN博客
(11-3-04 )检测以太坊区块链中的非法账户:Train-Test Split(拆分数据集)-CSDN博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SQLServer设置端口,并设置SQLServer和SQLServer Browser服务
- springCould-从小白开始【1】
- 13 个有趣的 Python 高级脚本
- 关于“Python”的核心知识点整理大全27
- 231.【2023年华为OD机试真题(C卷)】小明找位置(二分查找-Java&Python&C++&JS实现)
- 第二十一章总结
- HarmonyOS4.0系统性深入开发25访问DataAbility
- Django(五)
- java中list,map习题
- EI级 | Matlab实现VMD-TCN-GRU变分模态分解结合时间卷积门控循环单元多变量光伏功率时间序列预测