使用pandas处理数据的一些总结
发布时间:2023年12月28日
1、替换换行符等特殊符号
df = df.replace({None: "", np.nan: "", "\t": "", "\n": "", "\x08": ""}, regex=True)2、清除DataFrame中所有数据的左右空格,字符串中间空格不会清除,类似于字符串的strip()方法,如果是Serise类型可以使用df.str.strip()方法
df = df.applymap(lambda x: " ".join(x.split()) if isinstance(x, str) else x)3、dataframe数据去重
dataframe数据样本:
import pandas as pd
df = pd.DataFrame({'name':['苹果','梨','草莓','苹果'], 'price':[7,8,9,8], 'cnt':[3,4,5,4]})
name cnt price
0 苹果 3 7
1 梨 4 8
2 草莓 5 9
3 苹果 6 8
3.1、查看dataframe的重复数据
a = df.groupby('price').count()>1
price = a[a['cnt'] == True].index
repeat_df = df[df['price'].isin(price)]
3.2、duplicated()方法判断
3.2.1、?判断dataframe数据某列是否重复
flag = df.price.duplicated()
0 False
1 False
2 False
3 True
Name: price, dtype: bool
flag.any()结果为True (any等于对flag or判断)
flag.all()结果为False (all等于对flag and判断)
3.2.2、判断dataframe数据整行是否重复
flag = df.duplicated()
判断方法同1
3.2.3、判断dataframe数据多列数据是否重复(多列组合查)
df.duplicated(subset = ['price','cnt'])
判断方法同1
>> drop_duplicats()方法去重
4. 对dataframe数据数据去重
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
示例:
df.drop_duplicats(subset = ['price','cnt'],keep='last',inplace=True)
drop_duplicats参数说明:
参数subset
subset用来指定特定的列,默认所有列
参数keep
keep可以为first和last,表示是选择最前一项还是最后一项保留,默认first
参数inplace
inplace是直接在原来数据上修改还是保留一个副本,默认为False4、 文件中含有换行符时,需要保留换行符
import csv
import pandas as pd
#
data = {'col1': ['Hello\nWorld', 'Line\nbreak"'], 'col2': [1, 2]}
df = pd.DataFrame(data)
print(df)
df.to_csv('data.csv', line_terminator='\n', quoting=csv.QUOTE_ALL, index=False, header=False)
df = pd.read_csv('data.csv', header=None)
print(df)运行结果:
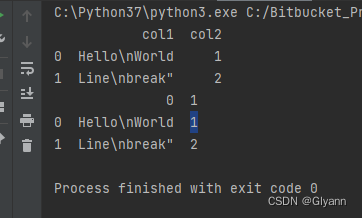
5、当csv文件入hive时,遇到空值需要在hive中显示为null值
CREATE TABLE my_table
(
id int comment '编号',
name string comment '名称',
money decimal(10, 2) comment '金钱'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
NULL DEFINED AS ''
STORED AS TEXTFILE
TBLPROPERTIES ("serialization.null.format"='');NULL DEFINED AS ''将空字符串视为NULL值,'serialization.null.format'=''则用于指定NULL值在数据文件中的表示方式。通过这种方式,我们可以同时使用NULL DEFINED AS ''和serialization.null.format=''来将NULL值和空字符串表示在Hive中的一致性。
也可以修改已存在的表,如下?
alter table my_table set serdeproperties('serialization.null.format' = '');
文章来源:https://blog.csdn.net/Gzigithub/article/details/131249898
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!