计算机组成原理期末复习
第一章:计算机系统漫游
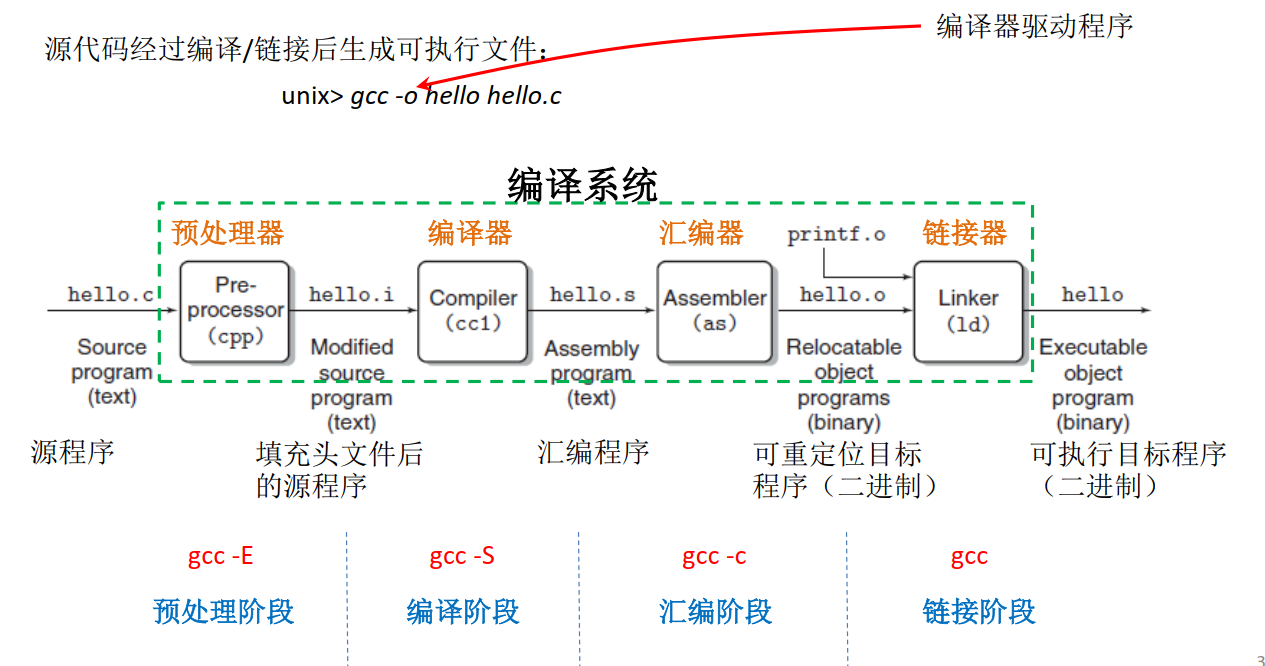
编译系统
进程线程之间的关系
1)从定义上说,进程是操作系统进行资源分配和调度的基本单位,而线程是进程的执行单元,共享进程的资源
2)具体来说,进程就是运行起来的可执行程序,当我们运行一个可执行程序的时候,就会创建一个或多个进程,创建进程的时候需要分配空间,比如:栈区、文件映射区、堆区、静态区、常量区、代码段,这就是为什么进程也被称为是资源分配的基本单位;每个进程中都有唯一的主线程,有且只有一个,主线程和进程是相互依存的关系,主线程结束进程也会结束
3)每个进程有自己的独立地址空间,不与其他进程分享;一个进程里可以有多个线程,彼此共享同一个地址空间。堆内存、文件、套接字等资源都归进程管理,同一个进程里的多个线程可以共享使用。每个进程占用的内存和其他资源,会在进程退出或被杀死时返回给操作系统
4)并发应用开发可以用多进程或多线程的方式,多线程由于可以共享资源,效率较高;反之,多进程默认是不共享地址空间与资源,开发较为麻烦,共享数据时效率较低。但多进程安全性较好,在某一个进程出问题时,其他进程一般不受影响,而在多线程的情况下,一个线程执行了非法操作会可能导致整个进程退出
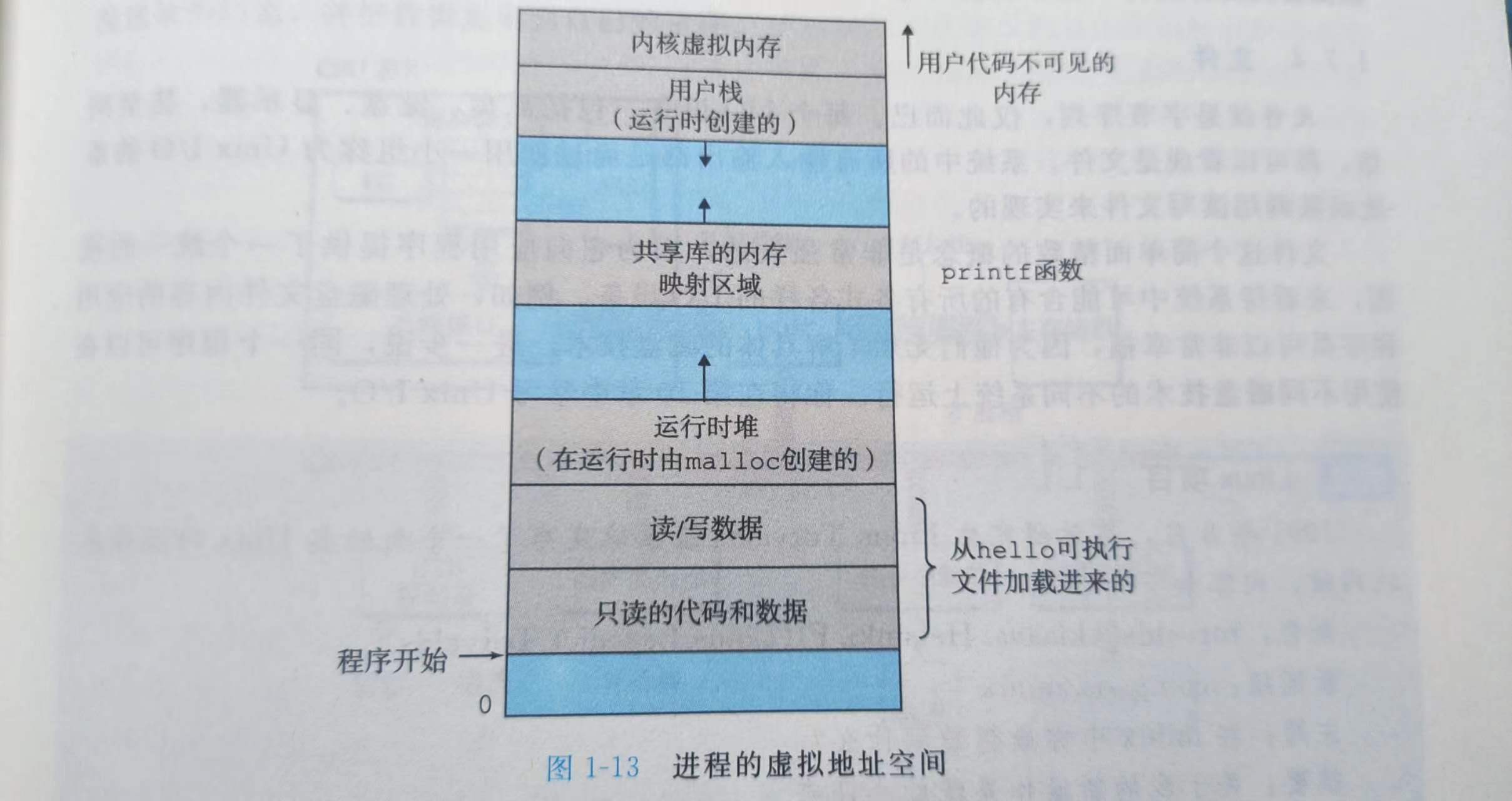
存储器层次结构

虚拟地址
第二章:信息的表示和处理
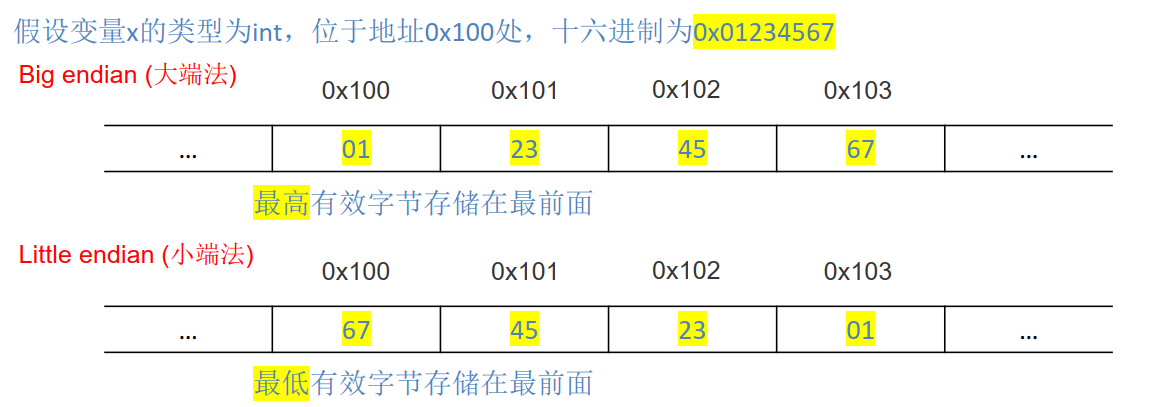
大端与小端
整数运算
移位运算
逻辑右移和算数右移的区别:算术右移填符号位,逻辑右移填 0
整数运算的要点
无论是有符号无符号什么类型,不用管这些方面
整数运算的要点就是:先转换成补码进行运算,运算完转换为原码,最后根据输出的进制和类型输出即可
(需要注意的是,根据不同的类型:1)整形提升,高位补符号位;2)截断,保留的是低位)
之前写过整形计算的文章:C语言-整形的存储,2.3 的部分有例题。
浮点数运算
(-1)^S * M * 2^E
(-1)^S 表示符号位;M 表示有效数字;2^E 表示指数位
举个例子:
十进制的 5.0
先转换成二进制:101.0
写成浮点数的形式:(-1)^0 * 1.01 * 2^2
相当于:S=0 , M=1.01 , E=2
需要注意的地方:
对于 32 位的浮点数,最高的 1 位是符号位 S
接着的 8 位是指数 E,剩下的 23 位为有效数字 M

对于64 位的浮点数,最高的 1 位是符号位 S
接着的 11 位是指数E,剩下的 52 位为有效数字 M

三种情况:规格化,非规格化,特殊情况
规格化:E 不等于 0,E 不等于 255 的时候就是规格化的情况(正常情况)(Normalized)
非规格化:E 存放的全为零(也就是 E = 0)的时候就是非规格化(Denormalized)
特殊情况:E 存放的全为 1(也就是 E = 255)的时候就是特殊情况,特殊情况分为两类:
- 表示这个数无穷大(Infinity)
- 表示这个数不存在(NaN)
页转换
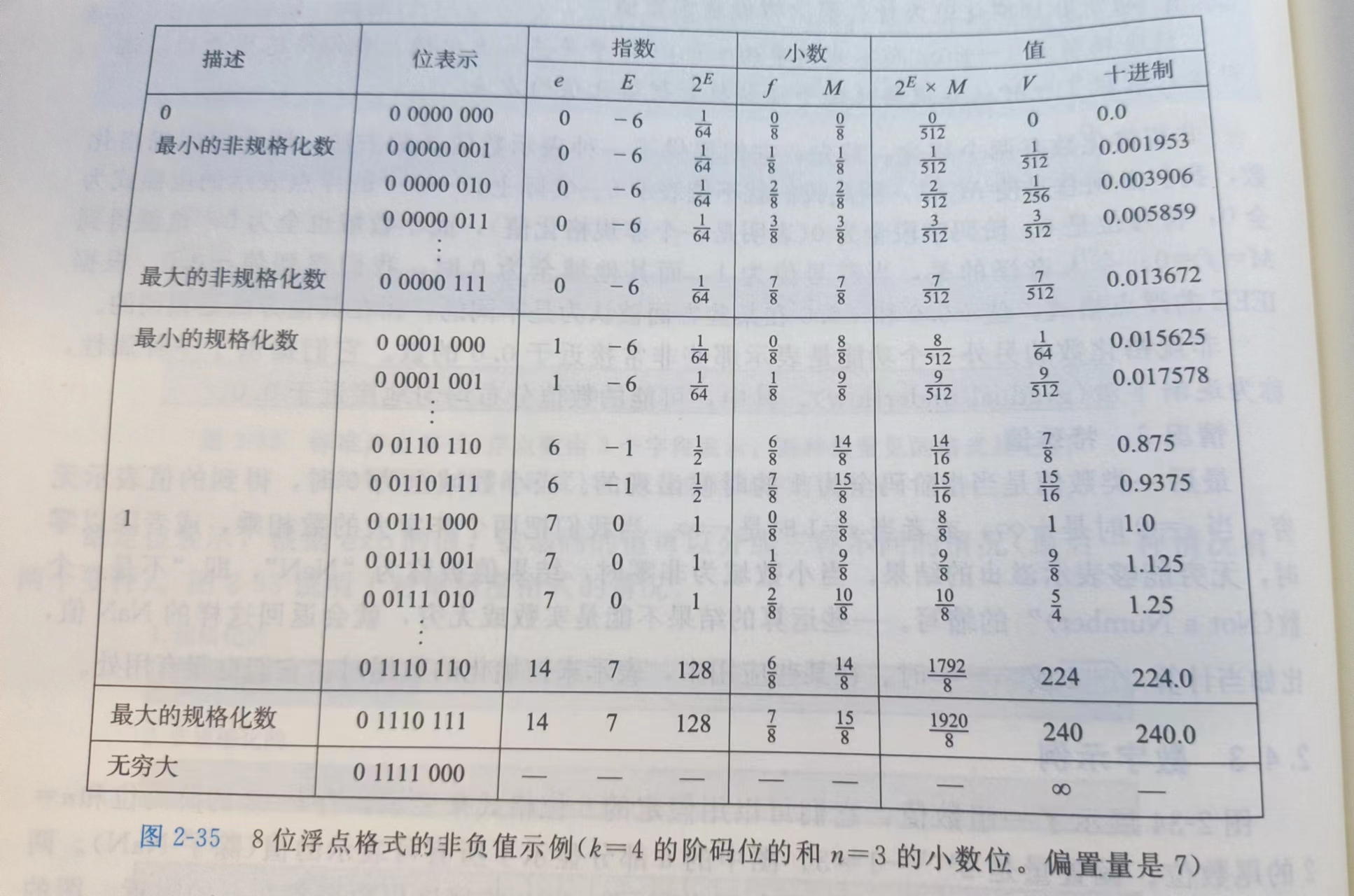
如图分析:k = 4 的阶码位和 n = 3 的小数位(位表示:中间的四位和最后的三位)
非规格化的数:
E = 1 - 偏置量,M 的值从 0 开始,分子与位表示最后三位的值保持一致
规格化的数:
E = e - 偏置量,e 代表的是中间四位的值(当中间全为 1 时,最终值为无穷大)
M = 1 + 最后三位的值,浮点数值的计算是: 2^E * M,最终求的取值
第三章:程序的机器级表示
栈的压入和弹出
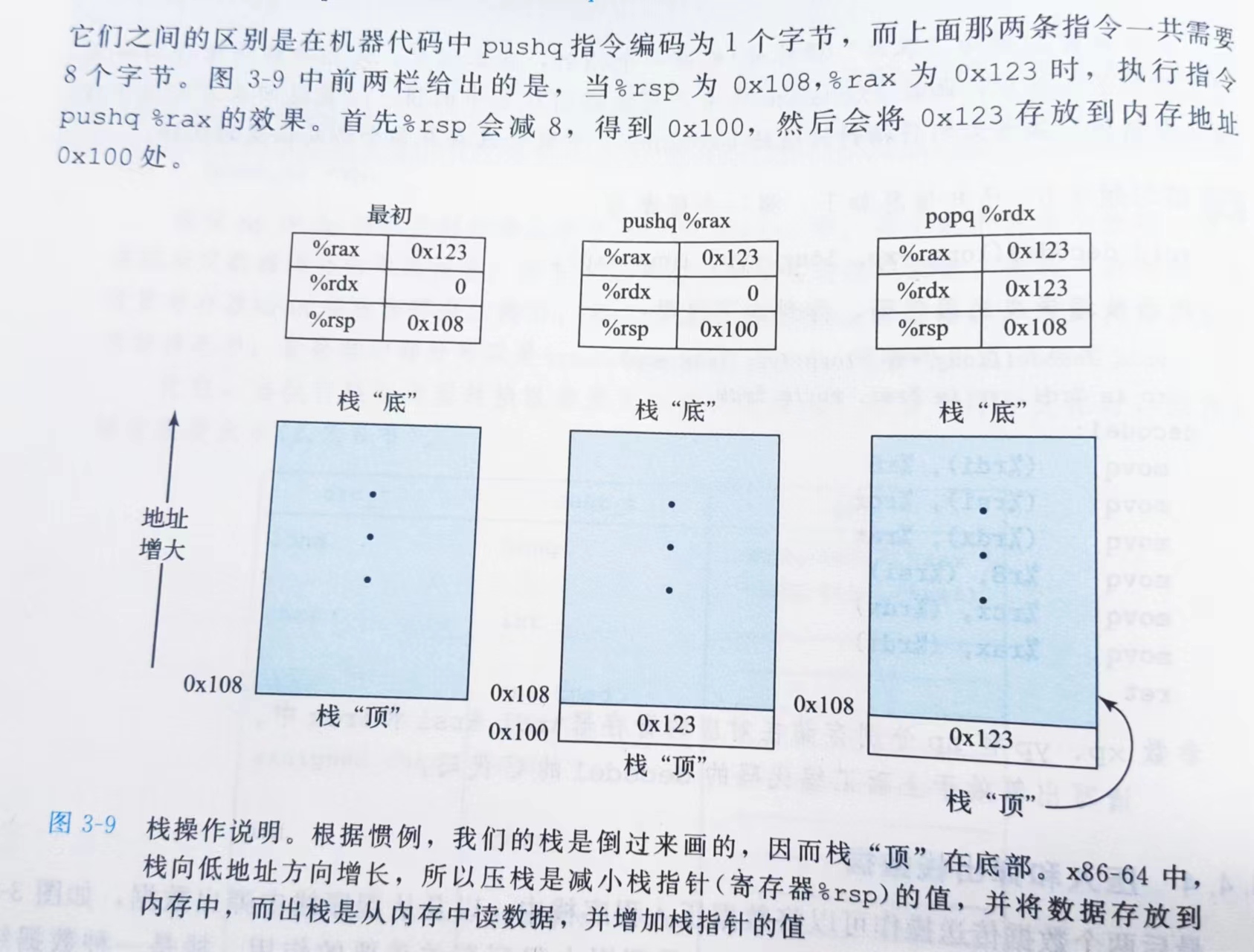
push 与 pop 指令:
入栈操作:1)栈顶指针(rsp) - 偏移量;2)将保存在寄存器(rax) 的数据保存进栈中
出栈操作:1)将栈顶的数据读出,复制到寄存器(rdx) 中;2)栈顶指针(rsp) + 偏移量
算数与逻辑运算操作指令
学会使用 leaq:
leaq 6(%rax), %rdx -> rdx = rax + 6
leaq (%rax, %rcx), %rdx -> rdx = rax + rcx
leaq (%rax, %rcx, 4), %rdx -> rdx = rax + rcx*4
leaq 7(%rax, %rax, 8), %rdx -> rdx = rax + rax*8 + 7
leaq 0xA(, %rcx, 4), %rdx -> rdx = rcx*4 + 0xA
练习使用其他操作数:
假设:%rax = 0x100 %rcx = 0x1 %rdx = 0x3
0x100 = 0xFF 0x108 = 0xAB 0x110 = 0x13 0x118 = 0x11
计算操作:
addq %rcx, (%rax) -> 0x100(地址) = 0x100 + %rcx 所以 0x100 = 0xFF(值) + 0x1 = 0x100(值)
subq %rdx, 8(%rax) -> (0x100+8)(地址) = 0x108 - %rdx 所以 0x108 = 0xAB - 0x3 = 0xA8
incq 16(%rax), -> 0x100+16 = 0x110 + 1 所以 0x110 = 0x13 + 1 = 0x14 (incq 类似 ++ 操作)
subq %rdx, %rax -> rax = rax - rdx 所以 0x100 = 0x100 - 0x3 = 0xFD (没有括号,直接减的 rax)
移位操作:
sal 和 shl 都是左移操作
sar 是算数右移,shr 是逻辑右移
条件判断与循环
练习:
(备注:%rdi 是 x,jge 表示 >=)
cmpq $-3, %rdi
jge .L2
这两句合在一起就是:如果 x >= -3 就 jump 到 L2 所在的位置
翻译成C语言代码就是:
if ( x < -3 ) {
}
因为 x < -3 程序就会正常往下走,不需要跳转到其他的位置
switch 语句:
跳转表从上到下从 0 开始依次排列
如果遇到重复的 L,就证明对应的数字不存在,不影响数数,继续往下数,不存在的数字全部归到 default
如果遇到两个 case 叠在一起(也就是 case 后面没有内容,而是直接跟着下一个 case)
那这两个 case 在跳转表中存在两个相同的 L,case 的数字就是 L 对应的数字(数字顺序不限(也就是答案不唯一))
第六章:存储器层次结构
存储器
易失性存储器
RAM(RandomAccessMemory)的全名为随机存取记忆体,它相当于PC 机上的移动存储,用来存储和保存数据的。
最常见的易失性存储器类型是随机存取存储器或 RAM。计算机和其他电子设备使用 RAM 进行高速数据访问。RAM 的读/写速度通常比大容量存储设备(例如硬盘或 SSD)快几倍。
非易失性存储器
非易失性存储器(NVMe)是一种半导体技术,不需要持续供电来保留存储在计算设备中的数据或程序代码。
非易失性存储器的例子包括:只读存储器(ROM是非易失性存储器,这意味着信息永久存储在芯片上)、闪存、大多数类型的磁性计算机存储设备(例如硬盘、软盘和磁带)、光盘和早期的计算机存储方法,如纸带和打孔卡。
磁盘的构造:
推荐看这篇文章:[5 分钟图解磁盘的结构(盘片、磁道、扇区、柱面)- CSDN 博客](https://blog.csdn.net/weixin_37641832/article/details/103217311#:~:text=一个 磁盘 (如一个 1T 的机械硬盘)由多个 盘片 (如下图中的,0 号盘片)叠加而成。 盘片的表面涂有 磁性物质 ,这些磁性物质用来记录 二进制 数据。)
程序的局部性
时间局部性
如果被引用过的内存位置很可能在不远的将来还会被多次引用,此时,我们可以说程序具有良好的时间局部性
空间局部性
如果内存一个位置被引用了一次,那么程序很可能在不远的将来引用附近的一个内存位置,此时,我们可以说程序具有良好的空间局限性
Cache
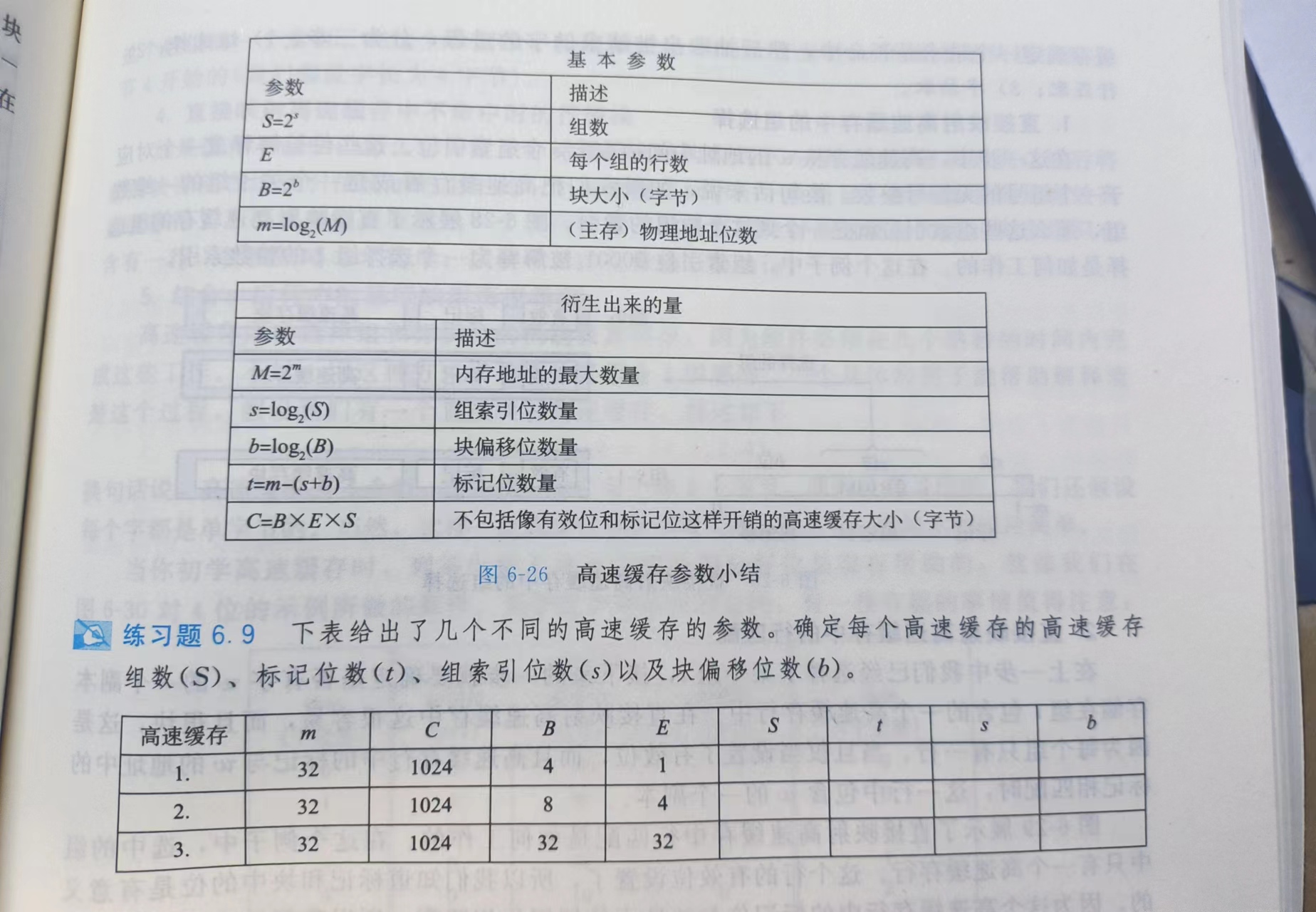
练习题 6.9:
C = B * E * S -> 1024 = 4 * 1 * S -> S = 256
S = 2^s -> 256 = 2^s -> s = 8
B = 2^b -> 4 = 2^b -> b = 2
t = m - (s + b) -> t = 32 - (8 + 2) -> t = 22
解得:S = 256;t = 32;s = 8;b = 2
主要得把公式记住:
C = B * E * S
t = m-(s+b)
S = 2^s
B = 2^b
M = 2^m
直接映射高速缓存的流程:

缓冲区溢出:
缓冲区溢出指当一段程序尝试把更多的数据放入一个缓冲区,数据超出了缓冲区本身的容量,导致数据溢出到被分配空间之外的内存空间,使得溢出的数据覆盖了其他内存空间的数据。攻击者可以利用缓冲区溢出修改计算机的内存,破坏或控制程序的执行,导致数据损坏、程序崩溃,甚至是恶意代码的执行。
防止缓冲区溢出攻击:
- 完整性检查:在程序指针失效前进行完整性检查。
- 随机化地址空间: 关键数据区的地址空间位置随机排列。通常,缓冲区溢出攻击需要知道可执行代码的位置,而随机化地址空间使这几乎不可能。
- 防止数据执行:标记内存的某些区域为可执行或不可执行,从而阻止在不可执行区域运行代码的攻击。
- 编写安全的代码:使用能够帮助识别不安全函数或错误的编译器,利用编译器的边界检查来实现缓冲区的保护。避免使用不进行缓冲区检查的函数(例如,在 C语言中,用 fgets() 代替 gets())。使用内置保护的语言编写或在其代码中使用特殊的安全性程序,来预防缓冲区溢出漏洞。
第七章:链接
目标文件的三种形式
可重定位目标文件
- 其代码和数据可和其他可重定位文件合并为可执行文件
- 每个 .o 文件由对应的 .c 文件生成
- 每个 .o 文件代码和数据地址都从 0 开始
可执行目标文件
- 包含的代码和数据可以被直接复制到内存中并执行
- 代码和数据地址为虚拟地址空间中的地址
共享的目标文件
- 特殊的可重定位目标文件,能在装入或运行时被装入到内存并自动被链接,称为共享库文件
可重定位目标文件
相关节的表示:
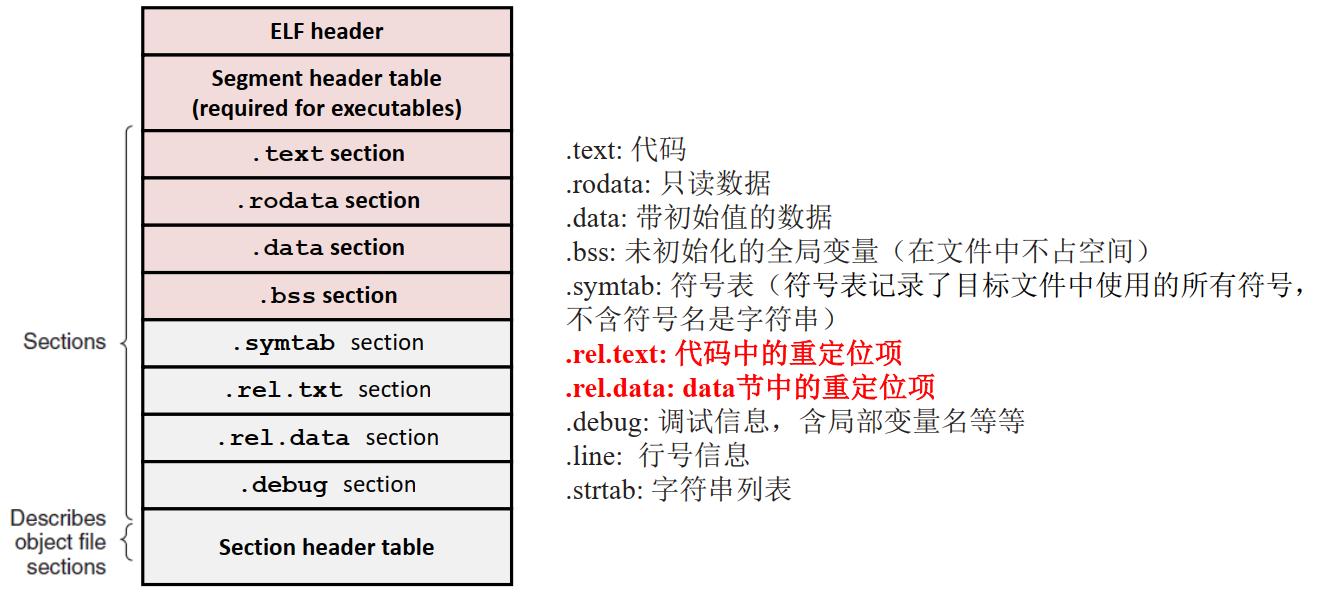
链接时符号相关
什么是强弱符号?
函数和带初始化的全局变量是强;
未初始化的全局变量是弱符号。
符号多重定义的规则:
– 规则1:不允许有多个强符号;
– 规则2:如果有一个强符号 + 一个或多个弱符号,选择强符号;
– 规则3:如果有多个弱符号,任意选一个。
链接报错是什么情况?
连接过程中常见的错误是 符号未找到(undefined reference)和符号重定义(redefinition)
由于在编译器在处理各个符号的时候,已经没有了各个 C语言源文件的概念,只有目标文件。 因此对于这种错误,连接器在报错的时候,只会给出错误的符号的名称,而不会像编译器报错一样给出错误程序的行号。
静态库静态链接逻辑

库在命令行中出现的位置和顺序问题:

练习:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 知识竞赛的组织程序
- Unity 面试篇|(三)设计模式篇 【全面总结 | 持续更新 | 建议收藏】
- parseInt(0.0000005)大于等于5
- 【python爬虫开发实战 & 情感分析】利用爬虫爬取城市评论并对其进行情感分析
- 桌面型物联网智能机器人设计(预告)
- 基于mpvue一款播课类小程序(附源码)
- 词嵌入位置编码的实现(基于pytorch)
- Docker服务启动失败,重启请求频繁被拒绝
- 强化学习应用(一):基于Q-learning的物流配送路径规划研究(提供Python代码)
- 智慧医院预约及支付平台—总体方案