51-7 CLIP,Contrastive Language-Image Pre-training 论文精读
今天我们一起来读一篇来自OpenAI的CLIP工作。原文Learning Transferable Visual Models From Natural Language Supervision,简称CLIP,Contrastive Language-Image Pre-training。自从2021年2月底提出,就立马火爆全场,他的方法出奇的简单,但是效果又出奇的好,很多结果和结论都让人瞠目结舌。
比如,作者说CLIP的这个迁移学习能力是非常强的。
CLIP预训练好后,能够在任意一个视觉分类数据集上取得不错的效果,而且最重要的是zero shot,意思就是说他完全没有在这些数据集上去做训练,就能得到很高的效果。
作者做了超级多的实验,他们在超过30个数据集上做了测试,涵盖的面也非常广,包括了OCR,包括视频动作检测,还有就是坐标定位和许多细分类任务。
在所有这些结果之中,其中最炸裂的一条就是在ImageNet上的这个结果了,CLIP在不使用ImageNet训练集的情况下,也就是不使用128万张图片中任何一张训练的情况下,直接zero shot做推理就能获得和之前有监督训练好的这个ResNet-50取得同样的效果。
就在CLIP这篇工作出来之前,很多人都认为这是不可能的事情。
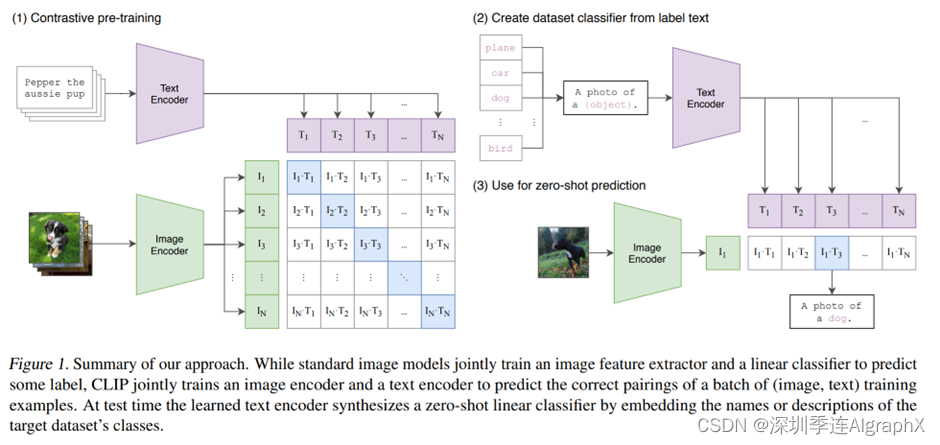
到底他是怎么去做这个zero的推理的,我们现在直接就来看文章的图一,也就是CLIP的这个模型总览图。
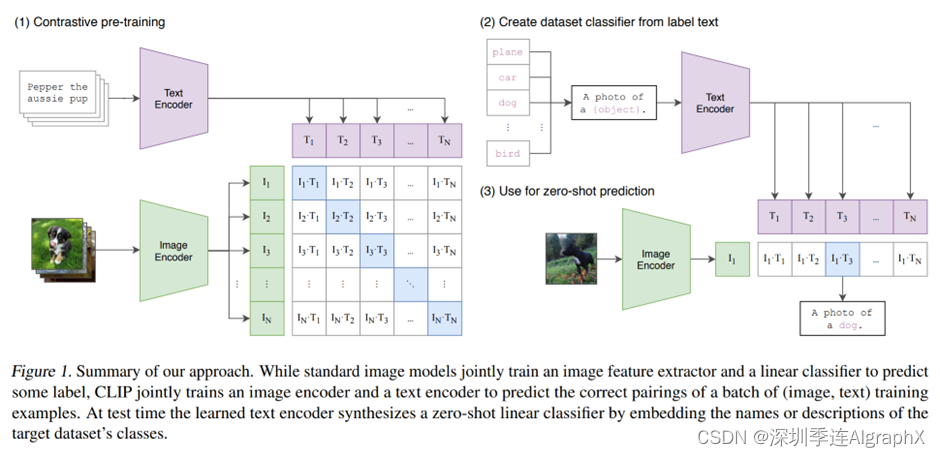
我们这里,就是先大概说一下它的流程,具体的细节,后面还会讲到。
首先,CLIP是如何进行预训练的?我们通过这个题目Learning Transferable Visual Models From Natural Language Supervision,也可以大概猜到一二。题目的意思是说,通过这个自然语言处理这边来的一些监督信号,我们可以去训练一个可以迁移效果很好的视觉模型。
所以很自然的,这是一个牵扯文字图片的一个多模态的工作。
那他是怎么去利用这个自然语言处理来的这个监督信号?
那其实在训练的过程中,模型的输入是一个图片和文字的配对。
比如这里,图片里画的是一只狗,配对的文字?也就是说pepper,是一只小狗。
然后图片,就通过了一个图片的编码器,从而得到了一些特征,这里的编码器,既可以是个ResNet,也可以是个Vision Transformer。
对于这个句子来说,它也会通过一个文本的编码器,从而得到一些文本的特征。
假设说我现在每个training batch里都有N个这样的图片文本对。也就是说,这里有N张图片,这里有N个句子。我们就会得到N个这种图片的特征,还有N个这样文本的特征。
然后CLIP就在这些特征上去做对比学习。
我们之前也提过,对比学习非常的灵活,它需要什么?它只需要一个正样本和负样本的定义,其他都是正常套路。
那这里什么是正样本,什么是负样本?
其实再明确不过了,就是这样配对的一个图片文本,它就是一个正样本,因为它描述的是一个东西。
所以说在这个特征矩阵里,沿着这个对角线方向上的都是正样本,因为i1T1,i2T2这些本身就都是配对的。

剩下这个矩阵里所有不是对角线上的元素就都是负样本,也就是说,我们有n个这个正样本,然后有n^2-n个负样本。
一旦有了正负样本,模型就可以通过对比学习的方式去训练起来,完全不需要任何手工的标注。
当然了,对于这种无监督的预训练方式,比如说对比学习,它是需要大量的数据的。
?
OpenAI专门去收集了一个数据集,它里面有4亿个图片文本配对,而且这个数据,清理的非常好,质量应该非常高。这也是CLIP这个预训练模型为什么能这么强大的主要原因之一。
接下来就是说如何去做zero shot推理,这部分,是非常有意思的。
因为CLIP这个模型经过训练之后,它其实只能去得到一些视觉上和文本上的这些特征。
他并没有在任何分类的任务上去做继续的这种训练或者微调,所以说它是没有分类头的。
如果没有分类头,怎么去做推理?
作者想出一个利用自然语言的一种巧妙方法。
也叫prompt template。
我们这里先拿ImageNet做个例子,就是先把ImageNet里1000个类,比如说这里的这个飞机、汽车、狗,变成这么一个句子。

也就是用这里的这些物体,去替代这里的这个object。
也就是说把一个单词,比如说飞机变成了这么一个句子,这是一张飞机的图片,那像ImageNet有1000个类,那其实这里,就生成了1000个句子。
然后这1000个句子,通过我们之前预训练好的这个文本编码器,就会得到1000个这个文本的特征。
那我们为什么要做这么一个prompt template?
其实直接用这里的这些单词,去抽取这种文本的特征也是可以的。
但是,因为你在模型预训练的时候,图片每次对应的基本都是一个句子。
如果你在推理的时候,突然把所有的这个文本,都变成了一个单词,那这样就跟你在训练的时候看到的这个文本就不太一样了,所以效果就会稍有下降。
而且怎么变成这边这个句子也是很有讲究的,所以这篇论文后面,还提出了prompt engineering,prompt ensemble这两种方式去进一步的提高这个模型的准确率。而不需要重新训练这个模型。
然后在推理的时候,不论任何一张照片,只要把这张照片扔给这个图片编码器,得到了这个图片特征之后,拿这个图片的特征去跟所有的这些文本的特征去做这个similarity,算这么一个相似性。
那最后?这个图像的特征跟这里的哪个文本特征最相似?
我们就把这个文本特征所对应的那个句子挑出来,从而完成了分类这个任务,也就是说这张图片里有狗这个物体,是不是非常的巧妙?
而且,其实当CLIP真正使用的时候。这里的这些标签,其实还是可以改的,它不光是ImageNet这1000个类,咱们可以换成任何的单词,这里的图片,也不需要是ImageNet里的图片,它也可以是任何的图片,然后依旧可以通过这种算相似度的方式去判断出这张图片里到底含有哪些物体。
比如说,这里给一张三轮车的照片,然后在上面的这个类别里,也加上三轮车这个类别。
那通过的这种zero shot推理的方式?很有可能这张图片就能正确的被分类成三轮车。
但如果像之前那种严格按照1000类去训练的这个分类头来说的话,那我们的模型,永远都不会判断出这张图片是三轮车。
最多也就是把它判断成是车或者是自行车这种在ImageNet这1000个类里的类别,而且跟三轮车最接近的类。
这个性质,才是CLIP的强大之处,也是CLIP这个模型最吸引人的地方。
因为它彻底摆脱了categorical label的这个限制。
也就是说,不论是在训练的时候,还是在推理的时候。
我都不需要有这么一个提前定好一个标签列表了。
任意给我一张照片,我都可以通过给模型去找这种不同的文本句子,从而知道这张图片里到底有没有我感兴趣的物体。
而且,CLIP不光是能识别新的物体。
由于他真的把这个视觉的这个语义和文字的语义联系到了一起。
所以他学到这个特征,语义性非常强,迁移的效果也非常的好。
?

譬如换到素描画的时候,或者这种对抗性样本的时候,一般算法准确度直接从70多掉到20多,甚至到对抗性的这种2.7,基本上就已经是在随机猜了,迁移的效果是惨不忍睹。
但是对于CLIP训练出来的模型来说?
它的这个效果,始终都非常的高,没有什么下降。
这也就从侧面说明了因为和自然语言处理的结合,所以导致CLIP学出来的这个视觉特征,和我们用语言所描述的某个物体,已经产生了强烈的联系。
比如说香蕉,不论是在这种自然图像里出现的香蕉,还是这种动漫里的香蕉,还是说这种素描的香蕉,或者是加过对抗性样本的香蕉。CLIP训练出来的模型,都知道它对应的是香蕉这个单词。
当然文章里,还做了很多其他分类的任务,以及数据集迁移的效果,都非趁好这里,我们先暂时不说分类了,我们去看一些其他基于CLIP的有趣的应用。
首先一个很有意思的工作就是这个StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
那从名字一看?很显然这就是一个CLIP加上的一篇工作。
文章的意思,就是想通过这种文字上的改变,从而去引导图像的这种生成。它通过改变不同的这个文字输入,就能改变生成的这个图像的各种属性。

比如说这里,原来的图片是奥巴马的图片。然后给它加上文字的这种指示以后,他就把这个发型就变了。
还有这里,本来是Taylor Swift的照片,这里的文字指示是说,去掉这个化妆,然后就直接一键卸妆了。
这里的这个猫,本来眼睛是闭上的,这里写出cute,变得更可爱一点,所以这个眼睛一下就变大了,这篇论文的效果,也确实非常好。
然后还有一篇论文叫CLIPDraw,也是利用CLIP预训练模型指导图像的生成。
CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders
除了去做这种图像生成的任务,CLIP肯定还能用来做更多的任务,物体检测和分割,这两个主流任务肯定是跑不掉。
所以在CLIP出来之后,很快也就是一个半月左右吧,Google,就出了一篇利用CLIP去做这个物体检测的工作。
当然这里的细节,我就不细讲了,我们可以来看一下它的这个效果怎么样,那作者这里说,如果你是用传统的这种目标检测的方法去做预测的话。
他可能只能告诉你这些都是玩具。
也就是这里他所说的蓝色的,这种基础类。
但是当你利用了这种自然语言之后。
你就摆脱了基础类的这个限制,你就可以随意发挥了。
也就他们这里说的这个open vocabulary。
所以他们训练出来的模型,就可以检测出这些新的类,也就是红色的这些类
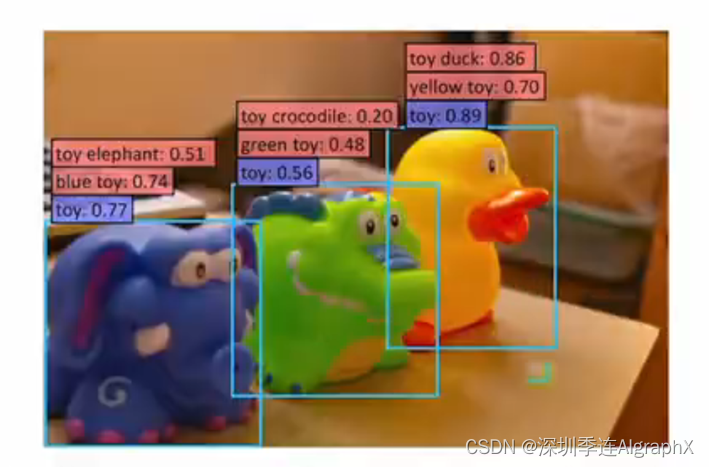
比如说,它不光可以知道这些玩具的颜色,这蓝色的玩具,绿色的玩具,同时,他还知道这些玩具具体所代表的这个物体类别,比如说这是一个玩具大象,这是一个玩具鳄鱼,这是一个玩具鸭子。
所以说你能得到的这个输出,一下就丰富了不少。
最后,我想再提一个基于CLIP的例子,是用来做视频检索的。
他的意思是说,如果现在给定你一个视频,然后你想去搜这个视频里到底有没有出现过这个物体,出现过这个人,或者说出现过医学场景,那你就可以通过直接输入文本的这种形式去做检索。
文字输入说去找一辆白色的这个宝马车,然后他也能准确的去找一辆这个白色的宝马车。
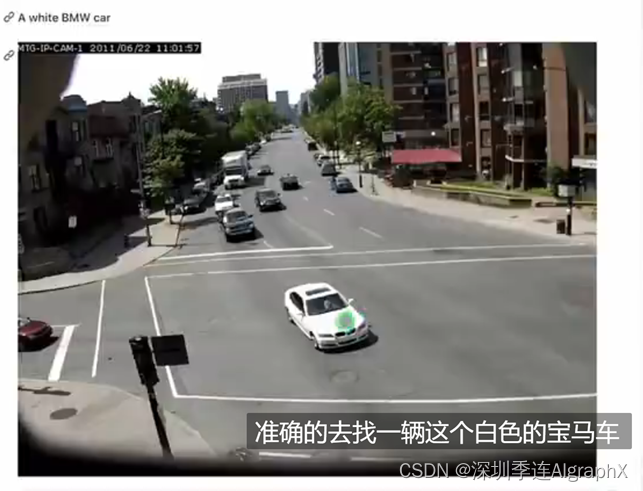
至于这个是凑巧,还是说CLIP这个模型真的已经知道宝马车的车头是长这样,那这个就不得而知了,但确实也是检索出来了。
当然了,作者这里只是把这些成功的例子展现出来,我相信肯定是有很多不成功的例子,但这个结果,还是比较令人不安的。
作者团队,应该也意识到了这一点,所以在他们的论文里,他们还专门有一段针对这个监控视频的这个讨论。
当然了,CLIP还有很多好玩的应用,而且还有很多很好的这个后续工作,我这里就不一一列举了。
首先我们来看一下CLIP这篇论文的整架构,CLIP这篇论文有48页。正文,也有30多页,其中大部分的篇幅,都是留给了实验和和相应的一些分析。
所以咱们一般先读摘要、再读结论和讨论,最后才开始读正文。
正文精读
接下来,我们开始精读CLIP这篇论文。
首先,题目是说利用自然语言的这种监督信号去学习一个迁移性能好的视觉网络,那这里,其实就是两个关键词,一个就是这个迁移性能好,可以迁移的,另外一个,就是利用这个自然语言的监督信号。
所以怎么去利用自然语言的这个监督信号?就是这篇论文的贡献所在,然后至于他想达到的目的,主要就是这个迁移性。
他,真的就是想去学一个这个泛化性非常的特征,从而能在各种数据集或者各种任务上能够不需要训练直接推理都能获得不错的效果。
作者团队,全部来自OpenAI,这里面,有12个作者。
但其实对于这种工作,做了这么多实验,刷了这么多数据集,而且光论文就写了48页,12个人,其实并不多,论文后面,还致谢了很多很多人。
?
1 Abstract摘要
那接下来,我们一起来读一下摘要部分。
文章说,现在最先进的这种视觉系统,它是怎么训练的?它都是先有这么一个固定的一个提前已经定义好的一些物体类别的集合。
然后模型通过去预测这些提前定义好的类别,从而完成模型的训练。这个固定的提前定义好的这个标签集合怎么理解?其实就是说ImageNet,它有固定的1000个类,不多不少。
CAR10 10个类,目标检测COCO 80个类,语言分割19个类,视频400个类。
总之,为了简单起见,不光是收集数据集的简单性,还是说从模型训练的简单性来说。
直接定义这么一个固定的提前定义好的这个标签集合,会大大的简化这个问题本身。
但是,也因为采用了这种有限制性的这种监督信号,从而也限制了模型本身的这个泛化性,尤其是当你需要去识别新物体类别的时候该怎么办?那对于这些新的类别,难道每次都要去收集新的数据,然后重头训练一个新的模型吗?
这样就很有局限性,就不好了,就不好做大做强了。
所以说,作者就想到了另外一种方式,也就是他这里说的,直接从自然语言这边,从这个文本里去得到一些监督信号,是一个看起来非常有前途的办法。
因为它的这个监督信号涵盖的范围就太广了,只要是你语言描述过的物体,你就有可能让你这个视觉模型去识别到这个物体,而不仅仅是你提前定义好的那1000个类。
然后作者接下来说,他们其实已经证实了,就是用一个非常简单的一个预训练的任务。
又可以非常高效的而且可扩展的去学习一些最好的这个图像的表征。
这个任务具体是什么?其实就是说给定你一张图片,然后又给定你一些句子。
然后这时候模型,需要去判断哪一个句子,跟这个图片是配对的。
既然要做这么一个配对的任务,那当然就需要这么一个类似的数据集了,也就是说你的训练样本,必须是一个图片文字的配对。
所以说文章的作者又去爬了一个超级大的,有四个亿的这个图片文本配对的数据集。
有了这么大的一个数据集之后,我们就可以选择一种自监督的训练方式去去训练一个大模型出来了。
在CLIP这篇文章,我们之前也提过,它是用多模态的对比学习去完成模型训练的,那在这个预训练完成之后,自然语言就被用来去引导这个视觉模型去做物体的分类,也就是我们之前说过的这个prompt,然后分类,也不光局限于已经学到的这种视觉的这个概念,它还能扩展到新的类别。
从而说你现在学到的这个模型,是能够直接在下游任务上去做这种zero shot的推理的。
那为了验证这个模型的有效性,作者接下来就在超过30个不同的这个视觉的任务和数据集上去做了这个测试。
然后作者发现,这个模型的迁移学习效果,就是说对大多数任务来说,它的效果都是非常好的。CLIP模型,在不需要任何数据集的这种专门训练的情况下,能和之前一个完全用有监督方式训练出来的模型打赢手,甚至还会更高。
那为了让摘要看起来更具吸引力,所以说作者就在这里举了一个ImageNet上兵家必争之地上的这个效果。
CLIP模型在不使用任何一张那128万个训练集的情况下,能跟之前一个有监督训练好的ResNet-50打成平手。
这个结果在当时读起来,是非常震惊的,已经足够吸引读者去读完整篇论文了。
最后作者说他们预训练好的模型,和他们的代码,都放到了这个链接里。
但其实这里的代码,只是可以用来做推理。OpenAI,并没有开源它真正的这个预训练的代码,但好在是他们开源了预训练的模型,所以像我们刚开始介绍过的一样,很快又激发了一系列好玩又有用的工作。
?
2 Introduce引言
那接下来我们一起读文章的引言部分。
文章一开始说,直接从这种原始的文本数据里去训练一个模型,已经在过去几年里,在NLP领域取得了革命性的成功,比如说GPT3.5这些模型。
那不论你是使用自回归预测的方式,还是使用这种掩码完形填空的方式,它都是一种自监督的训练方式。
所以说它的目标函数是跟你的下游任务无关的,它只是想通过预训练得到一个非常能泛化的特征,那随着计算资源的增多,模型变大,还有数据变得更多。这个模型的能力,也会稳健的提升,那这套系统,说白了其实就是说文字进,文字出,它并不是在做一个什么特殊的分类任务,它的这个模型架构也是跟下游任务无关的。
所以说当直接用在这种下游任务上的时候,我们就不需要费尽心思去研究一个针对那个任务的输出头,或者说针对那个数据集的特殊的一些处理了。
那这里面最厉害的,最耳熟能详的模型?也就是openAI自己的这个GPT3。
他也能够做分类,做翻译,还能帮你写邮件,写小说,写新闻,简直看起来是无所不能,而且在大多数任务上,它并不需要特定领域的这个数据,或者说只需要一点点的这个数据去做一点微调,就可以和之前精心设计过的那些网络,取得差不多的结果。
作者接下说,利用自监督的信号去训练整个模型的框架下,这种大规模,没有标注的数据,其实是要比那些手工标注的,质量非常高的那种数据集反而是要更好使的。
但是,在视觉领域,大家一般的做法,还是在image这种数据集上,去训练一个模型。
这就会让训练好的模型有诸多的限制,那CLIP这套框架到底能不能用在视觉里?那作者说,从之前的工作看起来应该是没问题。
然后接下来,作者就讨论了一下之前的工作。有了transformer,有了对比学习原形填空这种强大的自监督训练方式之后,最近也有一些工作,尝试把这个图片和文字结合起来,去学得一个更好的特征。
然后作者反思了一下,既然利用这个自然语言那边的这个监督信号是一个很有前途的方向,那为什么在视觉里这一系列的工作就这么少?
那其实,可能还是跟这个圈子文化有关系。
就是这里说,因为之前的那些方法,没有这么大的数据集,没有这么多的算力,没有这么大的模型,没有这么好的自监督训练的方式,对它在标准的这个测试数据集上,比如说ImageNet上的这个效果,就非常的差,比如我们刚才说的这个工作,它在的这种设定下,就只有11.5的这个准确率。
但是在ImageNet上,之前最好的表现方法,都已经88.4了,而且就算是不用deep learning这传统的视觉方法,它的准确度也有50的准确度。
当然这里的对比并不公平,因为这88.4,还有这50都是有监督的训练,但是这里的这个11.5,是zero shot的,但因为效果实在太低,所以说没有实用的价值。
大家去钻研这个方向的热情,就会小很多,取而代之,另一系列的工作就非常受人关注,就是说怎么去利用这种更弱的这种监督信号。
所以之前这个工作,他就提出了一个新的预训练的任务,也就是说他收集了一个Instagram的数据集,然后他去预测这个图片自身带的这些Hash Tags,那通过这种方法,你的数据集就可以变得非常大。
因为每张图片都会自带一些Hash Tags,你不用去人工的标注,同时,你这些Hash Tags也就可以想象成是一种自然语言的一种监读型号。
它也是一个或者几个单词,它是有明确的语义含义的。
然后另外还有一些工作,比如说这两篇工作就是去训练一个模型,然后去预测JFT-300M这个数据集上所有的这个类别,那因为JFT-300M这个数据集非常大,它的类别数好像有18000,然后因为有这么多的类别,所以它的标注,其实是比较noisy的,这样也就算是一种弱的监督信号。
但总之,作者想说的是,这一系列的工作之所以更火爆,就是因为他们的性能会更好。
这一系列的工作,其实也就代表了一个实用主义的这个空间地带,其实那些作者也知道使用这种有限的,而且就是固定的这种特别好的标注数据是不好的,是有很大的局限性的,他们是非常想用这种取之不尽,用之不竭的这种原始文字,但是,因为后一种方向,目前的这个效果还太低,所以说没办法,他们就走了这种中间的地带。
就是用这种文本带来的弱监督信号去帮助有监督的模型取得更好的效果。
但是,有得必有失,作者之类就指出,虽然你取得了更好的结果,但是,你还是有很大的局限性。
之前的这些工作,需要精心的设计,而且他们的监督信号,还是1000个类,或者18291个类,它并不能真的做到随心所欲去检测任何他想检测的类。
而且这两种方式都是会用一个固定的softmax分类头去做分类的。
所以说他们的输出都是固定,要么是1000选一,要么是18000选一。如果再有新的类别,他就无能为力了,所以他们没有灵活的这种做zero的能力。
接下来作者说,之前这些弱监督的方法,也就是之前我们提到的这两个工作,而最近的这些借助于自然语言处理去学习这个图像表征的方法,也就是这些VirTex LCMLM,这些工作他们的最大的区别在哪?
他们最大的区别,就是在他们这个规模上。
因为从方法上来说,不论你是从这个Instagram的这个Hash Tags上去学习,还是从JFT-300M这个数据集上,这个标签这一两个单词上去学习,其实也都算是一种从自然语言处理学习图像特征的方法,它们之间的区别,并不是很大。
关键就是在规模上,那这个规模,其实就是说数据规模、模型的规模。
那像之前这些弱监督学习的方法?他们是在有规模的数据集上去训练他们的模型的,而且训练了加速器,它这里为什么用加速器?
是因为大家用来训练的这个硬件,是不一样的,大多数人, ?可能还是用GPU,那像Google,就是用TPU。
当然还有很多别的训练硬件。
所以作者这里,把所有的这些硬件都统称为是加速器,反正都比CPU快。
这个其实我们之前在讲VIT那篇论文的时候,也提到过,当时,作者说他们训练这个VIT模型用了2500个TPU v3/天,也就是说如果你用一个TPUv3核的话,你训练这个模型需要训练2500天,那换算过来的话,大概就是七年。
他们当时,也是在JFT 300M这个数据集上去训练的,对,大概就是这里说的,训练了七个accelerate years,然后在这种级规模的数据集上去训练。
但最近的这些方法,比如说跟CLIP最相似的这三种方法,他们其实只是在几十万张图片上去做了这个训练,而且就训练了几天。
那跟之前那种亿级规模的数据集,而且还训练了几年的规模比起来,它的效果肯定是不太行的。
那CLIP这篇论文的作者就是想告诉大家,这些方法效果不行,不是因为他的方法不行,主要是因为规模没上去,只要规模上去了,效果好到你怀疑人生。
所以作者接下来就说,那在这篇论文里,我们就是Close这个GAP。什么GAP,就是之前这几个工作,它的这个训练规模不够大,那我们这里,就是把它的规模推到够大。
具体来说,首先,CLIP的作者团队就从数据出手。
他们就先去收集了一个超级大的这个图像文本配对的数据集,里面有400M这个图片文本的配对。
那这个规模就够大了,就跟JFT-300m数据集是一个水平上的,也就是说跟之前这些工作,这些弱监督学习的方式,他们在数据上打成平手了。
那至于模型上,作者也尝试了从ResNet到Efficient Net,Vision Transformer ,到最大的他们用了VIT Large这个模型,所以说模型的规模,也提上去了。
那在大数据加大模型双重的加持之下?作者说我们就提出来一个非常简单的方法,叫CLIP。
它,其实就是我们之前说的这个工作抗VIT的一个简化版本,但是效果非常的好,然后在模型方面,作者在视觉这边,一共尝试了8个模型,从最后到transformer。
这里面最小的模型和最大的模型之间的计算量差了大概有100倍,也就是他这里说的two orders of magnitude。
作者最后发现,这个迁移学习的效果是跟这个模型的大小,基本上是呈正相关的.就是说小的模型,它的效果就差一些,大的模型效果就好一些,你的模型逐步增大,你的这个迁移学习的效果也逐步增高。
它是一个非常平滑的过程,所以你也是可以预料的。那如果在你接下来真实的应用中,你采取了更大的模型或者更小的模型,其实你也可以大概估算出来它的这个签约学习的效果会是多少,这个性质,确实是非常实用的。
然后到引言的最后,自然又是老套路,作者得开始卖结果了,CLIP这篇论文的结果,非常非常的多,而且效果都非常非常的好,所以说,他就把最重要的几个点罗列了出来。
那首先既然CLIP模型做的是这个迁移学习,做的是这个泛化性能,那所以说你能迁移的这个任务越多,你的这个榜刷的越多,那自然就可以证明你的这个模型更有用,所以作者这里,就怒刷30个数据集,然后在这些数据集上,CLIP一般都能和之前精心设计的那些有监督训练好的模型打成平手,或者甚至比他们效果还好。
然后作者为了进一步验证CLIP学到的模型特征的这个有效性,暂时先不做这种zero shot,而是去做之前我们在对比学习里讲过的这个line probe这种设置,也就是说一旦这个预训练的模型训练好之后,我们把它冻住,整个backbone,骨干网络就不改变了。
我们只是从这个模型里去抽特征,然后训练最后一层分类头,去做这个分类任务。那在这种情况下,作者发现CLIP也比之前最好的这个ImageNet训练出来的模型,效果要好,而且计算上也更加高效。
最后又发现,这个zero shot,这个CLIP模型,它还更加的稳健,就是说当它的这个效果和之前这种有监督的ImageNet上训练好的模型效果持平的时候,它的这个泛化性能是远比那个ImageNet有监督训练出来的模型要好很多,也就是我们刚才刚刚讲过的那个例子。
就像OpenAI CLIP这个官方博客上面做的那个实验一样,在这种素描,或者对抗性样本的情况下,有监督训练的模型基本上就是在瞎猜了,可是CLIP模型,照样表现的很好,基本没有掉点。
所以说CLIP这个模型真的是想法又简单,实现又高效,性能在各个数据集上又非常的好,而且泛化性、稳健性都不错,全方面碾压之前的方法。
效果好的真是让人不敢相信,所以作者都不得不专门写了一个section,也就是后面我们会提到的这个SECTION 7去讨论CLIP这个工作的这个广泛的影响力,以及它有可能带来的这种政策上,或者伦理上的这种影响。
?
3 Approach方法
接下来我们一起来看一下文章的方法部分,看看CLIP是怎么进行预训练。
作者说他们方法的核心就是利用这个自然语言的这个监督信号来训练一个比较好的这个视觉模型,然后,大佬一般都比较谦虚,他们说,这个方法或者说这个思路,一点儿都不新。
那作者为什么还要接着这个方向继续做?因为他说,之前的这些方法,他们的这个用语,都比较的混淆。
本来都是很类似的想法,但是这四个工作,分别把他们的方法描述成为是,无监督的,自监督的,弱监督的和有监督的,所以让人感觉很无厘头,而且他们的规模,也没有做得很大。
所以作者说,那我来帮你们总结总结,顺便把规模做大,给你们看看效果到底有多好。
然后作者说,我们想强调的是这些工作,其实他们没有什么大的区别,他们就是想用文本,当做一个训练的信号。
但这条这条路走的不是很顺,其实也有一个原因,就是NLP那边的模型,也不是很好学。比如说之前NLP那边用的是这种model或者n-gram还是非常复杂的,所以不太好做这种跨模态的训练,但是随着transformer和自监督的这种训练方式的兴起,那边彻底革命了。
也就是他这里说的这种deep representation learning,就是具有上下文语义环境的这种学习方式,比如说BERT用的完型填空,然后在这种自建能学习的范式之下,现在NLP模型终于可以利用这种取之不尽用之不竭的这种文本监督信号了。文中还说训练出来的模型,又大又好,而且还简单,而且泛化的也好,这就为多模态的训练铺平了道路。
然后接下来作者又说了说我们为什么非要用这种自然语言的监督信号来训练一个视觉模型?因为它的好处实在是太多了。作者这里,列举了两个最重要的。
第一个,就是说你不需要再去标注这些数据了,那像ImageNet的话,你原来就得说你先定好,我有1000个类,那是1000个类也得是你提前去筛选选好的,然后你再根据这些类去下载照片,然后再去清理数据集,然后再去标注。
是一个非常复杂的过程,那如果你现在要做的,只是去网上下载这些图片文字的配对,标注的步骤都不用做了,那数据的这个规模,很容易就变大了。
而且,因为你现在的监督信号是一个文本,而不是像文中说的这种,N选一的这种标签了,那模型的这个输入输出,这个自由度就大了很多。
第二个非常重要的点,也是说正是因为你现在训练的时候,把这个图片和文字绑定到了一起,那你现在学到这个特征,不再单单的是一个视觉特征了,而是一个多模态的特征,当你和这个语言联系在一起以后,你就很容易去做这种zero的这种迁移学习了,但如果你只是做一种单模态的这种自见度学习的话,无论你是用单模态的对比学习,比如说MOCO,还是说单模态这种掩码学习,就是MAE,你都只能学到视觉的这个特征,而无法和自然语言联系到一起。
那这样,你还是很难去做这种zero shot的迁移,所以总结下来就是说,用文本监督信号去帮助训练一个视觉模型是非常有潜力的。
那可惜的是,如果你要去做这种文本和图片配对的学习,你就需要有一个足够大的数据集,里面,就有很多很多这种图片文字,对作者这里说,已有的常见的几个数据集,就是有这个ms coco 和这个YFCC100m,然后,虽然前两个数据集它的这个标注质量非常的高,但是它的这个数据量,太少了,只有大概这个10万个训练样本。
那跟现在大家对大数据的这个期待,也就是说它这个modern standard相比而言,它就小太多了.那像JFT 300m,有3亿个训练样本,然后Instagram那个数据集,有3.5billion,就35亿个训练样本。然后对于这个YFCC100m数据集来说,你乍一看有一个亿,好像很多,但是,它的标注质量实在是太差了,它里面很多照片的这个配对的文本信息,都是自动生成的,比如说,很多时候它配对的那个文本信息,就是这个照片的名字。
或者说是这个相机的一些参数,比如说焦距,曝光度什么这种完全跟这个图片是对不上号文不对题的,那你如果用这样的配对去训练模型的话,肯定这个效果就不是很好。
然后,就有人去把这个数据集清理一下,但是,发现经过清洗以后,这个数据集,一下就缩小了六倍,最后就大概就只有1500万张图片了,作者说,这个规模,那其实就跟ImageNet差不多,当然这里的ImageNet指的可能是ImageNet21 22K,那他们,也是有14m的图片。
总之,作者就是觉得即使是这个规模也是不够大,应该达不到他想要的这种一鸣惊人的效果。
所以说不如自己动手,自己造一个大数据集。
那确实造这个数据集,也是物有所值,不光是孕育了像CLIP这篇工作,而且还孕育了OpenAI另外一篇里的那个做DALLE2图像生成的工作。
那最后,OpenAI自己收集的这个数据集里面有400m,也就是四个亿的图片文本,对,那这个是什么概念?那如果你跟之前图像那边最大的数据集的JFT 300m数据集比的话,那比他们还多一个亿的训练样本。
那如果跟NLP那边比的话,作者这里说,如果按照单词的数量来看的话,他们新收集的这个数据集,大概跟练GPT2用的那个webText数据集差不多接近,所以,应该是够大够用了,他们就把最后这个数据集,叫做WIT也就是web image text数据集。
那有了超大规模的数据集,那接下来作者就在2.3节讲了一下预训练的方法,以及他们是怎么选择这个预训练的方法的,他说视觉现在这边的模型,都是非常大,训练起来都非常贵,比如说之前这个工作,他就在Instagram那个数据集上去做预训练的,他训练了一个ResNet101,这个网络需要19个GPU年,就是说如果你用一块GPU的话,你要19年。
然后另外一个工作,这noisy student,也就是之前在image数据集上榜很久的那个方法,我们也提到过很多次了,他需要33个TPUv3年,也就是说如果你用一个TPUv3核的话,你需要训练33年,总之就是说,训练起来非常贵,然后作者又补充了一点。
如果你去想一想,这两个系统,还都是在预测,只有1000类就已经这么耗费资源了,那他们现在不仅数据集更大,而且任务也更难,他们,是要从自然语言处理里直接去学这种open set of concept,就是直接去学这个开放世界里所有的这种视觉概念,那就连OpenAI这种每次出手都是大手笔,感觉从来不愁计算资源的公司,都觉得训练这个系统,太吓人了。
所以最后他们说,经过他们一系列的努力,他们发现,这个训练的效率对于这种多模态预训练的成功是至关重要。
那作者他们做了哪些尝试?他们说,首先他们试了一个跟VirTex这篇工作非常相似的方法,就是说,图像那边,他们用了个卷积神经网络,然后文本这边,用了个transformer,然后都是,从头开始训练,那他的任务是什么?就是说给定一张图片,他要去预测这个图片所对应的那个文本,也就是这个图片的那个caption,那其实这个,就是预测性的任务,那这个很好理解,因为OpenAI本来就是一家把任何事情都是GPT化的公司,从最开始的GPT,GPT2到GPT3,以及最近的还有DALLE2,image gpt和OpenAI Codex,所有这些鼎鼎有名的大项目,全都是基于GPT来做的,唯有CLIP这个工作因为训练效率的原因,选择了对比学习的方法。
那作者接下来,就解释一下为什么要用对比学习,他说,因为如果你是给定一张图片,然后你要去预测它对应的这个文本的话,你是要逐字逐句去预测这个文本的,那这个任务就太难了,因为对于一张图片来说,你可以有很多很多不同的描述,那比如说我们现在大家看到的这个画面,让不同的人去添加字幕的话,那有的人可能就会说,,这里是有一个人在讲论文,那也有人可能说这个人穿的衣服是蓝色的,所以说这个文本之间的差距,是非常巨大的。
那如果用这种预测型的任务去预训练这个模型的话,它就有太多太多的可能性了,那这个模型,训练的就非常慢,所以作者接下来就说了一大堆,对比学习的好处。
作者发现,如果你把这个训练任务变成一个对比的任务,也就是说你只需要去判断这个图片和这个文本是不是一个配对,那这个任务听起来是不是就简单了很多?因为我现在,不再需要去逐字逐句的去预测这些文本了,那这个时候,只要你这个文本和图片是配对了就行,这个约束一下就放宽了很多。
那其实这个监督信号,想起来也更合理。
然后作者把这个对比放到了这个图二里,他们发现,仅仅把这个预测型的这个目标函数换成一个对比性的目标函数,这个训练的效率,一下就提高了四倍。
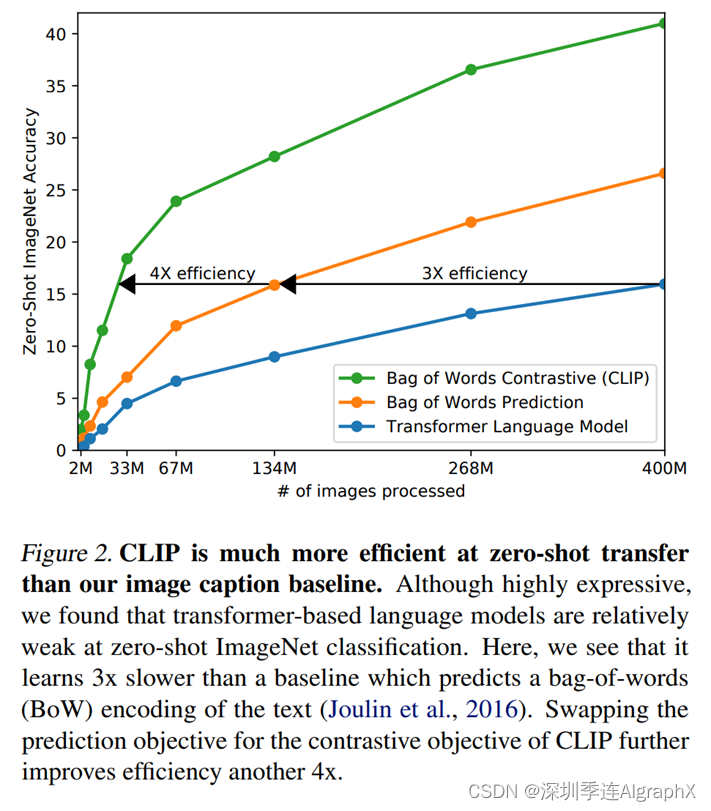
那在图二里,这条蓝线就是OpenAI这种gpt的模型,基于去做这种预测的任务。
中间这条橘黄色的线,指的是一种bag of words的方式,它其实简单来说就是说你不用去逐字逐句的去预测这个文本了,你的这个文本,已经全局化的抽成了一些特征,所以说相应的这个约束被放宽了,那我们可以看到,一旦这个约束放宽以后,立马这个训练的高效性就提高了三倍。
然后如果我们进一步放宽这个约束,就是不再去预测这个单词了,我只需要判断它是不是图片文本,对,也就是最后这里画的这条绿线,就是CLIP用了这种对比学习的方式,我们会发现,他这个训练效率又进一步的提高了四倍。
所以也就说明了基于对比学习的这种方法,它的训练是非常高效的。
那接下来,作者就具体讲了一下CLIP所用的方法。
之前我们在前沿的时候也大概讲了一下,图一里就是这个CLIP模型的这个总览图。那这里我们直接过一遍伪代码,应该就对CLIP这个方法,有更加直观的了解。

首先,就是你有两个输入,一个是图片的输入I,一个是文本的输入T,那这个图片的输入维度也已经都说明了,它是N,也就是这个Batch size和H W C,分别对应的,比如224*224*3,那文本的输入T,这里头当然这个也是N,因为它跟这个是配对的嘛,那这个L,就指的是序列。
那一旦你有了这两个输入,你就需要去通过这个编码器,去得到对应的这个特征,那当然这里的编码器,作者说它即使可以是一个resnet,也可以是一个Vision Transformer,那对于文本来说,它既可是一个CBOW 或者Text Transformer。
然后在你得到对应的这个图像特征和文本特征之后,一般后面会有一步这个归一化的操作。当然这里,还牵扯到一个投射层,那这个投射层的意义,主要就是需要学习一下如何从这个单模态,然后变到这个多模态,所以作者这里说,这是一个合并的,一个多模态的一个特征。
那当你投射完之后,再做一次这个L2归一化,你就得到了最终的用来对比的这个特征,I_e和T_e。
那一旦你有了这两个特征,也就是说你有N个图像的特征,还有N个文本的特征,那接下来要做的,就去算一下他们这个cosine similarity。
那这个算得的相似度,其实也就是最后你要用来做分类的这个logits。
那一旦你有了你预测的这个,那当然接下来,我们就需要一个ground truth,然后你这个logits,就去跟这个ground truth,做这个交叉商目标函数,从而算得最后的这个loss。
那这里我们可以看到它算这个ground truth,用的是这个arrange function.那你得到值,就是从一开始1234567,一直到N,这个跟我们之前讲的MOCO创建ground truth的方式是不一样的,因为对于MOCO来说,正样本永远都是在第一位,所以在MOCO那篇实现里,它的这个ground truth,全都是零,因为只有在零这个位置,也就是第一号这个位置是正样本。
但是对于CLIP来说,我们之前在图一里也说过,它的正样本,全都是在对角线上的,也就是说i1T1,i2T2,所有这些在对角线上的元素才是正样本,所以他就用这种形式,去创建这个ground truth。
然后接下来,是很中规中矩的,算两个loss,一个是image,一个是text,一个对称的loss,最后把两个loss加起来求个平均,这个操作在对比学习这边是非常常见的,最新的MOCO v3,这些工作全都是用的这种对称式的目标函数。
所以说当我们看完这份伪代码之后,我们就会发现CLIP真的很简单,它真的跟之前的对比学习没有什么区别,它无非就是把单模态的正样本换成了多模态的正样本。
接下来,作者还讲了一些很有意思的细节,他说,因为他们收集的这个数据集实在是太大了,所以说这个模型的训练,不太会有这种over fitting的问题,所以他的实现,就比之前的这个工作要简单很多,比如说在他们训练CLIP这个模型的时候,对应的这个文本编码器和图片编码器都是不需要提前进行预训练的。
然后第二个有趣的点,就是在他们最后做这个投射的时候,他们并没有用这种非线性的投射层,而是用了一个线性的投射层。
那这个线性非线性投射层,我们之前在讲对比学习,我们讲过,用这种非线性的投射层,会比用线性的投射层带来将近十个点的这个性能提升非常巨大的,但是作者这里说,在他们多模态的这个预训练过程中,他们发现这个线性,非线性没什么大关系。
他们怀疑,这个非线性的这个投射层,应该只是用来适配,这种纯图片的单模态学习的。
然后,也因为这个数集实在是太大了,所他们也不需要做太多的这个数据增强,作者这里说他们一用的这个数据增是一个随机裁剪,其他所有那些fancy的数据增强,都没有使用。
然后最后,因为这个模型实在是太大了,数据集也实在是太大了,训练起来太耗时,所以说你不太好去做这种调参的工作。
所以在算对比学习的这个目标函数的时候,我们之前在讲对比学习那些工作的时候,这个temperature这个参数,是个非常重要的参数,稍微调一调,这个最后的性能就会有很大的改变,但作者这里,实在是不想调,所以就把它设置成了一个可以学习的一个标量,所以这个参数,直接在模型训练过程中就被优化了,而不需要当成一个超参数,最后再去调参。
那在文章的2.4节,作者主要就讲了一下,在视觉那边,模型既可以选择ResNet,也可以选择vision transformer,文本那边,就是用的transformer。
模型的选择上都是非常中规中矩的,只有一些很小的改动,但这些改动,一般都是为了训练的更高效,然而最后的性能才好一点,它并不影响整个文章的这个故事走向。
所以这里我就直接跳过我们接下来看文章的2.5节,怎么训练这些模型。
作者说,对于视觉这边,他们一共训练了8个模型,有5个这个ResNet,有3个这个vision? transformer,那这5个ResNet里面,有ResNet-50和ResNet-101就标准的,还有3个网络,它是根据这种方式去把模型里的这个宽度,还有模型的这个深度,以及这个输入的大小,都做了调整,从而得到了几个残差网络的变体。
也就是他这里说的,RN50*4,RN50*16和RN50*64分别对应的,就是原始的那个RN50*4 16倍和64倍的这个更多的计算量。
那对Vision Transformer来说,作者这里就选择了VIT-B/32,16和VIT-L/14,这里的32、16、14分别指的是这个patches的大小,因为VIT large已经非常大了,所以就没必要再去把它变得更大了,而且如果你想要更大的模型,那VIT huge,VIT G也都有,你直接用就完了。
然后,作者说所有的这些模型,都训练了这个32个Epochs,是用Adam这个优化器去训练的。
然后对于所有的那些超参数,作者也简单的做了一些这个Grid? search,或者说Random search和手动的这个调整,但是为了让这个调调的快一点,所以在做超参搜索的时候,都是用的最小的这个RN 50去做的,而且都只训练了一个epoch,对于更大的模型来说,作者这里就没有再去调参了。
然后在训练的时候,作者选用的Batch Size是3万多,非常的大,之前对比学习的训练也无非就是说8192。
所以很显然这个模型肯定是在很多很多的机器上去做这种分布式训练,而且混精度训练也是用到,这样不仅能加速训练,而且还能省内存。混精度训练其实现在一个常见的操作了,基本上涉及transformer的论文都会用。
由于对于大部分任务来说,用混精度也不会掉点,有时候甚至还能涨点,然后凭空又能省一半内存,训练速度也能大幅度增加,那为什么不用?
然后为了进一步的这个节省内存,作者还用了很多的技术,比如说,即使是最后在算这个相似度的时候,其实这个相似度的计算也是被分到不同的GPU上去做的。
只有经过这么多工程上的优化,这个CLIP这个模型,才能被训练起来。
如果大家对这些工程上的细节感兴趣的话,我推荐给大家一篇很有用的博文,这篇博文的题目就是《How to Train Really Large Models onMany GPUs?》,这个博客其实也是OpenAI的一个员工,所以非常具备参考价值的也非常这个博主还有很多别的博客,都是满满的干货。
那最后我们来看,作者说对于最大的这个残差网络来说,这个RN50*64,它在592个V100的GPU训练了18天,而最大的这个Vison Transformer 模型用了 256 V100训练了12天。所以确实训练vision transformer比训练一个残差网络要高效的,因为ViT-L/14表现最好。
所以作者又拿预训练好的这个模型,再在这个数据集上又Fine-tune了一个epoch,而且用的是更大尺寸的图片,就是336*336的这种图片,这种在更大尺寸上Fine-tune,从而获得性能提升。
然后作者接下来说,如果没有特殊指明的话,接下来整篇文章剩下的二三十页,只要我们说到CLIP,其实都指的是这个ViT-L/14@336px最大最好的模型了。
4 Experiments实验
那读到这儿,我们就把文章的第二章节看完了,我们现在已经知道CLIP这个模型是如何进行预训练,以及作者为什么选用对比学习来预训练CLIP,那接下来,我们就来读一下这个长达十几页的实验部分。
那实验部分一开始,作者先介绍一下什么是zero shot transfer,因为这个才是CLIP这篇文章的核心和精华所在。那作者少不了,上来还得再介绍一下他们为什么要这么做,就是他们研究zero shot迁移的这个动机。
其实,大概总结下来就是一句话,就是说之前那些自监督或者无监督的方法,他们主要研究的是这种特征学习的能力,他们的目标,就是去学一种泛化性比较好的特征,比如说我们讲过的MOCO,但即使你学到了很好的特征,如果你想应用到下游任务的时候,你还是需要有标签的数据去做微调。
所以这里面,就还牵扯各种各样的问题,比如说下游任务不好去收集数据,比如说有shift的问题。
那我们如何能够训练一个模型,接下来就不再训练或者不再微调了?
所以这就是作者研究zero shot迁移的这个研究动机,一旦你借助文本训练好了一个这个又大又好的模型之后,你就可以用这个文本作为引导,去很灵活的做这种zero shot迁移学习,至少在分类上,效果都非常的好。
那至于怎么用CLIP去做这种zero shot的迁移?作者在这个3.1.2这一节里大概说了一下,那文字,还是不够直观,我们现在回到图一里去再复习一下这个zero shot的推理是如何做的。
这个图一,其实我们之前在前沿的时候已经介绍过了,这里,我们在细致的过一遍,当CLIP1训练好之后,其实它就有两个编码器,一个是这个图像编码器,一个是这个文本编码器,他们就都已经训练好了。
那这时候任意给你一张照片,比如说这里这张有狗的照片,那这个照片,通过这个图片编码器就会得到一个图片的特征,那文本那边的输入应该是什么?那文本那边的输入其实就是你感兴趣的标签有哪些?
比如说这里的标签,飞机、汽车、狗和鸟,我们暂且就用这四个词当做所有的标签。
那首先这四个词,通过prompt engineering就会变成这一个句子。
也就是说,飞机就会变成这是一张飞机的照片,汽车就会变成这是一张汽车的照片,所以说四个单词就变成了四个句子。
那当你有了四个句子之后?你通过这个文本编的编码器就会得到四个文本的特征。
那这时候,你拿着四个文本的特征去跟这一个图像的特征去算,最后得到这个相似度,还会再通过一层softmax,得到一个概率分布,那这里哪个概率最大,也就是说哪个相似度最高,那它所对应的那个句子,大概率就是在描述你这张照片,也就是说那个句子里所包含的物体,其实就是你这个图片里应该有的物体了。
那如果我们现在想一下,我们要给ImageNet里所有的图片去做这种推理,去测试一下模型的效果如何,我们这里会生成多少个句子?应该是1000个句子,因为你ImageNet有1000个类嘛,所以说你对应的,就会生成1000个句子,简单的来说,就是说你每张图片,你相当于都用1000个句子这样去问他,你是不是飞机,你是不是汽车,你是不是狗,你是不是人,问他1000次,然后他跟哪个文本最接近,那它就是哪一类。
当然在文本端算这个特征的时候,并不是这种顺序进行的,它是可以批次进行的,所以说CLIP的推理,还是非常高效的,它并不会慢。
那讲完了如何去做这种zero shot的推理,那接下来就可以跑分了,所以说作者在3.1.3里,就去做了一下和之前最相似这个工作,Visual n-grams这个对比。
作者说,我们在表一里,展示了一个非常惊人的结果,就是n-grams之前在ImageNet上这个效果,只有11.5的这个准确率,而已经达到了76.2。
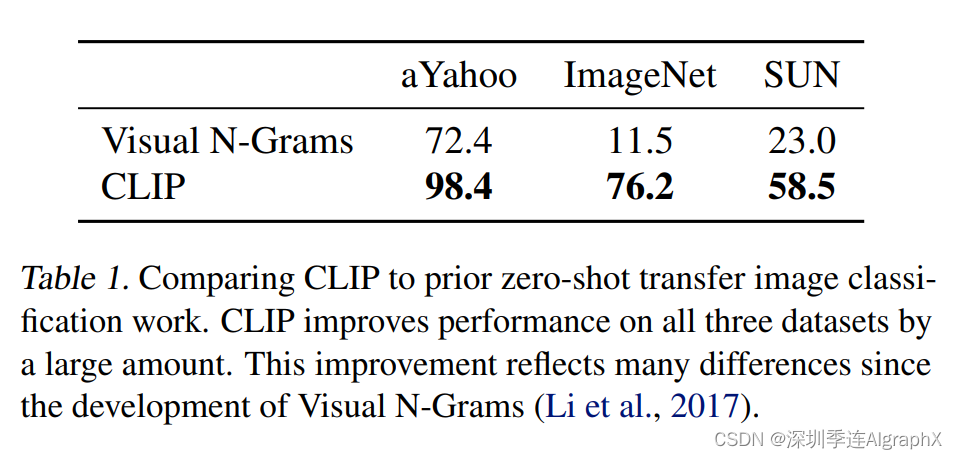
而这个76.2的这个性能,直逼之前的这个原版的50,而且还是在完全没有用任何一张,就是那128万张训练图片的情况下。
直接zero shot迁移就能得到76.2。
那现在我们来看一下表一,CLIP和visual n-grams的这个直接对比,我们可以看到CLIP是大幅度超越这个visual n-grams,当然ImageNet上这个提升是最明显的,但是在剩下两个数据上,也都非常厉害。
但是作者这里也指出了,这并不是一个公平的对比,因为很多东西都不一样。CLIP用的数据集,比之前的那个方法大了十倍,而且用的这个视觉上的模型,比之前要多100倍的这种计算。
所以说相当于在训练上,他们用了超过1000倍的这个资源去训练这个模型,而且在模型的架构上,用的是transformer,但是在2017年就visuals这篇论文发表的时候,其实这篇论文还没出现。
所以作者这里其实想强调的,就是这不是一个公平的对比,这也是对之前的工作,是respect。
那接下来,我们就来说一下大家比较感兴趣的这个3.1.4,也就是prompt? engineering和ensembling这个基于prompt这个学习方法,最近非常不论是在NLP还是在CV领域都非常的火。
如果你还在找研究方向,其实这是一个不错的选择,因为它主要是在你做微调或者直接做推理的时候用的一种方法,而不是在预训练阶段,所以你不需要那么多的计算资源,但是,因为效果好,所以说它的影响力也还是非常大的。
那这个prompt是什么?Prompt翻译过来它有很多的含义,但是在这里,它其实对应的这个中文含义,是提示,它起到是一个提示的作用,也就是我之前一直说的这个文本的引导作用。
那我们为什么要做prompt engineering和prompt?作者这里举了两个比较常见的例子,第一个问题,就是作者这里说的多性,也就是一个单词,可以同时拥有很多的含义。
那如果你在做这种文本和图片的匹配的时候,你每次只用一个单词,也就是那标签对应的一个单词去做这种文本的特征抽取,那你就有可能会面临到这种问题,比如说在ImageNet这个数据集?同时包含有两个类,一个类是construction crane,一个是crane。
那在相应的语境下,这两个crane对应的意义,是不一样的,在这种建筑工地环境下,它指的是起重机,而作为一个动物,它指的是鹤,就是丹顶鹤那种鹤类动物,那这个时候,就会有奇异性出现了,你算的这个相似度,很有可能就是错的。
那当然别的数据集也有这种问题,比如说他这里说Oxford-IIIT pet里面,也有一类叫boxer,那其实如果你只从动物的这个角度去理解,Boxer其实就指的是狗的一个种类。
但是对于一个什么都不知道的文本编码器来说,你如果只把boxer输给他,他很有可能就把这个词当成是一种运动员了,就是打玄机的。
那他抽取的这个特征,肯定是不对的。
这种多异性的情况,其实我们之前在做research的时候,也遇到过,在做物体检测的时候,经常有一类叫做remote,他说的就是遥控器的意思,但如果你只把remote这个词给这个文本编码器来看,如果不加任何上下文语义信息的话,它很大情况下就把这个remote理解成遥远的意思了,所以总之就是说,如果你只用一个单词去做prompt的话,会经常出现歧异性这种问题。
那另外一个问题,我们之前也说过很多次了,就是在我们做预训练的时候,我们这个匹配的文本一般,都是一个句子,很少是一个单词,可是如果你在做推理的时候,每次都进来的是一个单词,那你这里面,可能就会存在这种问题,你抽出来的特征,可能就不是很好。
所以基于这两个问题,作者就想了一个非常简单的一个方式,去做这种prompt template,就是有这么一个提示的模板,也就是说把标签放在这里,然后我把它变成这么一个句子,所有的标签都变成了这是一个什么什么的图片。
这样,首先它已经是一个句子了,所以就不太会出现这种distribution GAP的问题,其次,因为他说的是这是一张什么的图片,所以说后面这个标签,一般多指的是名词,那上面奇异性的问题,有时候就会解决了,比如我刚才说的这个remote的问题,那它就肯定指的是遥控器,而不是指的遥远这个含义了。
所以用上了这个提示模板之后,作者发现这个准确度,一下就提升了1.3%,而且这个模板,非常的简单粗暴,所有的标签,都是改成这样一种形式的句子。
那当然,Prompt engineering不光是提供这么一个提示的模板,它还可以做很多事情。作者就发现,如果你提前知道一些信息,那这样做zero shot的推理,是非常有帮助的。
比如说当你知道你现在做的,就是Oxford这个数据集的时候,它里面的类别肯定都是动物,所以你给出的提示,就不光是说a photo of xxx,你还可以在后面再加一句话,一种宠物的类别,那这样,一下就把这个解的空间缩小的很小,很容易得到一个正确的答案。
那同样的道理,对于这种实物的数据集,你就可以说这是一种实物,对于这种飞机的数据集,你就可以说这是一种飞机,对于zero的迁移,都会非常的有用。
作者这里还举例,就是说当你去做OCR这个任务,也就是说给了一个图片,去里面找文字数字这种任务,如果你在你想找到那个文本或者数字上打上这个双引号。模型,就更明白你的意思了,他可能就知道你就是想找双引号里面的这个内容,这个结果也是相当有意思。
最后,作者就讲了一下prompt ensemble,就是说多用一些这种提示的模板,我们做多次推理,然后最后把这个结果综合起来,Ensemble,一般都会给你更好的结果。
那作者这里到底用了多少个这个提示样本去做这个em?在论文里,他说用了80个,请看代码库。
Clip/notebooks/prompt_engineering_for_imagenet.ipynb
Imagenet_templates=[
‘a bad photo of a {}.’
‘a photo of many {}.’
那在作者讲完了如何做prompt engineering和ensemble之后,其实CLIP整体所有的方法都讲完了,包括数据集,怎么选择模型,怎么去做预训练,怎么去做zero shot的这种推理,整个的方法部分,我们都已经看完了,这个花了作者七页半的篇幅。
其实到这里结果就已经很好了,如果加上点讨论,加上一个结论部分,其实就是一个中规中矩的八页的论文投稿。
但是作者觉得,看官你别着急,你且看我再给你秀十页的结果,所以接下来在3.1.5节,作者就大范围的在27个数据集上去衡量一下CLIP做这种的迁移的效果。

作者接下来,就把这27个数据集的对比结果放到了这个图里。这个图比较的双方,一个就是做zero shot的CLIP,另外一个就是在ResNet-50的特征上去做这种linear probe。
Linear Probe,我们之前在讲对比学习的论文时候,已经反复说过了,就是把一个预训练好的模型冻住,只从里面去抽特征,然后就训练最后那一层那个FC,分类头层去做这种有监督的分类任务。
那这里,这个ResNet-50,是在ImageNet上用有监督的方式训练好的一个模型,我们从中去抽特征,然后在这些下游任务上去添加新的分类,然后在这个新类分类图上去做这种linear probe的微调。
作者在这里是把这种方式当成了基线,如果CLIP模型比它表现的好,它就列在上面,是绿色的这些,全都是加号,意思就是说CLIP模型相比于这个极限提升了多少。
那对于下面这些蓝色的,就是说CLIP模型相对于期限要降低了多少的性能?首先我们可以看到的是,在16个数据集上,也就是在大多数数据集上,zero shot的CLIP模型,都超越了之前这种有监督训练好的ResNet-50。
这个结果是非常惊人的,因为它真的证实了zero这种迁移也是有效的,是可以广泛进行应用的,而不是光在ImageNet或者某些数据集上有作用。
然后,作者这里还做了一些总结,就是对于这种普通的给物体进行分类的数据集来说,CLIP一般都表现的比较好,像这种车,食物,动作,或者是像CIFAR10,ImageNet这种普通的物体分类的数机,就能很好的去做这种zero的迁移。
这个也比较好理解,因为如果你这个图片中有一个可以描述出来的物体,那对应的那个文本里,应该也有这个物体的描述,所以他俩就会匹配的非常克雷普模型,对这种物体也会比较敏感。
但是,对于更难的一些任务,更难的一些数据集,比如说DTD这种对纹理进行分类的数据集,或者说clever counts这种去给图片中的物体计数的任务。
对于CLIP来说,就非常的难,而且太过抽象,所以CLIP模型在这些数据之上的表现就不好。
因为对于这种难的任务,你完全不给他任何标签信息的话,这有点强人所难了。
所以作者最后,也为CLIP打抱了个不平,他说对于这种特别难的任务,如果只做这种zero shot的迁移,可能不是那么的合理,有可能去做这种的few shot迁移会更合理,因为对于这种难的任务,比如说去给这种肿瘤做分类,这种需要特定领域知识的任务。
那即使是对于我们人来说,如果我们没有这个先验知识,我们也没法分类正确,那为什么要去强求CLIP在zero shot的时候正确分类?
那既然作者提到了,作者觉得对于这些更难的数据集会few shot比zero shot衡量更合理,那为了自圆其说,作者肯定就得把的实验也都做了。
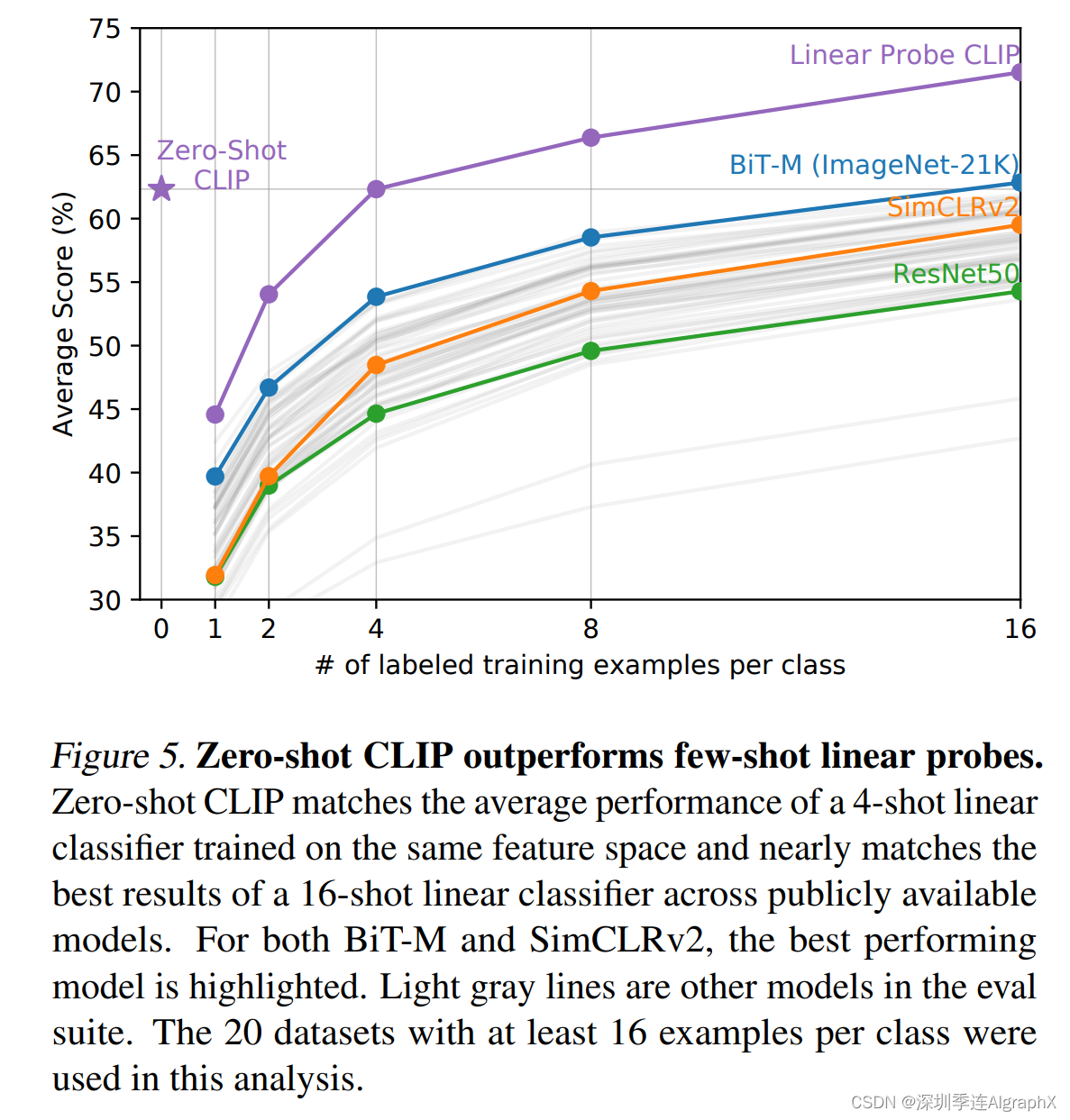
所以在图五里,作者就做了一下zero short CLIP和few shot CLIP,以及和之前那些方法的一些比较。
?
具体来说,对于之前的这些方法,就是用不同的方法去进行模型的预训练,然后当你训练好这个模型以后,我们就把这个模型的参数冻住,只从里面去抽特征,做这种linear probe。
那既然你是linear probe,你需要训练最后那个分类头了,所以你就需要下游数据集里,有这种有标签的数据,这个就算是few shot。
那对于CLIP模型也一样,作者这里,就是把CLIP里面那个图片的编码器拿出来冻住,然后去做这种linear probe。
图五的横坐标,是说这个数据基地每一个类别里到底我们用了多少这个训练样本,那零,就是说的zero shot什么都不用,所以是对应的,也就是zero shot的CLIP。别的这些方法,因为没有和自然语言的这种相结合,所以他们就没办法做zero shot,所以他们最低也得从one shot开始,就是你怎么着至少也得用一个训练样本,然后,从one到two shot,最后到sixteen shot。
那图五的纵坐标,说的是average,也就是一个平均的分类准确度,那这个平均,其实就在刚才的27个数据上去取的平均,当然这里,其实是20个数据集,因为在有七个数据集里,它有些类的训练样本,还不足16个。
所以如果把那个数据集囊括下来的话,这个16这块的曲线,就不好画了,所以作者就把那七个数据集踢掉了。
所以这里,就只是做了20个数据集的这个平均准确度,也就意味着这里的每一条曲线,其实是20个数据集结果的一个合并,而并不单单是一个数据集上的结果。
那从这张图里?我们可以观察到好几个有趣的结论。
那首先,就是看这条蓝色的曲线,对应的,其实是bit模型,Bit也是Google的一篇工作,叫big transformer,它主要就是为迁移学习而量身定做的,所以它算是迁移学习或者说迁移学习里表现最好的工作之一。那在这里,这个bit的模型是在image 21K上去做训练。
数据集也比较大,所以说这条蓝色的曲线,非常具有代表性,是一个很强的base line,但是我们可以看到zero shot的CLIP,不用任何训练样本,直接就和你最好的这个Bit打成平手了。
可见利用自然语言的这个威力。
那第二个比较有意思的点,就是说这条紫色的曲线,就是我们对CLIP里那个图片编码器去做这种的linear probe。
我们可以发现,在当这个训练样本只有1,2或者4的时候,这种用了训练样本的few shot的方式还不如直接去做zero shot CLIP,也就再次证明了用文本去做这个引导这种多模态的学习是多么的强大。
那最后一个观察,就是随着这个训练样本的增多,那这个few shot学习的这个CLIP,它的模型效果最后是最好,它不仅超越了之前的这些方法,验证了CLIP模型的强大,同时他还超越了这种zero shot CLIP,验证了作者刚才的说法,对于这种难的数据集来说,有一些这个训练样本还是非常有必要的。
那说完了zero shot又说完了few shot,那接下来很自然的就是要看一下,如果下游任务用全部的数据,CLIP的效果会如何。
作者,就在3.2节里做了这些实验,之所以作者把这一节叫做特征学习,因为之前,不论你是无监督还是自监督,这种表征学习的方法都是先预训练一个模型,然后在下游任务上,用全部的数据去做这种微调的。
所以这里,如果你用上了全部的数据,其实就可以跟之前的这些特征学习的方式去做公平对比了。
那如果下游任务用全部的数据,就有很多种方式去衡量这个模型学到的这个特征好不好,最常见的两种方式,一种就是linear probe,另外一种就是fine-tune。
Linear probe,就是把预训练好的模型冻住,然后在上面再训练一个分类头,那对于fine tune,就微调来说,就是说把整个网络都放开,直接去做这种端到端的学习。
微调一般是更灵活的,而且在你下游数据集比较大的时候,微调往往是要比这个linear probe的效果要好很多的。
但是在CLIP这篇文章里,作者说我就是要用linear probe,我不用fine tune,这里,他就列了几个原因。
第一个原因,就是说CLIP这种工作,它就是为了用来研究这种跟数据集无关的预训练方式,那如果你的这个下游数据集足够大,然后我整个网络全都放开在你这个数据集上去做微调的话,很有可能你预训练的那个模型并不好,但是在微调的这个过程中,经过不断的优化,最后它的这个效果也很好。
这样,你就无法分别你这个预训练的方法或者预训练的模型到底好不好了。
而linear probe就是用这种线性分类头的方式,他们就不太灵活,整个网络大部分都是冻住的,只有最后这一层FC是可以训练的,那它这个可学习的空间就比较小,所以如果你这个预训练的模型没有训练好的话,即使你在下游任务上训练的再久也很难优化到一个特别好的结果,所以说能更准确的反映出这个预训练模型的好坏。
那另外一个作者选用linear probe的原因,就是因为linear probe不太用调参,因为CLIP这篇论文,做了大量的实验,涉及到大量的数据集,那如果你是做这种端到端的微调,你就有太多可以调的这个套餐和设计方案。
比如如果你这个下游数据集特别大,而且数据标注也质量比较高的话,你就希望你的这个学习率,可能会大一点,因为你想要这个预的模型,尽可能的去拟合你下游的这个数据集,但如果你下游任务的这个数据集,特别小,你可能就得用特别特别小的这个学习率。
因为很有可能稍一学习,这个模型就过拟合了,总之,你得为每个数据集都去量身定做,就是你得去搜这个超参,才能在各个数据集上表现好一点。
但如果你是做linear probe,你的这个模型主体都已经冻住了,你就是抽特征,你唯一要学的就是最后那个分类层,所以它可以调的这个参数非常少,而且不论对于什么数据集,或者不论对于什么任务,只要是分类,那整个测试的流程,就是一个正规化的流程,什么都不用改,所以大大简化了这个方法之间的对比。
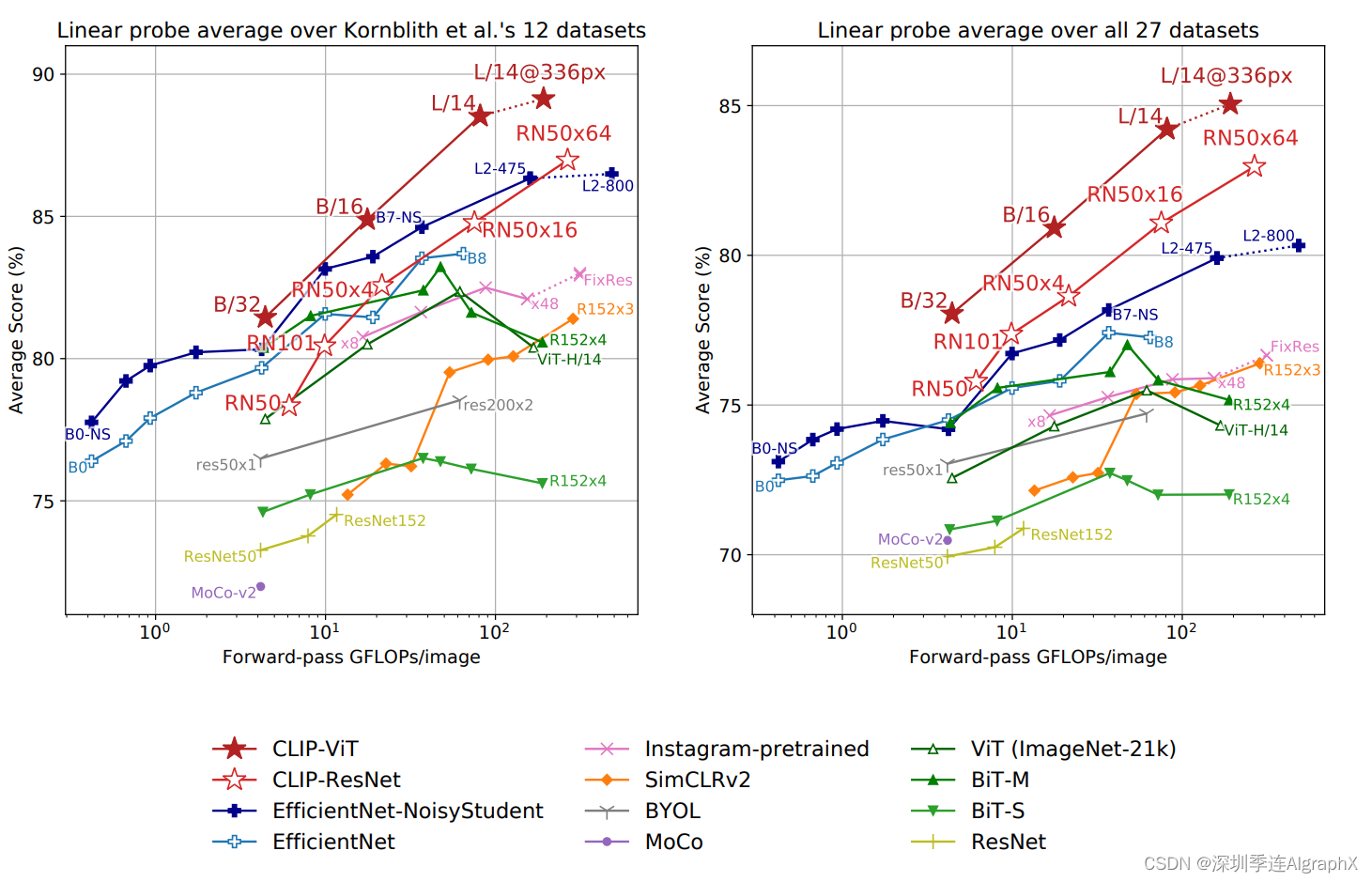
那接下来,作者就在这个图六里展示了一下结果,作者这里对比了很多的方法,从他们自己的这个CLIP,然后到有监督EfficientNet的这种,还有用了伪标签EfficientNet-NS的,还有这种弱监督的在Instagram上训练的模型,还有最近大火的这种对比学习MOCO这种自监督学到的模型,以及还有一些经典的有监督学习的这些基线模型。
左右两张图,其实画的都是一个意思,它的横坐标,都是说对于一张图片来说,它做一遍这个前向过程需要用多少的计算量,然后纵坐标,就是说在很多数据集上,最后的这个平均准确度。
那所以说,这个准确度越高,用的时间越短,它的这个效果就越好,所以说在这两张图里,越靠左上角点的,这个模型在精度和速度上的这个trade-off就做得更好。
首先我们先看右图,右者,就把那27个数据之像的这个效果平均了一下,然后这里我们可以看到,CLIP这里对应的这个红色五角星和这个红色的空心的五角星,效果都是最好的,比剩下所有的这些模型的效果都要好。
这就再次证明了CLIP这个模型的强大之处,就不光是zero shot,还有few shot,那再用全部的数据去做训练的时候,CLIP照样吊打别的所有模型。
那左边这张图,其实是为了跟之前的工作做一个公平对比,因为之前有个工作提出了这个12个数据集的一个集合,很多人,就都在这12个数据集上去比这个平均的效果,那在这张图里,我们可以看到用更大的模型,就是用vision transformer的这种CLIP,效果还是很好。
所以如果你那些模型,在这个数据集上做过有监督的预训练,那肯定它这个效果就会特别好,超过CLIP也就不足为奇了。
最后,作者为了再次证明CLIP模型的这个无比强大。
他就选择了之前在ImageNet上表现最好的模型,也就我们之前常说的这个用最大的EfficientNet L2 25 NS,noisy student这种方式,也就用伪标签的方式去训练的一个模型,那在ImageNet上霸榜了快一年,有88点几的这个top one的准确率。
那在这里,作者就是把CLIP的模型和这个模型全都冻住,然后从他里面去抽特征,然后最后去做这种logistic regression。
然后作者发现,在27个数据集里,CLIP在21个上面都超过了EfficientNet,而且很多数据集都是大比分超过,那在那些表现不行的数据集上,CLIP也只稍微低一点,差距并不大。
那讲完了zero shot,用所有数据去衡量这个模型的好坏,也就是说正规的任务,我们做完了,那接下来就要衡量一下这个模型其他的特性,那首当其冲的,就是这个模型的泛化性,也就是它的稳健性。
作者这里,就在3.5节讲了一下,当你这个数据,有分布偏移的时候的表现会如何。
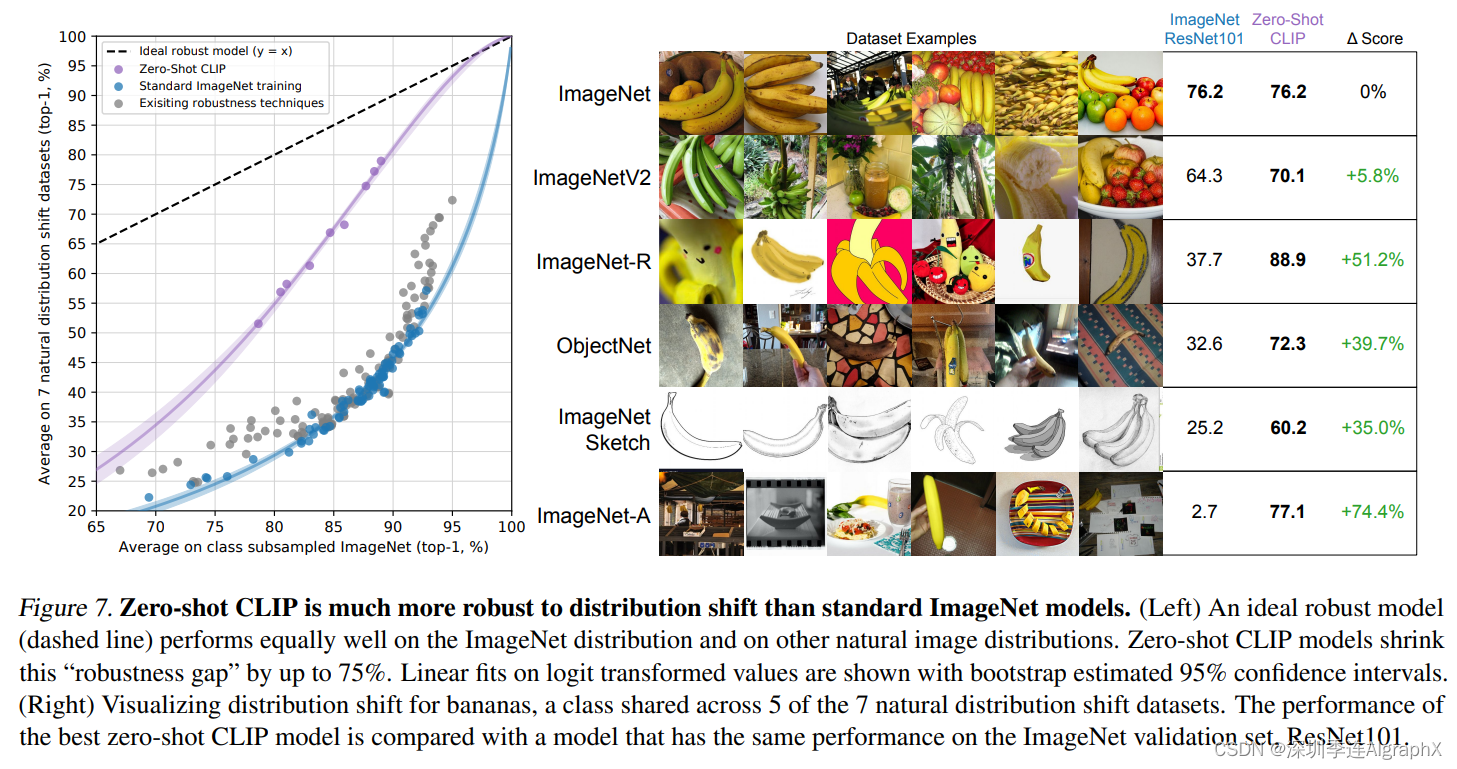
当然这个图我们在讲前沿的时候,就已经提到过了,就是说当数据这个分布改变的非常厉害的时候,普通的一个模型,它可能掉点就非常严重,但是对于CLIP训练出来的模型,它就非常的稳健,他在所有的这种数据分布上表现的都非常好。
鉴于时间关系,这里我就不展开了。
那在第二章作者讲完了这个怎么去做预训练,然后又在第三章讲了怎么去做这种zero的推理,以及在各种环境各个数据集上的表现,这篇论文的主体方法,而主要的实验结果,其实就已经讲完了。
那接下来的这十几页,其实全都是讨论和分析。
5 Data Overlap Analysis数据分析
然后因为CLIP,在zero shot,few shot,在所有数据上的表现,都非常亮眼,所是说作者,在这个第四章节就做了一个很有意思的事情,就是说既然你这么强,那你跟这个人比一比,看看有什么相似和区别,那以及我们还怎么能继续提高这个CLIP模型。
(略)
我们可以看到zero CLIP比这个zero的人,表现要好得多。
那毕竟对于一个普通人来说,如果他对狗和猫的种类不是那么了解的话,那确实很难去做出这种zero的分类。
比如对于我而言,我知道狗的种类,可能两只手就数得过来,肯定是不认识37种这么多的狗和猫的。
然后,一旦给这个参赛者看过一张这个视力图片以后,他们的这个准确度,一下就从50多提升到70多了,这个提升还是相当明显的,就说明人的这个学习速度还是非常快的,但如果你给这些参赛者,每个种类再多看一张照片,就是这里的two shot这种情况。
结果你会发现这个准确度并没有提升,这个倒是挺有意思的。
这说明人,之所以在给一张图片以后,准确率能提升这么多,主要是他可以把常识,他之前的这种先验知识和这个视力图片,联合在一起去做这种判断。
那如果他没有系统的学过这些知识,就是说他的先验知识并没有增加的情况下,那你再多给他看一到两张图片,其实也是于事无补的,他并不会真的随着这个数据的增加,准确率提升。
但这里这个对比,也不一定公平,因为毕竟只选了五个人作为参赛者嘛,它这个代表性不太够,而且数据集,也就只做了一个,而且狗、猫这些图片,在网上可能非常多,所以说,CLIP的预训练数据集,就有这些配对的图片文本对,所以说,它的这个准确率才能这么高,但无论如何,CLIP强大还是很强大的。
在第四章,作者简单讲完了这个和人类对比的实验之后,作者还简单的讲了一个章节,就这些数据集之间有没有这种重叠的问题,因为肯定会有很多人质疑,是不是因为你这个收集的数据集太大了,太好了,所以说他把这些下游的数据集全都包括了,所以才导致它的效果这么好。
那作者这里,也简单的做了一些消融化的实验,最后的结论,还是说CLIP这个模型本身泛化性比较好,这里我就不过多介绍,感兴趣的同学,可以自己去看一下。
其实最后,CLIP这篇文章我最想讲的一个章节,就是这个第六章,Limitation。
6 Limitation局限性
尽管CLIP这个模型这么强大,肯定还是有很多不足的地方,肯定还是有很多做不了的事情,来分析一下这些不足和这些局限性,其实比这篇文章到底怎么做的,之前那些好的结果是怎么来的,都要有意义的多。
因为这些不足和局限性,才能引发更多的思考,而让整个领域向前走。
加上这个章节,其实也是写论文很好的,或者说必不可少的一个步骤。
审稿人是很爱看的,而且现在,有越来越多的审稿人去要求这个作者写一些他们的局限和不足。
那接下来,我们就来看一看作者写了哪些局限性和不足之处。
第一点,作者说CLIP在很多数据集上,平均下来来看,它是可以和一个比较简单的基线模型打成平手的。
也就是我们反复说的那个ImageNet上训练的ResNet-50的模型。
但是,在大多数这个数据集上,这个RN50的模型,其实根本就不是state-of-the-art,如果跟现在最好的那个模型比起来,这个RN50要比state-of-the-art差很远。
那image也是如此,CLIP zero shot就76.2,跟这个RN50打个平手。
但是你要跟noisy student ,88点几,或者你跟最新最大的vision transformer,MAE比,都是88 89,甚至都上90了,差了十几个点。
所以CLIP的这个性能强,但是也没有强到不可一世的地步。
作者这里说,文章中也做了实验,就是如果你加大这个数据集,而且加大这个模型,就是你去扩大这个规模,CLIP的性能是还能继续提高的。
但是如果你想把这十几个点的差距都弥补上。
作者预估,还要在现在训练CLIP这个计算量的基础上,要*1000,那这个代价就太大了。作者这里说,即使对OpenAI来说,用现有的这种硬件条件,他们也是没办法训练。
所以如果你想走扩大规模的这种方式,去弥补这十几个点的差距,让CLIP在所有数据集上,都达到搜SOTA的这个效果的话。那肯定是要有新的方法,然后在这个计算和数据的这个高效性进行进一步的提高。
那另外一个局限之处,作者就是说CLIP在有些数据集上,它的这个zero shot的结果,也并不好。
比如在某些这种细分类的数据集上的效果,也是低于这个有监督训练ResNet-50的基线网络的。
另外,不光是这种细分类的任务,还无法处理这种任务,就是特别抽象的概念,或者说更难的这些任务。
比如说去数一数这个图片里到底有多少个物体。
或者说在监控视频里区分当前这一帧是异常还是非异常,因为CLIP模型,虽然很擅长去分类这个物体,但是他完全不了解什么叫异常,什么叫安全。
所以作者最后总结说,他们坚信,还有很多很多很多领域,这个zero shot的性能,其实是跟瞎猜一样的。
也就是说,在很多情况下,CLIP都不行,它并不是一个万能的方法。
那第三个局限性?作者这里说CLI虽然说泛化做的很好,对于很多这种自然图像的这个分布偏移模型还是相对稳健。
但是,如果你在做推理的时候,这个数据真的跟你训练的数据差的非常远,就这个数据,真的已经out of distribution了,那CLIP的模型,泛化照样也很差。
作者这里举了一个例子,就是在MINIST的这个数据集上,CLIP的准确率只有88%,那作者说这个就尴尬了,因为MINIST这个数据集特别小,而且是几十年前就提出来的,随随便便一个分类器在上面都有99%的准确度。
而且就连一个超级简单的一个基线模型,就这里说的,直接在这个像素点上去做了,最后的结果,就比zero shot CLIP还要高,这个在作者看来,甚至在我们读者看来,其实都是不可思议的一件事情。
然后作者,就深入的研究了一下,他就用各种去重的方法去看看,他们搜集的这个四个亿图片的数据集里,到底有没有跟MINIST相似的图片,结果发现,非常神奇的是,即使他们的训练数据集,有4亿个训练样本,但是,就是没有跟这个MINIST的数据长像,因为MINIST就是12345678这种合成的数据嘛,所以跟自然图像,还是有很大差距的。
所以这就导致MINIST的数据对于CLIP模型来说,就是一个out of distribution的数据,所以这其实也就从侧面反映了CLIP这个模型,也没什么大不了的,它跟普通的这些深度学习的模型,都非常的脆弱。
然后第四个局限性,作者这里就说,虽然CLIP可以去做这种zero shot的分类任务,那他,还是从你给定的那些类别里去做的选择,那相比而言,一种更灵活的方式就直接去生成图像的这个标题,那这样的话,一切都是这个模型在处理,所有的都自动化了,它是可以给你生成一个新的输出的,而不是像CLIP一样,你得给他一个新的类别,然后他告诉你跟这个图片类似不类似。
所以作者这里,还是不忘OpenAI的老本行,还是想把一切都GPT都做成生成式的模型,但可惜,受限于这个计算资源的问题,他们没办法去训练一个图像题目生成的这个基线网络。
作者说,以后,可能会有这么一个简单的想法,就是说把这个对比学习的目标函数和这个生成式的目标函数合在一起,那这样的话,你就有可能把两个方法的优势结合在一起。
就是既有了对比学习这个训练模型的这个高效性,又有了这个生成式模型的这个灵活性。
接下来,作者又讨论了第五个局限性,就是说CLIP,对这种数据的利用,并不是很高效,就是他还跟别的这个深度学习里的网络一样,需要大量,大量的数据去投喂。
作者这里形象的描述了一下他们这个数据集,到底有多大,那在他们训练的过程中?他们一共训练了32个epochs。
那每个epoch要过4亿个图片嘛,所以说最后一共就相当于是跑了128亿张图片,那如果我们这个data loader的速度,是每秒钟出一张图片。那这个模型,要把所有的这些图片全看完,就需要花405年的时间,所以作者感叹说,这用的数据,实在是太多了,如果能减少一下这个数据用量,那当然是极好的。那怎么减少这个数据用量?简单一点的方式当然就是做数据增强了。那另外,最近还有两种比较常见的方式,一种就是用自监督的方式,另一种,就是用伪标签的方式,这两种方式,都能比监督学习有更好的这个数据利用效率。
那作者接下来说的第六个局限性,还跟数据有关,但是,是跟下游任务的这个测试数据集有关。
他的意思是说,虽然我整篇文章都在说zero shot ,CLIP做zero shot效果最好,但是,在我们整个研发的这个过程之中,我们为了能跟别人去做这种公平的比较,也为了得到一些回馈,所以我们往往是在整个这个测试数据集上去不停的做测试。
比如说CLIP这里ImageNet上的分这么高,他并不是第一次训练出来分就这么高的,他肯定是测试了很多变体,做了很多超参的调整,最后才定下的这套网络结构和这套超参数。
而在整个这个研发的过程中,他其实每次都用的这个ImageNet测试集,去做了指导,所以这里面,已经无形之中就已经带入了偏见了,而且,并不是真正的这种zero shot的情况。
另外,作者还说他们整篇文章里,不停的用到27个数据集去做测试,但其实数据集千千万万,为什么只选这27个?这27个也不一定就具有代表性,所以整个CLIP的这个研发过程,也是跟这27个数据集息息相关的。
那最后作者总结了一下,就是说如果能真的在创建一个新的数据集,那这个数据集,就是用来测试各种各样的这个zero shot迁移的能力的,那就太好了,如果只是像他们现在一样简单的,重复使用已有的这种做有监督训练的数据集,就难免会有这种局限性。
那第七个局限性,就是OpenAI经常说的这个局限性了,因为他们的这个数据,都是从网上爬的,不论是图片还是文字,那这些下来的图片文本对,基本是没有经过清洗的,就是既没有被过滤过,也没有被审查过。
所以这就导致,最后学得的这个CLI模型,它很有可能就带来一些社会上的这种偏见,比如说性别,肤色,宗教。所以作者这里,还专门写了一个第七章,去讨论了一下克利普模型有可能带来的这种巨大的社会影响力,以及它模型里可能隐藏的这种偏见,有可能会带来的这种不当的使用。
那最后,作者还提到了另外一个局限性,他就说,虽然整篇论文他们都在宣传,CLIP这个工作到底有多么的灵活,利用这种自然语言处理到底有多么的牛逼。
但其实,它还是有局限性的,因为很多很复杂的这种任务,或者是很复杂的这种概念,其实即使你用语言也无法描述的。
如果你能在做下游任务做这种泛化的时候,提供一些这种训练样本还是非常有帮助的。
但可惜,CLIP这个模型的提出,并不是为了few shot的这种情况而提出的,也不是为了它优化的。
所以就导致了一个非常奇怪的现象,之前我们也看过,就是当给CLIP提供一些训练样本,one shot two shot,few shot的时候。他这个结果反而还不如直接用zero shot,这个就很耐人寻味了,你不给他提供训练样本,它反而效果很好,你给他提供一些训练样本,它反而效果还差了。
那这个跟我们人的学习,就截然不同了,因为在第四个章节的时候,我们跟人的那个表现也做过对比。
如果你给这些参加实验的人,就看一张图片,他这个分类的准确度,最后都会大幅提升。
而不可能是说你给他更多的训练样本,那反而这个分类的准确度还下降了。
所以说,之后的这个工作还有很多,怎么能让CLIP既在这种的zero shot情况下工作的很好,也能在给他提供一些训练样本的时候,few shot他做的也很好。
7 Conclusion结论
那接下来,在第七章作者主要讨论一下CLIP模型对这个社会可能产生的这个影响力,首先在7.1节讲了一下模型可能内在的这种偏见,然后在7.2节,讲了一下CLIP在监控视频里的应用和风险,最后,在7.3节展望了一下未来工作。
然后,作者又在最后第八章讲了一下相关工作,但因为时间关系,而且因为后面的这两章,跟文章的方法其实没有多大的关系了,所以这里我就跳过了。
我们最后,直接去看一下这个结论部分。
结论部分,其实写的非常短,像我之前说的一样,还没有最后的这个致谢,写的长,因为实在是该讨论的都讨论完了,该做的实验也全做完了,如果这里要把结果再秀一遍,写不下,所以说就只好简单的总结一下了。
作者这里说,他们的这个研究动机就是因为在NLP领域,现在利用这种大规模的数据去训练模型,而且用这种跟下游任务无关的这种训练方式,比如说完形填空,在这两种工具的加持之下。NLP那边,取得了非常革命性的成功,比如就是他们自己的GPT系列工作,所以他们,就想把NLP里的这个成功,复制到其他的领域里去,比如说视觉。
然后作者发现,在视觉领域里用了这一套思路之后,确实效果也不错,其实是特别好。
所以他还顺带讨论了一下,有可能带来的这个社会的影响力。
接下来,作者用一句话总结了他们的方法,那就在于预训练阶段,他们做了这种对比学习,他们利用了这种文本的提示,去做了这种zero shot的迁移学习。
最后的结论就是说,在大规模的数据集和大模型的双向加持之下的效果,能跟之前精心设计的那些,而且是有监督训练出来的基线模型打成平手,但是作者在第六章也讨论了很多这个局限性,所以说作者这里说,还有很多可以提升的空间。
那最后总结一下CLIP这篇工作最大的贡献?在我看来,就是他打破了之前这种固定种类标签的范式。
意思就是说,不论在你收集数据集的时候,还是在训练模型的时候,你都不需要像ImageNet一样,做1000类,或者像COCO一样做80类了。你直接就搜集这种图片文本的配对,然后用无监督的方式,要么就预测它的相似性,要么去生成它。
总之,是跟这种固定多少类别的范式,说拜拜了。
这样的好处,就是不仅在处理数据的时候更方便,训练模型更方便,那最主要的就是在你做推理的时候更方便,甚至可以去zero shot的,做各种各样的分类任务,所以在这边工作出来之后,很快就有一大批工作迅速跟进。
那到现在为止,其实像物体检测、物体分割、视频动作识别、检索,还有多模态,还有图像生成。基本上是每个领域都有利用CLIP的这个后续工作,它的影响力,可见一斑。
?
那如果我们按照沐神之前讲的那个,如何判断一个工作的这个价值来说?
CLIP,在我看来,应该就是100*100*100。
从新意度的角度来说,CLIP打破了这种固定类别标签的做法,彻底放飞了视觉模型的这个训练过程,引发了一大批后续的工作,所以新意度,无疑是很高的。
那从有效性上来说,那就更不用说了,做了这么多数据集,效果这么好,泛化性能也这么好,甚至在某些情况下,比人的这个zero的性能还好,那有效性,也毋庸置疑是100分。
最后,就是问题大小,那CLIP,用一个模型就能解决大部分的这个分类任务,而且是zero去解决这个问题本身就已经很大,更何况,你只要利用这个CLIP训练好的模型,再在其他领域里稍微适配一下,就能把别的领域的任务也全都做掉。
所以说它这个问题大小也是100分,CLIP模型的这个灵活性和它的高效性,能让我们看到一点,这个人工智障变人工智能的希望。
所以综合从这三个角度来看,CLIP都是一篇价值极高的论文。
?
8 摘录
CLIP 论文逐段精读【论文精读】_哔哩哔哩_bilibili
https://arxiv.org/abs/2103.00020
https://arxiv.org/pdf/2103.17249v1.pdf
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java内部类
- 第19章总结
- 单例设计模式
- Python数据分析之pandas的SQL风格
- 2023年前前同事12个月薪水未发,来聊聊普通的开发人如何避开丛丛杀机的新一年
- http网络编程——在ue5中实现文件传输功能
- superset未授权访问漏洞(CVE-2023-27524)复现
- 计算机毕设ssm中国服饰文献资料管理平台x94569【附源码】
- Node.js基础知识点(二)
- Science Robotics封面文章:瑞士洛桑联邦理工学院研制仿生鳄鱼和仿生巨蜥机器人,走进非洲尼罗河