爬虫之牛刀小试(六):爬取BOSS网站招聘的内容
发布时间:2024年01月14日
今天决定再次尝试一下
selenium
BOSS网站
想要找到我们感兴趣的职位,随便举个例子吧,比如家教啥的
搜一下
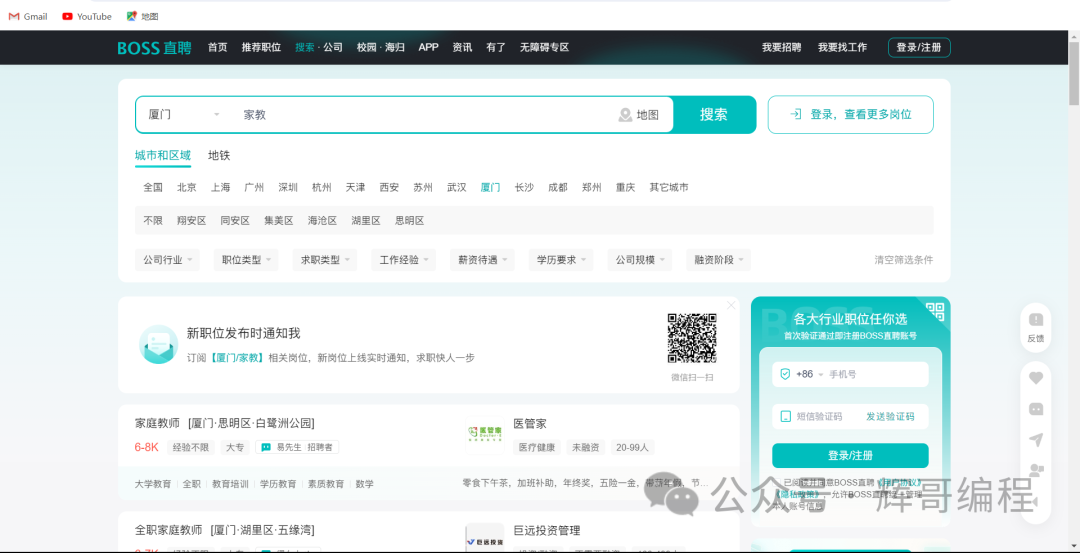
找到我们感兴趣的内容
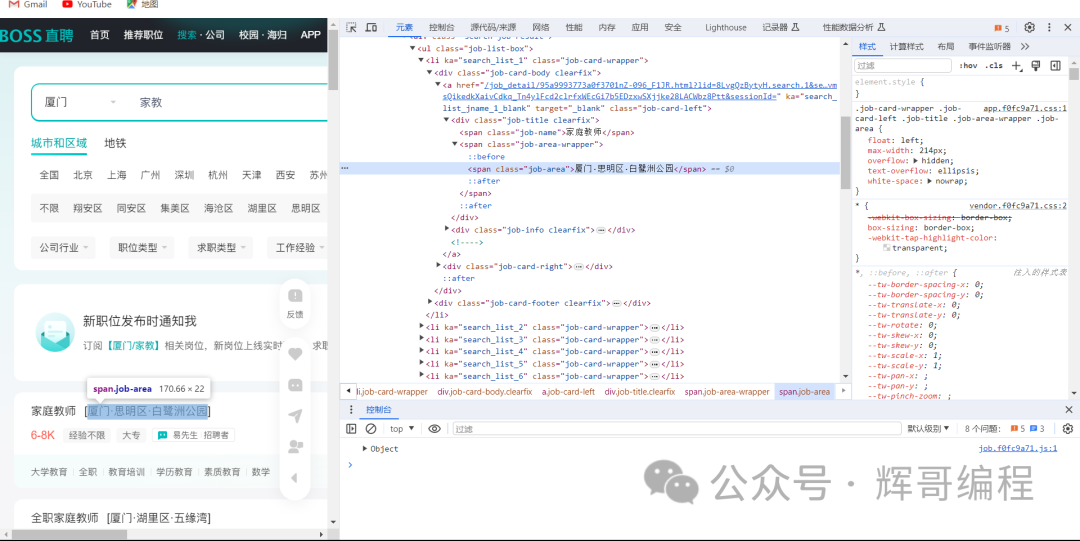
接着尝试用selenium模拟登录,如下所示:

接着找到对应的位置让selenium自己干就行了。
最后的代码如下:
from selenium.webdriver.common.keys import Keys
import re
from selenium import webdriver
from mitmproxy import proxy, options
from mitmproxy.tools.dump import DumpMaster
from selenium.common.exceptions import NoSuchElementException
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import json
import csv
def data_change_dict(text):
data = {"职位名称": "", "地点": "", "学历": "", "届别": "", "薪资": "", "招聘者": "", "公司名称": "", "公司类型": "", "公司规模": "", "福利": ""}
# 按换行符分割文本
parts = text.split('\n')
if len(parts) < 10:
parts.insert(9, "")
# 将分割后的部分分别赋值给字典的键
data["职位名称"] = parts[0]
data["地点"] = parts[1]
data["薪资"] = parts[2]
data["届别"] = parts[3]
data["学历"] = parts[4]
data["招聘者"] = parts[5]
data["公司名称"] = parts[6]
data["公司类型"] = parts[8]
data["公司规模"] = parts[7]
data["福利"] = parts[9]
return data
def get_url(driver):
# 找到输入框
input_element = driver.find_element(By.XPATH, '//*[@id="wrap"]/div[3]/div/div[1]/div[1]/form/div[2]/p/input')
# 在输入框中输入 "家教" 并按下回车键
input_element.send_keys("家教", Keys.RETURN)
time.sleep(8)
k=2
o=10
datas = []
print("正在爬取第1页")
s=['//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[2]/div/div/div/a[3]',
'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[4]',
'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[5]',
'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[6]',
'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[7]',
'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[7]',
'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[7]',
'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[8]',
'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[9]']
for j in range(1,10):
if j>1:
k=1
for i in range(1,31):
element = driver.find_element(By.XPATH, '//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div['+str(k)+']/ul/li['+str(i)+']')
time.sleep(1)
data_dict=data_change_dict(element.text)
datas.append(data_dict)
button = driver.find_element(By.XPATH, s[j-1])
# 点击按钮
button.click()
# 等待 8秒
time.sleep(8)
print('爬取第'+str(j)+'页成功')
print("正在爬取第"+str(j+1)+"页")
print('爬取第'+str(10)+'页成功')
save_data(datas)
def save_data(datas):
# 将数据写入到文件中
with open('boss.csv', 'w', encoding='utf-8') as f:
# 创建一个 DictWriter 对象
writer = csv.DictWriter(f, fieldnames=datas[0].keys())
# 写入表头
writer.writeheader()
# 写入数据
writer.writerows(datas)
def delu():
boss_url = 'https://www.zhipin.com/xiamen/'
option = webdriver.ChromeOptions()
option.add_argument('--ignore-certificate-errors')
# 使用 selenium.webdriver 创建 driver 对象
driver = webdriver.Chrome(options=option)
driver.get(boss_url)
time.sleep(2)
button1 = driver.find_element(By.XPATH, '/html/body')
button1.click()
time.sleep(2)
window_handles = driver.window_handles
# 切换到新打开的窗口
driver.switch_to.window(window_handles[-1])
button2 = driver.find_element(By.XPATH, '//*[@id="wrap"]/div[1]/header/div/div[2]/div')
button2.click()
time.sleep(5)
# 关闭新打开的窗口
driver.close()
# 切换回原来的窗口
driver.switch_to.window(window_handles[0])
driver.get(driver.current_url)
time.sleep(12)
print("登陆成功")
return driver
if __name__ == '__main__':
driver = delu()
get_url(driver)
运行效果:
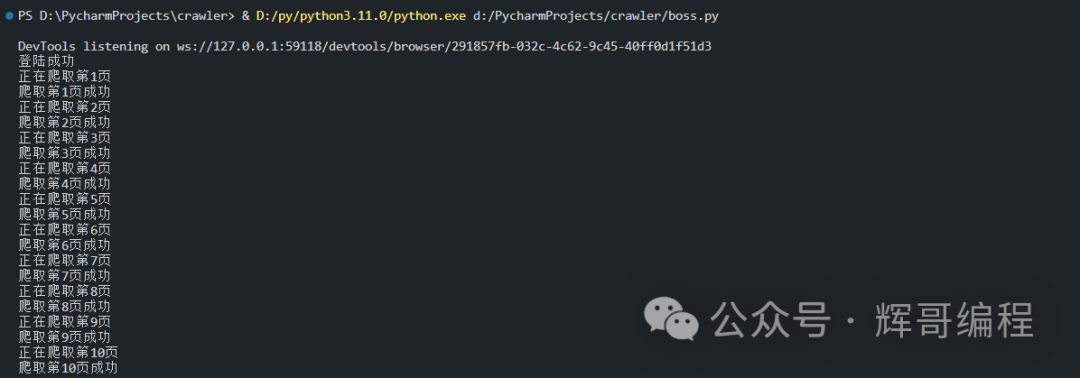
结果:

最近新开了公众号,请大家关注一下。

文章来源:https://blog.csdn.net/m0_68926749/article/details/135586183
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!