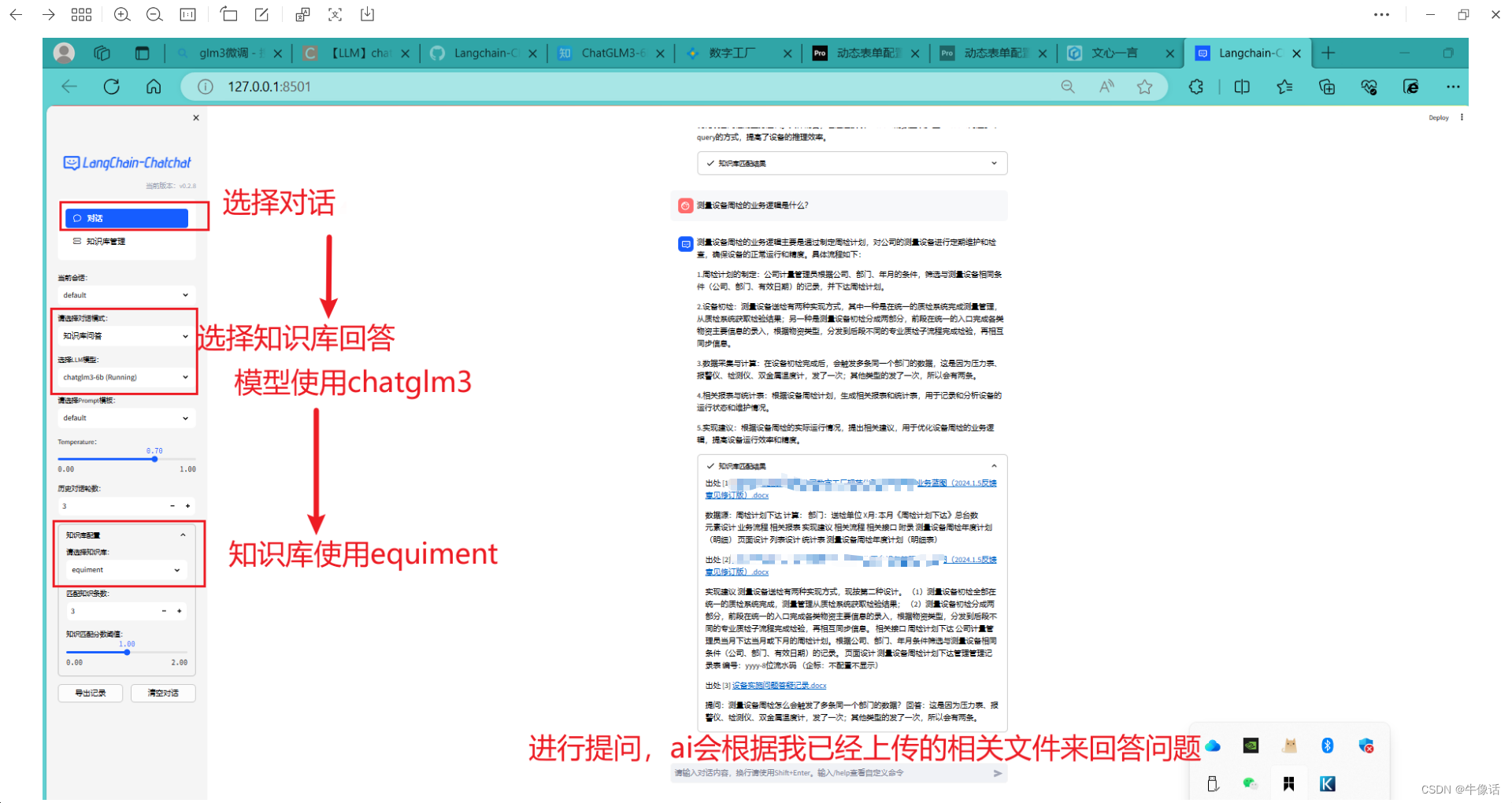
LangChain+glm3原理解析及本地知识库部署搭建
前期准备:在部署LangChain之前,需要先下载chatglm3模型,如何下载可以查看我的上一篇文章chatglm3本地部署
本地知识库和微调的区别:
- 知识库是使用向量数据库存储数据,可以外挂,作为LLM的行业信息提供方。
- 简单理解,微调相当于让大模型去学习了新的一门学科,在回答的时候完成闭卷考试。知识库相当于为大模型提供了新学科的课本,回答的时候为开卷考试。
LangChain+glm3实现本地知识库原理:
首先给出git地址,git上其实也有他是原理也可以去git上看langchain-chatchat
原理如下图:
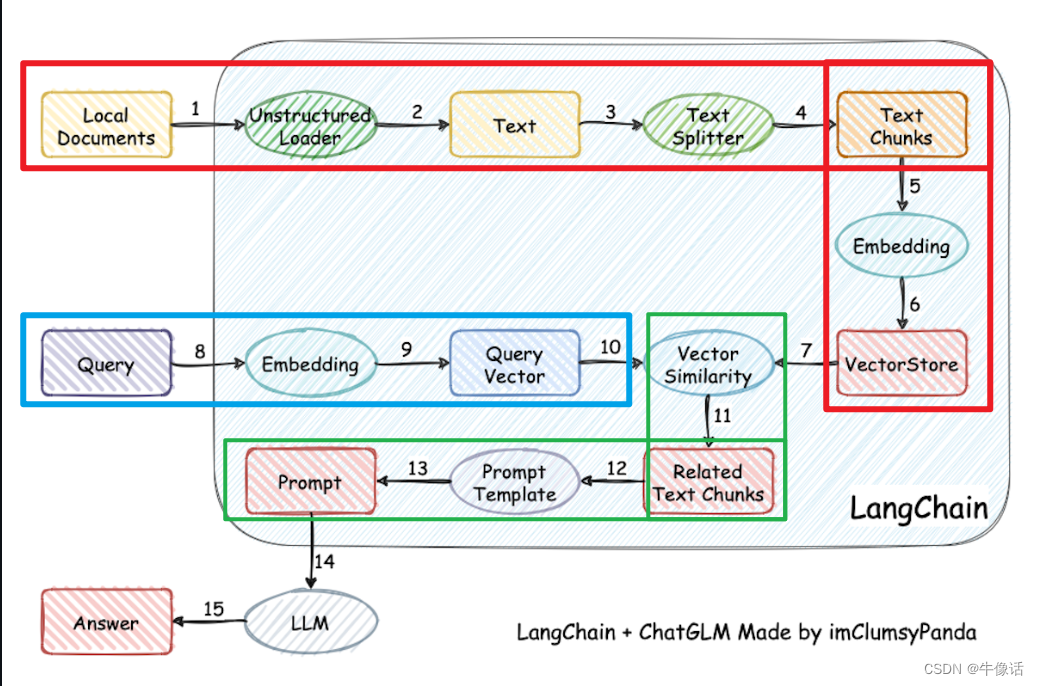
红框: 红框内是经历了这样一个过程,首先上传本地文档,然后把文档的内容进行分割,其中文档的分割方法有很多,比如可以按照符号分割,按照段落分割,或者按照语气词分割,接下来把分割后的内容,进行Embedding操作生成词向量,如果不清楚Embedding是什么的,可以参考我的这篇文章Embedding And Word2vec,最后把生成的词向量存入VectorStore,也就是词向量数据库。
蓝框: query是用户输入的信息,然后把用户输入的信息也做Embedding操作,然后得到词向量。
绿框: 利用向量相关性算法(例如余弦算法),计算用户输入后的词向量和向量数据库中最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 promt 提交给 LLM 回答。
本地部署:
1.拉取代码
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
2.创建一个conda环境,python环境我这里使用的是3.10.13,官方推荐的是 3.8 - 3.11,如果不知道如何创建的,在文章开头中的那篇文章里有。
3.激活刚刚创建的环境,然后下载torch,下载方法在文章开头中的那篇文章里有。
4.安装依赖,在安装依赖之前,需要把下面requirements.txt和requirements_api.txt文件中,有关torch的所有安装内容都删掉。因为如果直接执行下面的命令,下载的torch是cpu版本,从而导致后面无法启动langchain,这就是为什么我们要先装torch。
$ pip install -r requirements.txt
$ pip install -r requirements_api.txt
$ pip install -r requirements_webui.txt
5.把下载好的模型复制到langchain下
6.初始化知识库和配置文件
$ python copy_config_example.py
$ python init_database.py --recreate-vs
7.启动
$ python startup.py -a
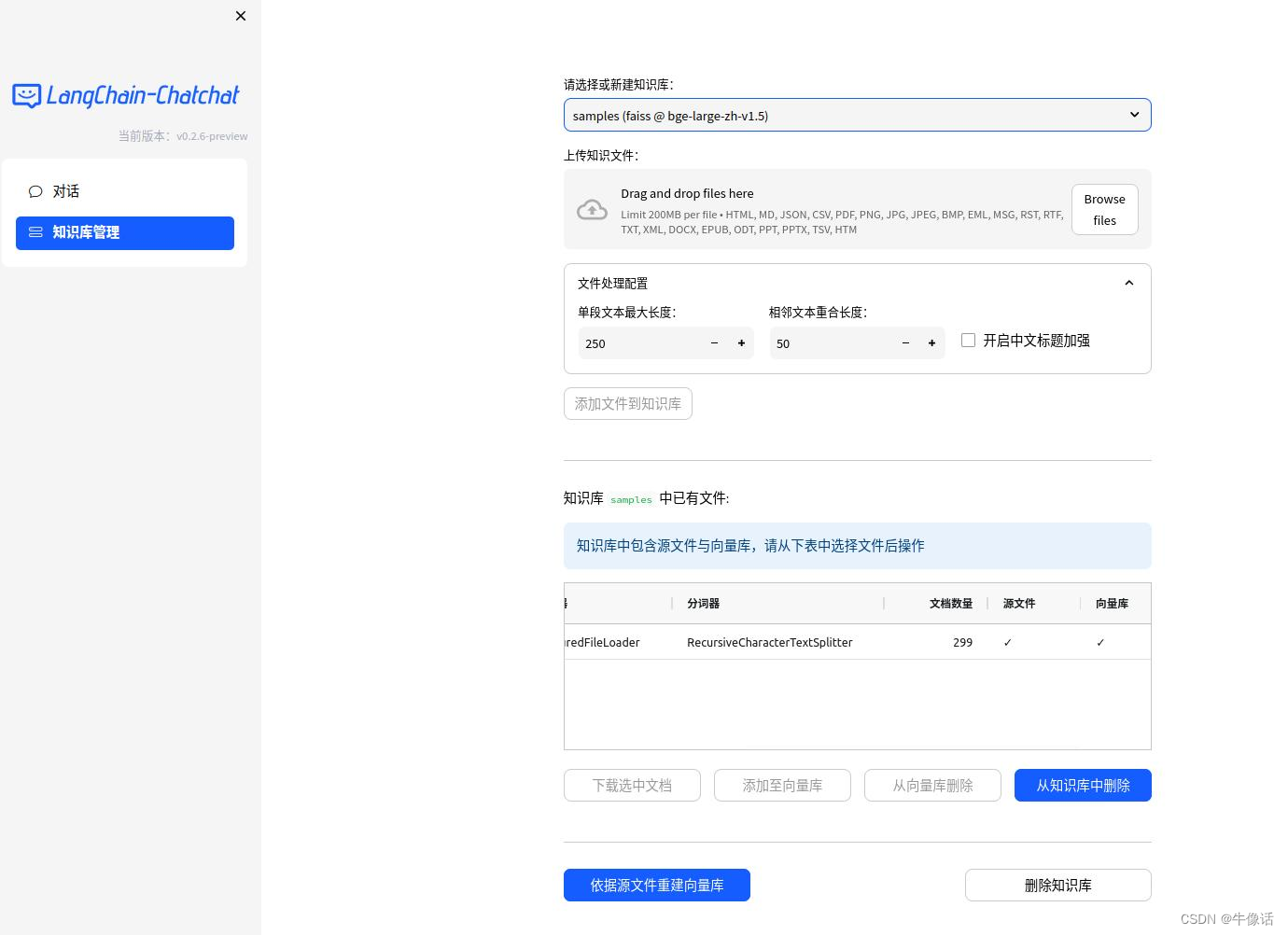
8.创建知识库
9.使用
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 机器学习计算题——朴素贝叶斯
- Go 企业开发知识链
- 2023.12.30 关于 Redis 数据类型 Set 常用命令、内部编码、应用场景
- 深入解析ESP32C3(1) - 使用ESP-IDF
- 代码随想录算法训练营第三十九天 | 62.不同路径、62.不同路径 II
- leetcode
- PowerShell Instal 一键部署TeamCity
- Spring Security 6.x 系列【72】授权篇之角色分层
- 如果我想用python自动操作手机、电脑软件,应该学python哪方面的知识呢?
- Linux学习之系统编程7(线程同步/互斥锁/信号量/条件变量)