混合专家模型(MoE)2022-2023顶会顶刊论文合集,包含算法、系统、应用3大类
混合专家模型(MoE)是一种深度学习技术,它通过将多个模型(这些模型被称为"专家")直接结合在一起,以加快模型训练的速度,获得更好的预测性能。这种模型设计策略在大模型中尤为重要,它可以解决大模型在训练时面临的一些问题。比如通过层之间的参数共享,MoE能够压缩模型大小;利用MoE的设计,可以扩大模型容量。
目前,基于Transformer扩展的大模型是当前各种大模型的主干,MoE则是扩展Transformer的一种关键技术。在大模型已至瓶颈的现在,MoE技术的发展为如何降低大模型训练难度和推理成本等难题提供了新的解题思路。
这次我整理了2022-2023近两年混合专家模型相关的顶会顶刊论文54篇,分了算法、系统、应用3个大类来和各位分享,帮助有需要的同学攻克大模型现存问题。
MoE算法
Patch-level Routing in Mixture-of-Experts is Provably Sample-efficient for Convolutional Neural Networks
混合专家系统中的补丁级路由对于卷积神经网络是样本高效的
「简述:」论文主要讨论了混合专家模型(MoE)在深度学习中的应用,特别是patch级路由在MoE(pMoE)中的效果。pMoE能够将输入分成多个补丁(或标记),并只将一部分补丁发送给每个专家,从而显著减少计算量。通过使用混合两层卷积神经网络(CNN)进行监督分类任务,作者证明了pMoE能够减少实现所需推广所需的训练样本数量,并优于其单个专家对应项。这是因为pMoE路由器可以过滤与标签无关的补丁,并将类似的类判别补丁路由到相同的专家,这有助于提高模型的泛化能力。
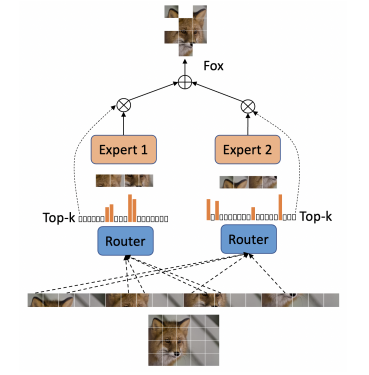
Robust Mixture-of-Expert Training for Convolutional Neural Networks
用于卷积神经网络的鲁棒混合专家训练
「简述:」论文提出了一种新方法AdvMoE,用于提高混合专家模型的对抗鲁棒性。作者发现传统的对抗训练对于混合专家模型不再有效,因为路由器和专家之间难以相互适应。因此,他们提出了一种新的交替对抗训练框架,将路由器和专家分开进行训练。实验结果表明,AdvMoE可以提高混合专家模型的对抗鲁棒性,并具有更高的效率。
Brainformers: Trading Simplicity for Efficiency
以简单换效率
「简述:」论文研究了Transformer设计的选择,并发现更复杂的块可以更有效。文章开发了一个名为Brainformer的复杂块,它由多种类型的层组成,并优于最先进的密集和稀疏Transformer。Brainformer具有更高的质量和效率,特别是在训练速度和步骤时间方面。在下游任务评估中,Brainformer也表现出更高的性能。最后,在fewshot评估中,Brainformer也优于通过NAS派生的模型。
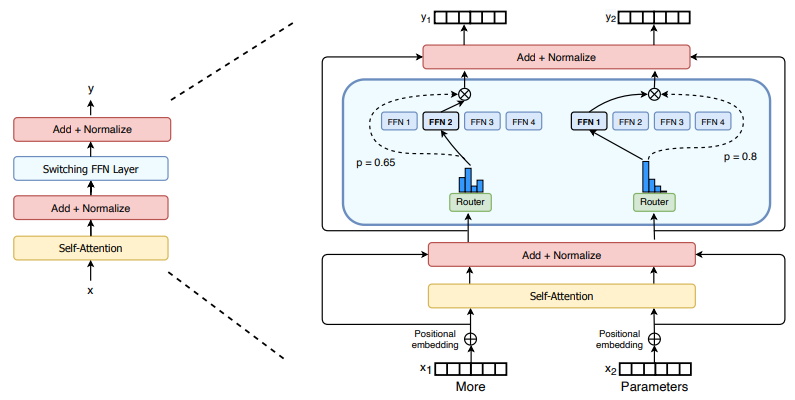
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
用简单高效的稀疏性扩展到万亿参数模型
「简述:」论文提出了一种名为Switch Transformer的方法,用于解决混合专家(MoE)模型的复杂性、通信成本和训练不稳定性等问题。作者简化了MoE路由算法,并设计了更直观的改进模型,以降低通信和计算成本。同时,作者提出了新的训练技术,帮助控制不稳定性,并展示了大型稀疏模型可以使用更低精度(bfloat16)格式进行训练。在多语言环境下,作者使用T5-Base和T5-Large模型实现了更高的预训练速度,并在大规模数据集上预训练了高达万亿参数规模的模型。
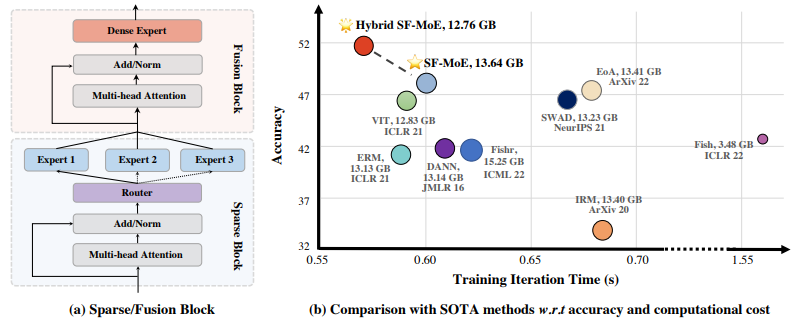
Sparse Fusion Mixture-of-Experts are Domain Generalizable Learners
稀疏融合专家混合是域可泛化学习器
「简述:」论文提出了一种名为SF-MoE的新领域泛化方法,该方法基于混合专家(MoE)模型构建。作者发现,混合专家模型可以通过处理多个领域的预测特征来处理分布偏移,从而提高其泛化能力。为此,作者将稀疏性和融合机制引入到MoE框架中,以保持模型的稀疏性和预测性。大量实验表明,SF-MoE是一个可泛化的域学习者,并在五个大规模领域泛化数据集上优于最先进的方法,同时计算成本相同甚至更低。作者还从分布式表示的角度揭示了SF-MoE的内部机制(例如视觉属性)。
-
On the Representation Collapse of Sparse Mixture of Experts
-
Taming Sparsely Activated Transformer with Stochastic Experts
-
Go Wider Instead of Deeper
-
StableMoE: Stable Routing Strategy for Mixture of Experts
-
Unified Scaling Laws for Routed Language Models
-
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs
-
A Theoretical View on Sparsely Activated Networks
-
Designing Effective Sparse Expert Models
-
Mixture-of-Experts with Expert Choice Routing
-
Parameter-Efficient Mixture-of-Experts Architecture for Pre-trained Language Models
-
A Review of Sparse Expert Models in Deep Learning
-
EvoMoE: An Evolutional Mixture-of-Experts Training Framework via Dense-To-Sparse Gate
-
muNet: Evolving Pretrained Deep Neural Networks into Scalable Auto-tuning Multitask Systems
-
Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts
-
ST-MoE: Designing Stable and Transferable Sparse Expert Models
-
MoEC: Mixture of Expert Clusters
-
No Language Left Behind: Scaling Human-Centered Machine Translation
-
Patcher: Patch Transformers with Mixture of Experts for Precise Medical Image Segmentation
-
Interpretable Mixture of Experts for Structured Data
-
Task-Specific Expert Pruning for Sparse Mixture-of-Experts
-
Gating Dropout: Communication-efficient Regularization for Sparsely Activated Transformers
-
AdaMix: Mixture-of-Adapter for Parameter-efficient Tuning of Large Language Models
-
Sparse Mixers: Combining MoE and Mixing to build a more efficient BERT
-
One Model, Multiple Modalities: A Sparsely Activated Approach for Text, Sound, Image, Video and Code
-
SkillNet-NLG: General-Purpose Natural Language Generation with a Sparsely Activated Approach
-
Residual Mixture of Experts
-
Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners
-
MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation
-
Mixture-of-experts VAEs can disregard variation in surjective multimodal data
-
Efficient Language Modeling with Sparse all-MLP
-
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
-
One Student Knows All Experts Know: From Sparse to Dense
MoE系统
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
推进专家混合推理和训练,为下一代人工智能规模提供动力
「简述:」论文提出了DeepSpeed-MoE,这是一个端到端的MoE训练和推理解决方案,包括新的MoE架构设计和模型压缩技术,以及一个高度优化的推理系统。DeepSpeed-MoE可以为大规模MoE模型提供更快、更便宜的推理服务,与同等质量的密集模型相比,可加速4.5倍,成本降低9倍。

FasterMoE: modeling and optimizing training of large-scale dynamic pre-trained models
大规模动态预训练模型的建模和优化训练
「简述:」论文提出了一种性能模型来预测特定任务的操作延迟,并设计了动态阴影方法和智能细粒度调度方法来应对负载不平衡和提高执行效率。此外,作者还设计了一种避免拥塞的专家选择策略来降低网络拥塞。最终,作者将这些优化措施集成为一个名为FasterMoE的系统,实现了高效的分布式MoE模型训练。实验证明,FasterMoE在大规模模型上比现有系统具有更好的性能。

-
HetuMoE: An Efficient Trillion-scale Mixture-of-Expert Distributed Training System
-
Tutel: Adaptive Mixture-of-Experts at Scale
-
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
-
BaGuaLu: Targeting Brain Scale Pretrained Models with over 37 Million Cores
-
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
-
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System
MoE应用
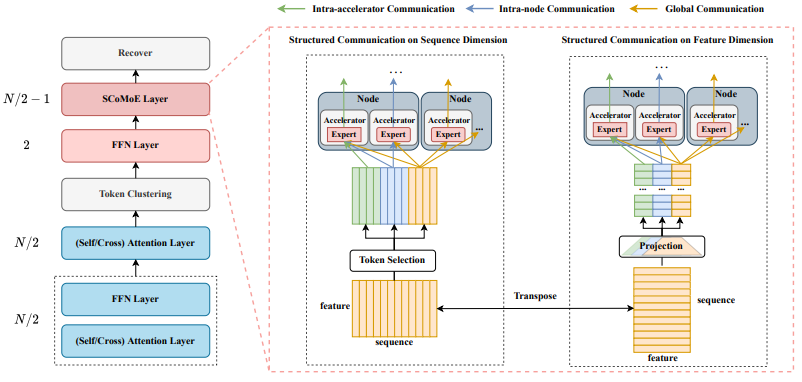
SCoMoE: Efficient Mixtures of Experts with Structured Communication
具有结构化通信的高效专家混合模型
「简述:」论文介绍了一种名为SCoMoE的Mixture-of-Experts(MoE)模型,该模型通过结构化全连接通信来减少通信成本。具体来说,SCoMoE使用快速的 intra-accelerator/node 通信通道来鼓励数据跨设备通信,并使用标记聚类方法在 MoE 层之前将来自不同设备的相关标记进行聚合。实验结果表明,SCoMoE在双语和多语言机器翻译任务上表现出色,比现有系统具有更好的性能和效率。
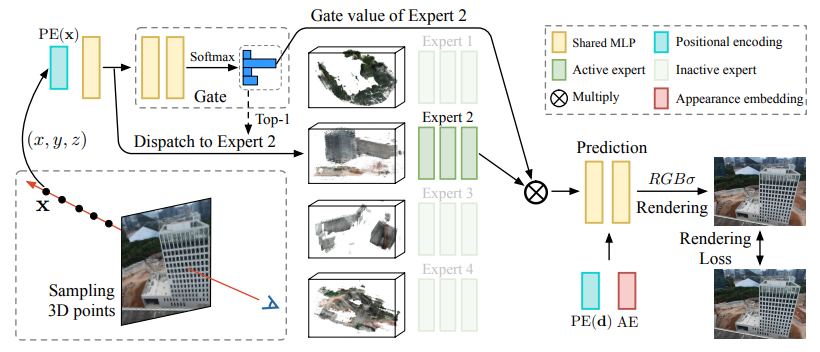
Switch-NeRF: Learning Scene Decomposition with Mixture of Experts for Large-scale Neural Radiance Fields
使用混合专家学习大规模神经辐射场的场景分解 简述:论文提出了一种新型端到端大规模神经辐射场Switch-NeRF,该模型使用基于专家混合的学习场景分解。作者设计了一个门控网络来将3D点分配给不同的NeRF子网络,并使用稀疏门控混合专家(MoE)的设计来优化门控网络和NeRF子网络以适应不同的场景分割。此外,作者还提出了一种可学习的方法来融合不同子网络的输出,以确保整个场景的一致性。实验结果表明,Switch-NeRF在重建大型场景方面具有高保真度和高效率,并在多个大规模数据集上取得了显著的性能提升。
-
Spatial Mixture-of-Experts
-
A Mixture-of-Expert Approach to RL-based Dialogue Management
-
Pluralistic Image Completion with Probabilistic Mixture-of-Experts
-
ST-ExpertNet: A Deep Expert Framework for Traffic Prediction
-
Build a Robust QA System with Transformer-based Mixture of Experts
-
Mixture of Experts for Biomedical Question Answering
-
Learning Large-scale Universal User Representation with Sparse Mixture of Experts
关注下方《学姐带你玩AI》🚀🚀🚀
回复“混合专家”获取全部论文合集
码字不易,欢迎大家点赞评论收藏
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringMVC之文件的下载
- K8S学习指南(56)-K8S核心组件Kube-Scheduler简介
- JS获取当前时间以及一个月前的时间
- GitLab服务器忘记root密码处理方式
- R语言【CoordinateCleaner】——cc_iucn():移除或标记所提供自然范围之外的记录(基于每个物种)
- 使用Python对音频进行特征提取
- 复盘理解/实验报告梳理 数据结构PTA实验二
- Java 报错java.Net.UnknownHostException:raw.githubusercontent.com
- 如何寻找到精准客源,企业名录篇
- 给 Linux 主机添加 SSH 双因子认证