初学python系列: pandas操作excel
发布时间:2024年01月21日
媳妇工作中经常用到excel处理,想用python处理excel更高效,所以自学了python,觉得python比Java还是简单多了,没有变量类型声明,比Java也就多了元组,各种库很丰富。
需求是: 汇总两个excel中?列,放到一个新的excel中,不允许有重复的列内容
代码编辑器:pycharm社区版本(根本不需要专业版,专业版很多功能用不到)
环境:conda(直接下载python也行,只不过需要pip下载很多库,这个conda默认包含很多库,只是减少了下载的麻烦)

为了演示方便,两个excel文件跟python脚本放到一起,两个excel内容都是产品、数量列,其中2.xlsx包含了1.xlsx中的内容

代码中引入pandas处理框架,读取2个excel的产品列内容,然后把内容放到一个列表里面,然后把列表赋值给一个新的excel,利用to_excel自动生成新的文档
import pandas as pd
df1 = pd.read_excel('1.xlsx')
df2 = pd.read_excel('2.xlsx')
result2=df2["产品"]
result1= df1["产品"]
my_list = []
for i in result1.values:
if i not in my_list:
my_list.append(i)
for i in result2.values:
if i not in my_list:
my_list.append(i)
data1={'产品':my_list}
df = pd.DataFrame(data1)
df.to_excel('zss2024.xlsx')调试代码如下

生成的新excel也会是在同级目录下
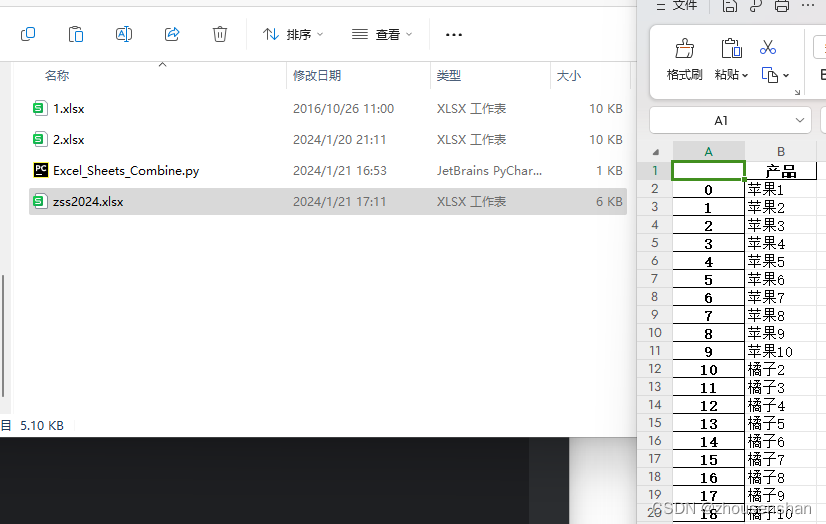
文章来源:https://blog.csdn.net/zhousenshan/article/details/135731637
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 用23种设计模式打造一个cocos creator的游戏框架----(二十)解析器模式
- Android自定义图片涂鸦View实现绘制和橡皮擦功能
- 120 填充每个节点的下一个右侧节点指针II
- 基于STM32单片机模拟智能电梯步进电机控制升降毕业设计3
- ASP.Net实现商品照片显示(三层架构)
- 电力电子技术
- 折半插入排序、冒泡排序、快速排序、简单选择排序、堆排序整理(介绍、原理、代码、时间复杂度)
- JMeter断言
- 医疗器械安规三项是什么?
- 2023年全国职业院校技能大赛网络系统管理 网络模块 出口配置