走进Docker的世界
前言
介绍docker的前世今生,了解docker的实现原理,带大家如何编写最佳的Dockerfile构建镜像。通过本章的学习,大家会知道docker的概念及基本操作,并学会构建自己的业务镜像,并通过抓包的方式掌握Docker最常用的bridge网络模式的通信
一、Docker相关概述
1、什么是docker?
docker是一个基于操作系统内核,提供轻量级虚拟化功能的C/S架构的软件产品。基于轻量的特性,解决软件交付过程中的环境依赖。
是一个开放源代码的容器化平台,可快速、高效、可移植地构建、打包、部署和运行应用程序,容器就是在隔离的环境运行的一个进程,如果进程停止,容器就会销毁。隔离的环境拥有自己的系统文件,ip地址,主机名等。
2、为什么出现docker?
首先看一组图片对比
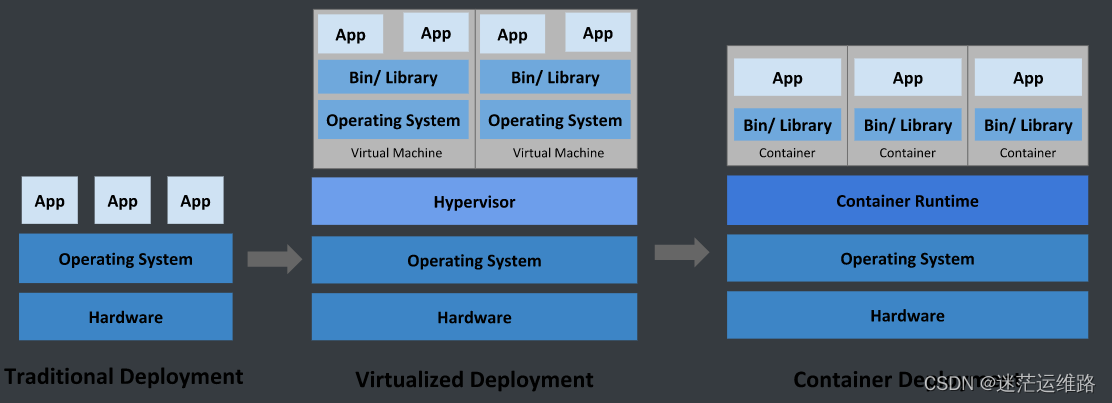
随着技术的更新迭代以及公司业务架构的变换,需要一种轻量、高效的虚拟化能力。因此由之前的传统业务部署方式-->虚拟化技术部署方式-->容器化部署方式的变化,
每种部署方法都标志的一个技术时代的迭代.当下主流的就是容器化部署方式。那么这三种方式有什么优缺点呢?
Hypervisor: 一种运行在基础物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享硬件 。常见的VMware的 Workstation 、ESXi、微软的Hyper-V或者思杰的XenServer。
Container Runtime: 通过Linux内核虚拟化能力管理多个容器,多个容器共享一套操作系统内核。因此摘掉了内核占用的空间及运行所需要的耗时,使得容器极其轻量与快速。
2.1 容器与kvm虚拟化的对比
| 启动 | 秒级(docker) | 分钟级(kvm) |
|---|---|---|
| 硬盘使用 | 一般为 MB | 一般为 GB |
| 性能 | 接近原生 | 弱于 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
| 特性 | 容器 | 虚拟机 |
2.2 docker的作用
- 可以把应用程序代码及运行依赖环境打包成镜像,作为交付介质,在各环境部署
- 可以将镜像(image)启动成为容器(container),并且提供多容器的生命周期进行管理(启、停、删)
- container容器之间相互隔离,且每个容器可以设置资源限额
- 提供轻量级虚拟化功能,容器就是在宿主机中的一个个的虚拟的空间,彼此相互隔离,完全独立
二、安装docker及配置文件调整
1.配置宿主机网卡转发
为什么要配置网卡转发后续会在docker网络章节中具体详解
配置如下(示例):
cat <<EOF > /etc/sysctl.d/docker.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward=1
EOF
然后在执行 sysctl -p /etc/sysctl.d/docker.conf 进行内核参数加载
2.yum安装docker
在线安装(示例):
1、如果服务器已经配置好了yum源,则直接执行
yum list docker-ce --showduplicates | sort -r 查看源中可用版本
yum -y install xxxx #安装 xxx是 查看后源中可用版本名称,复制替换xxx即可
2、查看是否安装成功,返回版本信息则安装成功
docker version
离线安装(示例):
1、如果服务器不通外网,则使用我已经下载好的安装包即可,执行install.sh 脚本安装即可,只针对x86_64操作系统
下载地址 https://download.csdn.net/download/weixin_50902636/88713671
2、查看是否安装成功,返回版本信息则安装成功
docker version
3.修改daemon.json文件
vim /etc/docker/daemon.json
{
"log-driver":"json-file",
"log-opts": {"max-size":"200m", "max-file":"3"},
"exec-opts": ["native.cgroupdriver=systemd"],
"insecure-registries": [
"https://harbor.test.local"
}
配置文件含义解释:
log-driver:指定容器日志的驱动程序。在这个例子中,json-file表示将日志输出到JSON格式的文件中。
log-opts:给出了进一步的日志选项。max-size指定了每个日志文件的最大大小(在这里是200MB),max-file指定了要保留的最大日志文件数(在这里是3个)。
exec-opts:指定Docker守护进程的执行选项。在这个例子中,native.cgroupdriver=systemd表示使用systemd作为Cgroups驱动程序。
insecure-registries:列出了Docker守护进程信任的不安全的注册表地址。在这个例子中,Docker将信任https://harbor.test.local,即允许从这个地址拉取和推送镜像,即使这个地址没有经过认证或加密。
敲黑板: 看重点
面试知识点:
`之前面试时,被面试官问道,你们的docker日志是怎么清理的,以上的日志配置就是回答项,别再说找到对应的容器ID进行echo '' > xxx-json.log了,假如容器过多,难不成手动一个个清理~~`
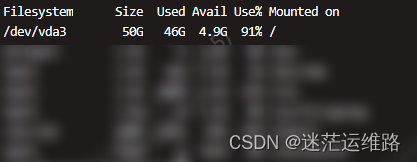
4.修改docker镜像和容器的默认存储路径
这里就会有人问道,为什么要修改这个,请看下面的VCR,随着时间增长,docker的默认存储路径/var/lib/docker/会逐渐将/目录打满,
众所周知,生产环境的/根目录本身就没有多少磁盘量,像我的环境中一般是50GB左右,长此以往会占满根目录,为了杜绝后患,在安装时我们就将该隐患给排除掉,
具体操作,请看以下大屏幕
vim /usr/lib/systemd/system/docker.service 找到以下文件
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
修改为这个 --graph 指定了新的Docker镜像和容器的存储路径
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --graph /export/docker
5.启动docker
systemctl daemon-reload
systemctl start docker
systemctl enable docker
三、Docker的核心要素
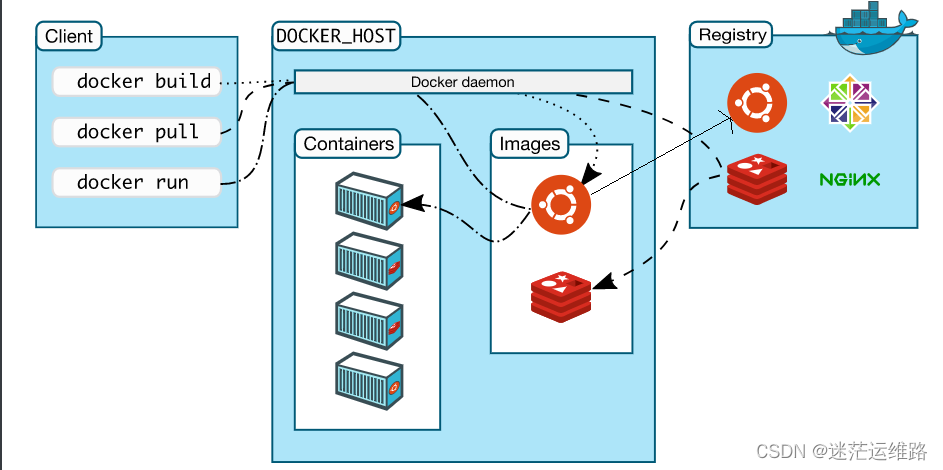
docker有三大核心要素:
镜像(image): 打包了业务代码及运行环境的包,是静态的文件,不能直接对外提供服务。
容器(container): 镜像的运行时,可以对外提供服务。
仓库(registry): 存放镜像的地方
共有仓库: Docker hub 、阿里 ...
私有仓库: harbor 自行搭建
四、Docker实现原理
首先,要清楚docker的优点在于: 轻量级的虚拟化、容器的快速启停,那么虚拟化核心需要解决的问题就是资源隔离和资源限制
虚拟化硬件技术: 它是通过一个hypervisor层实现对资源的彻底隔离
容器: 则是操作系统级别的虚拟化,利用的是linux内核的Cgroup和Namespace特性来实现隔离
通俗将就是docker会在启动一个容器时,调用linux内核的Namespace接口,创建一个虚拟空间,创建的时间支持设置以下几种:
| 名称 | 作用 |
|---|---|
| pid namespace | 用于进程隔离 |
| net namespace | 管理网络接口隔离 |
| ipc namespace | 管理对IPC资源的访问隔离 |
| mnt namespace | 管理文件系统挂载点隔离 |
| uts namespace | 隔离主机名、域名 |
| user namespace | 隔离用户、用户组 |
但是,通过上述的namespace接口只能保证容器之间的隔离,但是没法控制每个容器占用多少资源,如果某个容器正在执行CPU密集型的任务,那么就会影响到其他容器中任务的性能与执行效率,导致多个容器相互影响并抢占资源,从而导致容器宕机.
综上所述,就会出现一个新问题,如何对容器的资源使用进行限制就成了解决进程虚拟资源隔离之后的主要问题
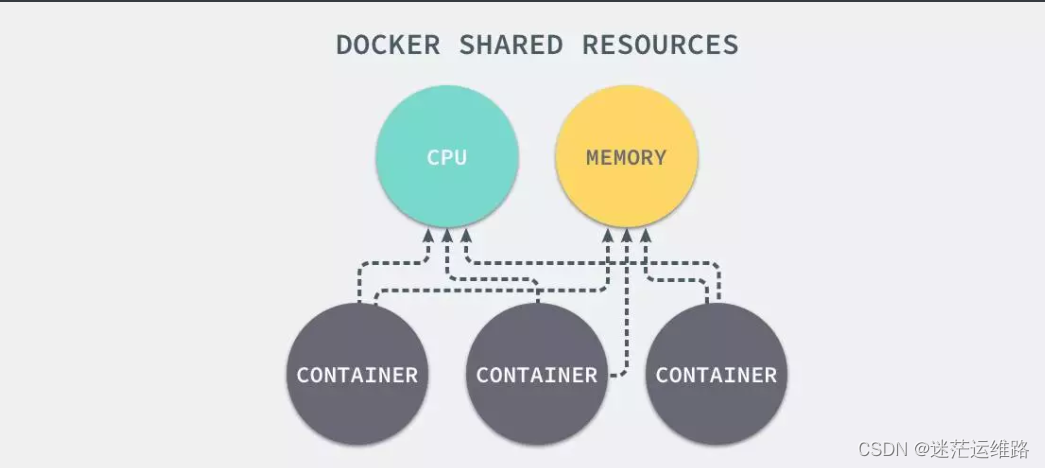
因此,从而引出linux内核的另一个机制Cgroups
4.1 什么是Cgroups?
cgroups是Control Groups的简称,是linux内核提供的一种机制,它可以根据需求把一系列任务及子任务整合到按资源划分等级的不同组中,从而为系统资源管理提供一个统一的框架。
Cgroups能够隔离宿主机上的物理资源,例如:CPU、MEM、disk.每个cgroup都是一组被相同的标准和参数限制的进程,而我们需要做的,其实就是把容器这个进程加入到指定的Cgroup中。
4.2 UnionFS联合文件系统
linux内核提供的Namespace和cgroup分别解决了容器的资源隔离和资源限制,那么容器是很轻量的,通常每台机器中可以运行几十上百个容器,
这些个容器是共用一个image,还是各自将这个image复制了一份,然后各自独立运行呢?
如果每个容器之间都是全量的文件系统拷贝,那么会导致至少如下问题:
- 运行容器的速度会变慢
- 容器和镜像对宿主机的磁盘空间的压力
如何解决上述的问题,则引入了联合文件系统以及镜像分层,如以下例子:
docker镜像是由一系列的层组成的,每层代表Dockerfile中的一条指令
FROM ubuntu:15.04
COPY . /app
RUN make /app
CMD python /app/app.py
这里的 Dockerfile 包含4条命令,其中每一行就创建了一层,下面显示了上述Dockerfile构建出来的镜像运行的容器层的结构:
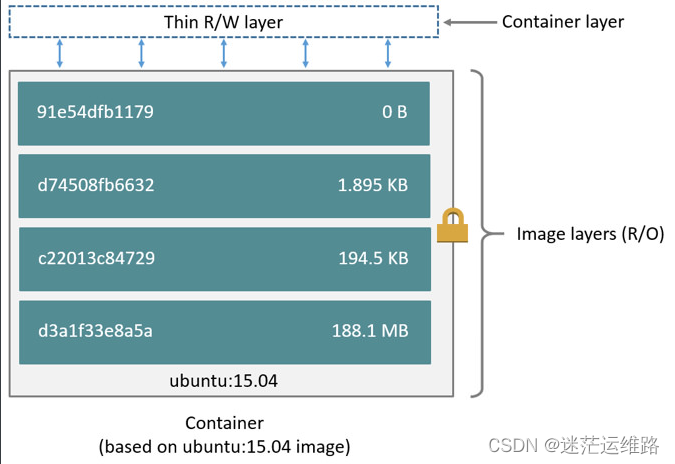
镜像就是由这些层一层一层堆叠起来的,镜像中的这些层都是只读的,当我们运行容器的时候,就可以在这些基础层至上添加新的可写层,
也就是我们通常说的`容器层`,对于运行中的容器所做的所有更改(比如写入新文件、修改现有文件、删除文件)都将写入这个容器层.
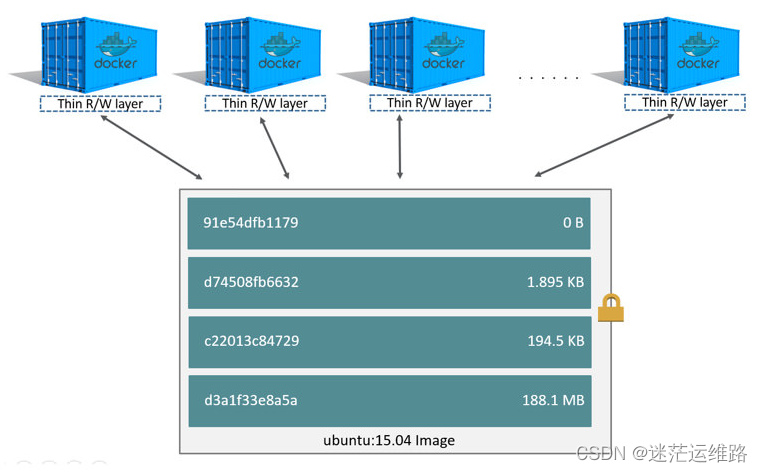
有了上述的描述,就能更好的回答了容器是共用一个image还是复制一份image单独使用的问题
对容器层的操作,主要利用了写时复制(CoW)技术。CoW就是copy-on-write,表示只在需要写时才去复制,这个是针对已有文件的修改场景。
CoW技术可以让所有的容器共享image的文件系统,所有数据都从image中读取,只有当要对文件进行写操作时,才从image里把要写的文件复制到自己的文件系统进行修改。
所以无论有多少个容器共享同一个image,所做的写操作都是对从image中复制到自己的文件系统中的复本上进行,并不会修改image的源文件,且多个容器操作同一个文件,会在每个容器的文件系统里生成一个复本,每个容器修改的都是自己的复本,相互隔离,相互不影响。使用CoW可以有效的提高磁盘的利用率。
4.3 镜像中每一层的文件都是分散在不同的目录中的,如何把这些不同目录的文件整合到一起呢?
UnionFS 其实是一种为 Linux 操作系统设计的用于把多个文件系统联合到同一个挂载点的文件系统服务。
它能够将不同文件夹中的层联合(Union)到了同一个文件夹中,整个联合的过程被称为联合挂载(Union Mount)。
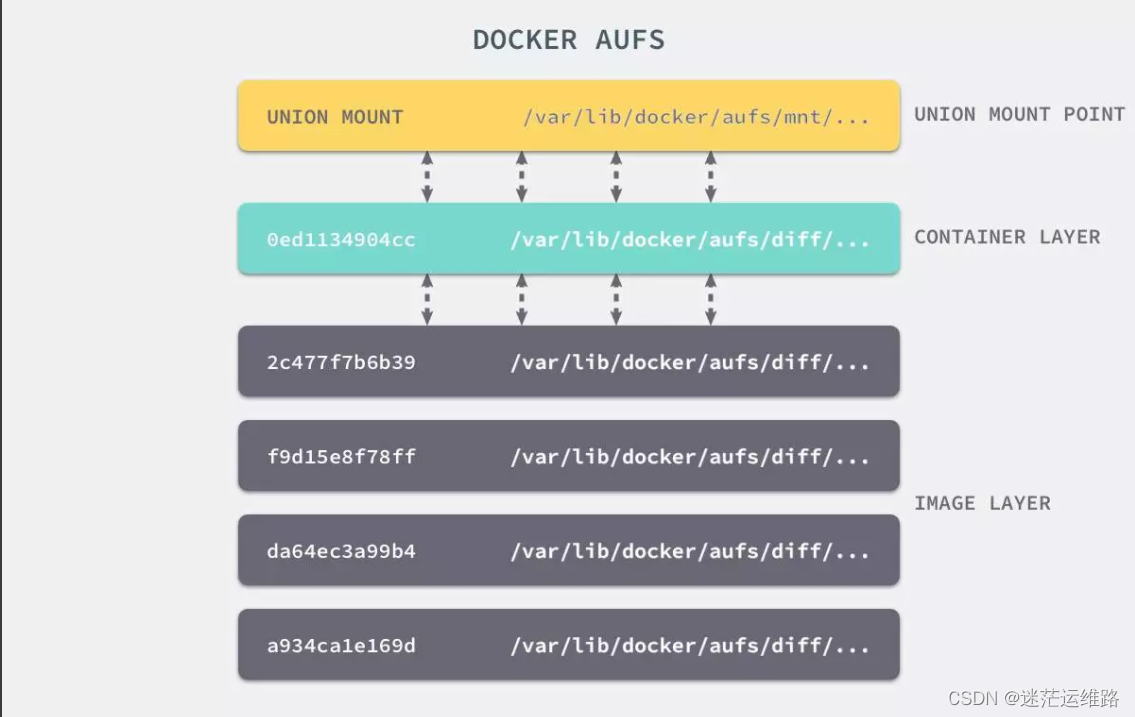
上图是AUFS的实现,AUFS是作为Docker存储驱动的一种实现,Docker 还支持了不同的存储驱动,包括 aufs、devicemapper、overlay2、zfs 和 Btrfs 等等,在最新的 Docker 中,overlay2 取代了 aufs 成为了推荐的存储驱动,但是在没有 overlay2 驱动的机器上仍然会使用 aufs 作为 Docker 的默认驱动。
五、Docker网络
docker容器是一块具有隔离性的虚拟系统,容器内可以有自己独立的网络空间
主要通过docker网络要实现以下功能:
- 多个容器之间是如何实现通信的呢?
- 容器和宿主机之间又是如何实现的通信呢?
- 使用-p参数是怎么实现的端口映射?
5.1 网络模式种类
在使用docker run创建Docker容器时,可以用--net选项指定容器的网络模式,Docker有以下4种网络模式:
- bridge模式,使用--net=bridge指定,默认设置
- host模式,使用--net=host指定,容器内部网络空间共享宿主机的空间,效果类似直接在宿主机上启动一个进程,端口信息和宿主机共用
- container模式,使用--net=container:NAME_or_ID指定 指定容器与特定容器共享网络命名空间
- none模式,使用--net=none指定网络模式为空,即仅保留网络命名空间,但是不做任何网络相关的配置(网卡、IP、路由等)
5.1.2 bridge模式
本文主要讲bridge即桥接模式,在创建容器时,如果没有指定网络模式,则默认就是桥接bridge模式,下面是桥接模式的一个示意图

在深入学习桥接模式时,首先要了解以下概念:
在linux中能够起到虚拟交换机作用的网络设备就是网桥,它是一个工作在数据链路层的设备,主要功能就是根据MAC 地址将数据包转发到网桥的不同端口上实现容器之间的联通。
5.1.3 如何查看网桥?
yum install -y bridge-utils #安装命令
[root@k8snode01 ~]# brctl show #查看网桥
bridge name bridge id STP enabled interfaces
cni0 8000.4ad53cf978fe no veth3c2abeae
veth617f2dd3
veth65d9457c
veth6b40ac8e
veth757e7d9b
veth7fa26f47
veth909d83df
veth9bc5d22f
vetha9f1b82b
vethb627deae
vethd3d9ebd5
vethf5e89e13
docker0 8000.0242456ef1e2 no
5.1.4 docker创建容器时会做哪些操作,才能实现容器间的联通?
- 创建一对虚拟接口/网卡,也就是veth pair;
- veth pair的一端桥接 到默认的 docker0 或指定网桥上,并具有一个唯一的名字,如 vethxxxxxx;
- veth paid的另一端放到新启动的容器内部,并修改名字作为 eth0,这个网卡/接口只在容器的命名空间可见;
- 从网桥可用地址段中(也就是与该bridge对应的network)获取一个空闲地址分配给容器的 eth0
- 配置容器的默认路由
补充:
veth pair: 成对出现的一种虚拟网络设备,数据从一端进,从另一端出。用于解决网络命名空间之间的隔离。(解决宿主机与容器之间的网络通信)
从5.1.4可以清楚的知道,整个过程是由docker自动帮助我们完成的,那么下面请看具体的通信过程
5.1.5 docker的容器间通信
1、登录测试服务器,执行以下命令
docker rm -f `docker ps -aq`
docker ps
brctl show # 查看网桥中的接口,目前没有
2、创建测试容器nginx-test1
docker run -d --name test1 nginx:alpine
brctl show # 查看网桥中的接口,已经把test1的veth端接入到网桥中
ip a |grep veth # 已在宿主机中可以查看到
docker exec -ti test1 sh
/ # ifconfig # 查看容器的eth0网卡及分配的容器ip
3、再创建测试容器nginx-test2
docker run -d --name test2 nginx:alpine
docker exec -ti test1 sh
/ # ifconfig # 查看容器的eth0网卡及分配的容器ip
4、进入nginx-test2容器,执行以下命令
docker exec -ti test1 sh
curl 172.17.0.2:80 #curl 容器1的IP地址
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
发现容器2能curl通容器1
容器2访问容器1流程分析:
1、进入容器2,执行route -n eth0是容器2里的默认路由设备
/ # route -n #检查路由
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
2、所有对172.17.0.0/16 网段的请求,都会被交给eth0来处理(即上面的第二条路由规则),网关是0.0.0.0,这意味着是一条直连路由规则
凡是匹配到这条规则的IP包,经过本机的eth0网卡,通过二层(数据链路层)直接发往目的主机
3、而要通过二层网络到达 test1 容器,就需要有 172.17.0.2 这个 IP 地址对应的 MAC 地址。所以test2容器的网络协议栈,就需要通过 eth0 网卡发送一个 ARP 广播,来通过 IP 地址查找对应的 MAC 地址
4、这个 eth0 网卡,是一个 Veth Pair虚拟设备对,它的一端在这个 test2 容器的 Network Namespace 里,而另一端则位于宿主机上(Host Namespace),并且被“插”在了宿主机的 docker0 网桥上。网桥设备的一个特点是插在桥上的网卡都会被当成桥上的一个端口来处理,而端口的唯一作用就是接收流入的数据包,然后把这些数据包的“生杀大权”(比如转发或者丢弃),全部交给对应的网桥设备处理。
5、因此ARP的广播请求也会由docker0来负责转发,这样网桥就维护了一份端口与mac的信息表,因此针对test2的eth0拿到mac地址后发出的各类请求,同样走到docker0网桥中由网桥负责转发到对应的容器中。
# 网桥会维护一份mac映射表,我们可以大概通过命令来看一下,
[root@nginx02 ~]# brctl showmacs docker0
port no mac addr is local? ageing timer
2 46:57:6d:fe:e2:b4 yes 0.00
2 46:57:6d:fe:e2:b4 yes 0.00
1 aa:fe:fd:cf:0f:53 yes 0.00
1 aa:fe:fd:cf:0f:53 yes 0.00
## 这些mac地址是主机端的veth网卡对应的mac,可以查看一下
$ ip a
5: veth89481c7@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether aa:fe:fd:cf:0f:53 brd ff:ff:ff:ff:ff:ff link-netnsid 0
7: veth129a5c1@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 46:57:6d:fe:e2:b4 brd ff:ff:ff:ff:ff:ff link-netnsid 1
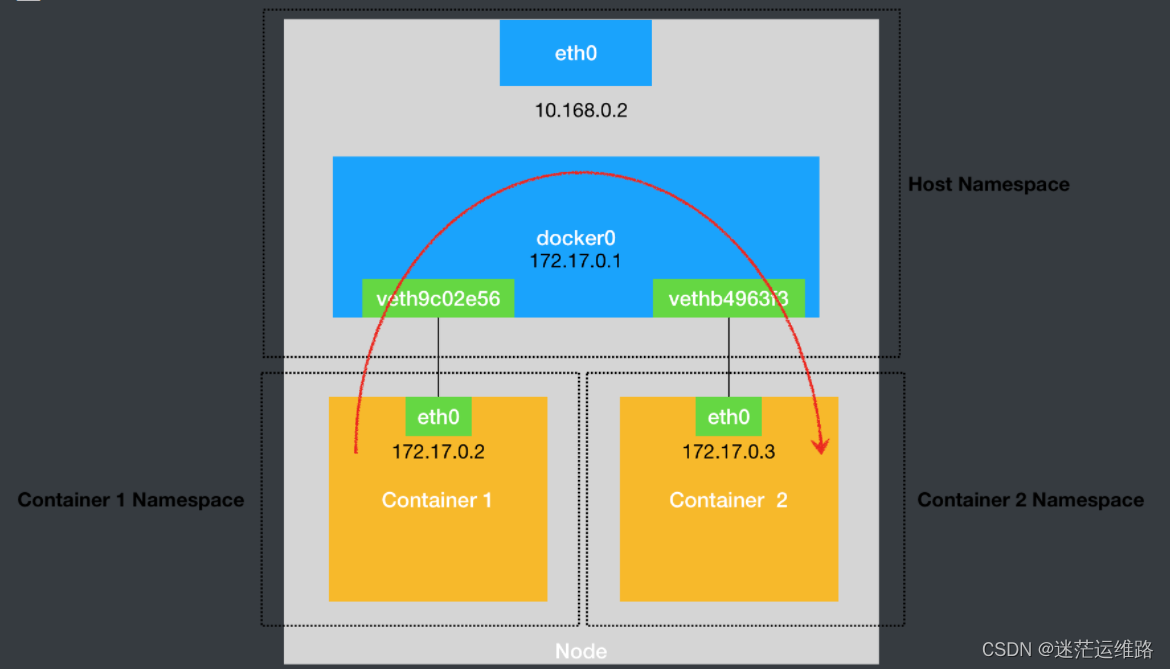
5.1.6 我们如何知道网桥上的这些虚拟网卡与容器端是如何对应?
## 查看test1容器的网卡索引
[root@nginx02 ~]# docker exec -ti test1 cat /sys/class/net/eth0/ifindex
4
## 主机中找到虚拟网卡后面这个@ifxx的值,如果是同一个值,说明这个虚拟网卡和这个容器的eth0网卡是配对的。
[root@nginx02 ~]# ip a |grep @if
5: veth89481c7@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
7: veth129a5c1@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
#!/bin/bash
#当容器过多时,该脚本可快速匹配虚拟网卡和哪个容器端是对应的
for container in $(docker ps -q); do
iflink=`docker exec -it $container sh -c 'cat /sys/class/net/eth0/iflink'`
iflink=`echo $iflink|tr -d '\r'`
veth=`grep -l $iflink /sys/class/net/veth*/ifindex`
veth=`echo $veth|sed -e 's;^.*net/\(.*\)/ifindex$;\1;'`
echo $container:$veth
done
5.1.7 容器与宿主机之间的通信
1、添加端口映射,启动一个名为test的容器
docker run --name test -d -p 8088:80 nginx:alpine
2、在本宿主机上和与宿主机同一网段的机器上curl 暴露出来的8088端口,发现也能curl通
3、因此,请看下面的流向图,进行进一步分析
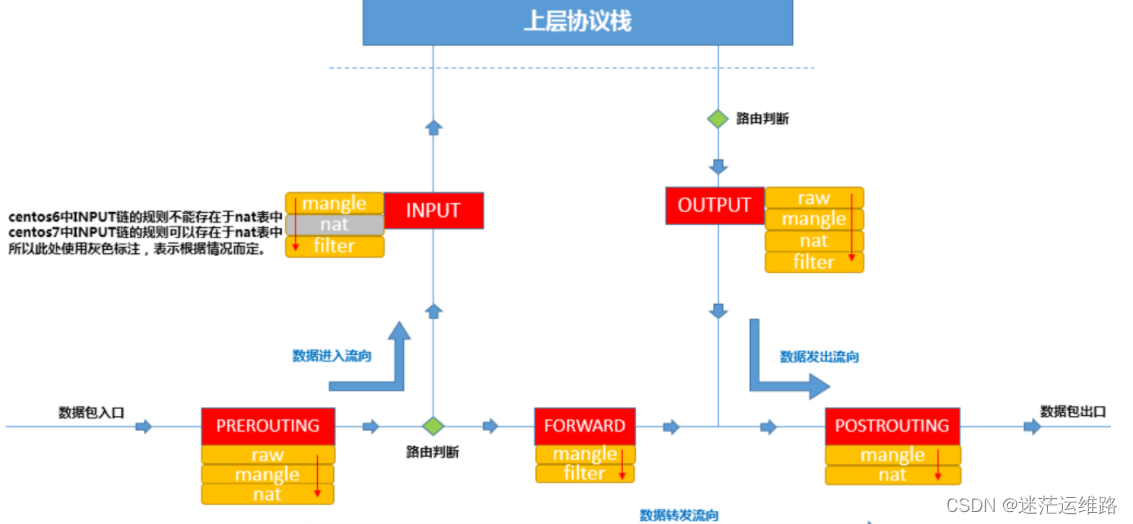
容器与宿主机通信流程:
1、访问本机的8088端口,数据包会从流入方向进入本机,因此涉及到PREROUTING和INPUT链,
我们是通过做宿主机与容器之间加的端口映射,所以肯定会涉及到端口转换,那哪个表是负责存储端口转换信息的呢,就是nat表,负责维护网络地址转换信息的。因此我们来查看一下PREROUTING链的nat表
[root@nginx02 ~]# iptables -t nat -nvL PREROUTING
Chain PREROUTING (policy ACCEPT 70 packets, 4200 bytes)
pkts bytes target prot opt in out source destination
8279K 497M DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
2、上述的TARGET为DOCKER,很明显DOCKER不是标准的动作,那DOCKER是什么呢?我们通常会定义自定义的链,这样把某类对应的规则放在自定义链中,然后把自定义的链绑定到标准的链路中,因此,此处DOCKER 是自定义的链。使用以下命令查看DOCKER这个自定义链上的规则
[root@nginx02 ~]# iptables -t nat -nvL DOCKER
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- docker0 * 0.0.0.0/0 0.0.0.0/0
1 60 DNAT tcp -- !docker0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8088 to:172.17.0.4:80
3、此条规则就是对主机收到的目的端口为8088的tcp流量进行DNAT转换,将流量发往172.17.0.4:80,172.17.0.4地址就是我们上面创建的test容器的ip地址,流量走到网桥上了,后面就走网桥的转发就ok了
4、根据图可知,数据包在出口方向走POSTROUTING链,我们查看一下规则
[root@nginx02 ~]# iptables -t nat -nvL POSTROUTING
Chain POSTROUTING (policy ACCEPT 5359 packets, 325K bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0
0 0 MASQUERADE tcp -- * * 172.17.0.4 172.17.0.4 tcp dpt:80
注意:
MASQUERADE这个动作是什么意思,其实是一种更灵活的SNAT,把源地址转换成主机的出口ip地址:
这条规则会将源地址为172.17.0.0/16的包(也就是从Docker容器产生的包),并且不是从docker0网卡发出的,进行源地址转换,转换成主机网卡的地址。
大概的过程就是ACK的包在容器里面发出来,会路由到网桥docker0,网桥根据宿主机的路由规则会转给宿主机网卡eth0,这时候包就从docker0网卡转到eth0网卡了,并从eth0网卡发出去,这时候这条规则就会生效了,把源地址换成了宿主机eth0的ip地址。
抓包分析:
首先访问宿主机的8088端口,我们抓一下宿主机的eth0:
tcpdump -i eth0 port 8088 -w host.cap
然后最终包会流入容器内,那我们抓一下容器内的eth0网卡:
tcpdump -i eth0 port 80 -w container.cap
然后再另外一台机器访问一下:
curl 192.168.1.10:8088 #该IP地址是运行容器test的宿主机地址
停止抓包,拷贝容器内的包到宿主机:
docker cp test:/root/container.cap /root/
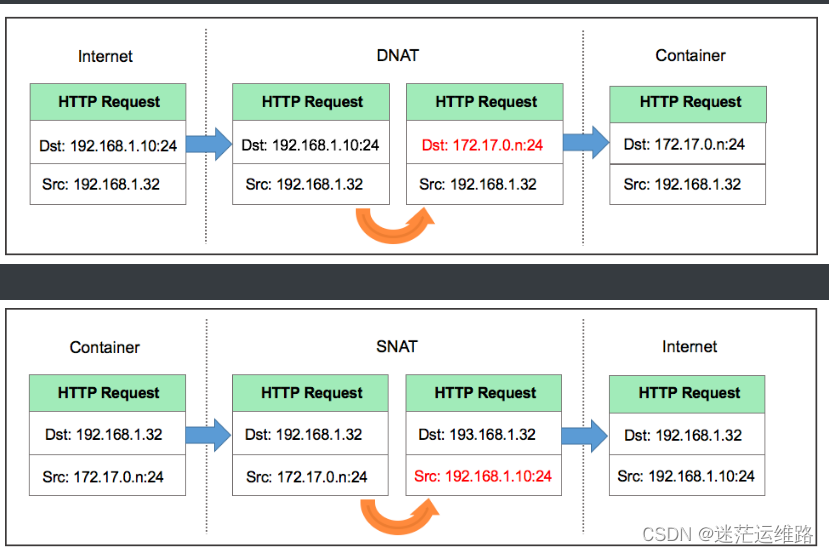
将container.cap host.cap两个文件下载到本地使用wireshark将包合并后进行分析。分析结果如下
进到容器内的包做DNAT,出去的包做SNAT
六、Docker常用操作命令
docker image ls 查看本地都有哪些镜像
docker pull redis:6.0 拉取镜像
docker pull --platform=linux/arm64 镜像地址 在centos操作系统上拉取arm环境的镜像(--platform标志可用于在FROM引用多平台镜像的情况下指定镜像的平台。构建镜像也可使用该参数 如:linux/amd64, linux/arm64, or windows/amd64)
docker inspect redis:6.0 查看镜像的详细信息
docker tag alpine:latest qfedu.com/alpine:latest 镜像打标签
docker image rm redis:6.0 删除镜像
docker rmi $(docker images -q) 删除所有镜像
docker container ls 查看容器
docker kill 容器名 强行停止容器
docker ps -a 查看本地运行的容器
docker logs -f 容器名/ID 查看某个容器的日志
docker start 容器名/ID 启动已存在的容器
docker stop 容器名/ID 停止正在运行的容器
docker restart 容器名/ID 重启容器
docker rm 容器名/ID 删除容器
docker rm $(docker ps -a -q) 删除所有已停止的容器
docker run -itd -name 容器名 -p 映射的端口号:自身端口号 镜像名称:版本 启动一个新的容器并后台运行,-d后台执行
docker stop $(docker ps -a -q) 停止所有容器
docker exec -it 容器名 bash 进入容器内的命令行
docker cp ./index.html 容器名:/usr/share/nginx/html/ 拷贝宿主机文件至某个容器内
docker logs -f 容器名 查看容器日志
docker system prune -a -f 删除停止的容器、无用的数据卷、网络和无tag的镜像
docker save IMAGE id -o /path/file.tar.gz 镜像导出
docker load -i /path/file.tar.gz 镜像导入
docker save 镜像名1 镜像2 > /path/all.tar.gz 一次导出多个镜像
docker top 容器ID 查看容器中的进程
docker stats 容器ID 查看容器资源利用率(动态获取)
docker stats 容器ID --no-stream 查看容器资源利用率(静态获取)
docker diff 容器ID 查看容器的文件结构更改
docker commit -a "guodong" -m "my db" 容器ID mymysql:v1 将旧容器保存为新的镜像,并添加提交人信息和说明信息。
docker port 容器ID 查看容器的端口映射情况。
docker pause db01 暂停数据库容器db01提供服务
docker unpause db 恢复数据库容器 db0 提供服务
docker build -f /path/to/a/Dockerfile . 通过 -f Dockerfile文件的位置 创建镜像
docker push myapache:v1 推送镜像到镜像仓库
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python非常好用的文件系统监控库
- 0基础学java-day21(网络编程)
- 网络第4天
- 不会写好你的年终总结报告,约等于一年白干,老板看了都摇头!
- LDRA Testbed系列(一)Testbed软件静态分析_操作指南
- ros2 基础学习10 ros 中服务的定义及示例
- PID笔记
- Golang 泛型
- 【仿真】verilog调用c的reference module
- 《Spring》--使用application.yml特性提供多环境开发解决方案/开发/测试/线上--方案1