Mobile Aloha 【软硬件原理+代码解析】
Mobile ALOHA: 利用低成本全身远程操作系统学习复杂的双手移动操作技能 [译]
-
硬件代码:https://github.com/MarkFzp/mobile-aloha
-
软件代码:https://github.com/MarkFzp/act-plus-plus
-
项目地址:https://mobile-aloha.github.io/
一句话:Static ALOHA 到 Mobile ALOHA 是从 table-top manipulation 到 mobile manipulation 的进展。
作者团队开发了一个双臂+轮式底盘的遥操作系统,可以通过全身控制来对比如像:开柜门,乘电梯等移动操作任务进行示教数据采集。
硬件上,和前作ALOHA一样的,作者使用低成本的设备来搭建这套平台,最终预算控制在32k美金,与一台Franka Panda的价格相近。
算法上,在使用该平台采集到的示教数据进行模仿学习的过程中,作者发现,使用前作Static ALOHA中收集到的示教数据(没有移动地盘)进行联合训练,能够使机器人在移动操作任务上有更好的表现。缺点在于Mobile ALOHA没有引入 LLM Agent 的zero shot能力,缺乏多模态大模型MLM对视频、语言等多种模态的理解预测的泛化能力。但作为具身智能的GPT1.0时刻,足以启发后人。
对于每个任务,只需用新平台采集50条示教数据,结合之前的数据联合训练后,任务成功率最高能被提升到原来的90%。
Static ALOHA实验环境:

Mobile ALOHA实验环境:

1. Mobile ALOHA Hardware
硬件设计时,研究人员主要从四个维度切入考虑:
-
移动速度要快:与人类的行走速度相媲美,约为 1.42 米/秒。
-
稳定性:在拿起沉重的家居物品时,如锅、吸尘器时,它是稳定的。
-
支持全身远程控制:所有的自由度可以同时远程操作,包括双臂和移动底座。
-
不受限制:板载电源和计算。

要想实现 Mobile ALOHA 的灵活性,研究员在它的下方安装了一个专为仓库设计的轮子底座——Tracer AGV,它可以承载 100kg,移动速度高达 1.6m/s,而成本只有 7000 美元。
为了使 Mobile ALOHA 不受能源限制,研究人员配备了一个 1.26 千瓦时的电池,重量在 14 公斤,这样还可以压住机器人,防止不平衡摔倒。
此外,整个装置还包括网络摄像头和一个搭载消费级 GPU 的笔记本电脑,成本共计约为 3.2 万美元,比现成的双臂机器人便宜得多。
研究员在论文中介绍道,Mobile ALOHA 可同时遥控所有自由度。人类操作员的腰部被用物理的方式拴在系统上,并反向驱动车轮,在工作环境中驾驶系统,同时用控制器控制机器人手臂。同时,研究人员记录基本速度数据和手臂操纵数据,形成一个全身远程控制操作系统。
这样,机器人控制系统就能同时学习动作和其他控制指令。一旦收集到足够的信息,模型就能自主地重复一系列任务。
品牌型号上:(总共 3w刀,RMB约20w)
- 轮式底盘:
AgileX Tracer(松灵)价格:$9000 x 1个 - 主动臂:
WidowX 250,6自由度 价格:$3295 × 2个 - 从动臂:
ViperX 300,6自由度 价格:$5695 × 2个 - 计算机:
i7-12800H + 3070Ti (8GB) - 相机:
Logitech C922x RGBx 3个,分辨率480×640,频率50Hz,两个在从端机械臂的腕部,一个朝向前方。
2. Imitation Learning
在 模仿学习(Imitation Learning) 方面,Mobile ALOHA 利用了 Transformer(大型语言模型中使用的架构)。最初的 Satic ALOHA 系统使用了一种名为 Action Chunking with Transformers (ACT) 的架构,它将来自多个视点和关节位置的图像作为输入并预测一系列动作。
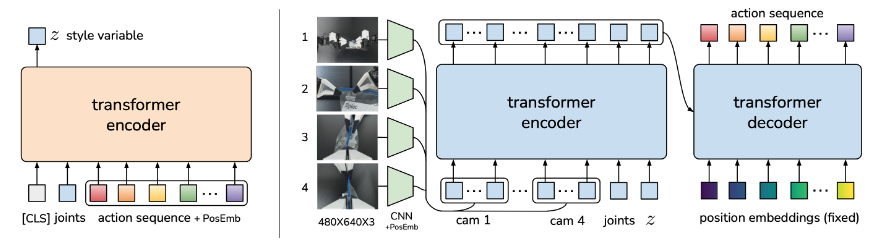
Mobile ALOHA 将底座运动信号添加到输入向量中,从而扩展了该框架。这种方法可以让 Mobile ALOHA 重复使用以前的深度模仿学习算法,而只需做最小的改动。
在论文中,研究人员写道:“我们观察到,简单地将底座和手臂动作连接起来,然后通过直接模仿学习进行训练,就可以产生出色的表现。具体来说,我们将 ALOHA 的 14-DoF 关节位置与移动底座的线速度和角速度 的 tokens concat 连接起来,形成 16 维动作向量。”
3. Co-training with Static ALOHA Data
数据层面,也使用前作ALOHA(Static ALOHA)中的静态数据,结合Mobile ALOHA的数据进行联合训练,作者采集的825条不包含轮式底盘运动的示教数据,任务种类包括放电池、开盖子等等。
数据采集过程:需要人来操控机器完成一系列动作,在运动的过程中,机器会记录各个关键的运动轨迹,作为训练数据。训练完之后就不需要人来操控了。
值得注意的是:Static ALOHA数据全部在一个黑色的桌面上采集,与Mobile ALOHA的数据采集场景很不一样,并且机械臂的布置方式也差别较大(朝中间和朝前方),但是作者并没有对图像数据做额外的处理,只是忽略掉了静态数据中放置在工作台前方的相机,保证都是3个视角的图像输入。另外对于静态数据,base相关的数据做zero-padding。
-
对于所有任务,共用的
static ALOHA数据为 D s t a t i c D_{static} Dstatic? -
对于一个任务 m ,其对应的
mobile ALOHA示教数据为 D m o b i l e m D^m_{mobile} Dmobilem?
联合训练中,对mobile和static数据样本的占比相同(注:对每一个动作维度,基于mobile ALOHA的数据分别做归一化处理):
-
输入(观测值):3视角图像(
480×640 image x 3) + 14维的从臂关节位置(6DOF × 2+1 Gripper × 2) -
输出(动作):14维的双臂关节位置 + 2维的底盘线速度和角速度
-
训练目标:标准的模仿学习loss。其中 o i o^i oi是两个手腕相机的RGB观测数据, a a r m s i a^i_{arms} aarmsi?是双臂关节位置, a b a s e i a^i_{base} abasei?是底盘线速度和角速度, π m \pi^m πm是task m 的控制策略, L L L是模仿损失函数。
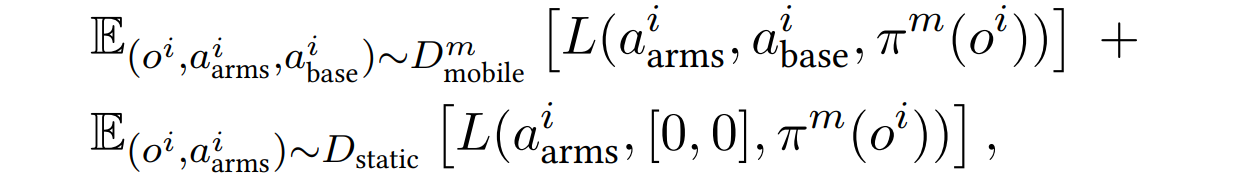
研究人员表示:“通过协同训练,我们只需对每项任务进行 50 次人类演示,就能在这些任务上取得超过 80% 的成功,与没有协同训练相比,平均绝对提高了 34%。”
4. Task Setting
作者一共测试了7个任务,包含灵巧操作、全身运动、涉及到金属、重物等较难的被操作对象,以及需要避障的与环境和人的交互任务。
具体设置如下:
Wipe Wine、Cook Shrimp、Wash Pan:

Use Cabinet、Take Elevator、Push Chairs:

High Five:

作者额外指出,对于所有的任务,如果在示教后,将环境恢复,单纯地直接重复执行示教轨迹(开环),任务全部无法完成,成功率为0。
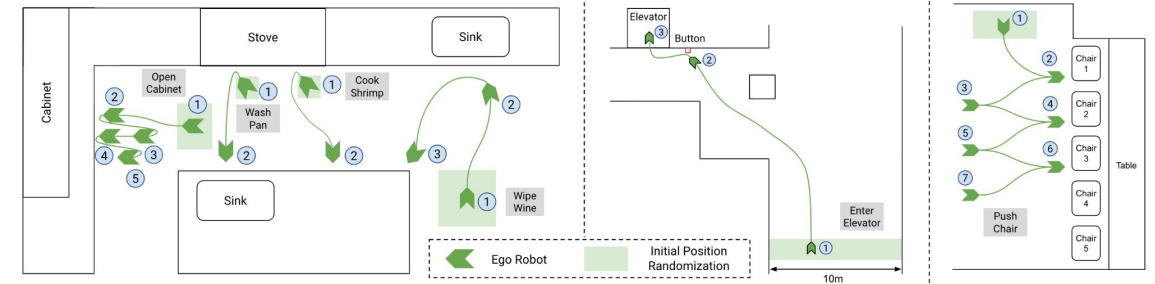
想要成功完成任务,需要机器人策略对环境和机器人状态做出动态的、闭环的响应。
经过实验分析,作者认为开环过程的误差主要来自移动底盘的速度控制误差,下图展示了实验中,轮式底盘进行一个半径为1m的180度旋转,在轮式底盘完成运动后,机械臂末端会在纸上点出红色的位置点(右上角的红叉×为真值ground truth),下图中展示了20次重复实验的结果,误差在10-20cm左右。

5. Experiments
实验中,将Co-training的方法与多种模仿学习的方法结合起来训练:ACT、Diffusion Policy、VINN三种方法。
5.1 ACT
首先对于ACT(算法的具体设计细节,可参考前作,此处不再赘述),联合训练显著的提高了任务成功率,6个在80%以上,尤其是对于需要精细操作的任务,比如按按钮、开水龙头等。
Cook Shrimp任务的成功率较低,作者认为原因在于这是一个长达75秒的任务,并且只采集了20条示教数据。
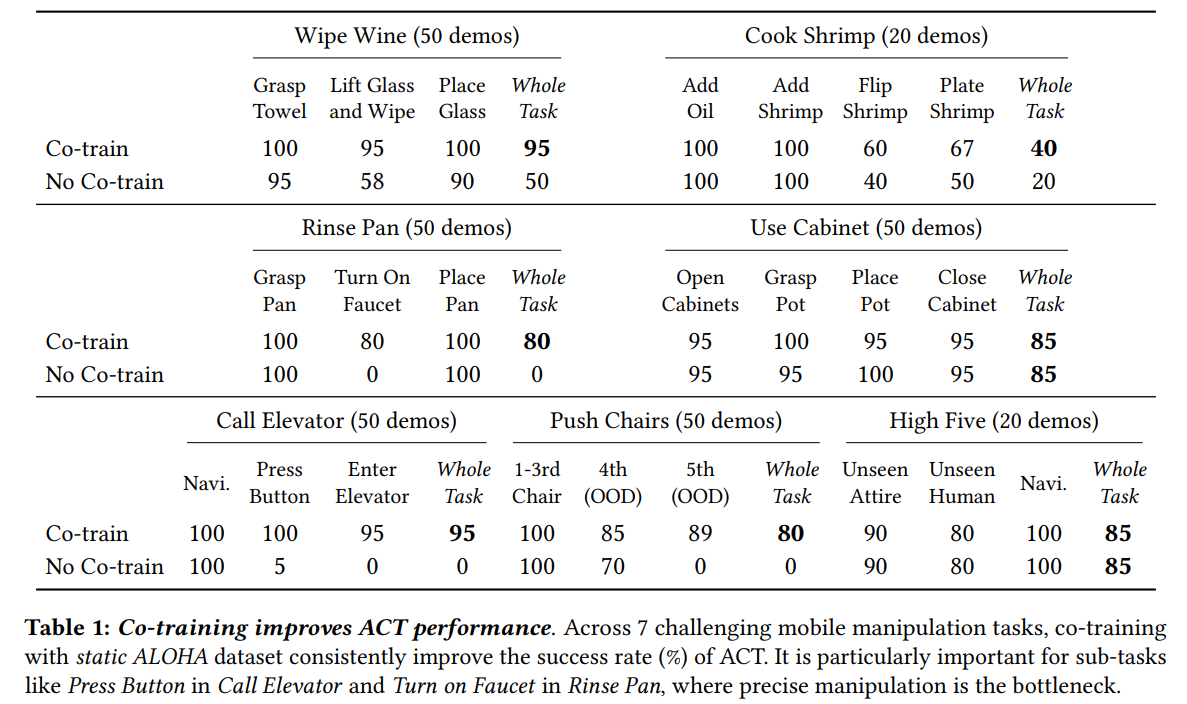
为什么联合训练的效果会更好?
作者认为,static ALOHA数据中关于抓取和接近物体的运动先验知识对训练mobile ALOHA的模型有很大帮助,尤其是其中腕部视角是具有不变性的,对场景的变换有较强的抗干扰能力。
另外,联合训练的策略在推椅子和擦红酒这两个任务上也表现出了更强的泛化能力。
对于推椅子任务,在前三个训练集的椅子上,单独训练和联合训练的表现都不错,但对于第四、五个训练集中未出现的椅子,联合训练的模型表现分别有15%和89%的提升。
对于擦红酒任务,联合训练能够适应酒杯更大的随机范围。
因此,作者认为,在仅有少量示教数据又要使用表达能力较强的transformer-based model的前提下,联合训练能够帮助避免过拟合的出现。
在所有的测试中,compounding error看起来是最主要的造成任务失败原因,作者认为这最初可能来自于底盘的控制误差和一些和环境物体有强接触的动作。
5.2 对比ACT、Diffusion Policy和VINN
对于擦红酒和推椅子这两个任务,作者额外使用了diffusion policy和VINN+action chunking算法进行了训练,联合训练的方式与ACT保持一致。
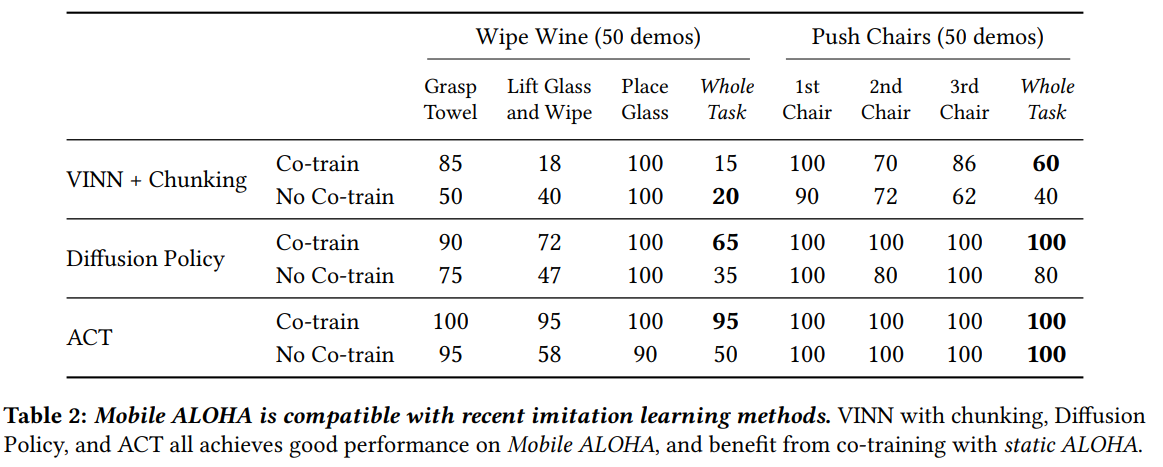
总的来看,ACT的表现最优,diffusion policy略差,VINN最差。对于这三种算法,联合训练的表现基本上都优于单独训练。
对于VINN+擦红酒任务,联合训练的表现比起单独训练反而变差了,作者认为,这是由于VINN算法本身没有办法利用测试(应用)场景分布之外的数据(具体原因可以看VINN原文,一种在测试时寻找训练集中nearest neighbour的方法),static ALOHA的数据对于VINN来讲就可能没那么有效。
对于diffusion policy来说,它的模型表达能力比较强,作者认为,50条的示教数据量可能不够。
6. Software Code Analyze
https://github.com/MarkFzp/act-plus-plus
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AbstractHttpMessageConverter + easyexcell优雅下载附件
- 云原生Kubernetes:K8S集群实现容器运行时迁移(docker → containerd) 与 版本升级(v1.23.14 → v1.24.1)
- 计算 日期增加小时转时间戳
- APT渗透和防守思路
- 一个很好用且开源的java验证码框架kaptcha
- javascript设计模式-组合
- 如何学习英语
- 最新情侣飞行棋源码完全解析+搭建教程:让爱情在游戏中升温!
- 计算机网络 网络层上 | IP数据报,IP地址,ICMP,ARP等
- Idea Community社区版如何添加Run Dashboard