杨中科 EFCORE 第三部分 主键
主键
自增主键
1、EF Core支持多种主键生成策略:自动增长;Guid;Hi/Lo算法等。
2、自动增长。
优点:简单;
缺点: 数据库迁移以及分布式系统中(多数据库合并,会有重复主键值)比较麻烦;并发性能差(大并发情况下,为了保证自增且不重复,会加锁)。
long、int等类型主键,默认是自增。因为是数据库生成的值,所以SaveChanges后会自动把主键的值更新到Id属性。试验一下。场景: 插入帖子后,自动重定向帖子地址。
3、自增字段的代码中不能为Id赋值,必须保持默认值0.否则运行的时候就会报错
示例:SaveChanges后会自动把主键的值更新到Id属性
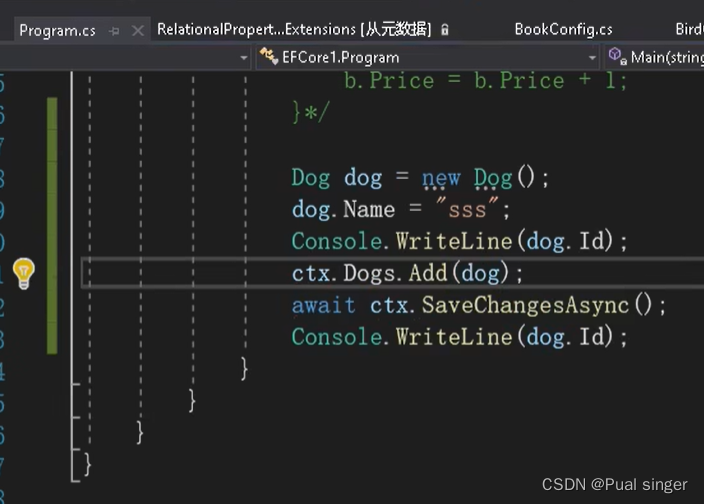

为主键指定值会报错

Guid主键
1、Guid算法 (或UUID算法) 生成一个全局唯一的Id。适合于分布式系统,在进行多数据库数据合并的时候很简单。优点:简单,高并发全局唯一;缺点: 磁盘空间占用大。
2、Guid值不连续。使用Guid类型做主键的时候,不能把主键设置为聚集索引。因为聚集索引是按照顺序保存主键的,因此用Guid做主键性能差。比如MySQL的InnoDB引警中主键是强制使用聚集索引的。有的数据库支持部分的连续Guid,比如SOLServer中的NewSeguentialId(),但也不能解决问题。在SQLServer等中,不要把Guid主键设置为聚集索引; 在MySQL中,插入频繁的表不要用Guid做主键。
3、演示Guid用法:既可以让EF Core给赋值,也可以手动赋值 (推荐)
示例:
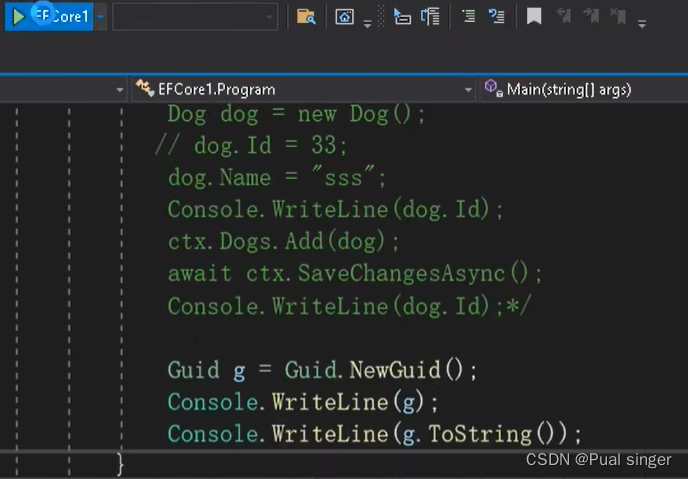
运行多次,每次生成的数据都不同
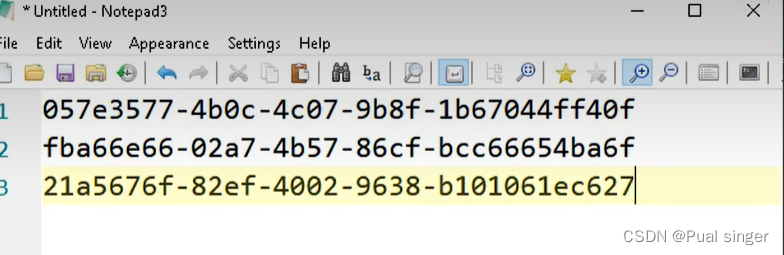
guid 使用示例
1.新建 Rabbit 类
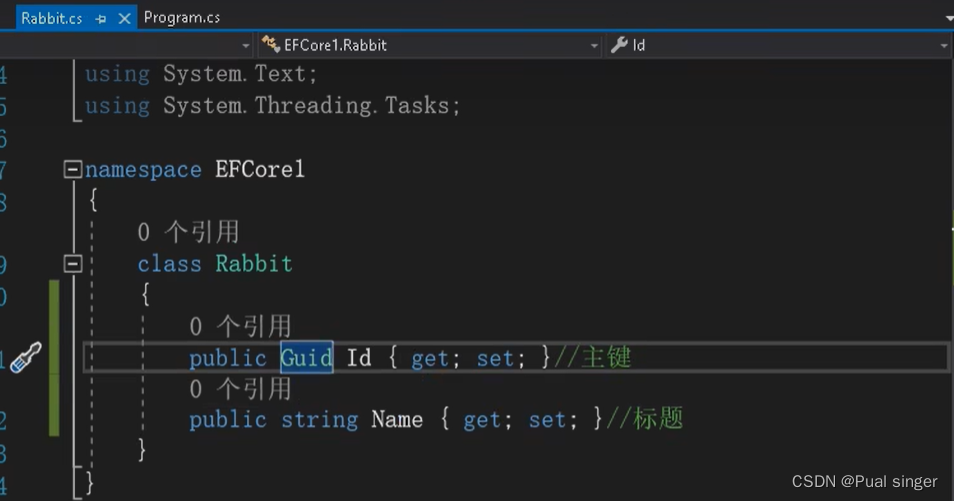
在DbContext中 配置
命令执行

结果:

插入数据
默认方式:
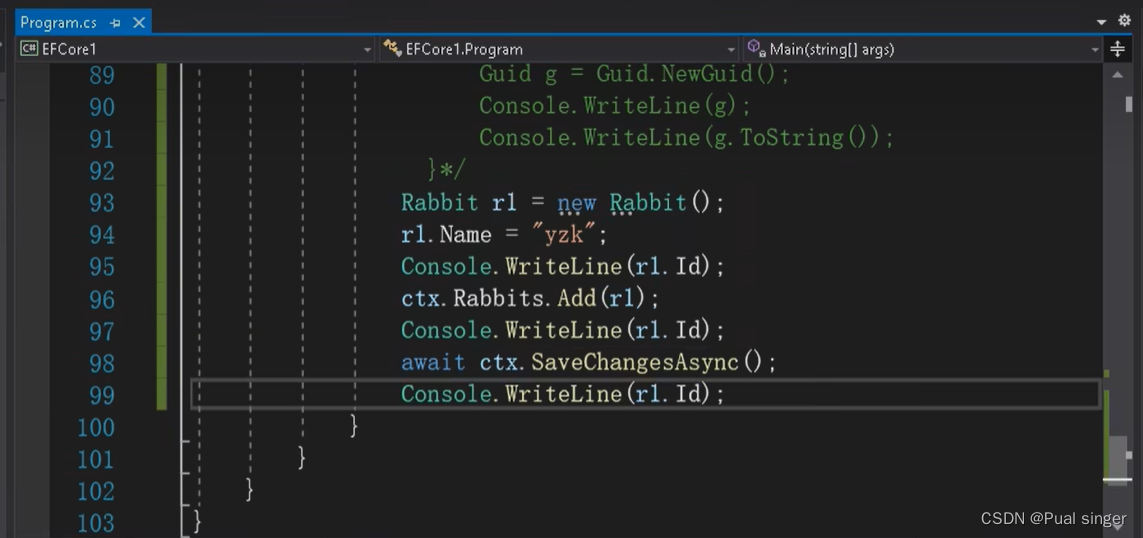
运行结果:
手动方式
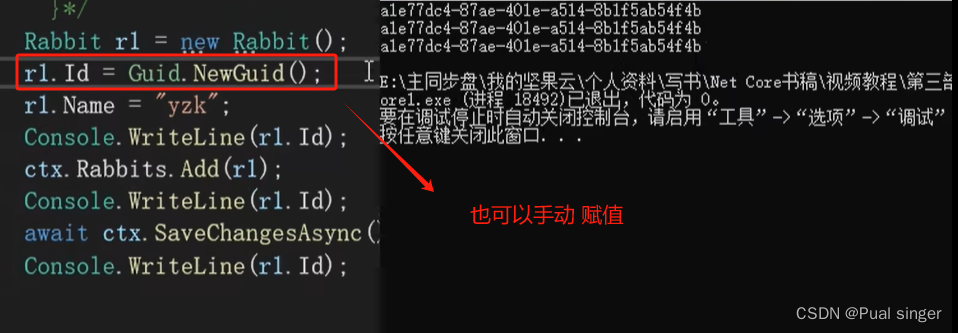
其他方案
1、混合自增和Guid(非复合主键) 。用自增列做物理的主键,而用Guid列做逻辑上的主键。把自增列设置为表的主键,而在业务上查询数据时候把Guid当主键用。在和其他表关联以及和外部系统通讯的时候(比如前端显示数据的标识的时候)都是使用Guid列。不仅保证了性能,而且利用了Guid的优点,而且减轻了主键自增性导致主键值可被预测带来的安全性问题(别人通过某一个数据,能预测到后面的数据。爬取你的数据)。
2、Hi/Lo算法:EF Core支持Hi/Lo算法来优化自增列。主键值由两部分组成:高位 (Hi) 和低位 (Lo),高位由数据库生成,两个高位之间间隔若千个值,由程序在本地生成低位,低位的值在本地自增生成。不同进程或者集群中不同服务器获取的Hi值不会重复,而本地进程计算的Lo则可以保证可以在本地高效率的生成主键值。但是HiLo算法不是EF Core的标准
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- tomcat控制台乱码问题
- Yestar成都艺星七色瓶3.0新品发布会圆满举办!助力全球星粉焕肤综合年轻态
- 13. C++ linux命令,查看端口占用,cpu负载,内存占用,如何发送信号给一个进程
- gin实现登录逻辑,包含cookie,session
- 二维码智慧门牌管理系统升级:解决通知通报难题
- Linux第三章(包/源管理)
- 小于190kb尺寸怎么调整?一键压缩变小!
- 3个以内正常显示超出3个
- 解决全彩LED显示屏像素失控的问题
- C语言分支语句