Transformer模型
前置知识:Attention机制
结构
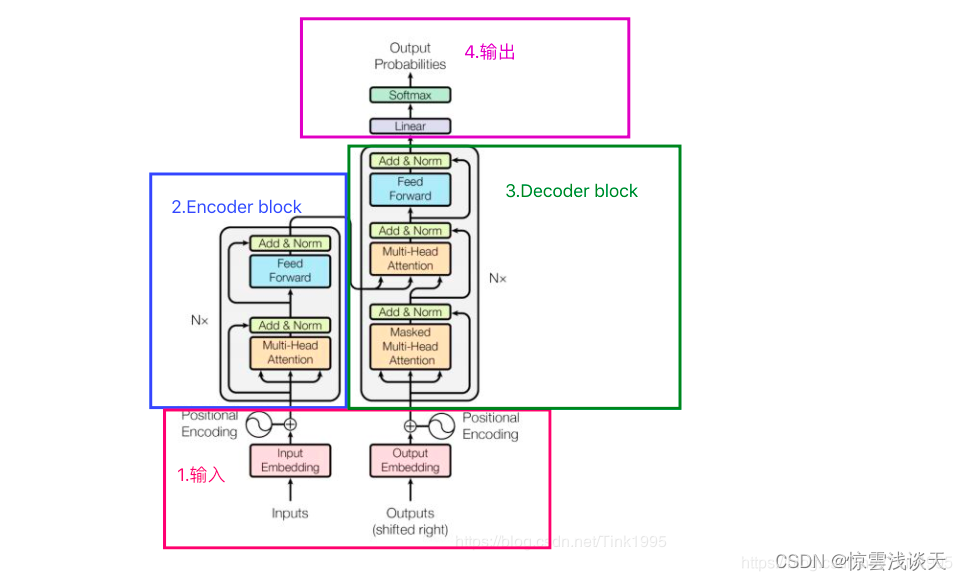
Transformer主要包括四部分,其中2, 3两部分是Transformer的重点,Transformer是一个基于Encoder-Decoder框架的模型
原理
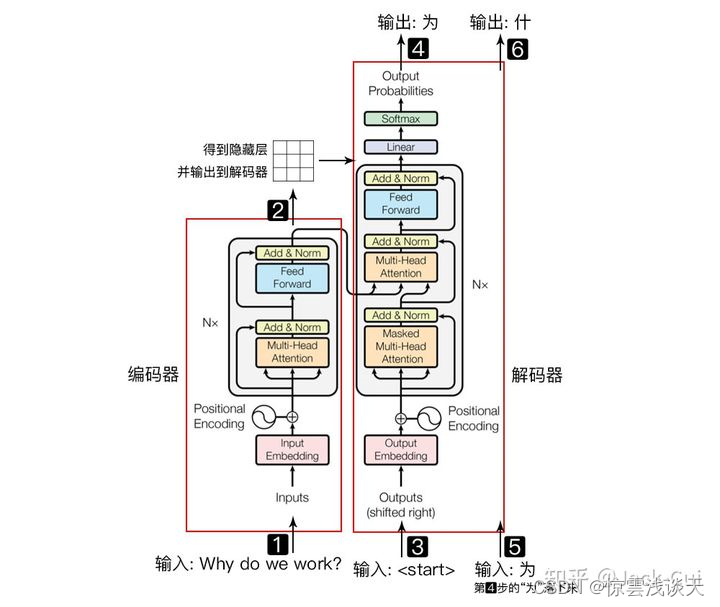
-
输入自然语言序列到编码器: Why do we work?(为什么要工作);
-
编码器输出的隐藏层,再输入到解码器;
-
输入 < > (起始)符号到解码器;
-
解码器得到第一个字"为";
-
将得到的第一个字"为"落下来再输入到解码器;
-
解码器得到第二个字"什";
-
将得到的第二字再落下来,直到解码器输出 < > (终止符),即序列生成完成。
维度
Transformer中的维度是指输入序列、输出序列、词嵌入、位置编码、注意力矩阵等元素的形状或大小。维度是一个重要的参数,它影响了Transformer模型的性能和效率。
一般来说,Transformer中的维度可以分为以下几类:
-
序列长度维度(sequence length dimension):表示输入序列或输出序列的长度,通常用n表示。
-
词向量维度(word vector dimension):表示词嵌入或位置编码的维度,通常用d表示。
-
注意力头数维度(attention head dimension):表示多头注意力中的头数,通常用h表示。
-
注意力维度(attention dimension):表示每个注意力头的维度,通常用dk或dv表示。
-
前馈网络维度(feed-forward network dimension):表示前馈网络中的隐藏层维度,通常用dff表示。
Input 输入
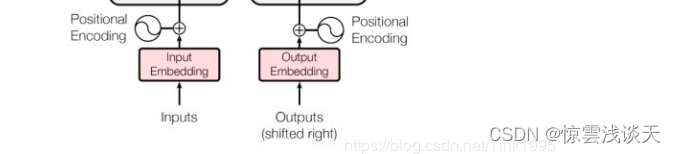
首先,我们需要进行词嵌入,即将文字转换成Xembedding(词向量)。可以是任意形式的词向量,如 Word2Vec、GloVe、one-hot编码等。以Word2Vec为例,词向量的维度为512。
然后向每个word的词向量添加位置编码positional encoding,以保留文字的位置信息。
我们使用位置嵌入的方式获取Positional Encoding。
位置嵌入是一种用于给输入序列添加位置信息的方法,用于解决Transformer模型中没有循环机制导致的位置顺序缺失的问题。
位置嵌入的主要作用是让模型能够感知到输入的顺序,因为Transformer模型是并行地处理句子中的所有词,而不是像RNN一样顺序迭代。
对于每个绝对位置 t,生成一个 d 维的位置向量 pt(PE),其中 d 是嵌入的维度。Transformer 使用 sin-cos 规则,即用 sin 和 cos 的线性变换来给模型提供位置信息:
-
i:词嵌入的维度,∈[0, d-1]
-
t:一句话中的第t个词,∈[0, n-1](n是句子的长度)
其中,
ωk是一个减小的频率,使得不同维度的正弦和余弦函数有不同的波长。这样,每个位置的向量都是唯一的,并且相对位置的距离也是一致的。
由此得到位置向量 pt。

位置嵌入的方法是将位置向量加到词嵌入之上,形成一种新的表示输入给模型。也就是说,对于句子里的每个词 ωt,计算其对应的词嵌入ψ(wt),然后按照下面的方法喂给模型:
为了保证这种相加操作正确,应让位置向量(PE)的维度等于词向量(WE)的维度,即
词 ωt?最终被表示为:
Transformer的sin-cos规则的优点是,它可以很容易地泛化到更长的序列,而不需要训练额外的参数。它也可以保持位置信息的有界性和确定性。
Transformer的sin-cos规则的缺点是,它可能不是最优的位置编码方式,因为它没有考虑到语言的语法和语义特征。
Encoder 编码层
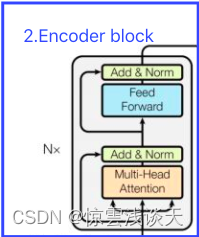
Encoder block是由6个encoder堆叠而成,即Nx=6。一个encoder由Multi-Head Attention 和全连接神经网络Feed Forward Network构成。
Multi-Head Attention
在self-attention机制中,假如输入序列是"Thinking Machines",x1,x2就是对应地"Thinking"和"Machines"添加过位置编码之后的词向量,然后词向量通过三个权值矩阵WQ , WK , WV ,转变成为计算Attention值所需的Query,Keys,Values向量。
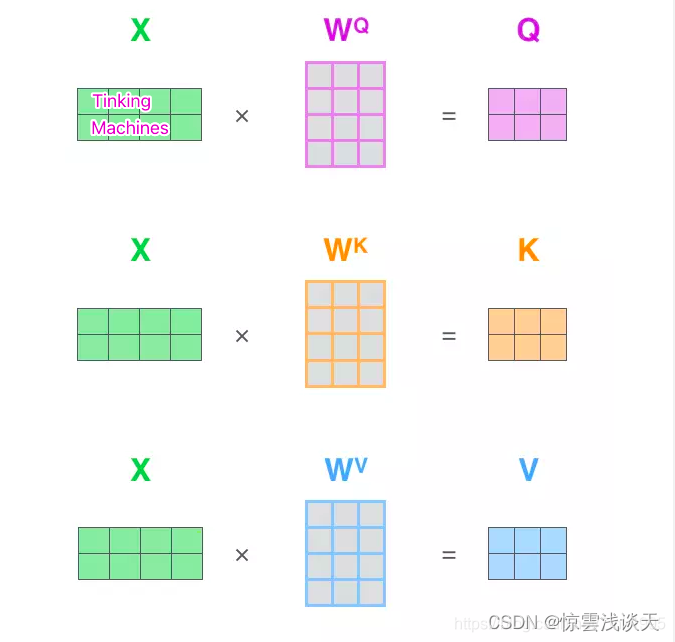
在实际使用中,每一个样本,也就是每一条序列数据都以矩阵的形式输入,因此,通过矩阵乘法可以计算出Q, K ,V三个矩阵。
假设词向量是512维,X矩阵的维度是(2, 512),WQ , WK , WV 均是(512, 64)维,得到的Query,Keys,Values就都是(2,64)维。
求得Q, K, V 之后,计算Attention值
-
dk就是矩阵K的维度(列数),以上面假设为例,dk=64
Multi-Head Attention 就是在self-attention的基础上,对于输入的embedding矩阵,使用多组WQ , WK , WV得到多组Q, K, V,然后每组计算得到一个 Z 矩阵,最后将得到的多个 Z 矩阵拼接。
Transformer里面是使用了8组不同WQ , WK , WV。
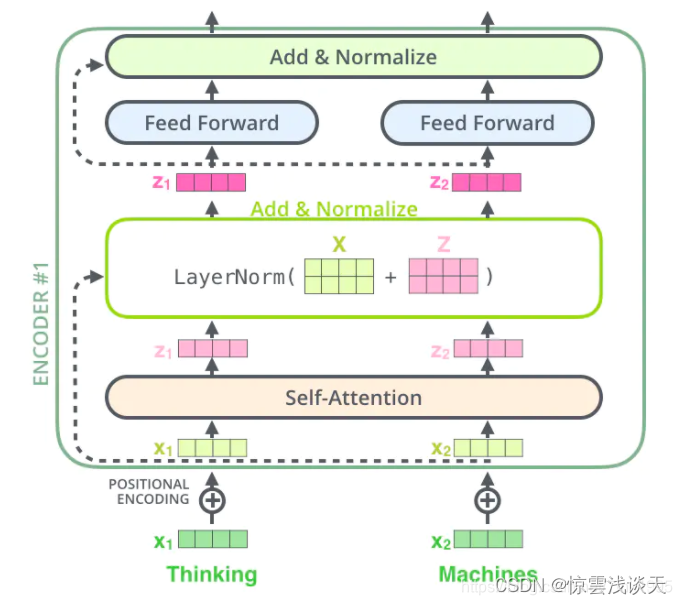
从上图中可以看到,在经过Multi-Head Attention得到矩阵Z之后,并没有直接传入全连接神经网络FNN,而是经过了一步:Add&Normalize。
Add&Normalize
Add是指在Z的基础上加入一个残差块X。加入残差块X的目的是为了防止在深度神经网络训练中发生退化问题。退化就是指,深度神经网络通过增加网络的层数,Loss逐渐减小,然后趋于稳定达到饱和,然后再继续增加网络层数,Loss反而增大的现象。
Transformer中加上的X也就是Multi-Head Attention的输入,X矩阵。
1、为什么深度神经网络会发生退化?
假如某个神经网络的最优网络层数是18层,但是我们在设计的时候并不知道到底多少层是最优解,本着层数越深越好的理念,我们设计了32层,那么32层神经网络中有14层其实是多余的,那么如果达到18层神经网络的最优效果,必须保证这多出来的14层网络进行恒等映射,即输入与输出等同。 但现实是神经网络的参数都是训练出来的,要想保证训练出来的参数能够很精确的完成恒等映射其实是很困难的。多余的层数较少的话,对效果可能不会有太大影响,但多余的层数过多,可能结果就不是很理想了。
2、如何解决?残差块是什么?
使用ResNet 残差神经网络。
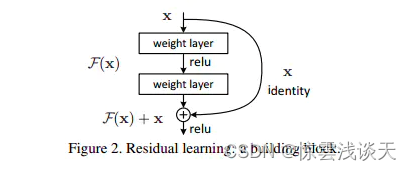
上图就是构造的一个残差块,X是这一层残差块的输入,称F(X)为残差,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(X)加入了这一层输入值X,然后再进行激活后输出。在第二层输出值激活前加入X,这条路径称作shortcut连接。
3、为什么添加了残差块能防止神经网络退化问题?
恒等映射从令h(X)=X,变成了令h(X)=F(X)+X=X,即令F(X)=0。神经网络通过训练变成0要比变成X容易很多。
Normalize
在神经网络进行训练之前,都需要对于输入数据进行Normalize归一化,目的是:加快训练速度、提高训练稳定性。
使用Layer Normalization(LN)而不使用Batch Normalization(BN)
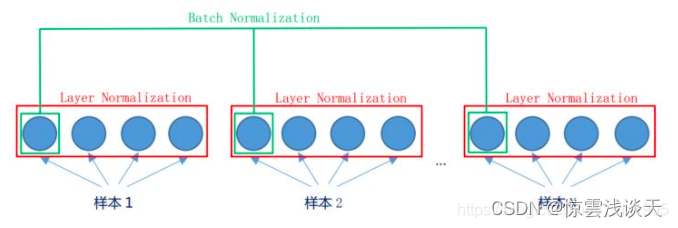
LN是在同一个样本中不同神经元之间进行归一化,而BN是在同一个batch中不同样本之间的同一位置的神经元之间进行归一化。LN是对所有的维度进行归一化,BN是在相同维度基础性上进行的归一化。
Feed-Forward Networks
全连接层公式如下:
这里的全连接层是一个两层的神经网络,先线性变换,然后ReLU非线性,再线性变换。
Decoder 解码层
Decoder层与Encoder层相似,也是由6个decoder堆叠而成,Nx=6。与Encoder层相比,多出了一个Masked Multi-Head Attention。
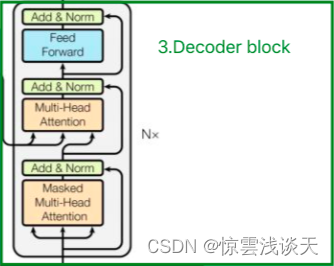
Decoder的输入
Decoder的输入分为两类: 一种是训练时的输入,一种是预测时的输入。
训练时的输入就是已经对准备好对应的target数据。例如翻译任务,Encoder输入"Tom chase Jerry",Decoder输入"汤姆追逐杰瑞"。 预测时的输入,一开始输入的是起始符,然后每次输入是上一时刻Transformer的输出。
Masked Multi-Head Attention
与Encoder的Multi-Head Attention计算原理一样,只是多加了一个mask码。mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。 padding mask是一种对齐输入序列的方法,因为每个批次输入序列长度是不一样的,所以我们需要进行处理。对于较短的序列,在后面填充 0,对于较长的序列,则截取左边的部分。
这些填充的位置是没有意义的,Attention机制不应该把注意力放在这些位置上,所以我们需要把这些位置的值加上一个非常大的负数(负无穷),经过 softmax函数,这些位置的概率就会接近于0。
sequence mask是为了使得 decoder 不能看见未来的信息。对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。
产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
事实上,在Encoder中的Multi-Head Attention也是需要进行mask地,只不过Encoder中只需要padding mask即可,而Decoder中需要padding mask和sequence mask
基于Encoder-Decoder 的Multi-Head Attention Encoder中的Multi-Head Attention是基于Self-Attention的,Decoder中的第二个Multi-Head Attention就只是基于Attention,它的输入Query来自于Masked Multi-Head Attention的输出,Keys和Values来自于Encoder中最后一层的输出。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 动态路由rip配置流程
- 5.5 DataFrame.rolling()创建滚动窗口对象
- 如何查看崩溃日志
- 设备树常用 OF 操作函数说明一
- 现在入坑csgo/cs2游戏搬砖还有利润吗?
- 解锁加密货币增长的秘密:通过 Token Explorer 解读市场信号
- 为什么修改了.gitignore文件不生效,Git常见问题解决
- 代客泊车「新赛点」,撬动大市场
- QT+OSG/osgEarth编译之六十六:dae+Qt编译(一套代码、一套框架,跨平台编译,版本:OSG-3.6.5插件库osgdb_dae)
- 信息论安全与概率论