PySpark-Spark SQL基本介绍
目录
Spark SQL基本介绍
概念:Spark SQL是Spark多种组件中其中一个,主要是用于处理大规模的结构化数据
结构化数据:可以转化为二维表格的数据,一份数据,每一行,每一列的了下都是一致的,我们将这样的数据称为结构化数据
例如:mysql的表数据
??????? 1 张三 10
??????? 2 李四 18
??????? 3 王五 20
Spark SQL特点
1.融合性:既可以使用标准SQL语言,也可以编写代码,同时支持混合使用
2.统一的数据访问:可以通过统一的API来对接不同的数据源
3.Hive的兼容性:Spark SQL可以和Hive进行整合,整合后替换执行引擎为Spark,核心是基于Hive的metastore来管理元数据
4.标准化连接:Spark SQL也支持JDBC/ODBC的连接方式
Spark SQL与Hive的异同
相同点:
??????? 1.都是分布式SQL计算引擎
??????? 2.都可以处理大规模的结构化数据
??????? 3.都可以建立YARN集群上运行
不同点:
??????? 1.Spark SQL是基于内存计算,而Hive SQL是基于磁盘进行计算的
??????? 2.Spark SQL没有元数据管理服务(自己维护),而Hive SQL是有metastore元数据管理服务的
??????? 3.Spark SQL底层执行的是Spark RDD程序,而Hive SQL底层执行的是mapreduce程序
??????? 4.Spark SQL可以编写SQL也可以编写代码,而Hive SQL仅能编写SQL语句
Spark SQL的数据结构
| 核心 | 数据结构 | 区别 |
| Pandas | DataFrame | ● 二维表数据结构 ● 处理单机(本地集合)结构数据 |
| SparkCore | RDD | ● 无标准数据结构(任何的数据结构) ● 大规模的分布式结构数据(分区) |
| SparkSQL | DataFrame | ● 二维表格结构 ● 大规模的分布式结构数据(分区) |
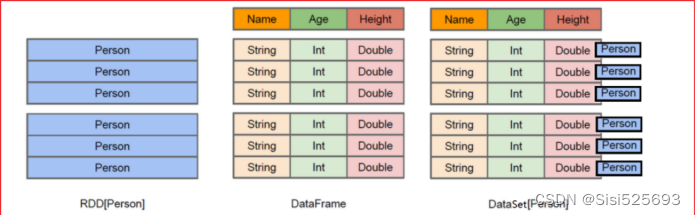
以图为例:
RDD:存储直接就是对象,存储就是一个Person的对象,无法看到对象的数据内容
DataFrame:将Person中的各个字段数据,进行结构化存储,形成一个DataFrame,可以直接看到数据
Dataset:将Person对象中的数据按照结构化的方式存储,同时保留对象的类型,从而知道来源于开一个Person对象
Spark SQL的入门
创建SparkSession对象
????????Spark SQL需要将顶级对象SparkContext变成SparkSesssion对象。SparkContext是RDD中的顶级对象,里面没有和SQL编程相关的API/方法。通过SparkSession对象还是可以得到SparkContext对象。
# 如何构建一个SparkSession对象呢?
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 创建SparkSQL中的顶级对象SparkSession
"""
注意事项:
1- SparkSession和builder都没有小括号
2- appName():给应用程序取名词。等同于SparkCore中的setAppName()
3- master():设置运行时集群类型。等同于SparkCore中的setMaster()
"""
spark = SparkSession.builder\
.appName('create_sparksession_demo')\
.master('local[*]')\
.getOrCreate()
# 通过SparkSQL的顶级对象获取SparkCore中的顶级对象
sc = spark.sparkContext
# 释放资源
sc.stop()
spark.stop()DataFrame详解
DataFrame基本介绍
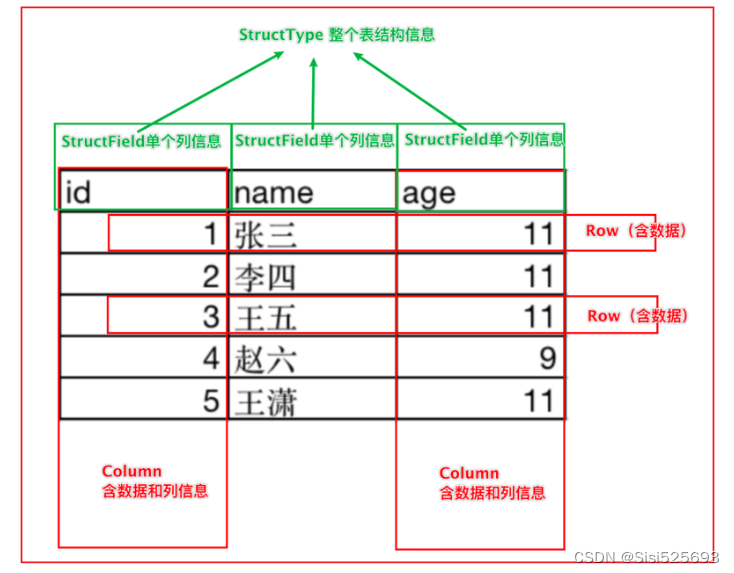
DataFrame:表示的是一个二维得表,存在行,列等表结构描述信息
表结构描述信息(元数据schema):strucType对象
字段:structField对象,可以描述字段名称,字段数据类型,是否可以为空
行:Row对象
列:column对象,包括字段名称和字段值
在一个StructType对象下,由多个StructField组成,构建成一个完整的元数据信息

?DataFrame的构建方式
RDD构建DataFrame
场景:RDD可以存储任意结构的数据;而DataFrame只能处理二维表数据。在使用Spark处理数据的初期,可能输入进来的数据是半结构化或者是非结构化的数据,那么我可以先通过RDD对数据进行ETL处理成结构化数据,再使用开发效率高的SparkSQL来对后续数据进行处理分析。
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType, StructField
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
print('通过Rdd创建DataFrame')
# 创建SparkSession对象
spark = SparkSession \
.builder.appName('rdd_to_DataFrame_demo') \
.master('local[*]') \
.getOrCreate()
# 通过SparkSession对象创建SparkContext顶级对象
sc = spark.sparkContext
# 数据输入
# 构建rdd
init_rdd = sc.parallelize(['1,张三,18', '2,李四,20', '3,王五,22'])
# 将qrdd数据结构转成二维结构
new_rdd = init_rdd.map(lambda line: (
int(line.split(',')[0]),
line.split(',')[1],
int(line.split(',')[2], )))
# 将RDD转成DataFrame:方式一
# 构建schema方式一
schema = StructType() \
.add('id', IntegerType(), False) \
.add('name', StringType(), False) \
.add('age', IntegerType(), False)
# 构建schema方式二
schema = StructType([
StructField('id', IntegerType(), False),
StructField('name', StringType(), False),
StructField('age', IntegerType(), False),
])
# 构建schema方式三
schema = "id:int,name:string,age:int"
schema = "id int,name string,age int"
# 构建schema方式四,不能指定字段类型
schema = ['id', 'name', 'age']
# 构建DataFrame
init_df = spark.createDataFrame(data=new_rdd, schema=schema)
# 数据输出
init_df.show()
# 输出schema
init_df.printSchema()
print('=' * 50)
# 将RDD转成DataFrame:方式二
"""
toDF:中的schema既可以传List,也可以传字符串形式的schema信息
"""
# 方式一:传入列表
init_df2 = new_rdd.toDF(schema=['id', 'name', 'age'])
# 方式一:传入字符串
init_df2 = new_rdd.toDF(schema="id:int,name:string,age:int")
init_df2 = new_rdd.toDF(schema="id int,name string,age int")
# 数据输出
init_df2.show()
# 输出schema
init_df2.printSchema()
# 释放资源
spark.stop()
sc.stop()
?内部初始化数据得到DataFrame
场景:一般用在开发和测试中。因为只能处理少量的数据
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType, StructField
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
print('内部初始化数据得到DataFrame')
# 创建SparkSession对象
spark = SparkSession \
.builder \
.appName('inner_create_dataframe') \
.master('local[*]') \
.getOrCreate()
# 2- 数据输入
"""
内部初始化数据得到DataFrame
通过createDataFrame创建DataFrame,schema数据类型可以是:DataType、字符串、List
字符串:格式要求
格式一 字段1 字段类型,字段2 字段类型
格式二(推荐) 字段1:字段类型,字段2:字段类型
List:格式要求
["字段1","字段2"]
"""
# 方式一
init_df = spark.createDataFrame(
data=[(1, '张三', 18), (2, '李四', 20), (3, '王五', 22)],
schema='id int,name string,age int'
)
# 方式二
init_df = spark.createDataFrame(
data=[(1, '张三', 18), (2, '李四', 20), (3, '王五', 22)],
schema='id:int,name:string,age:int'
)
# 方式三,列表形式不能指定字段类型,有输入的数据自动推断字段类型
init_df = spark.createDataFrame(
data=[(1, '张三', 18), (2, '李四', 20), (3, '王五', 22)],
schema=['id', 'name', 'age']
)
# 数据输出
init_df.show()
# 输出schema信息
init_df.printSchema()
# 是否资源
spark.stop()
schema总结
通过createDataFrame创建DataFrame,schema数据类型可以是:DataType、字符串、List
1: 字符串
??? 格式一 字段1 字段类型,字段2 字段类型
??? 格式二(推荐) 字段1:字段类型,字段2:字段类型
?? ?
2: List
??? ["字段1","字段2"]
?? ?
3: DataType(推荐,用的最多)
??? 格式一 schema = StructType()\
??????????? .add('id',IntegerType(),False)\
??????????? .add('name',StringType(),True)\
??????????? .add('age',IntegerType(),False)??? 格式二 schema = StructType([
??????????? StructField('id',IntegerType(),False),
??????????? StructField('name',StringType(),True),
??????????? StructField('age',IntegerType(),False)
????????? ])
读取外部文件得到DataFrame
复杂API
统一API格式:
Sparksession.read
??????? .format('text | csv | json | parquet | orc |? avro | jdbc | ......')??? # 读取外部文件的方式
??????? .option('k','v')????????? # 选项,可以设置相关的参数(可选)
??????? .schema(structType | string)? # 设置表的结构信息
??????? .load('加载数据路径')??? # 读取外部文件的路径,支持HDFS也支持本地
?简写API
注意:所有的复杂API外部读取方式,都有简单的写法,spark内置了一些常用的读取方案的简写
格式:
?????????? spark.read.读取方式()
例如:
??????? df=spark.read.csv(
??????????????? path='文件路径',
??????????????? header=True,
??????????????? sep=' ',
??????????????? inferschema=True,
??????????????? encoding='utf-8'
????????)
Text方式读取
load:支持读取HDFS文件系统和本地文件系统
??????????? HDFS文件系统:hdfs://node1:8020/文件路径
??????????? 本地文件系统:file:///文件路径
?????????? ?
??????? text方式读取文件总结:
??????????? 1- 不管文件中内容是什么样的,text会将所有内容全部放到一个列中处理
??????????? 2- 默认生成的列名叫value,数据类型string
??????????? 3- 我们只能够在schema中修改字段value的名称,其他任何内容不能修改
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# text方式读取
print('text方式读取外部文件')
# 创建sparksession对象
spark = SparkSession.builder.appName('text_demo').master('local[*]').getOrCreate()
# 复杂API方式
# 数据输入
init_df = spark.read \
.format('text') \
.schema('my_file string') \
.load('file:///export/data/pyspark_projects/02_spark_sql/data/stu.txt')
# 数据输出
init_df.show()
# 输出schema
init_df.printSchema()
# 简写API方式
init_df = spark.read.text(
paths='file:///export/data/pyspark_projects/02_spark_sql/data/stu.txt'
)
init_df.show()
# 输出schema
init_df.printSchema()
CSV方式读取
csv格式读取外部文件总结:
??? 1- 复杂API和简写API都须掌握
??? 2- 相关参数作用说明:
??????? 2.1- path:指定读取的文件路径。支持HDFS和本地文件路径
??????? 2.2- schema:手动指定元数据信息
??????? 2.3- sep:指定字段间的分隔符
??????? 2.4- encoding:指定文件的编码方式
??????? 2.5- header:指定文件中的第一行是否是字段名称
??????? 2.6- inferSchema:根据数据内容自动推断数据类型。但是,推断结果可能不精确
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# json方式读取
print('csv方式读取外部文件')
# 创建sparksession对象
spark = SparkSession.builder.appName('csv_demo').master('local[*]').getOrCreate()
# 复杂API方式
# 数据输入
init_df = spark.read \
.format('csv') \
.option('sep', ' ') \
.option('encoding', 'utf8') \
.option('header', 'True') \
.schema(schema='id int,name string,address string,sex string,age int') \
.load('file:///export/data/pyspark_projects/02_spark_sql/data/stu.txt')
# 数据输出
init_df.show()
# 输出schema
init_df.printSchema()
print('='*50)
#简写API方式
init_df = spark.read.csv(
path='file:///export/data/pyspark_projects/02_spark_sql/data/stu.txt',
schema='id int,name string,address string,sex string,age int',
sep=' ',
encoding='utf8',
header=True
)
init_df.show()
# 输出schema
init_df.printSchema()
JSON方式读取
json读取数据总结:
???? 1- 需要手动指定schema信息。如果手动指定的时候,字段名称与json中的key名称不一致,会解析不成功,以null值填充
???? 2- csv/json中schema的结构,如果是字符串类型,那么字段名称和字段数据类型间,只能以空格分隔
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# json方式读取
print('json方式读取外部文件')
# 创建sparksession对象
spark = SparkSession.builder.appName('json_demo').master('local[*]').getOrCreate()
# 复杂API方式
# 数据输入
init_df = spark.read \
.format('json') \
.option('sep', ':') \
.option('header', 'True') \
.option('encoding', 'utf8') \
.schema(schema='id int,name string,age int,address string') \
.load('file:///export/data/pyspark_projects/02_spark_sql/data/json.txt')
# 数据输出
init_df.show()
# 输出schema
init_df.printSchema()
print('=' * 50)
# # 简写API方式
init_df = spark.read.json(
path='file:///export/data/pyspark_projects/02_spark_sql/data/json.txt',
schema='id int,name string,age int,address string',
encoding='utf8'
)
init_df.show()
# 输出schema
init_df.printSchema()
# 释放资源
spark.stop()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 编程基础 - 变量与常量
- C++入门【31-C++ 基本的输入输出】
- 子类的构造函数和析构函数调用顺序
- 主从版本升级_主从_8.0.32_软链接_基于二进制日志文件
- 从零学算法94
- leetcode LCR 170. 交易逆序对的总数(hard)【小林优质解法】
- 虹科方案|低负载ECU老化检测解决方案:CAN/CAN FD总线“一拖n”
- SD-WAN是如何工作的?
- 竞赛保研 基于机器视觉的银行卡识别系统 - opencv python
- 低代码:美味膳食或垃圾食品