19、BLIP-2
简介
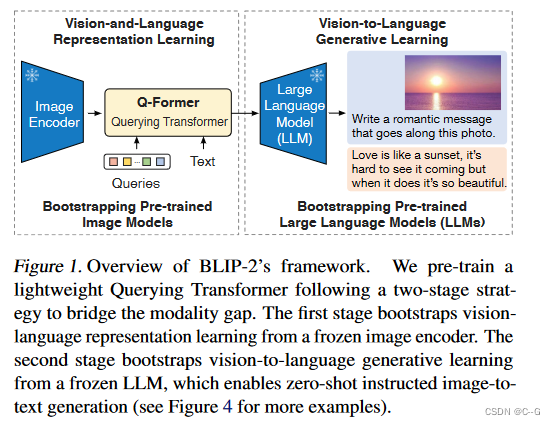
?通过利用预训练的视觉模型和语言模型来提升多模态效果和降低训练成本,预训练的视觉模型能够提供高质量的视觉表征,预训练的语言模型则提供了强大的语言生成能力。
实现过程

?为了弥合模态差距,提出了一个分两个阶段预训练的 Querying Transformer (Q-Former):
- 使用冻结Image Transformer的视觉语言表示学习阶段
- 使用冻结LLM的视觉到语言生成学习阶段
model
?Q-Former由两个Transformer子模块组成,它们共享相同的自关注层:
- 与冻结Image Encoder交互以提取视觉特征的Image Transformer
- 既可以作为Image Encoder又可以作为Image Decoder的Text Transformer
?queries通过 self-attention layers 相互交互,并通过 cross-attention layers (每隔一个转换块插入)与冻结的图像特征交互。queries 还可以通过相同的 self-attention layers 与文本交互。
?根据预训练任务的不同,应用不同的 self-attention 掩码来控制 query-text 交互。使用 B E R T b a s e BERT_{base} BERTbase? 的预训练权重初始化QFormer ,而 cross-attention layers 是随机初始化的。Q-Former共包含188M个参数。queries 被视为模型参数。
?论文中使用32个queries维度为768,与Q-Former的中间层维度一样,其输出的 Z 的大小(32 × 768)远远小于冻结图像特征的大小(例如viti - l /14的257 × 1024)
Training
?为了减少计算成本并避免灾难性遗忘的问题,BLIP-2 在预训练时冻结预训练图像模型和语言模型,但是,简单地冻结预训练模型参数会导致视觉特征和文本特征难以对齐,为此BLIP-2提出两阶段预训练 Q-Former 来弥补模态差距:表示学习阶段和生成学习阶段。
表示学习阶段
?在表示学习阶段,将 Q-Former 连接到冻结的 Image Encoder,训练集为图像-文本对,通过联合优化三个预训练目标,在Query和Text之间分别采用不同的注意力掩码策略,从而控制Image Transformer和Text Transformer的交互方式
Image-Text Contrastive Learning (ITC)
ITC的优化目标是对齐图像嵌入和文本嵌入,将来自Image Transformer输出的Query嵌入 z 与来自Text Transformer输出的文本嵌入 t 对齐,为了避免信息泄漏,ITC采用了单模态自注意掩码,不允许Query和Text相互注意。具体来说,Text Transformer的文本嵌入是 [CLS] 标记的输出嵌入,而Query嵌入则包含多个输出嵌入,因此首先计算每个Query输嵌入与文本嵌入之间的相似度,然后选择最高的一个作为图像-文本相似度。
Image-grounded Text Generation (ITG)
ITG 是在给定输入图像作为条件的情况下,训练 Q-Former 生成文本,迫使Query提取包含文本信息的视觉特征。由于 Q-Former 的架构不允许冻结的图像编码器和文本标记之间的直接交互,因此生成文本所需的信息必须首先由Query提取,然后通过 self-attention layers 传递给文本标记。ITG采用多模态Causal Attention掩码来控制Query和Text的交互,Query可以相互关注,但不能关注Text标记,每个Text标记都可以处理所有Query及其前面的Text标记。这里将 [CLS] 标记替换为新的 [DEC] 标记,作为第一个文本标记来指示解码任务。
Image-Text Matching (ITM)
ITM是一个二元分类任务,通过预测图像-文本对是正匹配还是负匹配,学习图像和文本表示之间的细粒度对齐。这里将Image Transformer输出的每个Query嵌入输入到一个二类线性分类器中以获得对应的logit,然后将所有的logit平均,再计算匹配分数。ITM使用 bi-directional self-attention 掩码,所有Query和Text都可以相互关注。
生成学习阶段
?在生成预训练阶段,将 Q-Former连接到冻结的 LLM,以利用 LLM 的语言生成能力。这里使用全连接层将输出的Query嵌入线性投影到与 LLM 的文本嵌入相同的维度,然后将投影的Query嵌入添加到输入文本嵌入前面。由于 Q-Former 已经过预训练,可以提取包含语言信息的视觉表示,因此它可以有效地充当信息瓶颈,将最有用的信息提供给 LLM,同时删除不相关的视觉信息,减轻了 LLM 学习视觉语言对齐的负担。
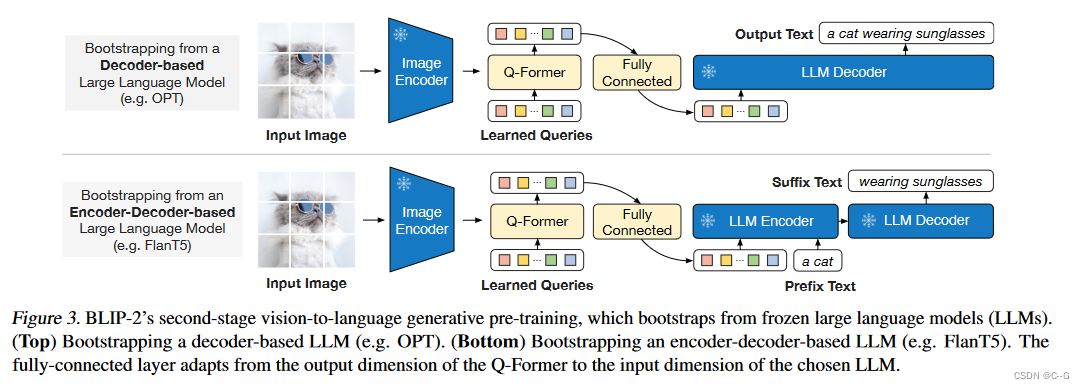
?BLIP-2试验了两种类型的 LLM:基于解码器的 LLM 和基于编码器-解码器的 LLM。对于基于解码器的 LLM,使用语言建模损失进行预训练,其中冻结的 LLM 的任务是根据 Q-Former 的视觉表示生成文本。对于基于编码器-解码器的 LLM,使用前缀语言建模损失进行预训练,将文本分成两部分,前缀文本与视觉表示连接起来作为 LLM 编码器的输入,后缀文本用作 LLM 解码器的生成目标。
VQA-finetuning
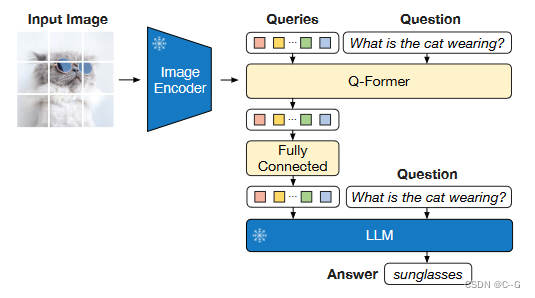
LLM接收Q-Former的输出并将问题作为输入,然后预测答案。还将问题作为条件提供给Q-Former,使得提取的图像特征与问题更加相关。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue购物车案例、v-model进阶、与后端交互
- 链表相关题目(数据结构期末复习)
- 工程监测振弦采集仪的信号处理与分析方法研究
- 无心剑汉英双语诗《一亩三分地》
- 智能锁语音提示芯片选型otp还是flash型的有什么特点
- 如何快速打造属于自己的接口自动化测试框架
- 上门洗车小程序开发源码,预约上门或到店洗车
- 今日小寒|三九将至,注意防寒保暖
- CUDA+Anaconda+Pytorch环境安装
- 【时间复杂度】时间复杂度优化法则简讲