【深度学习:评估指标】如何在计算机视觉中测量模型性能:综合指南

正确评估机器学习模型的性能是开发生命周期中的关键步骤。通过使用正确的评估指标,机器学习工程师可以更深入地了解模型的优势和劣势,帮助他们不断微调和提高模型质量。
此外,更好地了解评估指标有助于比较不同的模型,以确定最适合给定业务案例的模型。
本综合指南将首先探讨不同的指标,以衡量分类、对象检测和分割模型的性能,以及它们的优点和局限性。在本文的最后,您将学习如何评估以为您的项目选择正确的指标。
在本指南中,我们将介绍以下方面的不同性能指标:
- Classification 分类
- Binary classification 二元分类
- Object detection 物体检测
- Segmentation 分割
【深度学习:评估指标】如何在计算机视觉中测量模型性能:综合指南
计算机视觉的分类
我们被计算机视觉、自然语言处理和语音识别等不同领域的分类模型所包围。虽然性能良好的模型将有良好的投资回报,但糟糕的模型可能会更糟,尤其是在应用于医疗保健等敏感领域时。
什么是分类?
分类是机器学习和计算机视觉中的一项基本任务。目标是根据输入(行、文本或图像)的特征将输入分配给有限数量的预定义类别或类之一。换句话说,分类旨在找到数据中的模式和关系,并利用这些知识来预测新的、看不见的数据点的类别。这种预测能力使分类成为各种应用中的宝贵工具,从垃圾邮件过滤和情感分析到医疗诊断和对象识别。
分类如何工作?
分类模型根据输入数据的特征(可以是输入数据的任何可测量属性或特征)来学习预测输入数据的类别。这些特征通常用高维空间中的向量来表示。
本节将介绍分类模型的不同评价指标,尤其关注二元分类模型。
分类模型评估指标
可以使用准确率、精确率、召回率、F1 分数和混淆矩阵等指标来评估分类模型。每个指标都有自己的优点和缺点,我们将进一步探讨。
Confusion matrix 混淆矩阵
混淆矩阵是 N x N 矩阵,其中 N 是分类任务中的标签数。N = 2 是二元分类问题,而 N > 2 是多类分类问题。该矩阵很好地总结了模型的正确预测数。此外,它还有助于计算不同的其他指标。
没有比将它们放入真实世界示例中更好的方法来理解技术概念了。让我们考虑以下场景,一家医疗保健公司旨在开发一个人工智能助手,该助手应该预测给定的患者是否怀孕。
这可以被视为二元分类任务,其中模型的预测将是:
- 1,如果患者怀孕,则为TRUE或YES
- 0,则为否 、FALSE 或 NO。
下面给出了使用此信息的混淆矩阵,并提供的值用于说明目的。

- FP 也被称为 I 型错误。
- FN 被称为第二类错误。
下图有助于更好地理解这两类错误的区别。

Accuracy 准确性
模型的准确性通过回答以下问题来获得:
在模型做出的所有预测中,正确分类的实例比例是多少?
计算公式如下:
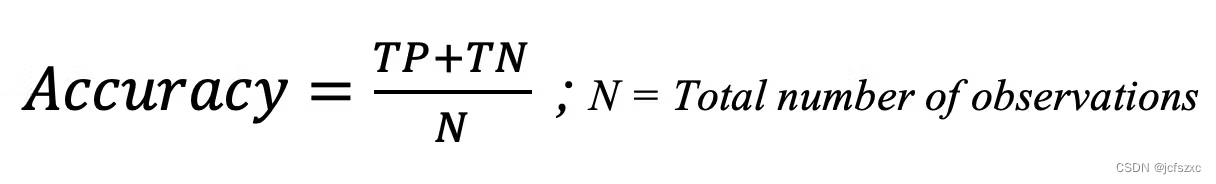
Accuracy = (66 + 34) / 109 = 91.74%
Advantages of Accuracy 准确性的优势
- 概念和公式都很容易理解。
- 适用于平衡数据集。
- 被广泛用作大多数分类任务的基准指标。
准确性的局限性
- 当用于不平衡数据时,会产生误导性结果,因为模型只需预测多数类就能达到很高的准确率。
- 为所有错误分配相同的成本,无论它们是误报还是漏报。
何时使用 Accuracy
- 当误报和漏报的成本大致相同时。
- 当真阳性和真阴性的好处大致相同时。
Precision 精度
精度计算的是在模型做出的所有正面预测中,真阳性预测所占的比例。
公式如下:

Precision = 66 / (66 + 4) = 94.28%
使用 Precision 的优点
- 对于最大限度地减少误报比例很有用。
- 使用精确度和召回率可以更好地理解模型的性能。
使用 Precision 的限制
- 不考虑假阴性。
- 与准确性类似,精度不太适合不平衡的数据集。
何时使用精度
- 当误报的成本远高于误报的成本时。
- 真正的阳性的好处比真正的阴性要高得多。
Recall 召回率
召回率是一种性能指标,用于衡量模型正确识别数据集中特定类的所有相关实例 (TP) 的能力。它的计算方式为真阳性与真阳性和假阴性(错过相关实例)之和的比率。
较高的召回率表明该模型可以有效地检测目标对象或模式,但它没有考虑误报(不正确的检测)。
这是召回率的公式:

在二元分类中,有两种类型的召回率:真阳性率(TPR)和假阴性率(FNR)。
真阳性率,也称为敏感性,衡量实际阳性样本被模型正确识别为阳性的比例。

召回率和灵敏度可以互换使用来指代相同的指标。然而,两者之间存在细微的差别。召回率是一个更通用的术语,指的是模型正确识别正样本的整体能力,无论模型使用的具体上下文如何。例如,召回率可用于评估模型在检测金融系统中的欺诈交易或识别医学图像中的癌细胞方面的性能。
另一方面,敏感性是一个更具体的术语,经常在医学检测中使用,指的是所有实际患有该疾病的个体中真阳性检测结果的比例。
假阴性率 (FNR) 衡量实际阳性样本被模型错误分类为阴性的比例。它是衡量模型正确识别负样本能力的指标。

特异性是衡量模型正确识别为阴性的实际阴性样本比例的指标。它是衡量模型正确识别负样本能力的指标。高特异性意味着模型善于将负样本正确分类,而低特异性意味着模型更容易将负样本错误地分类为正样本。

特异性是对召回率/敏感性的补充。敏感性和特异性共同提供了模型在二元分类中的性能的更完整的描述。

召回的优点
- 对于确定所有实际积极事件中真正积极事件的比例很有用。
- 更好地减少假阴性的数量。
召回的局限性
- 它只关注阳性事件的准确性,而忽略误报。
- 与准确性一样,在处理不平衡的训练数据时不应使用召回率。
何时使用召回
- 假阴性的成本远高于假阳性的成本。
- 真正阴性的成本比真正阳性的成本高得多。
F1-score F1分数
F1 分数是另一个结合了精度和召回率的性能指标,提供了模型在识别相关实例方面的有效性的平衡衡量标准,同时避免了误报。
它是精确率和召回率的调和平均值,确保两个指标得到同等考虑。
F1 分数越高,表明准确(精确度)和全面(召回)检测目标对象或模式之间取得了更好的平衡,这使得在误报和误报都很重要的场景以及处理不平衡数据集时评估模型非常有用
它被计算为精确率和召回率的调和平均值,以获得单个分数,其中 1 被认为是完美的,0 被认为是更差的。

F1 = (2 x 0.9428 x 0.9295) / (0.9428 + 0.9295) = 0.9361 or 93.61%
F1-Score 的优点
- 准确率和召回率都是需要考虑的重要因素。这就是 F1 分数发挥作用的地方。
- 在处理不平衡数据集时,这是一个很好的度量标准。
F1 分数的局限性
- 它假设精确率和召回率具有相同的权重,但在某些情况下并非如此。在某些情况下,精度可能很重要,反之亦然。
何时使用 F1-Score
- 当需要平衡精确率和召回率之间的权衡时,最好使用 F1-score。
- 当精度和召回率应该同等重要时,它是一个很好的选择。
二元分类模型评估指标
二元分类任务旨在将输入数据分类为两个互斥的类别。上面怀孕患者的例子是二元分类的完美例证。
除了前面提到的指标之外,AUC-ROC 还可以用于评估二元分类器的性能。
什么是 AUC-ROC?
前面的分类模型输出一个二进制值。然而,逻辑回归等分类模型会生成概率分数,并且最终预测是使用导致其混淆矩阵的概率阈值进行的。
等等,这是否意味着我们必须为每个阈值都有一个混淆矩阵?如果不是,我们如何比较不同的分类器?
个阈值都有一个混淆矩阵会是一种负担,而这正是 ROC AUC 曲线可以提供帮助的地方。
ROC-AUC 曲线是一种性能指标,用于衡量二元分类模型区分正类和负类的能力。 ROC 曲线绘制了不同阈值设置下 TP 率(敏感性)与 FP 率(1-特异性)的关系。
AUC 表示 ROC 曲线下的面积,提供单个值来指示分类器在所有阈值上的性能。 AUC 值越高(接近 1)表明模型越好,因为它可以有效地区分类别,而 AUC 值为 0.5 表明模型是随机分类器。
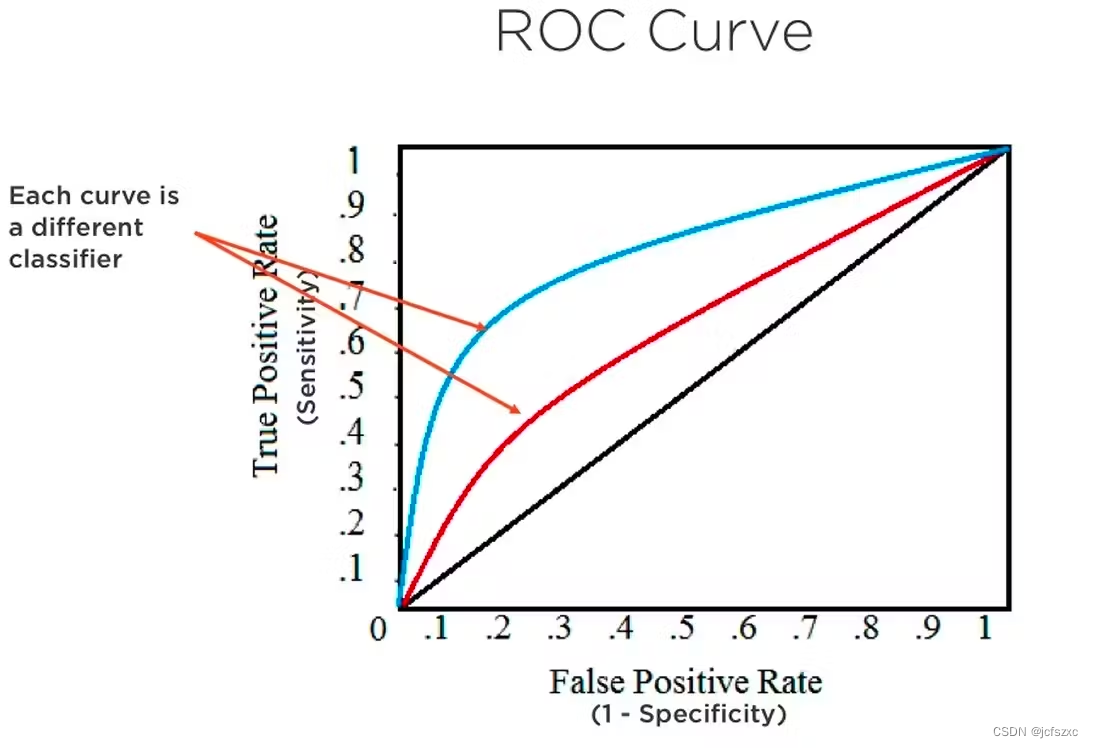
我们将曲线的每个点视为其混淆矩阵。此过程很好地概述了二元分类器的 TP 率和 FP 率之间的权衡。
由于 True Positive 和 False Positive 率都在 0 和 1 之间,因此 AUC 也在 0 和 1 之间,可以解释如下:
- 低于 0.5 的值意味着分类器较差。
- 0.5表示分类器随机进行分类。
- 当分数超过 0.7 时,分类器被认为是好的。
- 值为 0.8 表示强分类器。
- 最后,当模型成功分类所有内容时,得分为 1。
为了计算 AUC 分数,阳性类别(怀孕患者)的预测概率和每个观察的真实标签都必须可用。
让我们考虑一下上图中的蓝色和红色曲线,这是两个不同分类器的结果。蓝色曲线下方的面积大于红色曲线的面积,因此,蓝色分类器比红色分类器更好。
计算机视觉的目标检测
对象检测和分割越来越多地应用于各种现实生活应用中,例如机器人、监控系统和自动驾驶车辆。为了确保这些技术高效可靠,需要适当的评估指标。这对于在不同领域更广泛地采用这些技术至关重要。
本节重点介绍对象检测和分割的常见评估指标。
目标检测和分割都是计算机视觉中的关键任务。
但是,它们之间有什么区别呢?
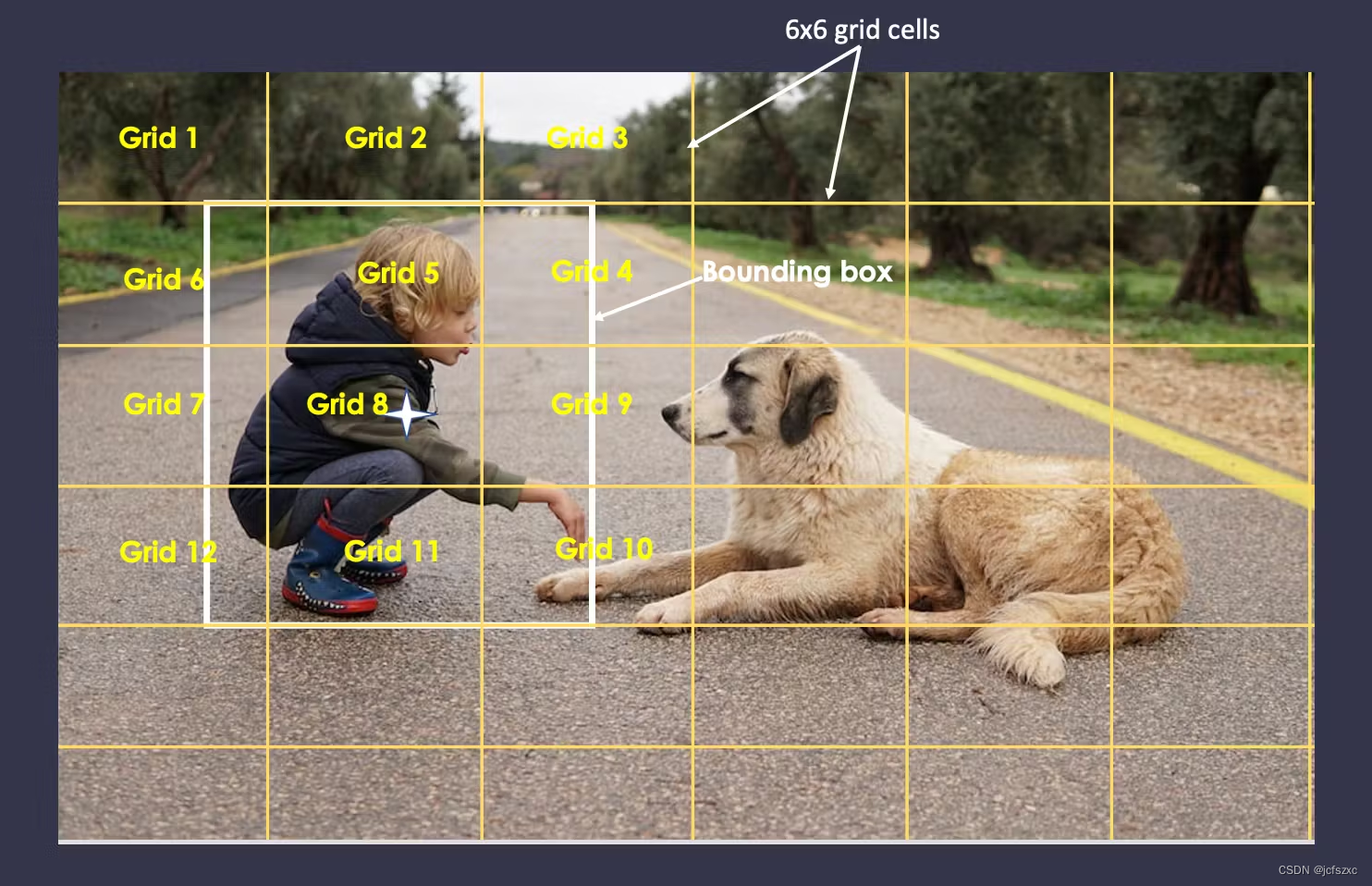
让我们考虑下图,以便更好地说明这两个概念之间的差异。

对象检测通常在分割之前进行,用于识别和定位图像或视频中的对象。定位是指使用对象周围的矩形(边界框)来查找一个或多个对象的正确位置。

一旦对象被识别和定位,接下来就是分割步骤,将图像分割成有意义的区域,其中图像中的每个像素都与一个类标签相关联,就像在上一个图像中,我们有两个标签:白色矩形和绿色矩形中的一只狗。

现在您已经了解了差异,让我们深入探讨这些指标。
目标检测模型评估指标
精度和召回率可用于评估二进制对象检测任务。但通常,我们会为两个以上的类别训练目标检测模型。因此,并集交集 (IoU) 和平均平均精度 (mAP) 是用于评估对象检测模型性能的两个常用指标。
联合交集 (IoU)
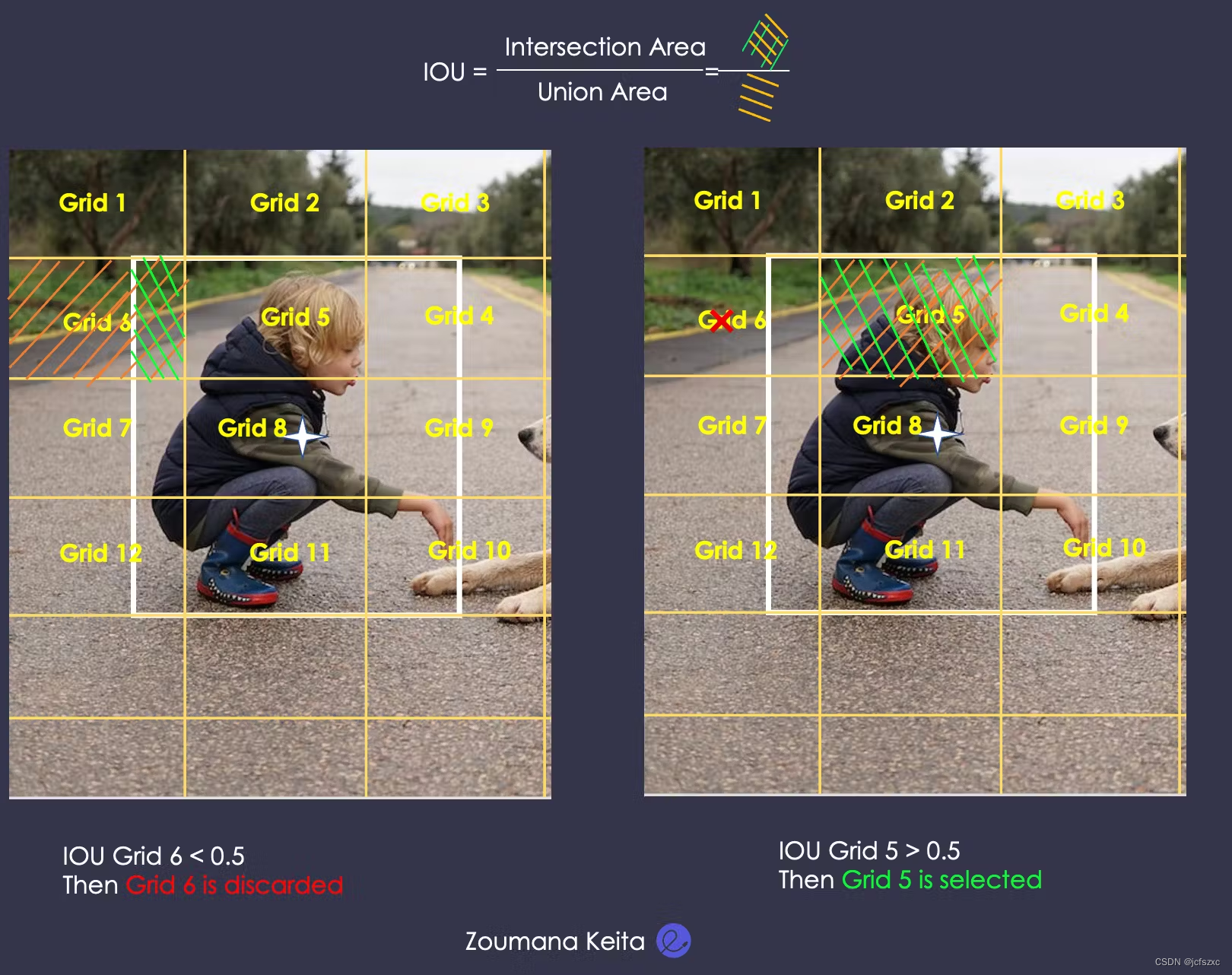
为了更好地理解 IoU,需要注意的是,对象识别过程从在原始图像上创建 NxN 网格(在我们的示例中为 6x6)开始。然后,其中一些网格比其他网格更有助于正确识别对象。这就是 IoU 发挥作用的地方。它的目的是识别最相关的网格并丢弃最不相关的网格。
从数学上讲,IoU 可以表示为:

其中交叉区域是给定类的预测掩模和地面实况掩模之间重叠的区域,联合区域是给定类的预测掩模和地面实况掩模两者包围的区域。
在这里,它对应于地面真实边界框和预测边界框在它们并集上的交集。让我们考虑一下检测到人员的情况。
- 首先定义真实边界框。
- 然后在中间阶段,模型预测边界框。
- IoU 是根据这些预测的边界框和真实情况计算的。
- 用户确定 IoU 选择阈值(例如 0.5)。
- 为了便于说明,让我们重点关注网格 6 和网格 5。选择 IoU 高于阈值的预测框或网格。在我们的示例中,选择了 5 号网格,而放弃了 6 号网格。对其余网格应用相同的分析。
- 之后,所有选定的网格都会连接起来,输出最终的预测边界框,即模型的输出。
Mean average precision (mAP) 平均精度 (mAP)
mAP 计算对象每个类别的平均精度 (mAP),然后取所有 AP 值的平均值。 AP 是通过绘制特定对象类的精确召回曲线并计算 AUC 来计算的。它用于衡量检测模型的整体性能。它考虑了精度和召回值。 mAP 的范围是从 0 到 1。mAP 值越高意味着性能越好。
mAP 的计算需要以下子指标:
- IoU
- 模型精度
- AP
这次,让我们考虑一个不同的示例,其目标是从图像中检测球。
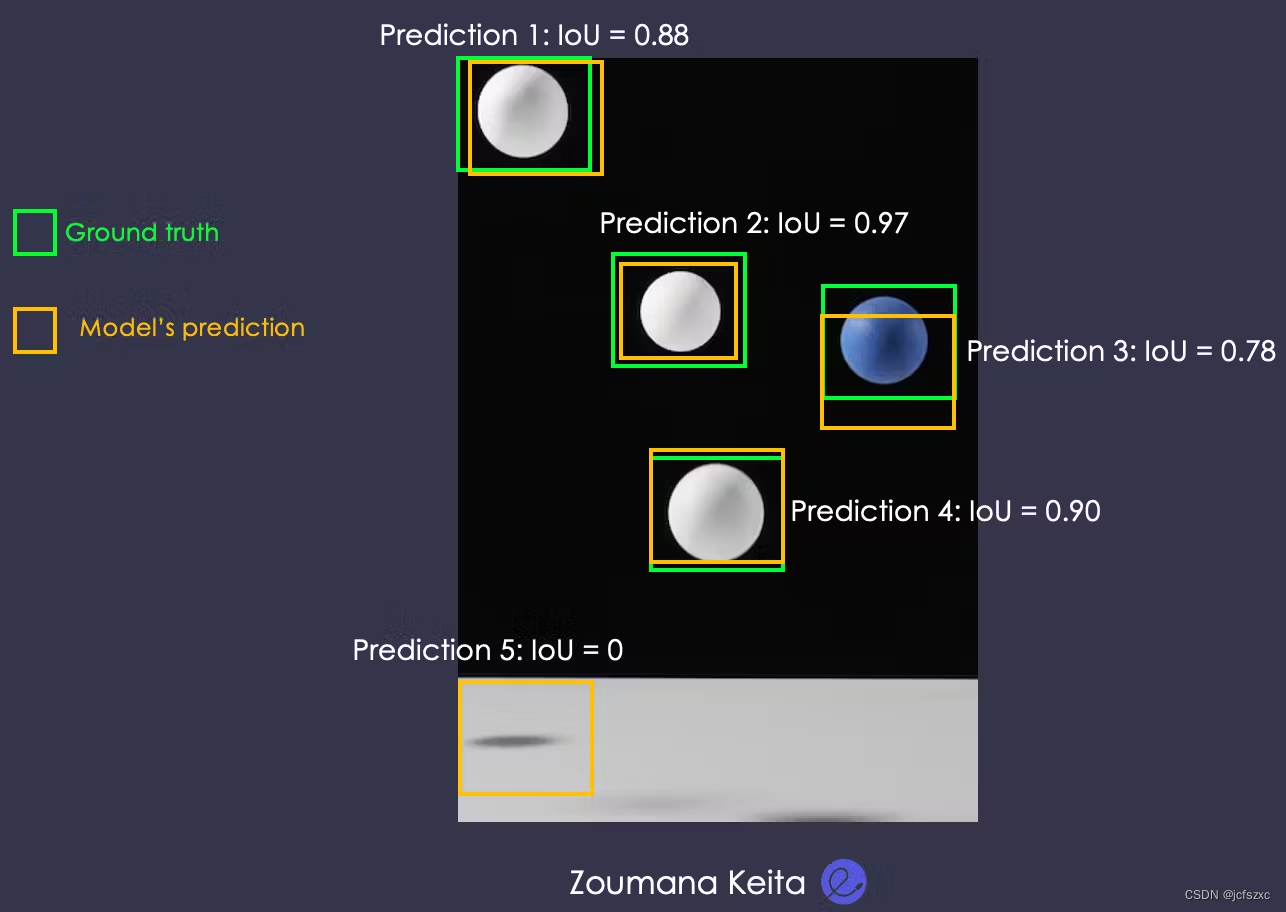
阈值水平为 IoU = 0.5 时,将从 5 个球中选择 4 个;因此精度变为 4/5 = 0.8。但是,当阈值为 IoU = 0.8 时,模型将忽略第 3 个预测。 只有 3 个会选择 5 个。因此精度变为 3/5 = 0.6。
那么,问题是:
为什么知道模型正确预测了两个阈值的 5 个球中的 4 个球,精度会降低?
只考虑一个阈值会导致信息丢失,而这正是平均精度的用武之地。AP的计算涉及的步骤:
- 对于每类对象,模型输出预测的边界框及其相应的置信度分数。
- 预测的边界框将与图像中该类的实况边界框进行匹配,使用重叠度量,例如交集大于并集 (IoU)。
- 计算匹配边界框的精度和召回率。
- AP 是通过计算每个类的精确召回曲线下的面积来计算的/它可以在数学上写成:

例如,让我们考虑一张包含行人、汽车和树木的图像。在哪里:
- AP(Pedestrians) = 0.8 AP(行人)= 0.8
- AP(Cars) = 0.9 AP(汽车)= 0.9
- AP(Trees) = 0.6 AP(树木)= 0.6
然后:
mAP = (?) 。 (0.8 + 0.9 + 0.6) = 0.76,这对应于良好的检测模型。
计算机视觉的分割模型评估指标
细分模型的评价指标为:
- Pixel accuracy 像素精度
- Mean intersection over union (mIoU) 并集的平均交集
- (mIoU) Dice coefficient Dice 系数
- Pixel-wise Cross Entropy 逐像素交叉熵
Pixel accuracy 像素精度
像素精度报告正确分类的像素占图像中像素总数的比例。这为模型在对每个像素进行分类时的性能提供了更定量的衡量。

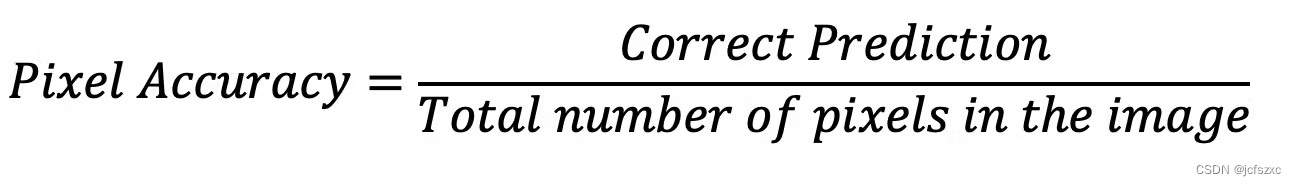
- 图像中的总像素 = 5 x 5 = 25
- 正确预测 = 5 + 4 + 4 + 5 + 5 = 23
那么,准确率 = 23 / 25 = 92%
像素精度直观且易于理解和计算。然而,在处理不平衡数据时,它的效率并不高。此外,它没有考虑分割区域的空间结构。使用 IoU、平均 IoU 和骰子系数可以帮助解决这个问题。
联合平均交集 (mIoU)
平均 IoU 或简称 mIoU 是通过多类分割任务中图像中所有类的 IoU 值的平均值来计算的。与像素精度相比,这更加稳健,因为它确保每个类别的性能对最终分数有相同的贡献。该指标同时考虑了误报和漏报,使其成为比像素精度更全面的模型性能衡量标准。
平均 IoU 介于 0 和 1 之间。
- 值为 1 表示预测分割和地面实况分割之间完美重叠。
- 值为 0 表示没有重叠。
让我们考虑前两个分割掩码来说明平均 IoU 的计算。
- 我们首先确定类的数量,在我们的示例中有两个:
- 使用以下公式计算每个类别的 IoU,其中:

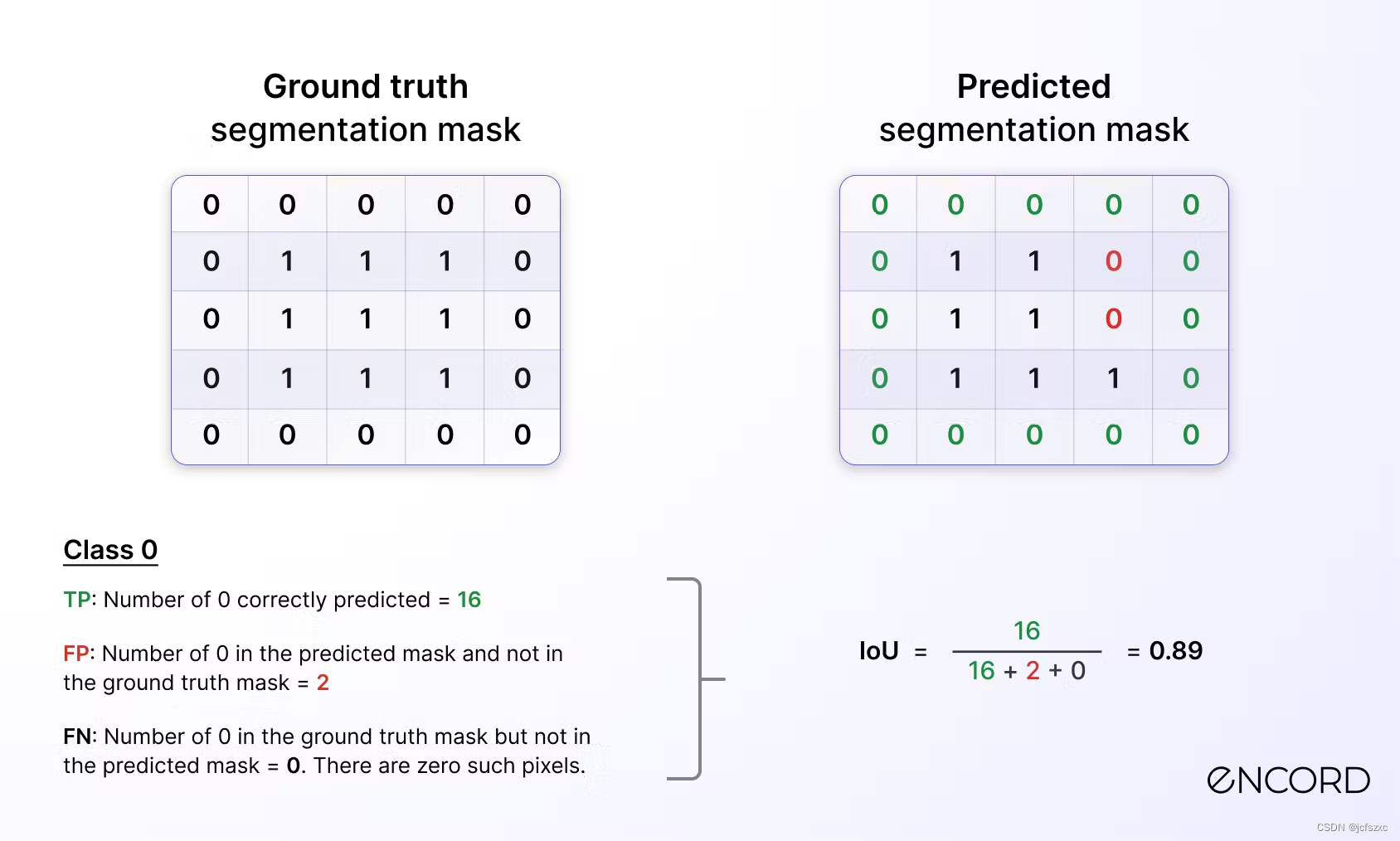
- 对于 0 类,详细信息如下:
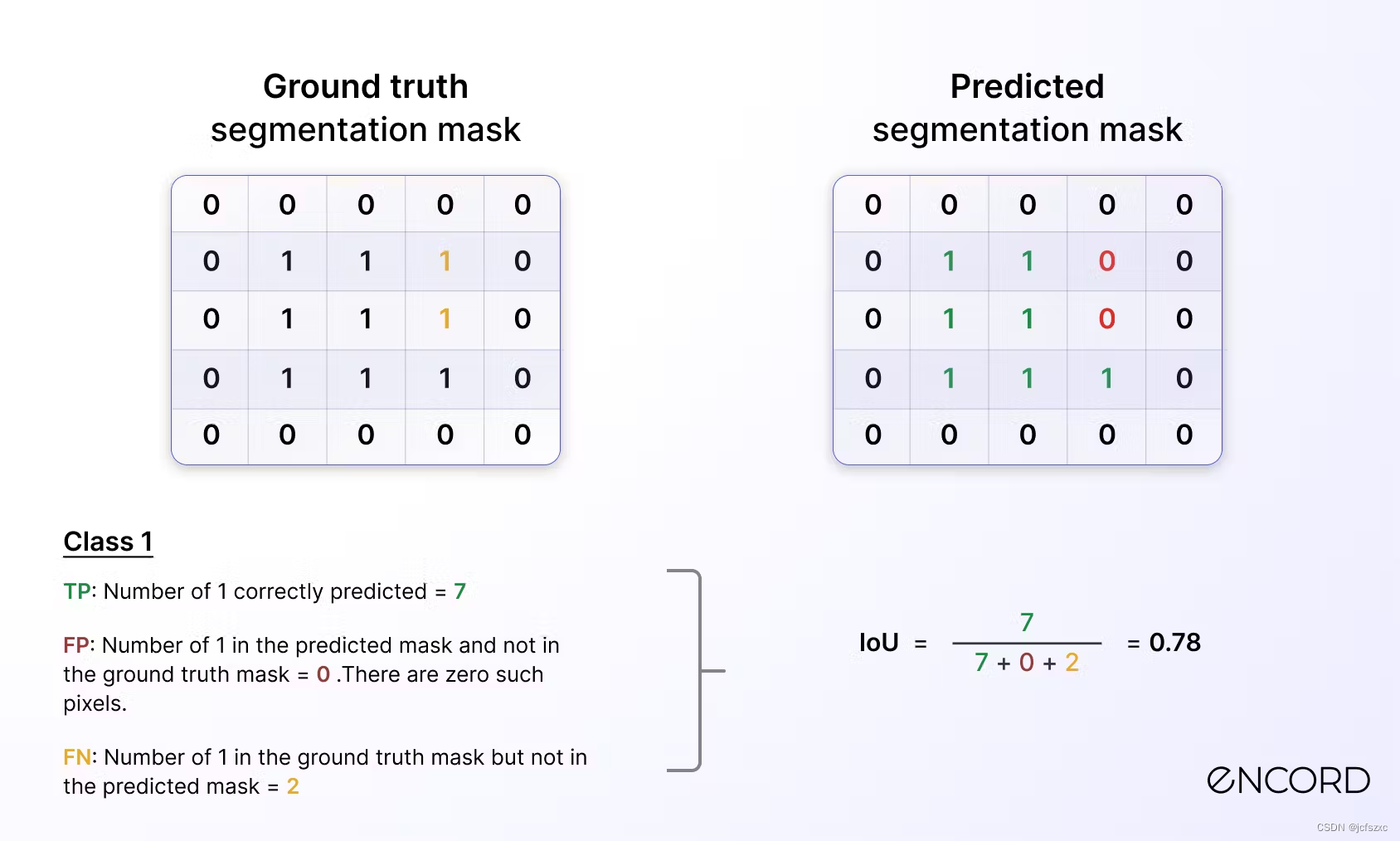
- 对于 1 类,详细信息如下:
- 最后,使用下面的公式计算平均 IoU,其中 n 是标签总数:
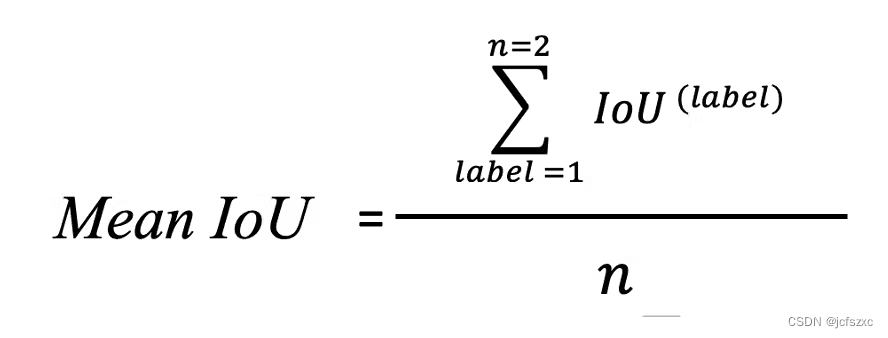
最终结果为Mean IoU = (0.89 + 0.78) / 2 = 0.82
Dice Coefficient Dice 系数
Dice 系数可以考虑用于图像分割,就像 F1 分数用于分类任务一样。它用于测量预测分割与地面实况之间重叠的相似度。
当处理不平衡的数据集或空间一致性很重要时,此指标非常有用。 Dice系数的取值范围是0到1,0表示没有重叠,1表示完全重叠。
下面是计算Dice系数的公式:

- Pred 是模型预测的集合
- GT 是基本事实的集合。
现在您已经更好地了解了Dice 系数是什么,让我们使用上面的两个分割掩码来计算它。
首先,计算逐元素乘积(交集):
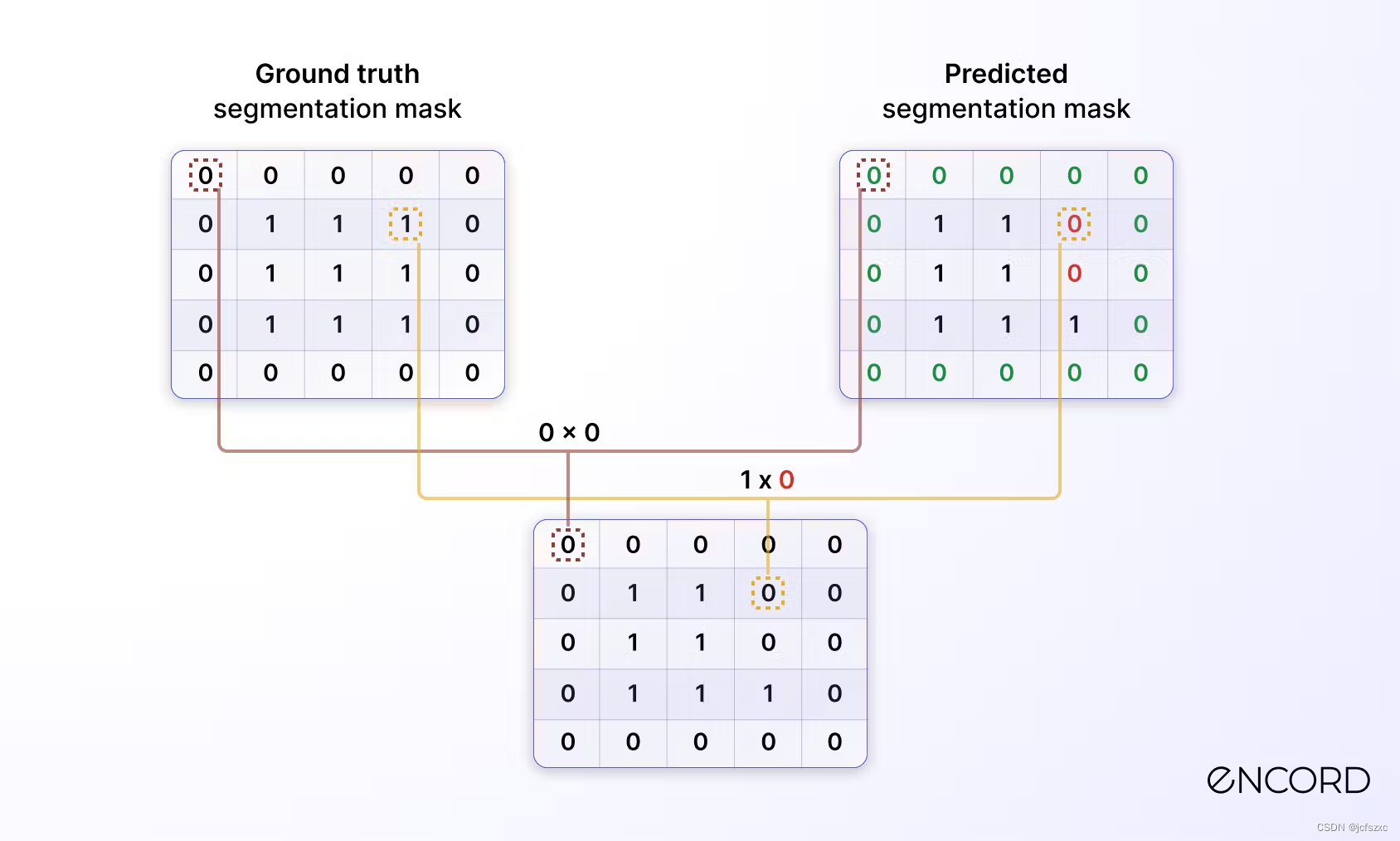
然后,计算之前生成的矩阵中的元素之和,结果为7。

对标签真值和预测结果执行相同的总和计算。

最后,根据上述所有分数计算 Dice 系数。
Dice = 2 x 7 / (9 + 7) = 0.875
Dice 系数与 IoU 非常相似。它们是正相关的。要了解它们之间的区别,请阅读以下关于 dice-score 与 IoU 的堆栈交换答案。
Pixel-wise Cross Entropy 逐像素交叉熵
像素交叉熵是图像分割模型常用的评估指标。它测量像素标签的预测概率分布和真实分布之间的差异。
从数学上讲,像素级交叉熵可以表示为:

其中N是图像中的像素总数,y(i,j)是像素(i,j)的groundtruth标签,p(i,j)是像素(i,j)的预测概率。
像素级交叉熵损失会惩罚做出错误预测的模型,并奖励做出正确预测的模型。交叉熵损失越低表明分割模型的性能越好,0 是最佳可能值。
像素交叉熵通常与并集平均交集结合使用,以提供对分割模型性能的更全面的评估。
Wrapping up . . .
通过本文,您了解了用于评估计算机视觉模型的不同指标,例如平均精度、并集交集、像素精度、并集平均交集和Dice系数。
每个指标都有自己的优点和缺点;选择正确的指标对于帮助您在评估和改进新的和现有的人工智能模型方面做出明智的决策至关重要。
计算机视觉模型性能常见问题解答
为什么模型的性能很重要?
模型性能不佳可能会导致企业做出错误的决策,从而导致投资回报不佳。更好的性能可以确保依赖于模型预测的应用程序的有效性。
使用哪些指标来评估模型的性能?
有几个指标用于评估模型的性能,每个指标都有其优点和缺点。
准确率、召回率、精确率、F1 分数和接收器操作特征曲线下面积 (AUC-ROC) 通常用于分类。而均方误差 (MSE)、平均绝对误差 (MAE)、均方根误差 (RMSE) 和 R 平方则用于回归任务。
哪些模型性能指标适合衡量模型的成功?
这个问题的答案取决于要解决的问题以及底层数据集。可以根据用例考虑上述所有指标。
准确性如何影响模型的性能?
准确性很容易理解,但在处理不平衡数据集时不应将其用作评估指标。结果可能会产生误导,因为模型始终会在推理模式下预测多数类。
绩效指标是如何计算的?
使用不同的方法来计算性能指标,上面的文章介绍了分类、图像检测和分割的主要方法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 宏景eHR fileDownLoad SQL注入漏洞复现
- 重生奇迹mu翅膀合成
- 关于黑客攻击
- 负载均衡-Feign
- jvm参数配置
- 如何使用PR制作抖音视频?抖音短视频创作素材剪辑模板PR项目工程文件
- 免 费 搭 建 多模式商城:b2b2c、o2o、直播带货一网打尽
- 目标检测数据集 - 猫狗检测数据集下载「包含VOC、COCO、YOLO三种格式」
- 华为云Stack 8.X流量模型分析(三)
- 如何计算JMeter性能和稳定性测试中的TPS?