基于JavaWeb+BS架构+SpringBoot+Vue+Spark的共享单车数据存储系统的设计和实现
基于JavaWeb+BS架构+SpringBoot+Vue+Spark的共享单车数据存储系统的设计和实现
文末获取源码
Lun文目录
第一章 概述 2
1.1课题研究背景 2
1.2 课题研究意义 2
1.3国内外发展现状 3
1.4研究内容 3
1.5本文的结构 3
第二章 开发工具及技术介绍 4
2.1 Java编程语言 4
2.2 Spark简介 4
2.3 SPRINGBOOT 框架 5
2.4 MySQL数据库 5
2.5 B/S架构 5
第三章 系统分析 1
3.1功能需求分析 1
3.2系统可行性分析 1
3.2.1技术可行性 1
3.2.2经济可行性 1
3.2.3社会可行性 2
3.3系统用例分析 2
3.4流程图设计 3
3.4.1登录流程图 3
3.4.2添加新用户流程图 4
第四章 系统概要设计 5
4.1系统设计原理 5
4.2功能模块设计 5
4.3数据库设计 5
4.3.1数据库设计原则 5
4.3.2数据库E-R图设计 5
4.3.3数据库表结构设计 7
第五章 系统功能实现 10
5.1系统登录注册实现 10
5.2管理员模块实现 10
5.3用户模块实现 13
第六章 系统测试 14
6.1软件测试原则 14
6.2软件测试过程 15
6.3测试用例 16
6.4本章小结 16
结 论 17
致 谢 18
参考文献 19
前言
.4研究内容
(1)调研:通过网络、图书馆等渠道调查该课题的参考资料。
(2)系统需求分析:对参考资料分类整理,设想需求与功能,再研究实现功能所需的开发工具、技术、数据库等。
(3)系统概要设计:设计功能模块、流程、数据库模型、表与字段间的关系等。
(4)系统实现:对系统用户以文字加截图的形式进行精细化分解。
(5)系统测试:测试的作用和好处,测试的具体操作步骤,分析需求与测试结果是否一致。
1.5本文的结构
本论文分为六个章节。
第一章,绪论,其包含课题背景及意义,现国内外的发展现状,本课题要研究的内容,所使用开发工具的描述等信息。
第二章,主要介绍了系统的开发技术。
第三章,先讲述功能需求分析,再讲述系统可行性分析和流程图的设计。
第四章,是系统设计原理,功能模块设计和数据库设计。
第五章,详细讲述每个界面的正确操作步骤。
第六章,该章讲述了测试的目的以及测试过程及用例。
最后对论文进行总结,包括致谢和参考文献等内容。
主要技术
.2 Spark简介
Spark最初由加州大学伯克利分校的AMP(算法、机器和人)实验室于2009年开发,是一个基于内存计算的大数据并行计算框架,可用于构建大型、低延迟的数据分析应用程序。Spark最初是一个研究项目,它的许多核心思想来自学术研究论文。2013年,Spark加入Apache孵化器项目,开始快速发展。目前已成为Apache软件基金会分布式计算系统(Hadoop、Spark和Storm)三大最重要的开源项目之一。
Spark是大数据计算领域的后起之秀,在2014年打破了Hadoop的排序基准(Sort Benchmark)记录,使用206个节点在23分钟内对100tb的数据进行排序。Hadoop使用2000个节点在72分钟内对相同的数据进行排序。换句话说,Spark只使用十分之一的计算资源,速度是Hadoop的三倍。这一新的记录使Spark成为一个受欢迎的平台,并表明Spark可以作为一个更快、更高效的大数据计算平台。
2.3 SPRINGBOOT 框架
Spring Boot是由Pivotal的开发团队在2013年开发的一个免费、轻量级、开源的系统框架。SpringBoot的主要设计思想是约定大于配置,因此SpringBoot在设计时几乎达到零配置。SpringBoot集成了业界的开源框架。
SpringBoot是一个非常强大的后台框架,因为SpringBoot的开发基本上不需要写配置文件,所以利用SpringBoot来构建网站的后台环境,在SpringBoot的YML配置文件中写项目启动端口,项目就可以启动了。项目的Java和静态文件由SpringBoot管理。
系统设计
4.1系统设计原理
设计原理,是指一个系统的设计由来,其将需求合理拆解成功能,抽象的描述系统的模块,以模块下的功能。功能模块化后,变成可组合、可拆解的单元,在设计时,会将所有信息分解存储在各个表中,界面不会显示所有定义的字段。在设计时,会有几大要求,抽象、模块化、信息隐藏、耦合低、内聚等特性,本系统的设计也符合以上几大特性。制作和显示流程都属于程序员需要分析研究的一部分。每个模块都是相对独立的。

功能截图


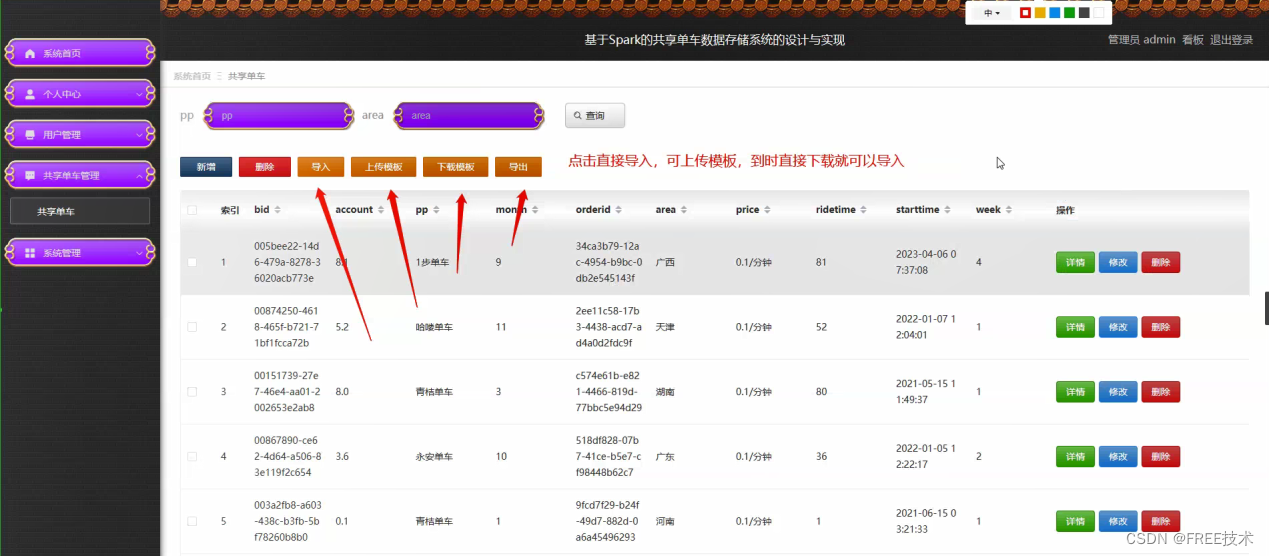
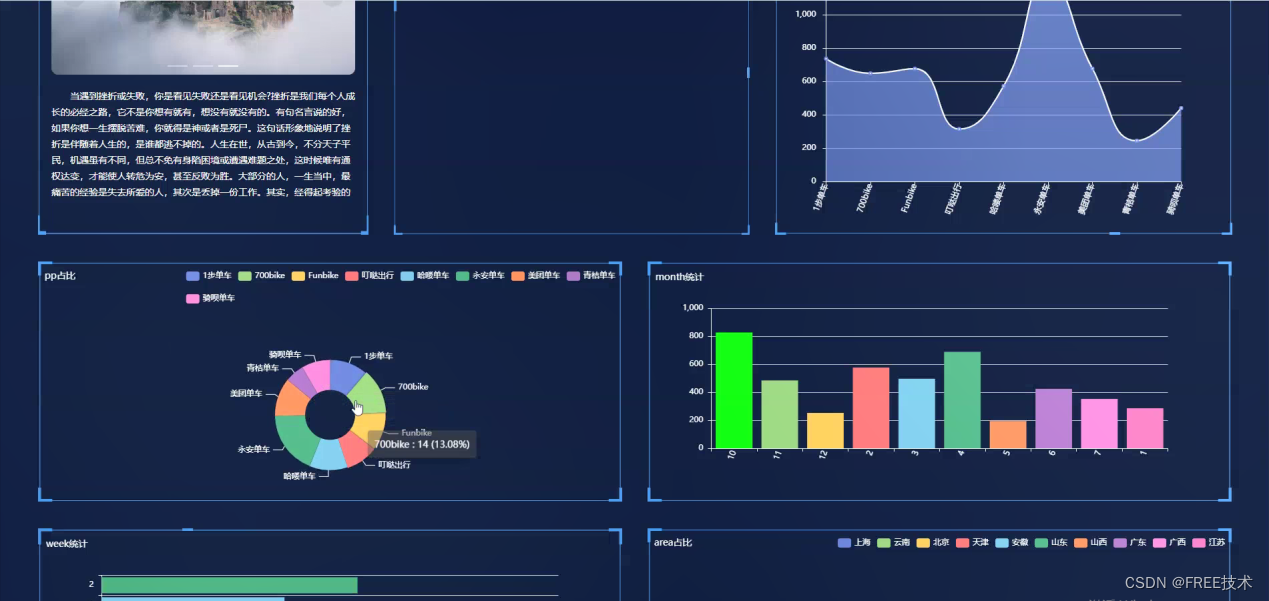

订阅经典源码专栏
Java项目精品实战案例《500套》
源码获取
欢迎大家点赞、收藏、关注、评论啦 。
点击下方卡片获取源码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 架构模式:分片
- 10个国内外素材网站,提供免费 Photoshop 素材下载资源
- 简单高效LaTeX 第005集 导言区和文档输出
- 四色问题(图论)python
- CSS浮动
- 【MATLAB源码-第106期】基于matlab的SAR雷达系统仿真,实现雷达目标跟踪功能,使用卡尔曼滤波算法。
- 【Hadoop_03】HDFS概述与Shell操作
- 【面试】Java最新面试题资深开发-Spring篇(1)
- 如何搭建 Jenkins 自动化测试平台?
- host没有管理员权限