离线AI聊天清华大模型(ChatGLM3)本地搭建
在特定的情况下,要保证信息安全的同时还能享受到AIGC大模型带来的乐趣和功能,那么,离线部署就能帮助到你,最起码,它是一个真正可用的方案。
大模型本身清华的 (ChatGLM3),为的是对中文支持友好,另外就是我也很看好它,毕竟一直在优化自己的模型,提升模型的质量。
如果基础环境没有布置好可以参考我上篇文章《Ubuntu 22.04 Tesla V100s显卡驱动,CUDA,cuDNN,MiniCONDA3 环境的安装》。
ChatGLM3 (ChatGLM3-6B)
项目地址
https://github.com/THUDM/ChatGLM3大模型是很吃CPU和显卡的,所以,要不有一个好的CPU,要不有一块好的显卡,显卡尽量13G+,内存基本要32GB+。
清华大模型分为三种(ChatGLM3-6B-Base,ChatGLM3-6B,ChatGLM3-6B-32K)
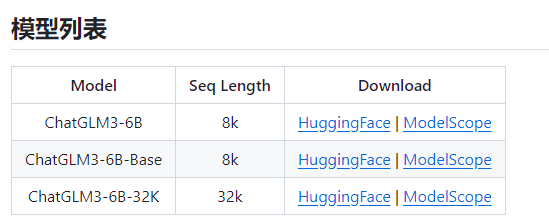
从上图也可以看到,ChatGLM3-6B-32K的话是最高配的模型,而ChatGLM3-6B-Base是最低配的模型。
一般会选择 ChatGLM3-6B普通模型来使用,当然,如果配置高,可以用32K的,会更好。
ChatGLM3 部署
如果不能访问github,那么就不容易下载资源了,主要是资源也比较大,可以自己想办法。
ChatGLM3 项目git clone
很简单一句命令就下载下来了。
git?clone?https://github.com/THUDM/ChatGLM3执行完,就下载完毕了
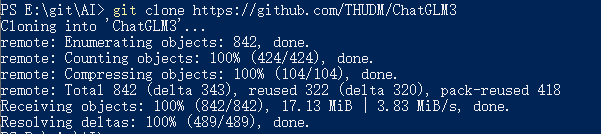
但是,默认里面是没有模型的,只有自带的简单的聊天项目以及相关的接口示例项目,还得继续下载模型。
ChatGLM3-6B 模型下载
当然,如果你自己不下载这些模型,这些模型就会在运行的时候自动下载(网络不好的话会影响使用体验,所以,建议提前下载)
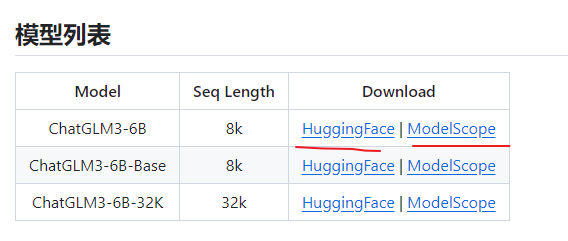
模型下载提供了两个地址来下载,第一个不可以,那就选择第二个。
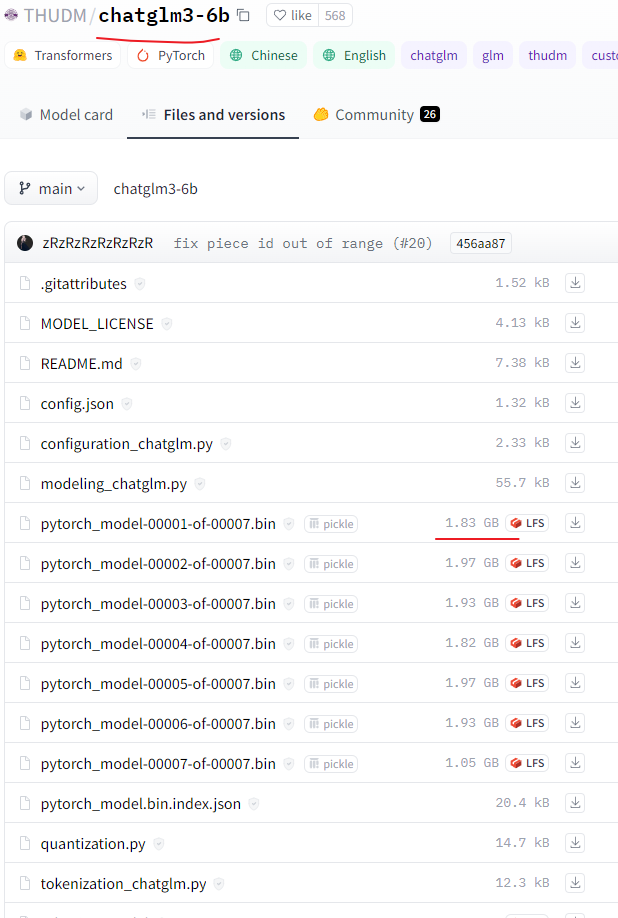
打开地址后,发现这个文件还挺大,而且还是 git项目的方式来进行展现的。
其中 LFS那种可以直接点击然后,保存的方式来下载,也可以用git命令来下载。
git?lfs?install需要 git增加 lfs 的功能,才能直接下载这么大的文件
?git?clone?https://huggingface.co/THUDM/chatglm3-6b或者
git?clone?https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git下载完毕后,就有很多文件
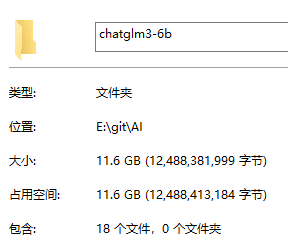
看一下大小 11.6GB ,还挺大的
项目配置和部署
把下载的服务直接放到需要运行的地方 然后,执行上节的python 环境管理
conda?create?--name?chatglm3?python=3.10
conda?activate?chatglm3然后,进入到主项目中,开始配置一些环境
cd?ChatGLM3第一步是要安装python 的依赖包
pip?install?-r?requirements.txt?-i?https://mirror.sjtu.edu.cn/pypi/web/simple
它会自己安装一些依赖包,很快就安装完了
也可以查询自己安装了什么包
pip?list??????????????????//查看安装了什么包
pip?show?openai?//?查看包安装到了哪里当然,我也是按照 README.md 里面的部署方式来部署的,具体以README.md为准。
修改配置
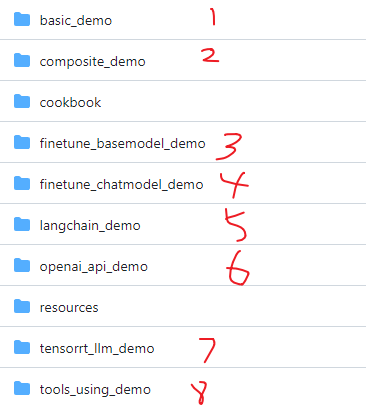
可以看到,实际上我们可以运行8种案例。
-
1.?基础例子(cli_demo , web_demo_streamlit )
-
2.?综合例子(聊天,工具,代码解释)
-
3.?基础模型微调
-
4.?聊天模型微调
-
5.?类似于langchain的案例
-
6.?openai接口的案例
-
7.?TensorRT-LLM推理部署
-
8.?工具调用
目前,只有第二种的综合例子,是比较有趣的,就以它为案例进行配置修改。
composite_demo
看到,这个demo下还有requirements.txt 文件,我们把他给安装了
pip?install?-r?requirements.txt?-i?https://mirror.sjtu.edu.cn/pypi/web/simple演示中使用 Code Interpreter 还需要安装 Jupyter 内核:
pip?install?ipykernel?-i?https://mirror.sjtu.edu.cn/pypi/web/simple
ipython?kernel?install?--name?chatglm3?--user接着修改client.py里面的配置信息
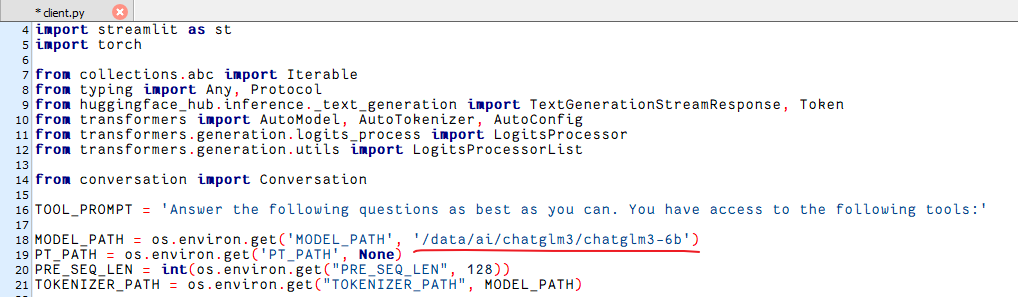
修改里面的模型地址为你的模型地址即可,我这边直接写了个绝对路径。
然后,执行以下命令启动服务
streamlit?run?main.py正常情况下,控制台会出现以下信息
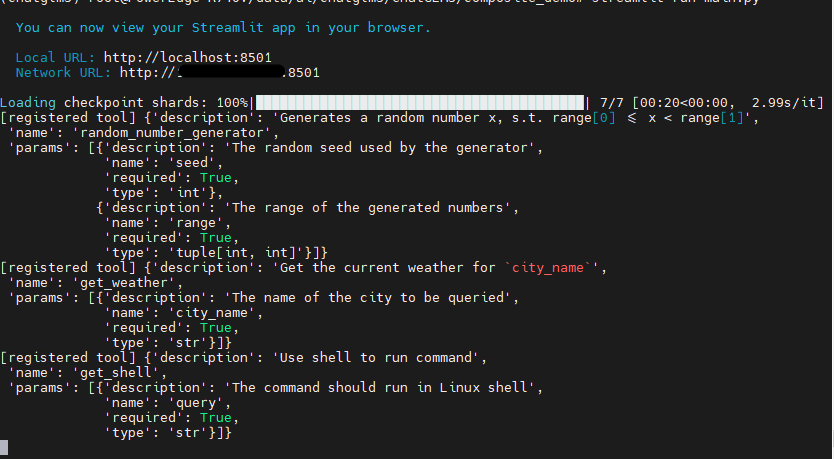
而网页会出现以下信息
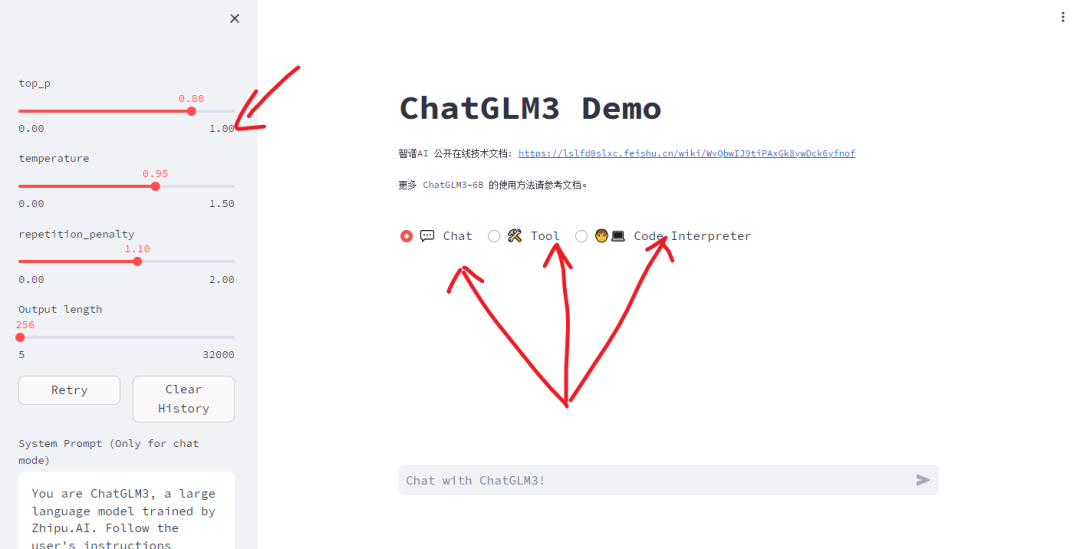
左侧就像OpenAI那种的参数细节的调整,右侧是三种不同的使用方式选择。
效果展示
对话模式
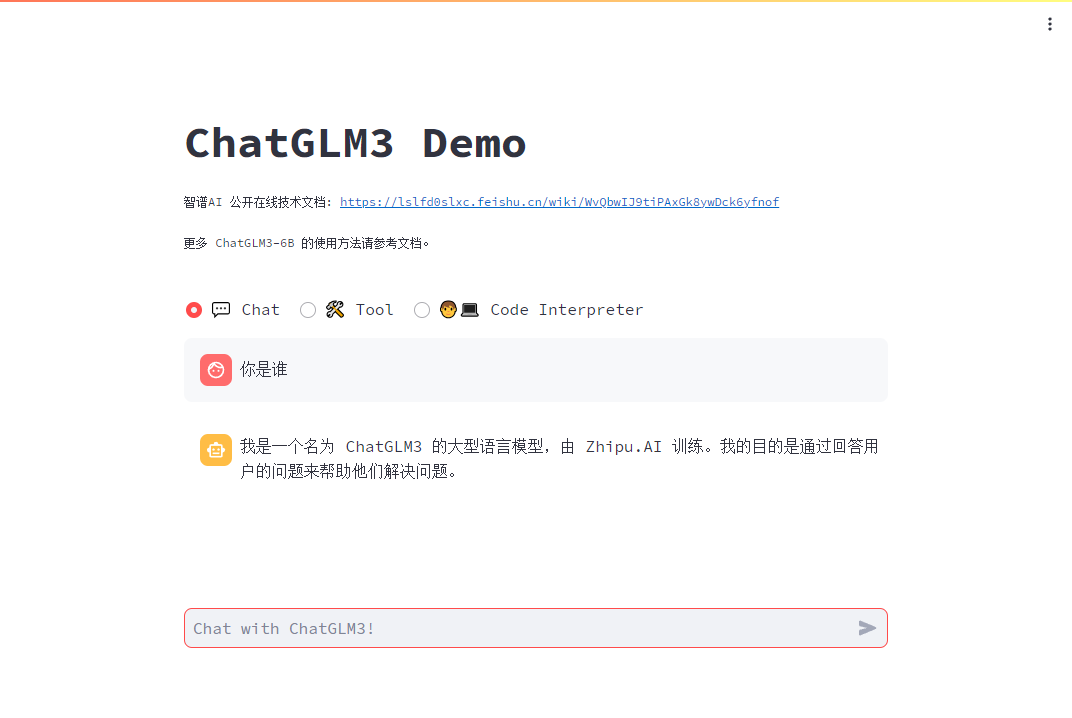
输入你是谁,它就输自动的输出信息,速度还挺快。
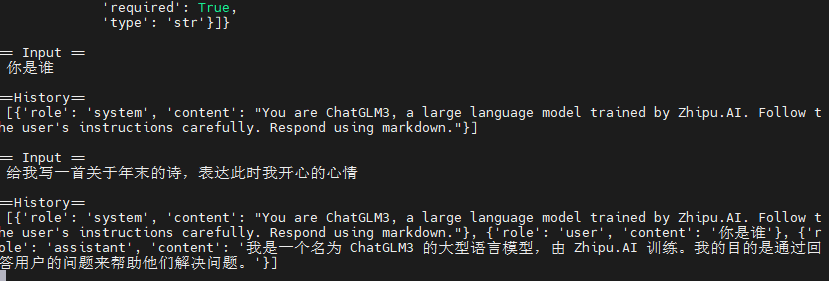
而控制台也会显示你输入的信息以及返回的信息。
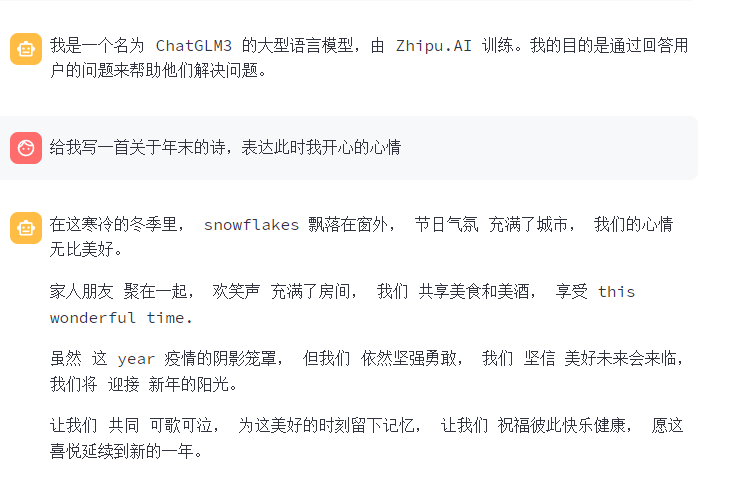
根据这个问题可以看到,这个模型,虽然对中文的支持度很高,但是,也掺杂一些英文信息。
工具模式
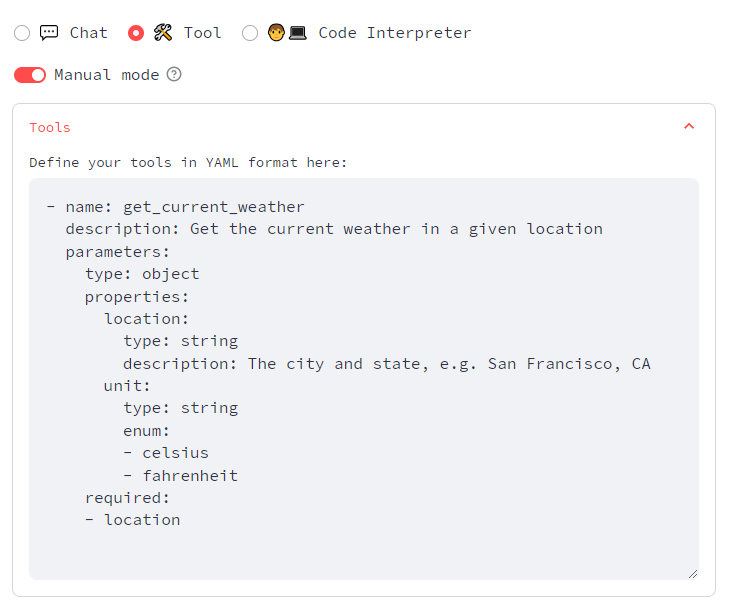
工具模式,需要自己先定义工具,我这边没有定义,有兴趣的可以整一下。
以下是自带的工具进行的演示:
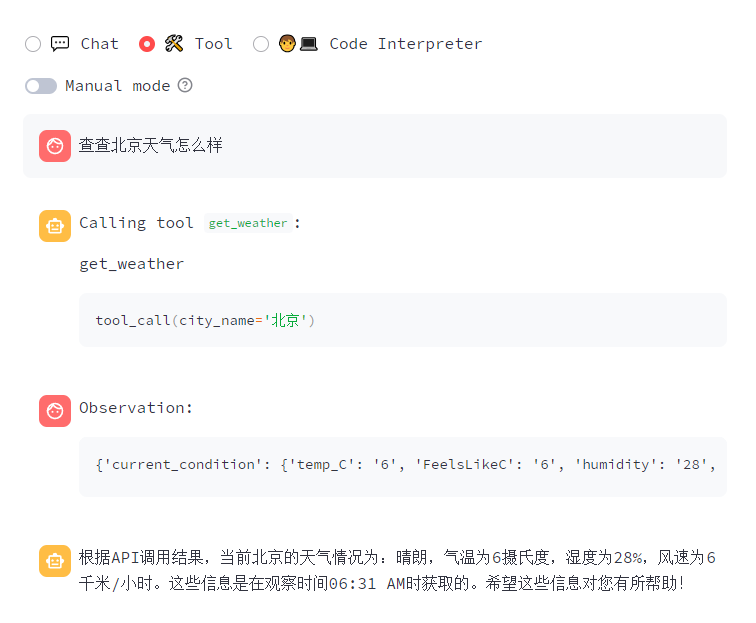
我调用了一个查询天气的工具(tool_registry.py) 文件可以看到 get_weather的代码
@register_tool
def?get_weather(
????????city_name:?Annotated[str,?'The?name?of?the?city?to?be?queried',?True],
)?->?str:
????"""
????Get?the?current?weather?for?`city_name`
????"""
????if?not?isinstance(city_name,?str):
????????raise?TypeError("City?name?must?be?a?string")
????key_selection?=?{
????????"current_condition":?["temp_C",?"FeelsLikeC",?"humidity",?"weatherDesc",?"observation_time"],
????}
????import?requests
????try:
????????resp?=?requests.get(f"https://wttr.in/{city_name}?format=j1")
????????resp.raise_for_status()
????????resp?=?resp.json()
????????ret?=?{k:?{_v:?resp[k][0][_v]?for?_v?in?v}?for?k,?v?in?key_selection.items()}
????except:
????????import?traceback
????????ret?=?"Error?encountered?while?fetching?weather?data!\n"?+?traceback.format_exc()
????return?str(ret)代码解释器模式
我尝试了很久也没有得到以下的效果。
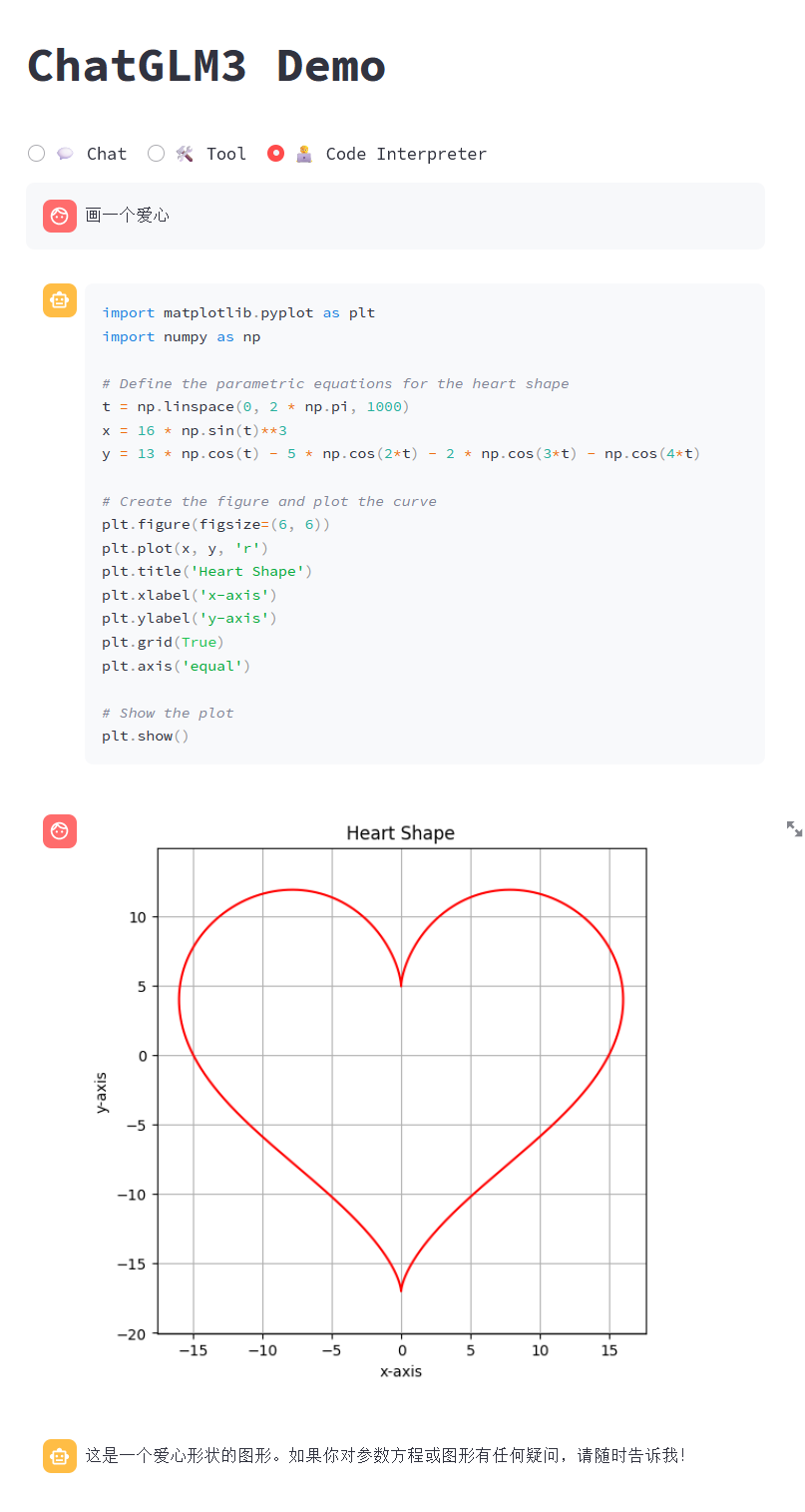
可能是我的打开姿势不对,我只能获取这样的。
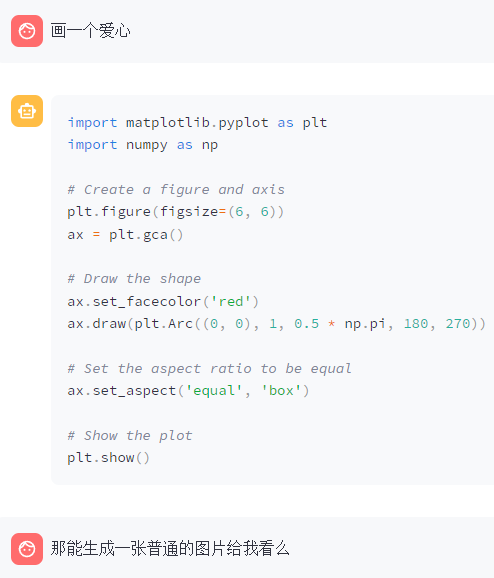
但是,给出的代码,还是很合理的,看着就能执行。
感兴趣的可以参考
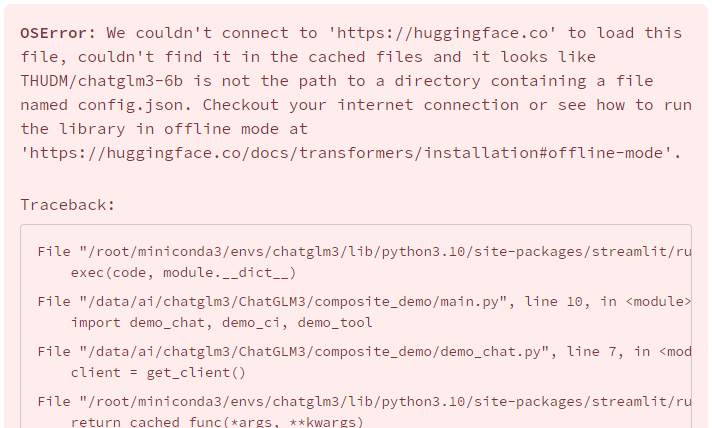
https://zhipu-ai.feishu.cn/wiki/VdYWwcZfmiNBnlkwYf1cqytcngf异常:
如果没有修改配置就会出现这个问题,当然,如果网络好的话,它会自己去安装。
总结
至此 ChatGLM3就演示完了,效果还是不错的说。比之前版本好太多了,我还会继续关注它的。
它也可以通过Web api的方式,自己搞个前端进行展现。
总体来讲,清华ChatGLM3-6B大模型对中文支持度还是蛮高的。
参考资料地址
《清华ChatGLM3?ChatGLM3-6B?大模型》
https://github.com/THUDM/ChatGLM3本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 50套Threejs实现的Web3D学习案例,总有一套适合你
- 文件操作一(非常重要)
- Concurrency in C# Cookbook中文翻译第六章System.Reactive基础知识
- Unity网格篇Mesh(二)
- 史上最牛软件开发工位
- 如何为项目创建高效的项目进度表?
- 第二证券:开通创业板交易权限的条件是什么?
- 开源进程/任务管理服务Meproc之事件插件开发
- 计算机网络(2):物理层
- django智慧迎新管理系统(程序+开题)