2023.12.13 关于 MySQL 复杂查询
发布时间:2023年12月18日
目录
聚合查询
聚合函数
函数 说明 COUNT([DISTINCT] expr) 返回查询到的数据的数量 SUM([DISTINCT] expr) 返回查询到的数据的总和 AVG([DISTINCT] expr) 返回查询到的数据的平均值 MAX([DISTINCT] expr) 返回查询到的数据的最大值 MIN([DISTINCT] expr) 返回查询到的数据的最小值 注意:
- 求和、平均值、最大、最小 这几个函数都需要针对数字类型的列
实例理解
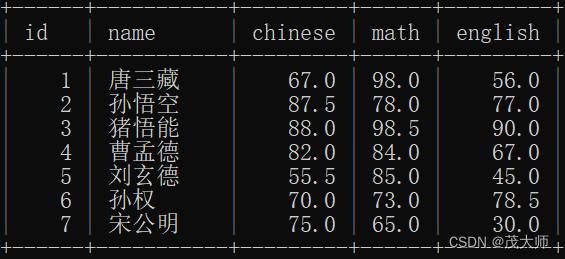
- 此处我们创建一个 exam_result 表,并插入几条数据
- 使用 count?查询返回结果的行数
select count(*) from exam_result;执行结果:
- 使用 sum 查询 chines 字段数据的和(针对某一列计算)
select sum(chinese) from exam_result;?执行结果:
- 使用 avg?查询 chines + math + eglish? 这三个字段数据的平均值(针对表达式计算)
select avg(chinese + math + english) from exam_result;执行结果:
group by 子句
- 使用 group by 子句可以对指定列进行分组查询
- 不使用 group by 分组的时候,就相当于只要一组,把所有的行进行聚合
- 引入 group by 就可以针对不同的组,来分别进行聚合
实例理解
- 此处我们创建一个 emp 表,并插入几条数据
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
- 此处我们想根据?role 字段分别查询各个职位的平均薪水
select role,avg(salary) from emp group by role;执行结果:
分组查询 也是可以指定条件的三种情况
- 分组之前 指定条件,即先筛选再分组(where)
- 分组之后 指定条件,即先分组再筛选(having)
- 分组之前和之后,都指定条件
实例理解
- 查询每个岗位的平均薪资,但是需筛选掉?employ 岗位中 name = haoran 的薪水
- 使用 where
select role,avg(salary) from emp where name != 'haoran' group by role;执行结果:
- 查询每个岗位的平均薪水,但是最后筛选掉平均薪水大于 10000 的岗位
- 使用 having
执行结果:
- 查询每个岗位的平均薪资,但是在计算平均薪水之前 需筛选掉?employ 岗位中 name = haoran 的薪水,在计算平均薪水后 需筛选掉平均薪水大于 10000 的岗位
- where 和 having 结合使用
select role,avg(salary) from emp where name != 'haoran' group by role having avg(salary) < 10000;执行结果:
执行流程图








联合查询?
笛卡尔积
- 多表查询的基本执行过程:笛卡尔积
实例理解一
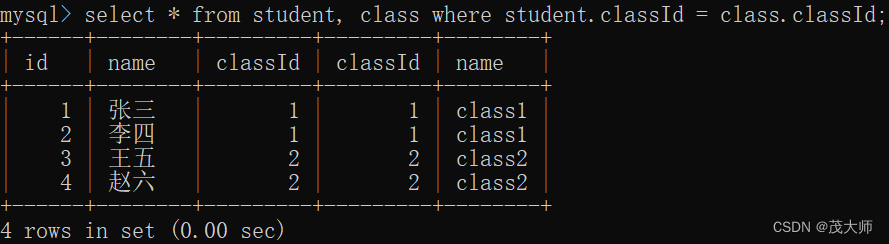
- 此处我们创建两个表,分别为 student 表 和 class 表,并插入几条数据
- 此时我们想得到 student 表 和 class 表的笛卡尔积
select * from student, class;执行结果:
- 笛卡尔积得到一个更大的表,列数为两个表列数之和,行数为两个表行数之积
- 但是仔细观察,笛卡尔积里的结果,很多都是无效数据,只有一部分是有意义的
- 因此我们需要把 无意义的数据给筛选掉
- 此处无意义的数据行为 classId 既为?1 又为 2 的
select * from student, class where student.classId = class.classId;执行结果:
- 加上条件后,我们所查询到的数据便都是合法的了
- 此处我们将用来筛选有效数据的条件 称为连接条件
实例理解二
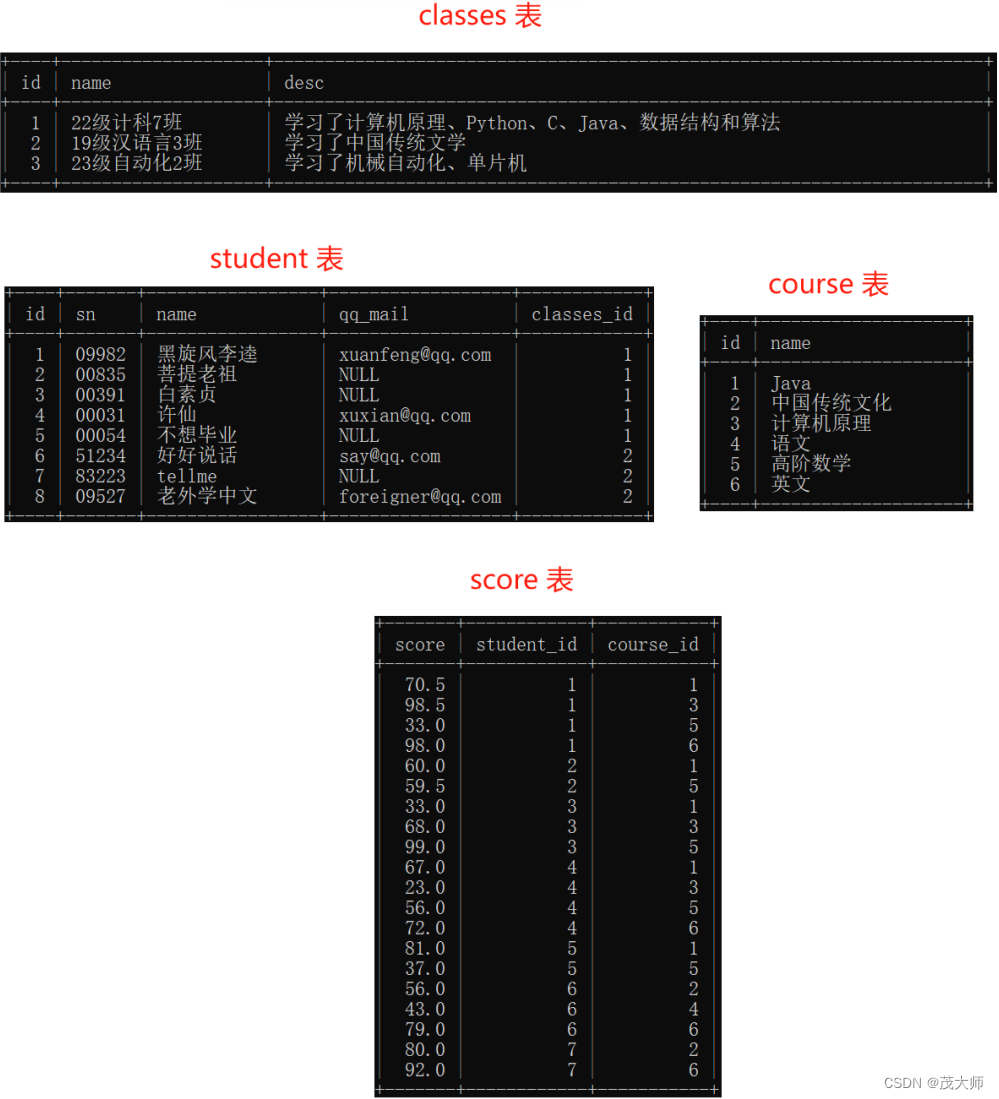
- 此处我们创建四个表,分别为 classes 表、student 表、course 表、score 表,并插入多条数据
分析:
- 学生 和 班级,一对多关系
- 学生 和 课程,多对多关系,要想表示这个多对多关系,就需要引入个关联表
- score 表正好描述了 学生 和 课程 之间的关联关系,顺便也把分数也给列出来了
1)查询 许仙 同学的成绩
- 先计算笛卡尔积,加上连接条件
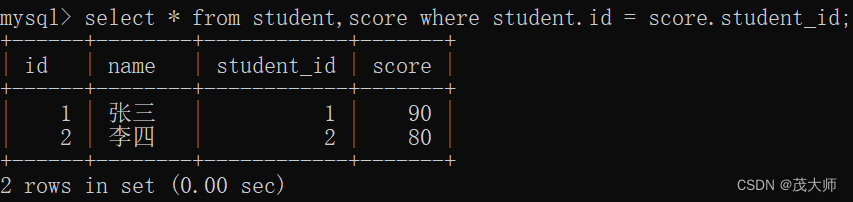
select * from student,score where student.id = score.student_id;执行结果:
- 根据需求,我们仅需得到 name = '许仙' 的数据行
select * from student,score where student.id = score.student_id and name = '许仙';执行结果:
- 再针对查询的列进行精简,此处只保留 name 字段 和 score 字段
select student.name,score.score from student,score where student.id = score.student_id and name = '许仙';
2)使用 join 关键字查询 许仙 同学的成绩
- 写法一
select student.name,score.score from student join score on student.id = score.student_id and student.name = '许仙';
- 写法二
select student.name,score.score from student inner join score on student.id = score.student_id and student.name = '许仙';执行结果:
- 这两种写法的执行结果相同
注意:
- 上述 直接?from 多个表和使用?join on 关键字,虽然均能实现查询许仙同学成绩
- 但是 直接 from 多个表,只能实现 内连接
- 而 join on 既可以实现 内连接 也能实现 外连接
3)查询所有同学的总成绩,及同学的个人信息
select student.name,sum(score.score) as '总分' from student,score where student.id = score.student_id group by student.name;执行结果:
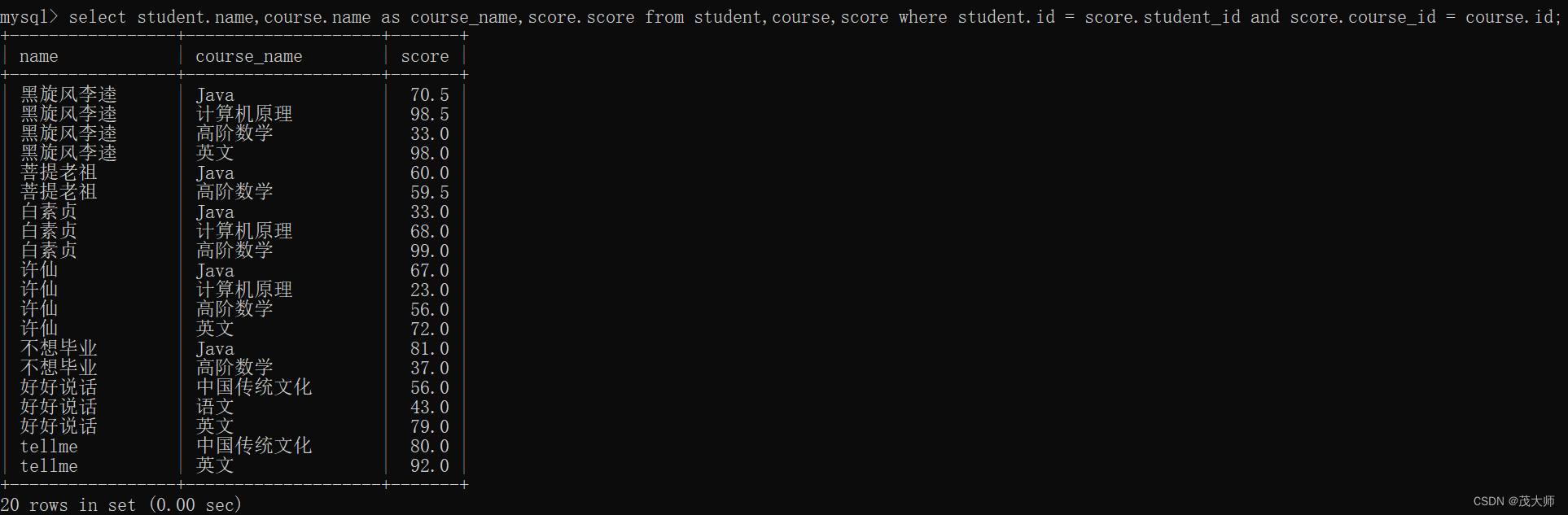
4)查询所有学生的成绩信息,及同学的个人信息
- 期望查询结果中包含个人信息、课程名字、分数
写法一:
- 直接 from 多个表
select student.name,course.name as course_name,score.score from student,course,score where student.id = score.student_id and score.course_id = course.id;写法二:
- 使用 join 关键字
select student.name,course.name as course_name,score.score from student join score on student.id = score.student_id join course on score.course_id = course.id;执行结果:
内连接 外连接
- 内连接 和 外连接在大多数情况下,是没区别的
- 比如 要连接的两个表,其里面的数据都是相互对应的,这时候二者没区别
- 如果不是 相互对应的,那么此时 内连接 和 外连接 就有区别了
实例理解一
- 此处我们创建两个表,分别为 student 表 和 score 表,并插入多条数据
- 此时我们两个表中的数据为 相互对应的
- 使用 直接 from 多个表的方式 查询学生成绩
select * from student,score where student.id = score.student_id;执行结果:
- 使用 join 关键字的方式 查询学生成绩
select * from student join score on student.id = score.student_id;执行结果:
- 我们可以对比观察两种方式的查询结果,发现查询结果相同,且此处的连接为 内连接
实例理解二
- 此处我们将 score 表中的 score = 70 的 student_id 改为 4
- 此时 student 表中的 王五 同学是没有分数的
- ?score 表中?student_id = 4 的分数不知道是哪位同学的
- 使用 直接 from 多个表的方式 查询学生成绩
select * from student,score where student.id = score.student_id;执行结果:
- 此处的查询结果为 两个表中能相互对应上的数据
- 使用 join 关键字的方式 查询学生成绩
select * from student join score on student.id = score.student_id;执行结果:
- 此处的查询结果为 两个表中都有的数据,即能对应上的数据
- 上述的两种写法均为 内连接
- 此时我们通过 join 关键字来实现外连接
- 写法为在 join 前面加个 left? 或 right ,分别对应着 左外连接 和 右外连接
左外连接
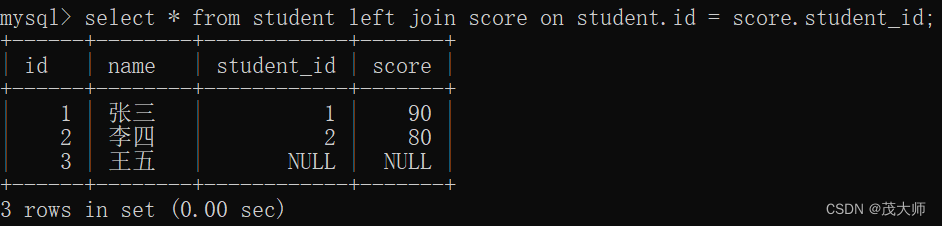
select * from student left join score on student.id = score.student_id;执行结果:
- 左外连接 会把左表的结果尽量列出来,哪怕在右表中没有对应的记录,就使用 NULL 填充
右外连接
select * from student right join score on student.id = score.student_id;执行结果:
- 右外连接 会把右表的结果尽量列出来,哪怕在左表中没有对应的记录,就使用 NULL 填充
自连接
- 自己和自己进行笛卡尔积
- 自连接的效果就是把 行 转成 列
- sql 中无法针对 行和行 之间使用条件比较
- 但是有的需要中,又需要行和行比较,就可以使用 自连接 把行转成列
实例理解
- 此处我们还是使用下图所示的四张表 举例说明
1)查询计算机原理成绩比 Java 高的同学 id
- 首先我们进行笛卡尔积,并简单筛选 无效数据
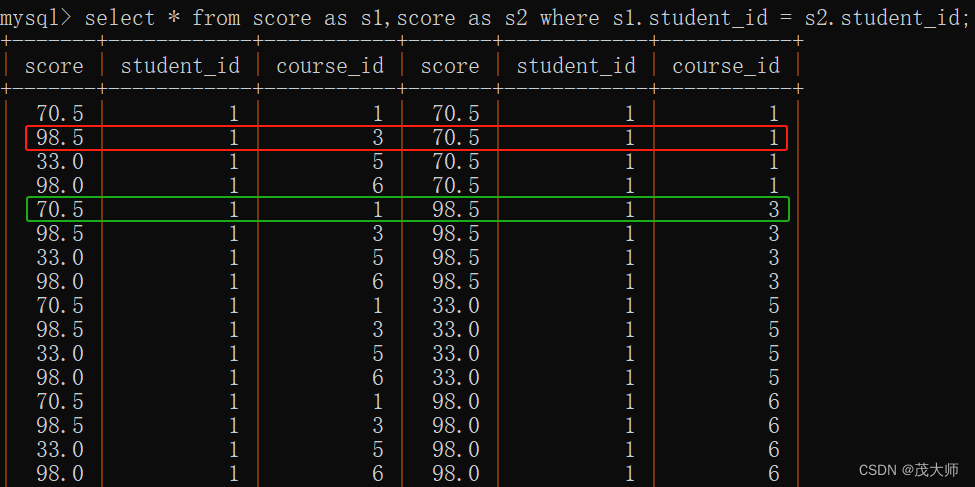
select * from score as s1,score as s2 where s1.student_id = s2.student_id;执行结果:
- 插叙出来的数据行还是比较多的,此处我们仅截取 1号同学
分析:
- 我们可以看到这里的每一行就是在针对同一个同学的各种课程 id 进行了排列组合
- 同时也是针对分数进行 排列组合
- 上图红框部分数据行 其 course_id 分别为 3 和 1,即代表 计算机原理 和 Java
- 上图 红框部分 和 绿框部分 为重复行,所以我们还需进行去重
select * from score as s1,score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1;执行结果:
- 此处我们再进一步指定查询 s1 表 course_id = 3 且 s2 表 course_id = 1 的数据行
- 即 s1 表仅保留?计算机原理的成绩,s2 表仅保留 Java 的成绩
- 既满足了 仅需比较 计算机原理 和 Java 这两门课的成绩的要求,也达到了去重的目的
- 最后我们再进行最后的筛选,只留下计算机原理成绩 比?Java 高 的数据行
select * from score as s1,score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;执行结果:
子查询
- 子查询本质上就是套娃,即把多个 sql?组合成了一个
- 在实际开发中,子查询要慎用
- 因为子查询可能会构造出非常复杂、不好理解的 sql,对于 代码的可读性 和 sql的执行效率 很可能是毁灭性的打击
单行子查询
- 返回一行记录的子查询
实例理解
- ?此处我们还是使用下图所示的四张表 举例说明
1)查询 name = '不想毕业' 的同班同学的姓名
- 步骤一:先查询到 name = '不想毕业' 同学的班级 id
select classes_id from student where name = '不想毕业';执行结果:
- 步骤二:根据查询到的班级 id 来查询该班级的所有学生姓名,排除掉 name =?'不想毕业' 同学
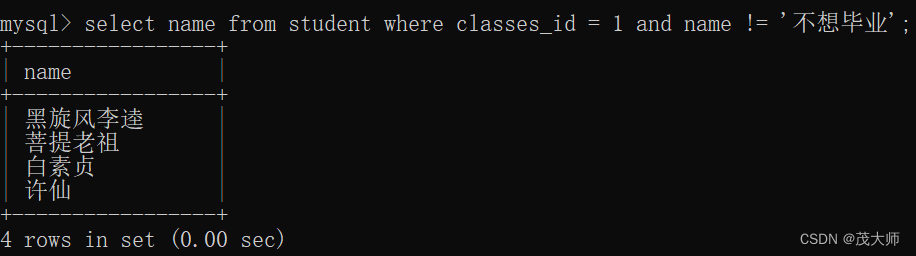
select name from student where classes_id = 1 and name != '不想毕业';执行结果:
- 我们子查询就是将上述的两个步骤合二为一
select name from student where classes_id = (select classes_id from student where name = '不想毕业') and name != '不想毕业';执行结果:
多行子查询
- 返回多行记录的子查询
实例理解
- 还是使用上文 的四张表来举例
1)查询 语文 或 英语 课程的成绩信息
- 步骤一:先根据名字 查询出课程 id
select id from course where name = '语文' or name = '英文';执行结果:
- 步骤二: 根据课程 id 查询出课程分数
select * from score where course_id in(4,6);执行结果:
- 使用子查询将上述两个步骤合并为一
select * from score where course_id in(select id from course where name = '语文' or name = '英文');执行结果:
EXISTS 关键字
- 该关键字的可读性比较差 且 执行效率也大大低于 in 关键字写法,但使用 exists 关键字可以解决一些特殊场景
- 如 当我们使用 in 关键字进行查询时,其查询结果在内存中,如果查询结果太大,以至于内存都放不下了
- 此时就不能使用 in 关键字,需转而使用 exists 关键字代替
- 实际上处理上述场景 更推荐的是多步完成查询,没必要强行合成一个
- exists 关键字的本质也就是让数据库执行多个 查询操作
合并查询
- 本质上就是把两个查询的结果集 合并成一个
- 要求这两个结果集的列相同才能合并,即 列的类型 + 列的个数 + 列的名字 相同
实例理解:
- ?此处我们还是使用下图所示的四张表 举例说明
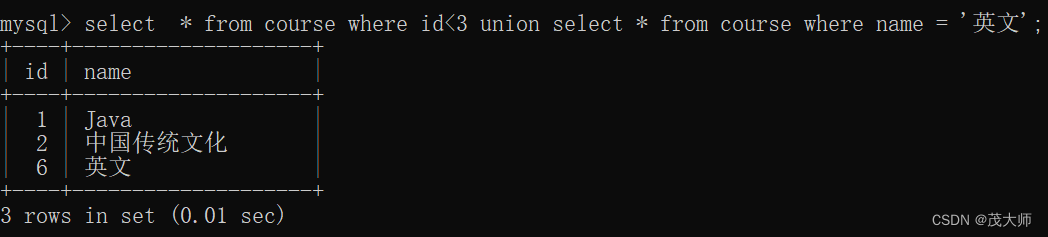
1)查询 id < 3 或者名字为 英文 的课程
- 此处使用 union 关键字进行 合并查询
select * from course where id<3 union select * from course where name = '英文';执行结果:
注意:
- 虽然在该场景下使用 or 关键字也能完成查询
- 但是用 or 关键字 时,你的查询只能来自于同一张表
- 如果使用 union 关键字查询结果,你的查询可以来自于不同的表,只要保证查询结果的列相同即可
union on 和 union 的区别
- union on 和 union 这两个关键字,在大多数场景下都是差不多的
- 但 union 会进行去重操作,即重复的行只会保留一份
- 而 union on 可以保留多份重复的数据行,不会去重






















文章来源:https://blog.csdn.net/weixin_63888301/article/details/134995850
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 智能语音机器人NXCallbot
- android 新版studio gradle 里面没有offline 勾选项
- Python中常用模块解锁你的编程魔法:探索神奇的标准库!
- 【MySQL】数据库并发控制:悲观锁与乐观锁的深入解析
- 【Linux】修复 Linux 错误 - 功能未实现
- 20240105-要具有成果化思维
- iview表格固定列横向滚动条无法拖动问题
- SpringBoot入门到精通-Spring Boot Jasypt Encrypt 演示
- Java 线程池四种拒绝策略
- 基于SSM的搬家预约系统(有报告)。Javaee项目。ssm项目。