redis缓存
redis缓存
缓存穿透
什么是缓存穿透?
查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查询数据库,导致数据库压力过大
如何解决缓存穿透问题?
解决方案一:缓存空数据,查询返回的数据为空,把这个空结果进行缓存
优点:实现简单
缺点:查询的空数据过多就会导致内存消耗大,而且缓存的数据修改后可能存在数据不一致问题
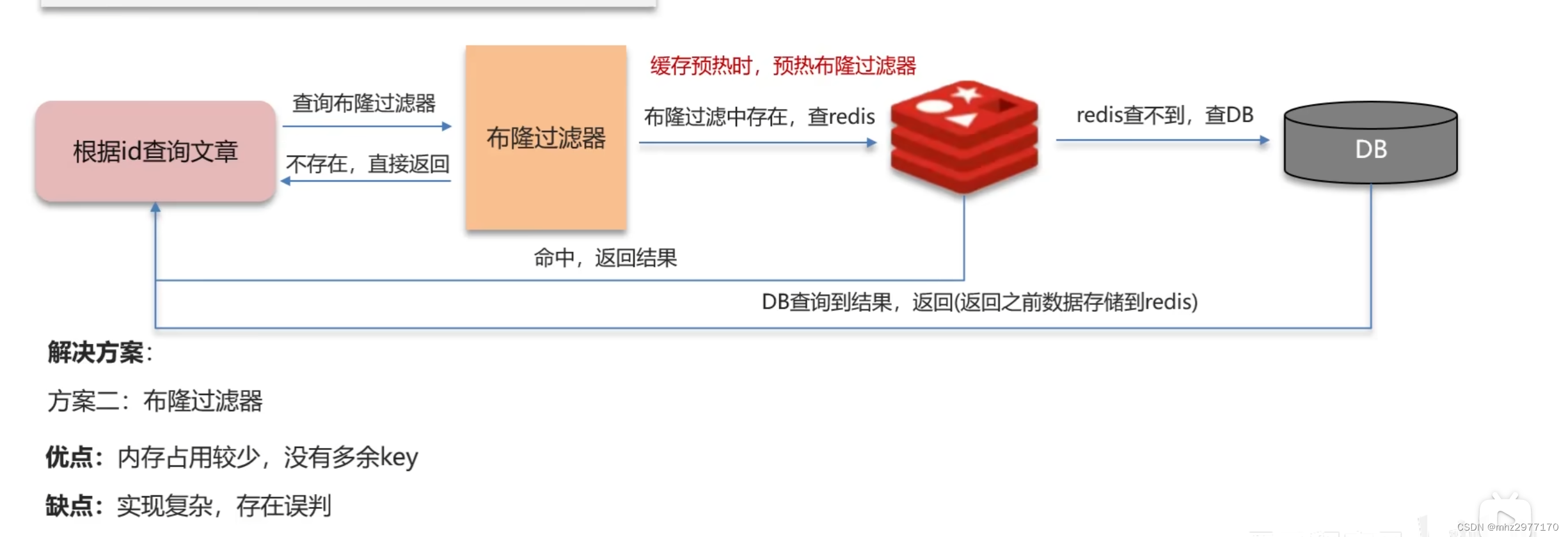
解决方案二:布隆过滤器实现过滤
查询的时候会先查询布隆过滤器,不存在就直接返回,如果在布隆过滤器中存在就会查询redis,查不到就再查询数据库,查询到了就会缓存到redis
优点:内存占用较少,没有多余的key
缺点:实现复杂,存在误判
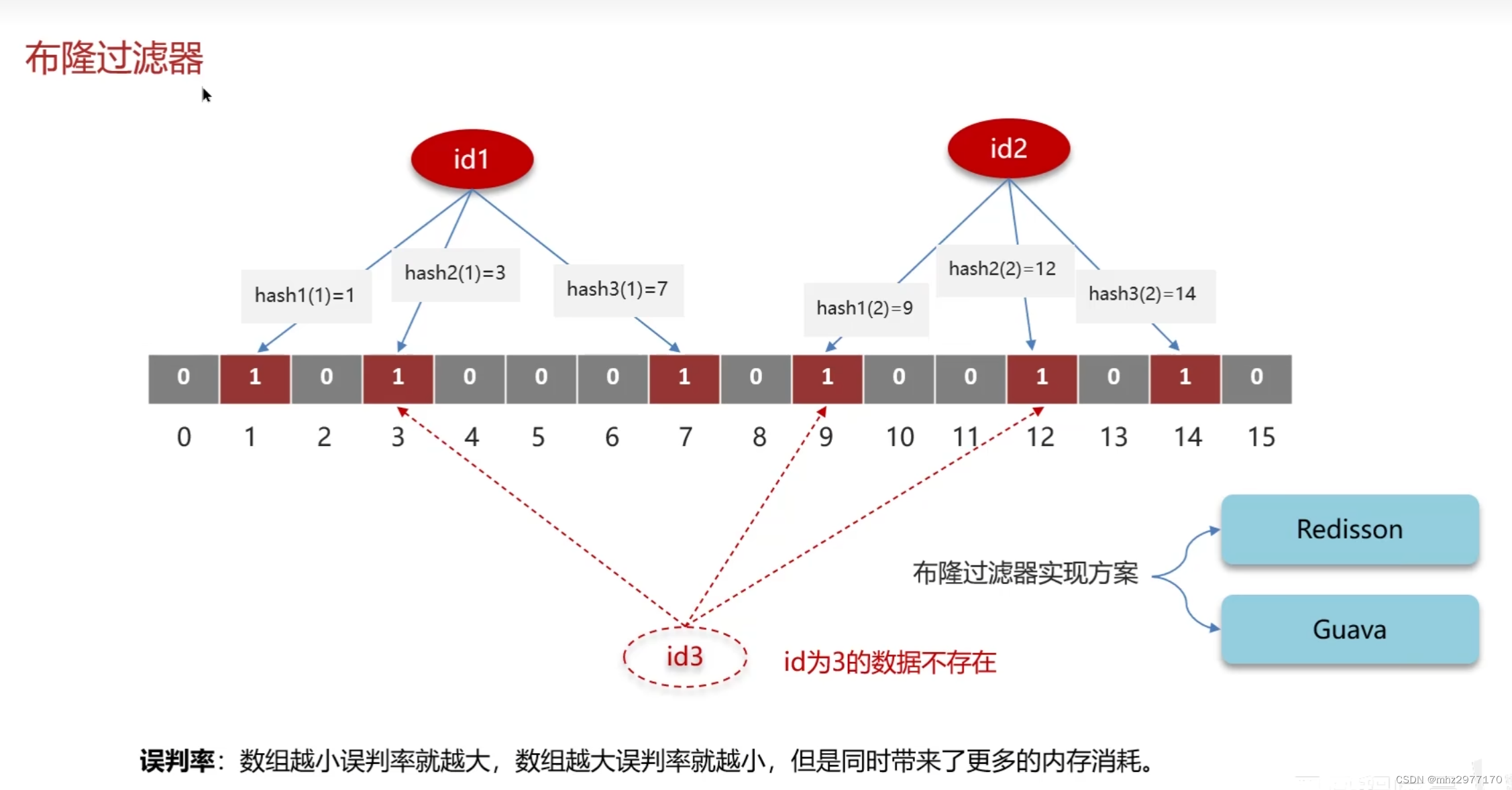
布隆过滤器的误判
布隆过滤器用于检索一个元素是否在一个集合中
存储数据:通过hash函数计算元素的hash值,在数组中将对应的值修改为1
查询数据:使用相同的hash函数获取hash值,判断是否都为1
元素是否存在,都基于数组中的hash值,可能某个不存在的元素的hash值在数组中恰好值都为1,就会产生误判
数组越大误判率越小,但是同时带来了更多的内存消耗
缓存击穿
什么是缓存击穿?
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好有大量请求,这些请求可能会瞬间把数据库压垮
如何解决缓存击穿?
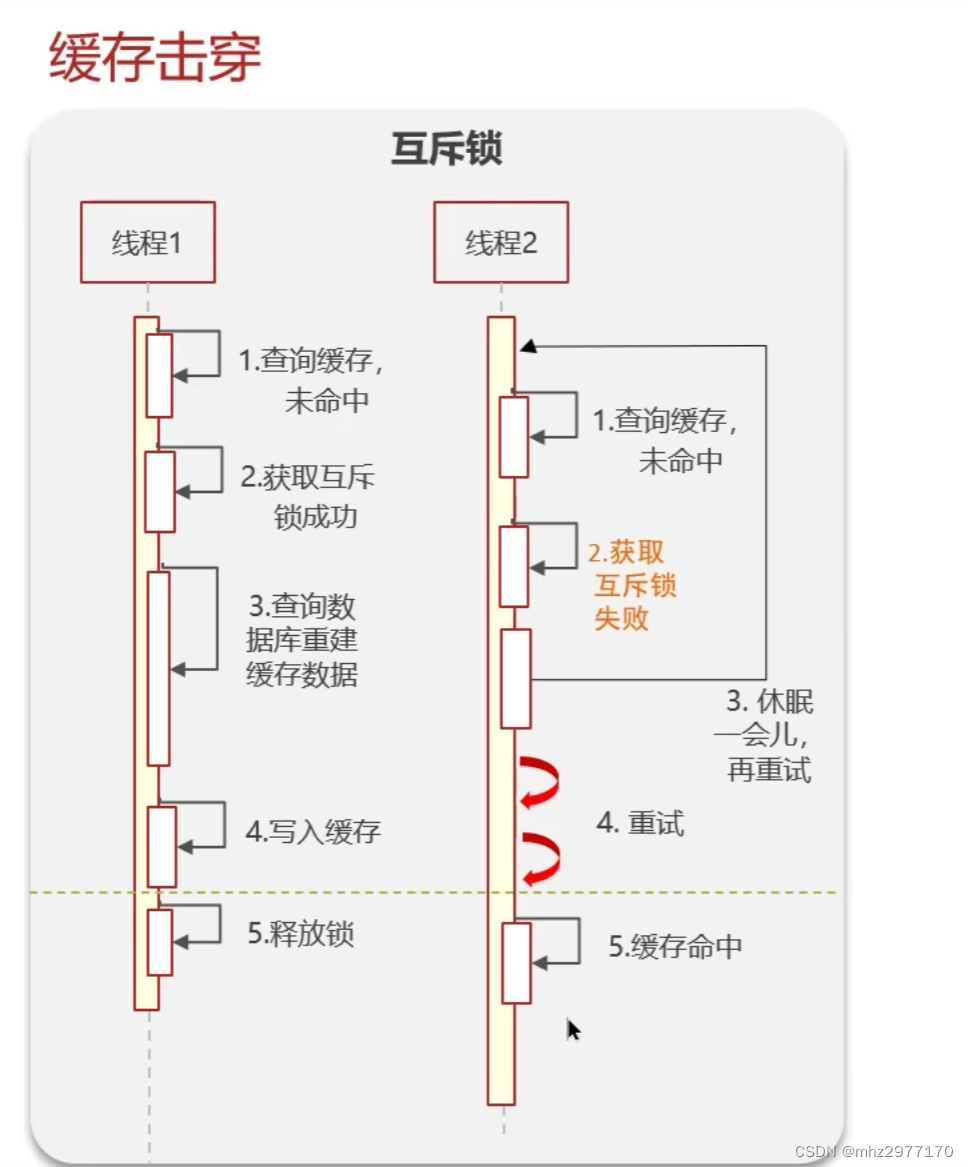
解决方案一:互斥锁
线程1查询缓存没有数据,获取互斥锁成功,查询数据库重建缓存数据,写入缓存然后释放锁。线程2查询缓存没有数据,获取锁失败,休眠一会重新查询,再没查到就再获取锁,直到查询到数据
优点:强一致,安全
缺点:性能较低,只有一个线程在工作,后续线程都在等待
解决方案二:逻辑过期
对缓存中的热点数据不设置过期,设置一个过期时间字段
线程1查询缓存发现过期,获取一个互斥锁,开启一个新线程查询数据库重建缓存数据,写入缓存重置过期时间,然后释放锁。线程1无需等待重建缓存,直接返回过期数据。在重建缓存期间,有一个线程3,查询缓存发现过期,获取互斥锁失败会直接返回过期数据。构建缓存成功之后,再查询就没有过期,直接返回。
优点:高可用,高性能
缺点:延迟更新,在重建缓存期间会导致数据不一致

缓存雪崩
什么是缓存雪崩?
缓存雪崩:是指同一时段大量缓存的key失效或者redis宕机,导致大量请求直接到数据库,带来巨大压力
如何解决缓存雪崩?
解决方案一:设置随机的过期时间
解决方案二:使用redis集群提高服务可用性,如哨兵模式、集群模式
解决方案三:给缓存业务添加降级限流,可以使用nginx,getway
解决方案四:使用多级缓存,可以使用Guava或者Caffeine
**
以使用nginx,getway
解决方案四:使用多级缓存,可以使用Guava或者Caffeine

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何在Android Glide中结合使用CenterCrop和自定义圆角变换(图片部分圆角矩形)
- 打开这个地方,就能让你的手机网速提升好几倍,赶紧来试试!
- 2024网工必备技术词汇大全(网络、运维、安全3大方向)
- vscode编写python步骤
- C++ opencv RGB三通道提升亮度
- 【 ATU NXP-SBC 系列 】FS26XX GUI_OTP烧录与模拟操作
- .Net 访问电子邮箱-LumiSoft.Net,好用
- 使用分时调度协程降低开发成本
- Java学习(十七)--IO流
- 图像识别快速实现