高级RAG(五):TruLens 评估-扩大和加速LLM应用程序评估
之前我们介绍了,RAGAs评估,今天我们再来介绍另外一款RAG的评估工具:TruLens , trulens是TruEra公司的一款开源软件工具,它可帮助您使用反馈功函数客观地评估基于 LLM 的应用程序的质量和有效性。反馈函数有助于以编程方式评估输入、输出和中间结果的质量,以便我们可以加快和扩大实验评估,并将其用于各种应用场景,包括问答、检索增强生成和基于代理的应用程序。
一、核心概念
1.1 反馈函数
反馈函数,类似于标记函数,提供了一种在应用程序运行时生成评估的编程方法。TruLens的反馈函数的实现包装了一个受支持的提供者模型,比如一个相关性模型或一个情感分类器,它被重新用于提供评估。通常,为了获得最大的灵活性,这个模型也可以是另一个LLM。
在两个维度上考虑评估范围是非常有用的:可扩展性(Scalable)和有意义(Meaningful)。

领域专家评估(Ground Truth?Evals)
在早期开发阶段,我们建议从领域专家评估开始。这些评估通常是由开发人员自己完成的,代表了你的应用程序期望完成的核心用例。这让你能够更深入地了解应用的性能,但却缺乏规模性。
用户反馈(人工)评估(Human Evals)
在你完成了早期评估并对你的应用获得更多信心后,收集人们的反馈通常是有用的。这通常以用户提供的二元(上/下)反馈的形式出现。这比基本事实(Ground Truth)的可扩展性稍强,但与方差作斗争,并且收集起来仍然很昂贵。
传统 NLP 评估(Traditional NLP Evals)
传统的 NLP 指标进行评估是一种常见的做法,例如 BLEU 和 ROUGE。虽然这些评估具有极高的可扩展性,但它们通常过于语法化,并且无法提供有关应用程序性能的有意义的信息。
中等语言模型评估(MLM Evals)
中等语言模型(如BERT)是LLM应用评估的最佳选择。这种规模的模型运行起来相对便宜(可扩展),还可以为你的应用提供细微的、有意义的反馈。在某些情况下,这些模型需要进行微调,以便为你的领域提供正确的反馈。
TruLens提供了许多开箱即用的反馈功能,这些功能依赖于这种模型风格,如基础NLI、情感、语言匹配、适度等。
大型语言模型评估(LLM Evals)
大型语言模型也可以为LLM应用程序的性能提供有意义和灵活的反馈。通常通过简单的提示,基于LLM的评估可以提供与人类非常一致的有意义的评估。此外,它们可以很容易地用LLM提供的推理来扩展,以证明对调试有用的高或低评估分数。
根据LLM的规模和性质,这些评估在规模上可能相当昂贵。
1.2 RAG三元组
为了避免LLM产生幻觉,RAG已经成为为LLM提供上下文(Context)的标准架构。然而,即使是RAG也会产生幻觉,因为当检索器无法检索到足够的上下文,甚至检索到不相关的上下文,然后将其传送给LLM后,LLM也可能产生幻觉。
TruEra创新的使用了RAG三元组来评估RAG架构的每条边的幻觉,如下所示:
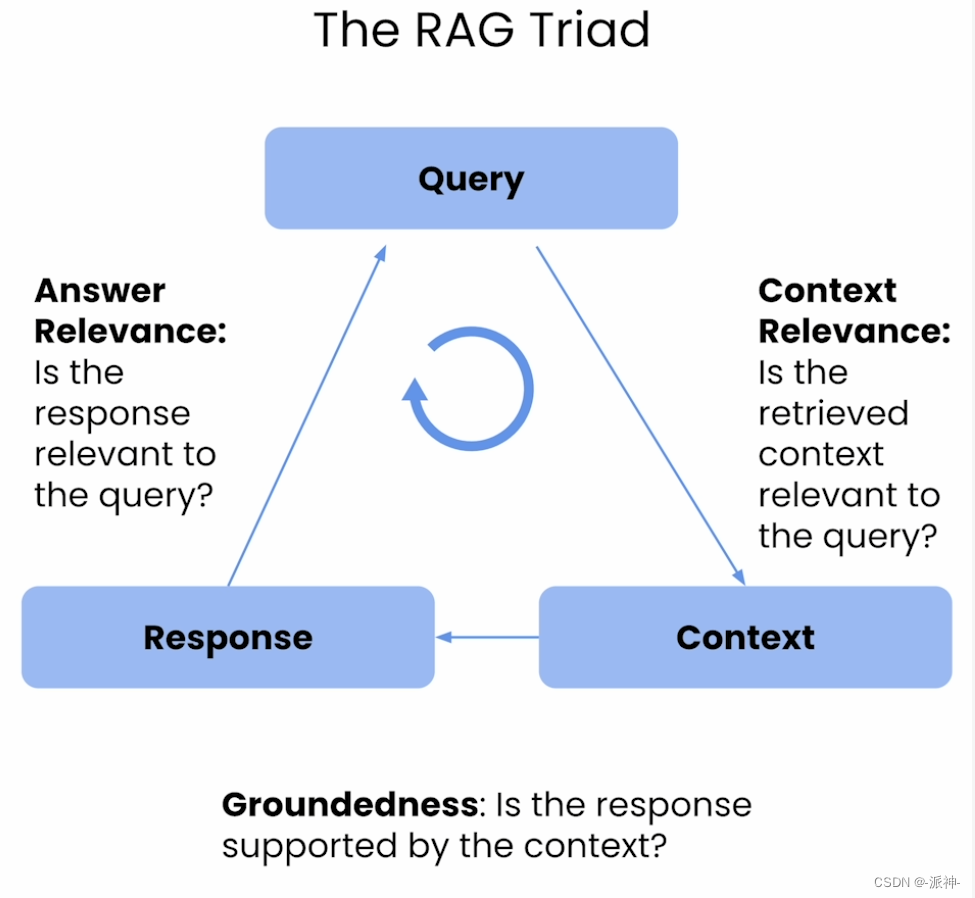
?RAG 三元组由 3 个评估组件组成:上下文相关性(Context Relevance)、基础性(Groundedness)和答案相关性(Answer Relevance)。?
上下文相关性(Context Relevance)
任何 RAG 应用程序的第一步都是检索;为了验证检索的质量,我们希望确保每个检索到的上下文文档块(Context)都与输入查询(question)相关。这一点至关重要,因为LLM将使用此Context来形成答案(answer),因此Context中任何不相关的信息都可能会被编织成幻觉。TruLens 使您能够使用序列化记录的结构来评估上下文相关性。
基础性(Groundedness)
在检索上下文之后,然后由LLM将其形成答案。LLM往往倾向于偏离所提供的事实,夸大或扩展到一个听起来正确的答案。为了验证我们的应用程序的基础性(groundedness),我们可以将LLM产生的答案(answer)分成单独的主张(claims),并在检索的上下文(Context)中独立地搜索支持每个主张的证据。
答案相关性(Answer Relevance)
最后,我们的答案(answer)仍然需要有助于回答最初的问题。我们可以通过评估最终答案与用户输入(question)的相关性来验证这一点。
将它们组合在一起
如果我们对这个三元组进行评估后获得了满意的结果,?我们可以明确的说我们的应用程序经验证在其知识库的限制范围内不会出现幻觉。 换句话说,如果向量数据库包含的信息时准确的,那么RAG提供的答案也是准确的。
二、基本的RAG管道
2.1?基本的RAG管道介绍
在进行TruLens评估之前,我们首先回顾一下基本的RAG架构:
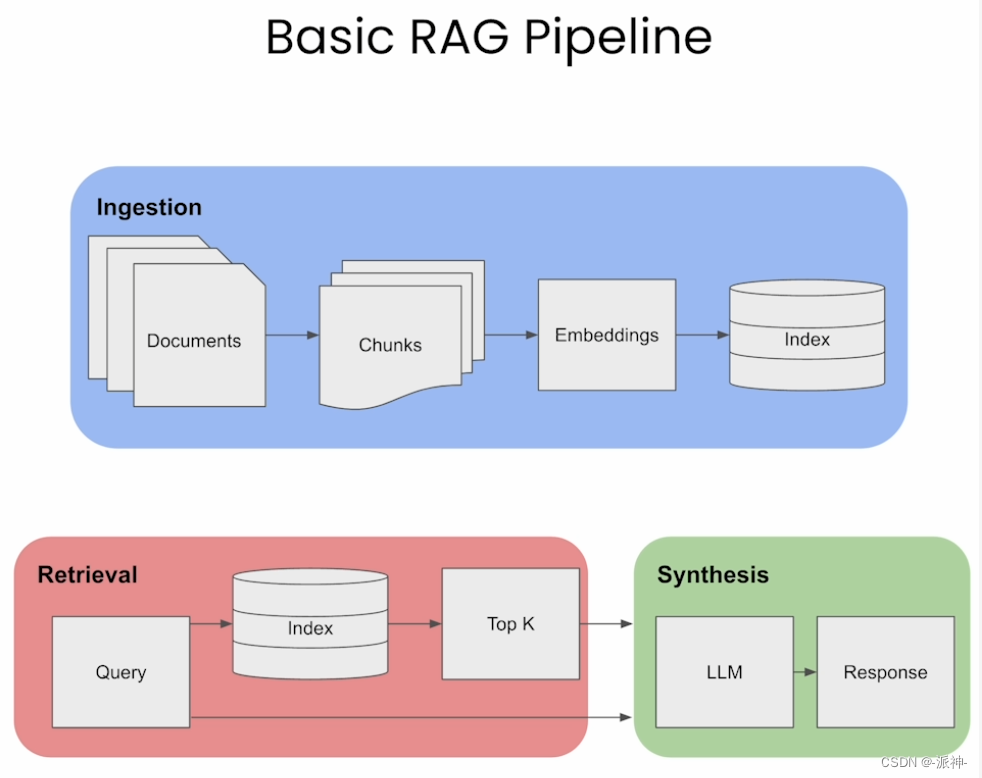
在基本RAG架构中包含了文档数据的处理,文档内容检索、LLM应答等环节,其中文档数据处理包含了文档的分割,向量化处理,向量数据库存储等步骤,而文档内容检索又包含了对向量数据库内容的相似度搜索,获取top_k个相关文档等步骤,然后将相关文档(context)和用户问题传送给LLM并产生最终的答案(answer), 如果对这些过程和步骤还不熟悉的朋友可以看一下我之前写的使用langchain与你自己的数据对话系列博客。接下来我们要使用llamaIndex开发一个基本RAG应用程序,并使用TruLens的RAG三元组对其进行评估。
2.2 环境配置
我们首先需要安装如下python包:
pip install llama_hub
pip install llama_index
pip install trulens-eval接下来我们需要做一些初始化的工作,比如导入openai,gemini等大模型的api_key:
import os
from dotenv import load_dotenv, find_dotenv
#导入.env配置文件
_ = load_dotenv(find_dotenv()) 2.3 加载文档数据
今天我们同样使用上一篇博客:RAGAs评估 中的相同数据即从百度百科的网页中抓取关于恐龙的文章:
这里我们使用的是LlamaIndex 的数据爬虫工具:TrafilaturaWebReader
from llama_index.readers.web import TrafilaturaWebReader
url="https://baike.baidu.com/item/恐龙/139019"
docs = TrafilaturaWebReader().load_data([url])
docs
2.4 切割文档
接下来我们要对该文档进行切割,我们首先需要创建一个文档切割器:
from llama_index.node_parser import SimpleNodeParser
from llama_index.schema import IndexNode
#创建文档切割器
node_parser = SimpleNodeParser.from_defaults(chunk_size=1024)
node_parser
?这里我们创建了一个简单的文档切割器,并且将chunk_sez设置为1024,这样我们被切割出来的文档块长度将会在1024左右。
#切割文档
base_nodes = node_parser.get_nodes_from_documents(docs)
len(base_nodes)
这里我们看到,原来的文档被切割成了30个文档块,下面我们看一下文档块中的内容:
base_nodes[5]
2.5 设置Embedding 和 LLM
接下来我们要设置一些基础组件,其中包括:embedding模型,llm,service_context,这里我们的embedding模型选择的是开源的bge-small-zh-v1.5模型,llm选择的是openai的gpt-3.5-turbo模型,当然你也可以选择gemini模型:
from llama_index.embeddings import resolve_embed_model
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import OpenAI
#from llama_index.llms import Gemini
#创建BAAI的embedding
embed_model = resolve_embed_model("local:BAAI/bge-small-zh-v1.5")
#创建OpenAI的llm
llm = OpenAI(model="gpt-3.5-turbo")
#创建谷歌gemini的llm
# llm = Gemini()
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embed_model
)2.6 创建?Index, retriever, query engine
#创建index
base_index = VectorStoreIndex(base_nodes, service_context=service_context)
#创建检索器
base_retriever = base_index.as_retriever(similarity_top_k=2)
#检索相关文档
retrievals = base_retriever.retrieve(
"恐龙是冷血动物吗?"
)接下来我们可以查看和问题:"恐龙是冷血动物吗?"相关的文档:
from llama_index.response.notebook_utils import display_source_node
for n in retrievals:
display_source_node(n, source_length=1500)
这里我们看到由于我们在创建检索器的时候设置了similarity_top_k=2,即让检索器每次都返回2个与用户问题相似度最高的文档,在上面的返回结果中我们同时还看到检索器除了返回相关node的内容(Text)以外,还返回了Node Id,相似度值Similarity。接下来我们要请出大模型ChatGPT根据检索器返回的相关文档来回答用户的问题,下面我们看看ChatGPT的回答:
#openai的回答
response = query_engine_base.query(
"恐龙是冷血动物吗?"
)
print(str(response))
?这里我们看到chatgpt模型在这两个相关文档的基础上归纳出了一个比较完整的且对用户友好的答案。
?三、TruLens 评估
3.1 什么是反馈函数
反馈函数的作用是在审查 LLM 应用程序的输入,输出和中间结果后给出一个分数。下面我们要定义一个评估器对象,和一个provider,其中评估器对象会初始化一个数据库,该数据库用来存储prompt、reponse、中间结果等信息。provider则用来执行反馈功能。
from trulens_eval import Tru
from trulens_eval import OpenAI as fOpenAI
import nest_asyncio
#设置线程的并发执行
nest_asyncio.apply()
#创建评估器对象
tru = Tru()
#初始化数据库,它用来存储prompt、reponse、中间结果等信息。
tru.reset_database()
#定义一个provider用来执行反馈
provider = fOpenAI()?接下来我们需要定义Answer Relevance、Context Relevance、Groundedness等3个反馈函数。
3.2?答案相关性(Answer Relevance)
Answer Relevance评估的是最终的答案(answer)与用户的问题(question)相关程度。它的主要结构如下图所示:
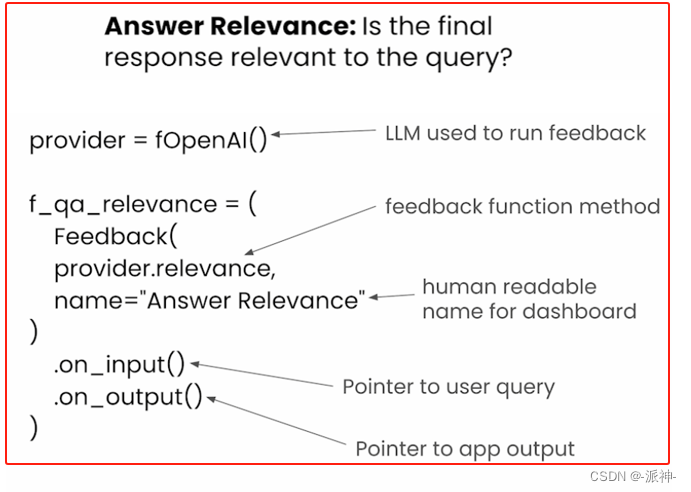
?下面我们来定义一个Answer Relevance反馈函数
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()3.3?上下文相关性(Context Relevance)
Context Relevance评估的是检索出来的上下文(Context )与用户的问题(question)相关程度。由于我们会设置检索器返回的检索结果的数量(如similarity_top_k), 所以在计算Context Relevance指标时会对返回的多个上下文取平均值。
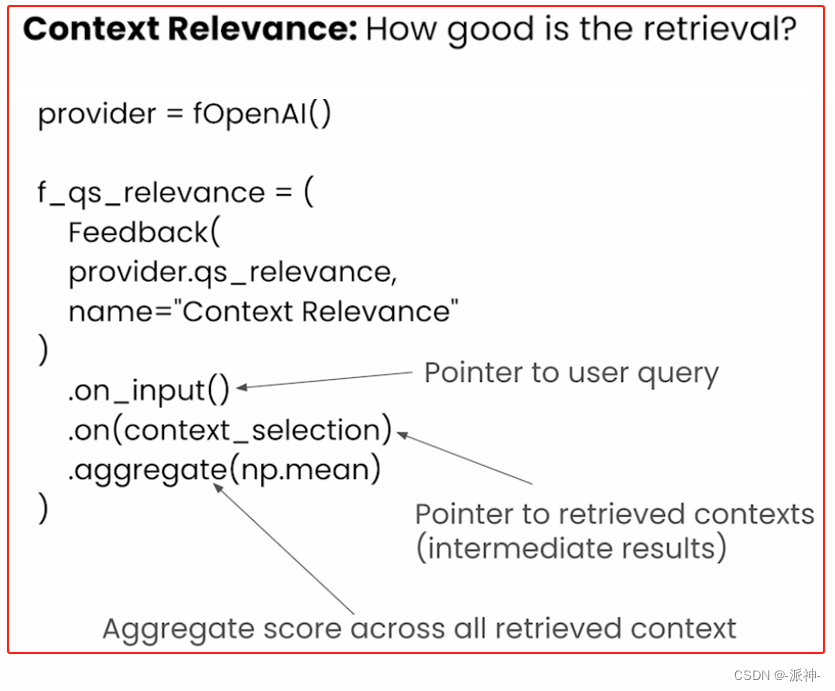
下面我们来定义一个Context Relevance反馈函数?
import numpy as np
from trulens_eval import TruLlama
context_selection = TruLlama.select_source_nodes().node.text
f_qs_relevance = (
Feedback(provider.qs_relevance,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)3.4 基础性(Groundedness)
Groundedness用来评估LLM提供的答案(answer)和上下文(context)相关程度,或者说,当Groundedness的分数很低时,说明LLM产生了幻觉,理想情况下因为我们希望answer完全由context总结(推导)出来,当Groundedness的分数较高时可以排除LLM产生幻觉的可能性。下面我们来定义一个Groundedness反馈函数:
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)3.5 评估RAG三元组
前面我们定义了三个反馈函数:f_qa_relevance、f_qs_relevance、f_groundedness,接下来我们要定义一组问题,然后通过基本RAG管道来检索答案,最后我们通过这些问题和答案来实现对基本RAG管道的评估:
from trulens_eval import TruLlama
from trulens_eval import FeedbackMode
#
tru_recorder = TruLlama(
query_engine_base,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
#定义问题
eval_questions = ["恐龙是怎么被命名的?",
"恐龙怎么分类的?",
"体型最大的是哪种恐龙?",
"体型最长的是哪种恐龙?它在哪里被发现?",
"恐龙采样什么样的方式繁殖?",
"恐龙是冷血动物吗?",
"陨石撞击是导致恐龙灭绝的原因吗?",
"恐龙是在什么时候灭绝的?",
"鳄鱼是恐龙的近亲吗?",
"恐龙在英语中叫什么?"
]
#执行评估,LLM回答所有的问题
for question in eval_questions:
with tru_recorder as recording:
query_engine_base.query(question)
#展示评估结果
records, feedback = tru.get_records_and_feedback(app_ids=[])
records[['input', 'output']] = records[['input', 'output']].applymap(lambda x: x.encode('latin1').decode('unicode_escape'))
records[["input", "output"]+feedback]
?这里我们看到除了Context Relevance的分数有较大的波动之外,Groundedness和Answer Relevance的分数都是比较高,其中所有问题的Answer Relevance分数都是1,说明Answer和question有非常高的相关性,并且Groundedness除了两个问题之外剩余的8个问题得分都是1,这说明answer基本上都是从上下文(Context)中推导(或是总结)出来的,因此可以肯定的说answer不是由于LLM的幻觉产生的。另外Context Relevance分数较低这是和我们在拆分文档时设置的块大小(chunk_size)有关,当chunk_size设置的太大时文档块中可能会包含更多的信息,这就会导致检索到的文档块内容(context)和question的相关性降低。但是由于我们使用的是openai的gpt-3.5模型,它有着非常强大的推理能力,尽管我们的Context Relevance分数较低,但gpt-3.5模型仍然能够从中推导出正确的答案。下面我们看一下这10个问题的总体成绩:
tru.get_leaderboard(app_ids=[])
这里我们看到了总体的评估结果除了Context Relevance,Groundedness和Answer Relevance之外还包括了评估的耗时(latency),以及评估的总成本(total_cost),其中耗时耗时(latency)花费了10.25秒,而评估的成本花费了$0.003322美刀,而总成本是通过计算question,context,answer统计出来的。
四、总结
今天我们学习了TruLens评估的基本原理,其中包括RAG三元组Context Relevance,Groundedness和Answer Relevance的定义和作用,然后我们又使用llamaIndex开发了基本RAG应用,最后我们使用了TruLens的反馈函数对基本RAG的检索结果进行了评估。希望今天的内容对大家学习RAG有所帮助.
五、参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uniapp组件定义
- 9道软件测试面试题,刷掉90%的测试程序员
- Postgres提升Superuser权限
- 配网故障定位装置:实现高效故障排查的利器
- C#使用MongoDB-第二章 序列化
- Redis 有序集合(sorted set)常见问题
- Qt-UI界面无法输入名字
- SysTick 定时器
- Jmeter、postman、python 三大主流技术如何操作数据库?
- Spring Boot - Application Events 的发布顺序_ApplicationPreparedEvent