深度学习论文解读分享之diffGrad:一种卷积神经网络优化方法
IEEE TNNLS 2020:diffGrad: 一种卷积神经网络优化方法
题目
diffGrad: An Optimization Method for Convolutional Neural Networks
作者
Shiv Ram Dubey , Member, IEEE, Soumendu Chakraborty , Swalpa Kumar Roy , Student Member, IEEE, Snehasis Mukherjee, Member, IEEE, Satish Kumar Singh, Senior Member, IEEE,
and Bidyut Baran Chaudhuri, Life Fellow, IEEE
关键词
Adaptive moment estimation (Adam), difference of gradient, gradient descent, image classification, neural networks, optimization, residual network.
研究动机
解决模型训练容易陷入局部最优的情况
模型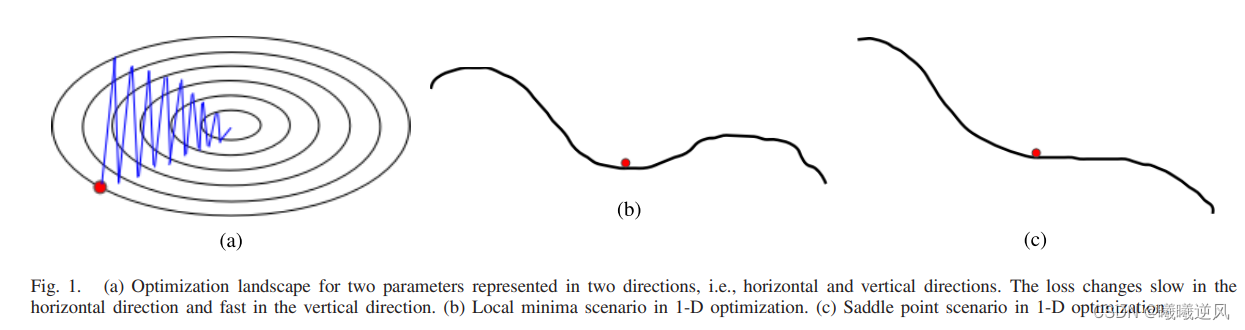
随机梯度下降(SGD)是深度神经网络成功的核心技术之一。梯度提供了函数变化速度最快的方向的信息。基本SGD的主要问题是对所有参数以相同大小的步长变化,而不考虑梯度行为。因此,深度网络优化的一个有效方法是对每个参数具有自适应的步长。最近,人们试图改进梯度下降方法,如AdaGrad、AdaDelta、RMSProp和自适应矩估计(ADAM)。这些方法依赖于过去梯度平方的指数滑动平均的平方根,因此这些方法没有利用梯度的局部变化,因此提出了一种基于当前梯度和最近过去梯度之差的优化器(即DiffGrad)。在DiffGrad优化技术中,对每个参数的步长进行调整,使其具有较大的步长和较小的步长,以适应较快的梯度变化参数和较低的梯度变化参数。收敛分析采用在线学习框架的遗憾界方法。本文对三个合成的复非凸函数进行了深入的分析。并在CIFAR10和CIFAR100数据集上进行了图像分类实验,观察了DifferGrad相对于SGDM、AdaGrad、AdaDelta、RMSProp、AMSGrad等最新优化器的性能,实验中采用了基于残差单元(ResNet)的卷积神经网络(CNN)结构,实验结果表明,DiffGrad的性能优于其他优化器。此外,我们还表明,对于使用不同的激活函数训练CNN,DiffGrad的性能是一致的。
亮点
采用了类似学习率动量(momentum)的策略。
论文以及代码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 归并排序(五)——归并排序的递归与非递归
- GreenPlum-数据世界的绿洲
- 关于进程process
- 图片处理工具(任意像素扩图、涂鸦、清理、剔除、换脸、替换天空等)
- 股市中的Santa Claus Rally (圣诞节行情)
- B2107 图像旋转 题解
- Linux权限
- 前后端分离下的鸿鹄电子招投标系统:使用Spring Boot、Mybatis、Redis和Layui实现源码与立项流程
- vite 打包二级目录记录
- 编写系统服务脚本